Addressing Over-Refusal in LLMs with Competing Rewards
Pith reviewed 2026-07-01 06:56 UTC · model grok-4.3
The pith
Encouraging LLMs to explore unsafe reasoning before giving safe answers reduces over-refusal on harmless prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
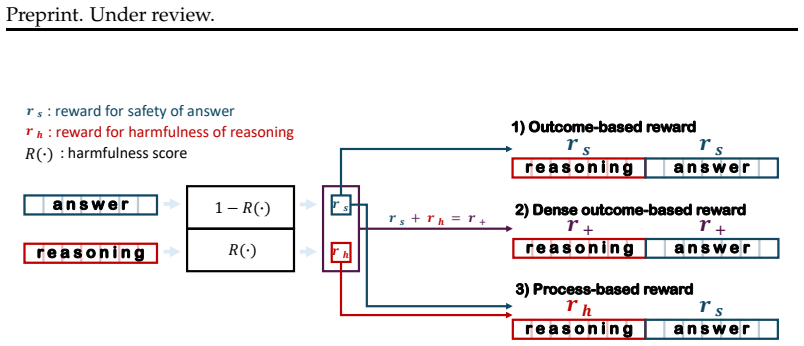
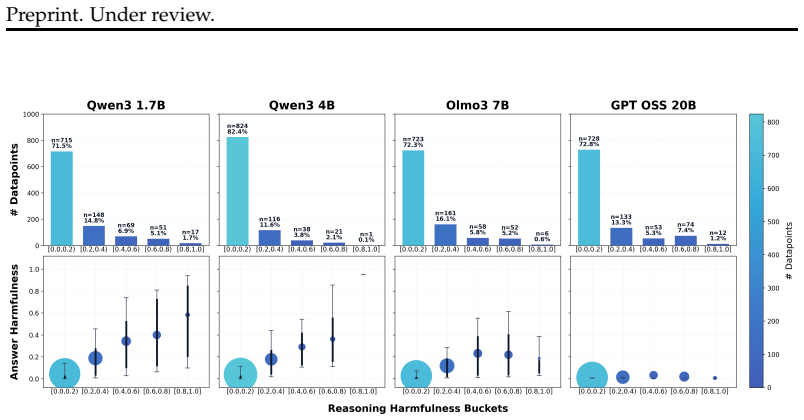
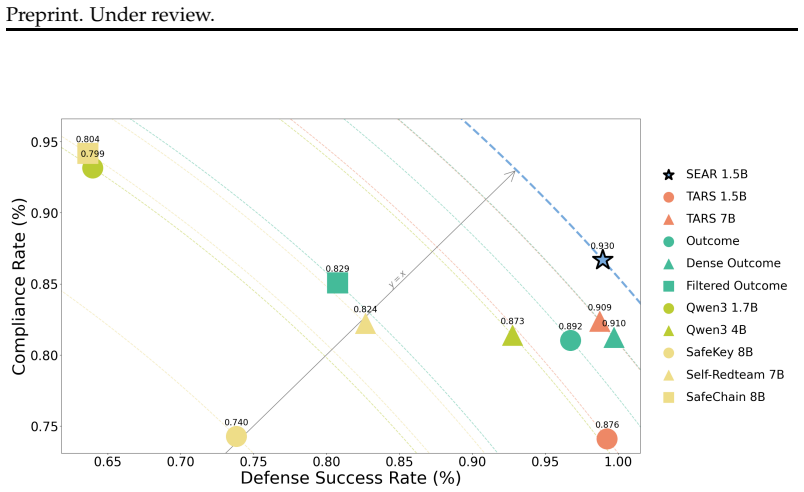
The paper claims that unsafe reasoning itself serves as a useful exploratory signal. By casting safety reasoning as an adversarial optimization problem in which a reasoning player explores strategies for producing an unsafe response and an answer player ensures that the final output is safe, and by training a single model with dense rewards to play both roles within one chain-of-thought across different segments, the model learns to engage in harmful reasoning as exploration while reliably flipping back to a safe answer. This behavior mitigates over-refusal and defends against attacks that directly manipulate the reasoning to be harmful.
What carries the argument
Adversarial optimization with competing rewards, where the model plays both a reasoning explorer for unsafe responses and an answer player ensuring safety within segments of a single chain-of-thought.
If this is right
- The model remains safe on harmful prompts while complying with appropriate harmless ones.
- The approach defends against attacks that manipulate the reasoning process to be harmful.
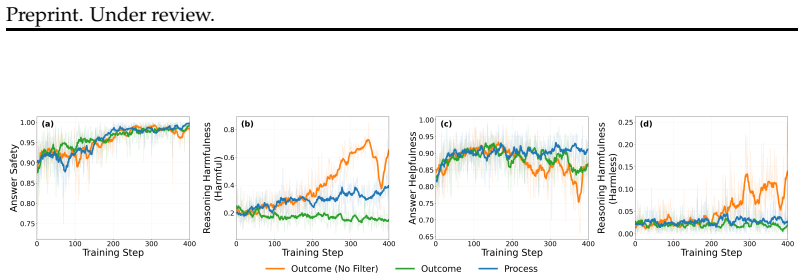
- Process rewards enable stable training when optimizing the two competing objectives.
- Harmful exploration resolves prompt ambiguity and allows selective compliance.
Where Pith is reading between the lines
- The single-model dual-role training might simplify deployment compared to maintaining separate safety modules.
- The distinction improvement could extend to other alignment trade-offs such as helpfulness versus truthfulness.
- Evaluating the method on a broader set of jailbreak techniques would test whether the exploratory benefit generalizes.
- Internal exploration of disallowed paths may prove useful for decision-making in other constrained AI systems.
Load-bearing premise
Process rewards are crucial for stable optimization of competing objectives, and encouraging unsafe reasoning as exploration will improve distinction without the model producing harmful outputs in deployment.
What would settle it
Measure whether the trained model shows a lower refusal rate on a set of ambiguous harmless prompts while maintaining refusal on harmful prompts and generating no unsafe content in its final outputs.
Figures
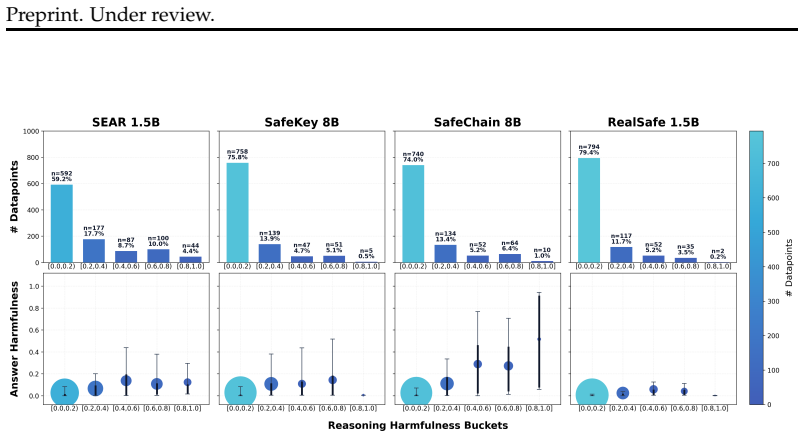
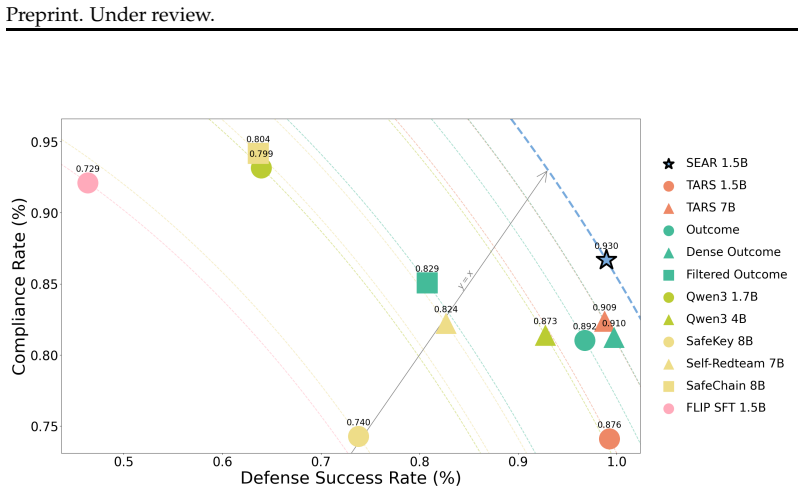
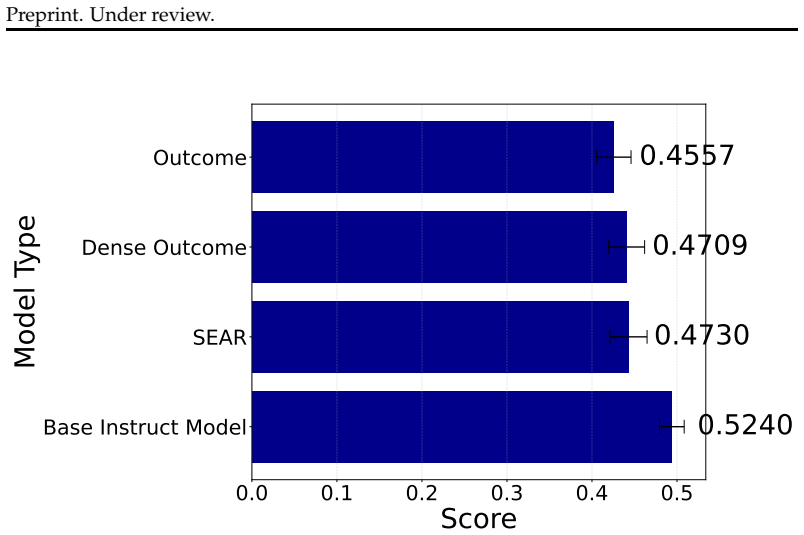
read the original abstract
Safety training on language models often induces over-refusal: improved safety on harmful prompts at the cost of increased refusal on harmless ones. Though this trade-off can be mitigated by training models with reinforcement learning (RL) to reason before answering, it does not remove the underlying problem that reasoning can often be a "rubber stamp" for a predetermined response. In this paper, we address the safety-refusal trade-off by rethinking how models are trained to reason about safety. Our key insight is that unsafe reasoning can itself serve as a useful exploratory signal. Rather than preemptively blocking harmful thoughts, we encourage the model to sufficiently explore unsafe reasoning but produce a safe response. The harmful exploration improves the model's ability to distinguish harmful from harmless prompts by resolving ambiguity, allowing it to remain safe while complying only when appropriate. We cast this as an adversarial optimization problem in which a reasoning player explores strategies for producing an unsafe response and an answer player ensures that the final output is safe. We train a single model with dense rewards to play both roles within one chain-of-thought, across different segments. To achieve this, we find that process rewards are crucial for stable optimization of competing objectives. Our resulting model SEAR deliberately engages in harmful reasoning as exploration while reliably flipping back to a safe answer. We demonstrate that this behavior helps mitigate over-refusal and defend against attacks that directly manipulate the reasoning to be harmful.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SEAR, a method to mitigate over-refusal in safety-trained LLMs by reframing reasoning as an adversarial optimization problem. A single model is trained with dense competing process rewards across CoT segments: a 'reasoning player' is incentivized to explore strategies for unsafe responses, while an 'answer player' ensures the final output remains safe. The authors claim this deliberate harmful exploration resolves prompt ambiguity, improves distinction between harmful and harmless inputs, and allows compliance only when appropriate, without producing harmful outputs at deployment. They state that process rewards are crucial for stable optimization of the competing objectives.
Significance. If the separation of exploration and safety behaviors holds under shared parameters, the approach could meaningfully advance LLM alignment by turning unsafe reasoning into a controlled exploratory signal rather than a liability. The use of dense process rewards to stabilize competing objectives within one forward pass is a concrete technical idea that, if validated, would be of interest to the safety and RLHF communities.
major comments (2)
- [training procedure and adversarial setup description] The central claim requires that gradients from the unsafe-reasoning reward do not bleed into the final-answer policy despite shared parameters. The manuscript states that process rewards are 'crucial for stable optimization' but provides no analysis or ablation showing that the answer segment reliably overrides unsafe content generated during reasoning. This separation is load-bearing for the safety guarantee and is not demonstrated.
- [Abstract and results claims] The abstract asserts that the method 'helps mitigate over-refusal and defend against attacks that directly manipulate the reasoning to be harmful,' yet the provided description supplies no quantitative results, baselines, or attack evaluations to support that the exploration actually improves distinction without increasing unsafe outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: The central claim requires that gradients from the unsafe-reasoning reward do not bleed into the final-answer policy despite shared parameters. The manuscript states that process rewards are 'crucial for stable optimization' but provides no analysis or ablation showing that the answer segment reliably overrides unsafe content generated during reasoning. This separation is load-bearing for the safety guarantee and is not demonstrated.
Authors: We agree that explicit demonstration of the separation is important. The manuscript states that process rewards are crucial for stable optimization of competing objectives but does not include dedicated ablations or gradient analyses showing override behavior. We will add an ablation study comparing process-reward variants on override reliability and include analysis of how the answer segment maintains safety. revision: yes
-
Referee: The abstract asserts that the method 'helps mitigate over-refusal and defend against attacks that directly manipulate the reasoning to be harmful,' yet the provided description supplies no quantitative results, baselines, or attack evaluations to support that the exploration actually improves distinction without increasing unsafe outputs.
Authors: The full manuscript contains quantitative results, baseline comparisons, and attack evaluations in the Experiments section that support the abstract claims, including metrics on over-refusal reduction and safety under reasoning attacks. We will add explicit cross-references from the abstract to these results to make the support clearer. revision: partial
Circularity Check
No circularity: optimization procedure is independent of its inputs
full rationale
The paper describes an adversarial training setup with competing rewards on CoT segments but provides no equations, derivations, or self-citations that reduce the claimed benefit (improved distinction via harmful exploration) to a quantity defined by the method itself. The central claim is presented as the outcome of an empirical optimization process rather than a tautological re-expression of fitted parameters or prior self-referential results, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Process rewards enable stable optimization of competing objectives in RL for LLMs
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Deliberative Alignment: Reasoning Enables Safer Language Models , author=. 2025 , eprint=
2025
-
[2]
2025 , eprint=
Trading Inference-Time Compute for Adversarial Robustness , author=. 2025 , eprint=
2025
-
[3]
Setlur, Amrith and Qu, Yuxiao and Yang, Matthew and Zhang, Lunjun and Smith, Virginia and Kumar, Aviral , title=
-
[4]
OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling , author=. arXiv preprint arXiv:2506.20512 , year=
-
[5]
2025 , eprint=
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs , author =. 2025 , eprint=
2025
-
[6]
arXiv preprint arXiv:2501.18841 , year=
Trading inference-time compute for adversarial robustness , author=. arXiv preprint arXiv:2501.18841 , year=
-
[7]
arXiv preprint arXiv:2407.18219 , year=
Recursive introspection: Teaching language model agents how to self-improve , author=. arXiv preprint arXiv:2407.18219 , year=
-
[8]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[9]
arXiv preprint arXiv:2503.07572 , year=
Optimizing test-time compute via meta reinforcement fine-tuning , author=. arXiv preprint arXiv:2503.07572 , year=
-
[10]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
s1: Simple test-time scaling , author=. arXiv preprint arXiv:2501.19393 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2501.18585 , year=
Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs , author=. arXiv preprint arXiv:2501.18585 , year=
-
[14]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Large language monkeys: Scaling inference compute with repeated sampling , author=. arXiv preprint arXiv:2407.21787 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
As an AI language model, I cannot
“As an AI language model, I cannot”: Investigating LLM Denials of User Requests , author=. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
2024
-
[16]
arXiv preprint arXiv:2504.10050 , year=
Emotional Strain and Frustration in LLM Interactions in Software Engineering , author=. arXiv preprint arXiv:2504.10050 , year=
-
[17]
arXiv preprint arXiv:2502.12970 , year=
Reasoning-to-Defend: Safety-Aware Reasoning Can Defend Large Language Models from Jailbreaking , author=. arXiv preprint arXiv:2502.12970 , year=
-
[18]
arXiv preprint arXiv:2502.12659 , year=
The hidden risks of large reasoning models: A safety assessment of r1 , author=. arXiv preprint arXiv:2502.12659 , year=
-
[19]
arXiv preprint arXiv:2504.07128 , year=
DeepSeek-R1 Thoughtology: Let's< think> about LLM Reasoning , author=. arXiv preprint arXiv:2504.07128 , year=
-
[20]
arXiv preprint arXiv:2501.18438 , year=
o3-mini vs DeepSeek-R1: Which One is Safer? , author=. arXiv preprint arXiv:2501.18438 , year=
-
[21]
arXiv preprint arXiv:2504.09420 , year=
SaRO: Enhancing LLM Safety through Reasoning-based Alignment , author=. arXiv preprint arXiv:2504.09420 , year=
-
[22]
arXiv preprint arXiv:2504.10081 , year=
RealSafe-R1: Safety-Aligned DeepSeek-R1 without Compromising Reasoning Capability , author=. arXiv preprint arXiv:2504.10081 , year=
-
[23]
arXiv preprint arXiv:2503.17882 , year=
THINK BEFORE REFUSAL: Triggering Safety Reflection in LLMs to Mitigate False Refusal Behavior , author=. arXiv preprint arXiv:2503.17882 , year=
-
[24]
arXiv preprint arXiv:2503.05021 , year=
Safety is Not Only About Refusal: Reasoning-Enhanced Fine-tuning for Interpretable LLM Safety , author=. arXiv preprint arXiv:2503.05021 , year=
-
[25]
Guard: Multilingual Reasoning Guardrail using Curriculum Learning , author=
MR. Guard: Multilingual Reasoning Guardrail using Curriculum Learning , author=. arXiv preprint arXiv:2504.15241 , year=
-
[27]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024 , author=
2024
-
[28]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal , author=. arXiv preprint arXiv:2402.04249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
Jailbreaking Black Box Large Language Models in Twenty Queries
Jailbreaking black box large language models in twenty queries , author=. arXiv preprint arXiv:2310.08419 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Autodan: Generating stealthy jailbreak prompts on aligned large language models , author=. arXiv preprint arXiv:2310.04451 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
A StrongREJECT for Empty Jailbreaks
A strongreject for empty jailbreaks , author=. arXiv preprint arXiv:2402.10260 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Xie, T., Qi, X., Zeng, Y ., Huang, Y ., Sehwag, U
Sorry-bench: Systematically evaluating large language model safety refusal behaviors , author=. arXiv preprint arXiv:2406.14598 , year=
-
[35]
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. arXiv preprint arXiv:2308.01263 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
arXiv preprint arXiv:2405.20947 , year=
Or-bench: An over-refusal benchmark for large language models , author=. arXiv preprint arXiv:2405.20947 , year=
-
[37]
Demystifying Long Chain-of-Thought Reasoning in LLMs
Demystifying Long Chain-of-Thought Reasoning in LLMs , author=. arXiv preprint arXiv:2502.03373 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Advances in Neural Information Processing Systems , volume=
Rainbow teaming: Open-ended generation of diverse adversarial prompts , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
2023 , eprint=
UltraFeedback: Boosting Language Models with High-quality Feedback , author=. 2023 , eprint=
2023
-
[41]
arXiv preprint arXiv:2406.10216 , year=
Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs , author=. arXiv preprint arXiv:2406.10216 , year=
-
[42]
Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A
Rewardbench: Evaluating reward models for language modeling , author=. arXiv preprint arXiv:2403.13787 , year=
-
[43]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[45]
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
2024 , eprint=
WildTeaming at Scale: From In-the-Wild Jailbreaks to (Adversarially) Safer Language Models , author=. 2024 , eprint=
2024
-
[47]
0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails , author=
AEGIS2. 0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails , author=
-
[48]
2024 , eprint=
Detoxifying Large Language Models via Knowledge Editing , author =. 2024 , eprint=
2024
-
[49]
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars , author=. arXiv preprint arXiv:2503.01307 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models , author=. arXiv preprint arXiv:2408.00724 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Training Language Models to Self-Correct via Reinforcement Learning
Training language models to self-correct via reinforcement learning , author=. arXiv preprint arXiv:2409.12917 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
arXiv preprint arXiv:2405.00451 , year=
Monte carlo tree search boosts reasoning via iterative preference learning , author=. arXiv preprint arXiv:2405.00451 , year=
-
[54]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[55]
LIMO: Less is More for Reasoning
LIMO: Less is More for Reasoning , author=. arXiv preprint arXiv:2502.03387 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Do not think that much for 2+ 3=? on the overthinking of o1-like llms , author=. arXiv preprint arXiv:2412.21187 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
Great, now write an article about that: The crescendo multi-turn llm jailbreak attack , author=. arXiv preprint arXiv:2404.01833 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
arXiv preprint arXiv:2504.13203 , year=
X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents , author=. arXiv preprint arXiv:2504.13203 , year=
-
[59]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned , author=. arXiv preprint arXiv:2209.07858 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Red Teaming Language Models with Language Models
Red teaming language models with language models , author=. arXiv preprint arXiv:2202.03286 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
arXiv preprint arXiv:2401.17263 , year=
Robust prompt optimization for defending language models against jailbreaking attacks , author=. arXiv preprint arXiv:2401.17263 , year=
-
[66]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Umap: Uniform manifold approximation and projection for dimension reduction , author=. arXiv preprint arXiv:1802.03426 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
2025 , note=
DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL , author=. 2025 , note=
2025
-
[69]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A holistic approach to undesired content detection in the real world , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[70]
arXiv preprint arXiv:2412.17034 , year=
Shaping the Safety Boundaries: Understanding and Defending Against Jailbreaks in Large Language Models , author=. arXiv preprint arXiv:2412.17034 , year=
-
[71]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Revisiting Jailbreaking for Large Language Models: A Representation Engineering Perspective , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[72]
arXiv preprint arXiv:2406.10794 , year=
Towards understanding jailbreak attacks in llms: A representation space analysis , author=. arXiv preprint arXiv:2406.10794 , year=
-
[73]
Advances in Neural Information Processing Systems , volume=
Iterative reasoning preference optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Smoothllm: Defending large language models against jailbreaking attacks , author=. arXiv preprint arXiv:2310.03684 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Improving alignment and robustness with circuit breakers , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[77]
arXiv preprint arXiv:2409.14586 , year=
Backtracking improves generation safety , author=. arXiv preprint arXiv:2409.14586 , year=
-
[78]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[79]
arXiv preprint arXiv:2309.07875 , year=
Safety-tuned llamas: Lessons from improving the safety of large language models that follow instructions , author=. arXiv preprint arXiv:2309.07875 , year=
-
[80]
arXiv preprint arXiv:2404.01295 , year=
Towards safety and helpfulness balanced responses via controllable large language models , author=. arXiv preprint arXiv:2404.01295 , year=
-
[81]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.