Vision-EKIPL: External Knowledge-Infused Policy Learning for Visual Reasoning
Pith reviewed 2026-05-19 10:31 UTC · model grok-4.3
The pith
Infusing actions from external auxiliary models into RL training expands exploration and lifts visual reasoning performance in MLLMs by up to 5%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The core discovery is that policy learning with knowledge infusion from external models significantly expands the model's exploration space, effectively improves the reasoning boundary, and substantially accelerates training convergence speed and efficiency, producing measurable gains over standard GRPO-style RL that samples action groups solely from the policy itself.
What carries the argument
The central mechanism is the deliberate insertion of high-quality action groups generated by separate auxiliary models into the RL optimization loop so that the policy model receives guidance beyond its own current samples.
If this is right
- The exploration space available to the policy grows because it now considers reasoning steps it would not have generated itself.
- The upper limit on achievable reasoning quality rises because the model is steered by stronger action examples during gradient updates.
- Training reaches high performance in fewer steps because the policy receives useful guidance from the start rather than discovering good actions through random exploration alone.
- The method supplies a concrete way to inject domain knowledge into RL without changing the underlying reward model or loss function.
Where Pith is reading between the lines
- If the external models are themselves trained on similar data, the benefit may shrink once the policy catches up to their level.
- The same infusion idea could be tested in non-visual RL domains such as mathematical proof search or game playing where self-sampling is also a known bottleneck.
- Choosing which auxiliary models to use and how heavily to weight their actions becomes a new hyper-parameter that future work would need to tune systematically.
Load-bearing premise
The approach assumes that actions drawn from the external auxiliary models are reliably higher quality and less biased than the actions the policy model would produce on its own, and that mixing them in does not create new distribution-shift problems that hurt final performance.
What would settle it
An experiment that trains the same base MLLM with and without the external-action infusion on the identical Reason-RFT-CoT benchmark and finds no accuracy gain or a clear drop would falsify the central claim.
Figures




read the original abstract
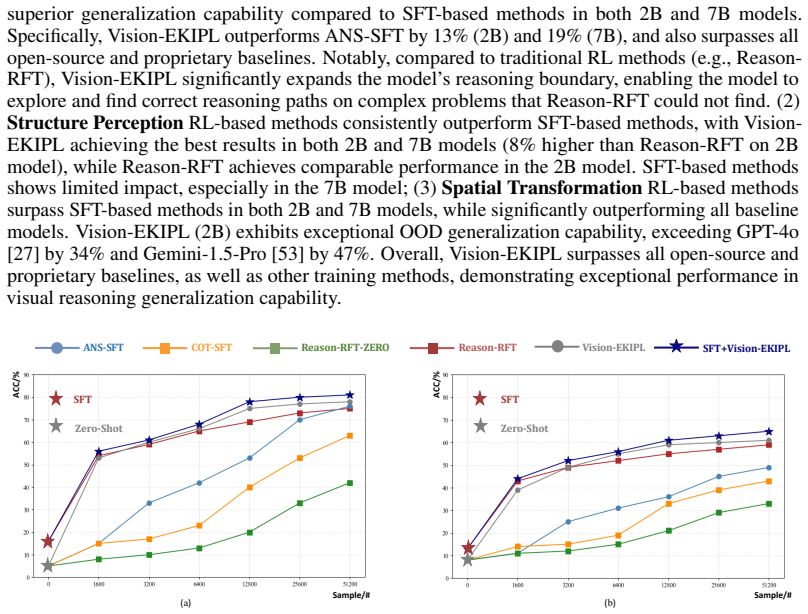
Visual reasoning is crucial for understanding complex multimodal data and advancing Artificial General Intelligence. Existing methods enhance the reasoning capability of Multimodal Large Language Models (MLLMs) through Reinforcement Learning (RL) fine-tuning (e.g., GRPO). However, current RL approaches sample action groups solely from the policy model itself, which limits the upper boundary of the model's reasoning capability and leads to inefficient training. To address these limitations, this paper proposes a novel RL framework called \textbf{Vision-EKIPL}. The core of this framework lies in introducing high-quality actions generated by external auxiliary models during the RL training process to guide the optimization of the policy model. The policy learning with knowledge infusion from external models significantly expands the model's exploration space, effectively improves the reasoning boundary, and substantially accelerates training convergence speed and efficiency. Experimental results demonstrate that our proposed Vision-EKIPL achieved up to a 5\% performance improvement on the Reason-RFT-CoT Benchmark compared to the state-of-the-art (SOTA). It reveals that Vision-EKIPL can overcome the limitations of traditional RL methods, significantly enhance the visual reasoning performance of MLLMs, and provide a new effective paradigm for research in this field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Vision-EKIPL, a novel RL framework for enhancing visual reasoning in MLLMs. It modifies standard GRPO-style training by infusing high-quality actions sampled from external auxiliary models to expand the policy's exploration space, raise the reasoning boundary, accelerate convergence, and deliver up to 5% gains on the Reason-RFT-CoT Benchmark relative to prior SOTA methods.
Significance. If the performance lift is shown to arise specifically from superior action quality rather than increased sample diversity, and if the method generalizes without introducing new distribution-shift artifacts, the work would supply a practical new paradigm for external-knowledge infusion in RL fine-tuning of multimodal models. This could meaningfully advance visual reasoning capabilities and provide a reusable template for other MLLM reasoning tasks.
major comments (3)
- [§3.2] §3.2 (Knowledge Infusion Mechanism): The central assumption that actions from external auxiliary models are systematically higher-quality and less biased than those generated by the policy itself is stated without any quantitative verification, such as reward histograms, error typology comparisons, or bias metrics between the two sources.
- [§4.2] §4.2 (Ablation Experiments): No ablation on the mixing ratio of external versus policy-generated actions is presented; without this, it is impossible to isolate whether the reported 5% gain on Reason-RFT-CoT stems from action quality or simply from greater sample diversity.
- [§4.3] §4.3 (Failure-Mode Analysis): The manuscript provides no examination of whether the external auxiliary models share the same visual-reasoning failure modes as the policy model; correlated errors would undermine the claim that infusion genuinely improves the reasoning boundary rather than merely increasing variance.
minor comments (2)
- [Abstract] Abstract: The phrase 'up to 5% performance improvement' should be accompanied by the precise metric (accuracy, F1, etc.) and the exact baseline model for transparency.
- [§3] Notation: The distinction between 'action groups' sampled from the policy versus those infused from auxiliaries is introduced without a clear mathematical definition or pseudocode in the methods section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and have revised the manuscript to incorporate additional analyses where feasible.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Knowledge Infusion Mechanism): The central assumption that actions from external auxiliary models are systematically higher-quality and less biased than those generated by the policy itself is stated without any quantitative verification, such as reward histograms, error typology comparisons, or bias metrics between the two sources.
Authors: We agree that direct quantitative verification strengthens the central claim. In the revised manuscript we have added reward histograms and an error typology comparison between external auxiliary actions and policy-generated actions within Section 3.2. These results show that external actions receive higher average rewards and display distinct error patterns, particularly fewer visual grounding mistakes. revision: yes
-
Referee: [§4.2] §4.2 (Ablation Experiments): No ablation on the mixing ratio of external versus policy-generated actions is presented; without this, it is impossible to isolate whether the reported 5% gain on Reason-RFT-CoT stems from action quality or simply from greater sample diversity.
Authors: The referee is correct that an explicit mixing-ratio ablation is needed to separate quality from diversity effects. We have performed and included this ablation in the revised Section 4.2, testing ratios from 0 % to 100 % external actions. The results indicate that gains scale with the proportion of external actions up to an optimum, supporting that superior action quality is the primary driver rather than diversity alone. revision: yes
-
Referee: [§4.3] §4.3 (Failure-Mode Analysis): The manuscript provides no examination of whether the external auxiliary models share the same visual-reasoning failure modes as the policy model; correlated errors would undermine the claim that infusion genuinely improves the reasoning boundary rather than merely increasing variance.
Authors: We acknowledge the value of examining failure-mode overlap. The revised Section 4.3 now contains a categorized error analysis on the Reason-RFT-CoT benchmark. While partial overlap exists in multi-step reasoning failures, the external models exhibit complementary strengths in visual perception, resulting in a measurable expansion of the effective reasoning boundary beyond what increased variance alone would produce. revision: yes
Circularity Check
No circularity: empirical framework proposal with independent experimental validation
full rationale
The paper proposes Vision-EKIPL, a new RL framework that infuses high-quality actions from external auxiliary models into GRPO-style policy optimization for visual reasoning in MLLMs. The central claim of up to 5% improvement on Reason-RFT-CoT is presented as an empirical outcome from experiments, not as a mathematical derivation or fitted quantity renamed as a prediction. No equations, self-definitional loops, uniqueness theorems from prior self-work, or ansatzes smuggled via self-citation appear in the abstract or described method. The derivation chain remains self-contained: the method is introduced as novel, its benefits are asserted descriptively, and support rests on benchmark comparisons rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Vision-EKIPL samples high-quality action groups from the action sets of the external models and the policy model based on reward function (RF) evaluation, and then optimizes the policy model using the high-quality action group through the GRPO algorithm.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The policy learning with knowledge infusion from external models significantly expands the model's exploration space, effectively improves the reasoning boundary
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
AdaTooler-V: Adaptive Tool-Use for Images and Videos
AdaTooler-V trains MLLMs to adaptively use vision tools via AT-GRPO reinforcement learning and new datasets, reaching 89.8% on V* and outperforming GPT-4o.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Pravesh Agrawal, Szymon Antoniak, Emma Bou Hanna, Baptiste Bout, Devendra Chaplot, Jessica Chudnovsky, Diogo Costa, Baudouin De Monicault, Saurabh Garg, Theophile Gervet, et al. Pixtral 12b. arXiv preprint arXiv:2410.07073, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Neuro- symbolic visual reasoning: Disentangling
Saeed Amizadeh, Hamid Palangi, Alex Polozov, Yichen Huang, and Kazuhito Koishida. Neuro- symbolic visual reasoning: Disentangling. In International Conference on Machine Learning , pages 279–290. Pmlr, 2020
work page 2020
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 10
work page 2024
-
[8]
Towards neuro-symbolic video understanding
Minkyu Choi, Harsh Goel, Mohammad Omama, Yunhao Yang, Sahil Shah, and Sandeep Chinchali. Towards neuro-symbolic video understanding. InEuropean Conference on Computer Vision, pages 220–236. Springer, 2024
work page 2024
-
[9]
Deep reinforcement learning from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017
work page 2017
-
[10]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In IEEE conference on computer vision and pattern recognition , pages 3213–3223, 2016
work page 2016
-
[11]
Insight-v: Exploring long-chain visual reasoning with multimodal large language models
Yuhao Dong, Zuyan Liu, Hai-Long Sun, Jingkang Yang, Winston Hu, Yongming Rao, and Ziwei Liu. Insight-v: Exploring long-chain visual reasoning with multimodal large language models. arXiv preprint arXiv:2411.14432, 2024
-
[12]
G-llava: Solving geometric problem with multi-modal large language model
Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing Hong, Jianhua Han, Hang Xu, Zhenguo Li, et al. G-llava: Solving geometric problem with multi-modal large language model. arXiv preprint arXiv:2312.11370, 2023
-
[13]
Artur d’Avila Garcez, Marco Gori, Luis C Lamb, Luciano Serafini, Michael Spranger, and Son N Tran. Neural-symbolic computing: An effective methodology for principled integration of machine learning and reasoning. arXiv preprint arXiv:1905.06088, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Visual programming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. In IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 14953–14962, 2023
work page 2023
-
[17]
Tla: Tactile-language-action model for contact-rich manipulation
Peng Hao, Chaofan Zhang, Dingzhe Li, Xiaoge Cao, Xiaoshuai Hao, Shaowei Cui, and Shuo Wang. Tla: Tactile-language-action model for contact-rich manipulation. arXiv preprint arXiv:2503.08548, 2025
-
[18]
Xiaoshuai Hao, Ruikai Li, Hui Zhang, Dingzhe Li, Rong Yin, Sangil Jung, Seung-In Park, ByungIn Yoo, Haimei Zhao, and Jing Zhang. Mapdistill: Boosting efficient camera-based hd map construction via camera-lidar fusion model distillation. In European Conference on Computer Vision, pages 166–183, 2024
work page 2024
-
[19]
Xiaoshuai Hao, Mengchuan Wei, Yifan Yang, Haimei Zhao, Hui Zhang, Yi Zhou, Qiang Wang, Weiming Li, Lingdong Kong, and Jing Zhang. Is your HD map constructor reliable under sensor corruptions? In Advances in Neural Information Processing Systems , 2024
work page 2024
-
[20]
Mbfusion: A new multi-modal bev feature fusion method for hd map construction
Xiaoshuai Hao, Hui Zhang, Yifan Yang, Yi Zhou, Sangil Jung, Seung-In Park, and ByungIn Yoo. Mbfusion: A new multi-modal bev feature fusion method for hd map construction. In IEEE International Conference on Robotics and Automation , pages 15922–15928, 2024
work page 2024
-
[21]
Mapfusion: A novel bev feature fusion network for multi-modal map construction
Xiaoshuai Hao, Yunfeng Diao, Mengchuan Wei, Yifan Yang, Peng Hao, Rong Yin, Hui Zhang, Weiming Li, Shu Zhao, and Yu Liu. Mapfusion: A novel bev feature fusion network for multi-modal map construction. Information Fusion, page 103018, 2025
work page 2025
-
[22]
Transformation driven visual reasoning
Xin Hong, Yanyan Lan, Liang Pang, Jiafeng Guo, and Xueqi Cheng. Transformation driven visual reasoning. In IEEE/CVF Conference on computer vision and pattern recognition , pages 6903–6912, 2021. 11
work page 2021
-
[23]
Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning
Yingdong Hu, Fanqi Lin, Tong Zhang, Li Yi, and Yang Gao. Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning. arXiv preprint arXiv:2311.17842 , 2023
-
[24]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models. arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
open-r1: Fully open reproduction of deepseek-r1
Huggingface. open-r1: Fully open reproduction of deepseek-r1. https://github.com/ huggingface/open-r1, 2025. [Online; accessed: 2025-01-24]
work page 2025
-
[26]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jia- jun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Advlora: Adversarial low-rank adaptation of vision- language models
Yuheng Ji, Yue Liu, Zhicheng Zhang, Zhao Zhang, Yuting Zhao, Gang Zhou, Xingwei Zhang, Xinwang Liu, and Xiaolong Zheng. Advlora: Adversarial low-rank adaptation of vision- language models. arXiv preprint arXiv:2404.13425, 2024
-
[29]
Robobrain: A unified brain model for robotic manipulation from abstract to concrete
Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, et al. Robobrain: A unified brain model for robotic manipulation from abstract to concrete. arXiv preprint arXiv:arXiv:2502.21257, 2025
-
[30]
Inferring and executing programs for visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Judy Hoffman, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Inferring and executing programs for visual reasoning. In IEEE international conference on computer vision , pages 2989–2998, 2017
work page 2017
-
[31]
Geomverse: A systematic evaluation of large models for geometric reasoning
Mehran Kazemi, Hamidreza Alvari, Ankit Anand, Jialin Wu, Xi Chen, and Radu Soricut. Geomverse: A systematic evaluation of large models for geometric reasoning. arXiv preprint arXiv:2312.12241, 2023
-
[32]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In European Conference on Computer Vision, pages 235–251, 2016
work page 2016
-
[33]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[35]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
What foundation models can bring for robot learning in manipulation: A survey
Dingzhe Li, Yixiang Jin, Yuhao Sun, Hongze Yu, Jun Shi, Xiaoshuai Hao, Peng Hao, Huaping Liu, Fuchun Sun, Jianwei Zhang, et al. What foundation models can bring for robot learning in manipulation: A survey. arXiv preprint arXiv:2404.18201, 2024
-
[37]
Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning
Zhuowan Li, Xingrui Wang, Elias Stengel-Eskin, Adam Kortylewski, Wufei Ma, Benjamin Van Durme, and Alan L Yuille. Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning. In IEEE/CVF conference on computer vision and pattern recognition , pages 14963–14973, 2023
work page 2023
-
[38]
Clevr-math: A dataset for compositional language, visual and mathematical reasoning
Adam Dahlgren Lindström and Savitha Sam Abraham. Clevr-math: A dataset for compositional language, visual and mathematical reasoning. arXiv preprint arXiv:2208.05358, 2022. 12
-
[39]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning. arXiv preprint arXiv:2503.01785, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems , pages 2507–2521, 2022
work page 2022
-
[41]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Llama 3 at connect 2024: Vision for edge and mobile devices, 2024
Meta AI. Llama 3 at connect 2024: Vision for edge and mobile devices, 2024. URL https:// ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/ . Ac- cessed: 2025-02-15
work page 2024
-
[43]
OpenAI. Learning to reason with llms. https://openai.com/index/ learning-to-reason-with-llms/ , 2024. Accessed: 2025-03-02
work page 2024
-
[44]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems , 35:27730–27744, 2022
work page 2022
-
[45]
arXiv preprint arXiv:2502.19634 (2025)
Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. arXiv preprint arXiv:2502.19634, 2025
-
[46]
Image processing: the fundamentals
Maria MP Petrou and Costas Petrou. Image processing: the fundamentals . John Wiley & Sons, 2010
work page 2010
-
[47]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Math-llava: Bootstrapping mathematical reasoning for multimodal large language models
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See-Kiong Ng, Lidong Bing, and Roy Ka-Wei Lee. Math-llava: Bootstrapping mathematical reasoning for multimodal large language models. arXiv preprint arXiv:2406.17294, 2024
-
[49]
Mastering the game of go without human knowledge
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017
work page 2017
-
[50]
Aligning Large Multimodal Models with Factually Augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually augmented rlhf. arXiv preprint arXiv:2309.14525, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. In IEEE/CVF International Conference on Computer Vision, pages 11888–11898, 2023
work page 2023
-
[52]
Reason- 14 rft: Reinforcement fine-tuning for visual reasoning.arXiv preprint arXiv:2503.20752, 2025
Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Minglan Lin, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Reason-rft: Reinforcement fine-tuning for visual reasoning. arXiv preprint arXiv:2503.20752, 2025
-
[53]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Llamav-o1: Rethinking step-by-step visual reasoning in llms
Omkar Thawakar, Dinura Dissanayake, Ketan More, Ritesh Thawkar, Ahmed Heakl, Noor Ahsan, Yuhao Li, Mohammed Zumri, Jean Lahoud, Rao Muhammad Anwer, et al. Llamav-o1: Rethinking step-by-step visual reasoning in llms. arXiv preprint arXiv:2501.06186, 2025
-
[56]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems , pages 24824–24837, 2022
work page 2022
-
[59]
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Guowei Xu, Peng Jin, Li Hao, Yibing Song, Lichao Sun, and Li Yuan. Llava-o1: Let vision language models reason step-by-step. arXiv preprint arXiv:2411.10440, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. arXiv preprint arXiv:2412.14171, 2024
-
[62]
Internlm-math: Open math large language models toward verifiable reasoning
Huaiyuan Ying, Shuo Zhang, Linyang Li, Zhejian Zhou, Yunfan Shao, Zhaoye Fei, Yichuan Ma, Jiawei Hong, Kuikun Liu, Ziyi Wang, et al. Internlm-math: Open math large language models toward verifiable reasoning. arXiv preprint arXiv:2402.06332, 2024
-
[63]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13807–13816, 2024
work page 2024
-
[64]
Rlaif-v: Aligning mllms through open-source ai feedback for super gpt-4v trustworthiness
Tianyu Yu, Haoye Zhang, Yuan Yao, Yunkai Dang, Da Chen, Xiaoman Lu, Ganqu Cui, Taiwen He, Zhiyuan Liu, Tat-Seng Chua, et al. Rlaif-v: Aligning mllms through open-source ai feedback for super gpt-4v trustworthiness. arXiv preprint arXiv:2405.17220, 2024
-
[65]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models. arXiv preprint arXiv:2407.12772, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Take a step back: Rethinking the two stages in visual reasoning
Mingyu Zhang, Jiting Cai, Mingyu Liu, Yue Xu, Cewu Lu, and Yong-Lu Li. Take a step back: Rethinking the two stages in visual reasoning. In European Conference on Computer Vision, pages 124–141. Springer, 2024
work page 2024
-
[68]
Mavis: Mathematical visual instruction tuning with an automatic data engine
Renrui Zhang, Xinyu Wei, Dongzhi Jiang, Ziyu Guo, Shicheng Li, Yichi Zhang, Chengzhuo Tong, Jiaming Liu, Aojun Zhou, Bin Wei, et al. Mavis: Mathematical visual instruction tuning with an automatic data engine. arXiv preprint arXiv:2407.08739, 2024
-
[69]
o1-coder: an o1 replication for coding
Yuxiang Zhang, Shangxi Wu, Yuqi Yang, Jiangming Shu, Jinlin Xiao, Chao Kong, and Jitao Sang. o1-coder: an o1 replication for coding. arXiv preprint arXiv:2412.00154, 2024
-
[70]
Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
Zhiyuan Zhao, Bin Wang, Linke Ouyang, Xiaoyi Dong, Jiaqi Wang, and Conghui He. Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization. arXiv preprint arXiv:2311.16839, 2023. 14
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.