Mobile-R1: Towards Interactive Capability for VLM-Based Mobile Agent via Systematic Training
Pith reviewed 2026-05-19 08:22 UTC · model grok-4.3
The pith
A three-stage hierarchical curriculum trains vision-language models to explore mobile screens and correct their own errors more effectively than prior offline methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
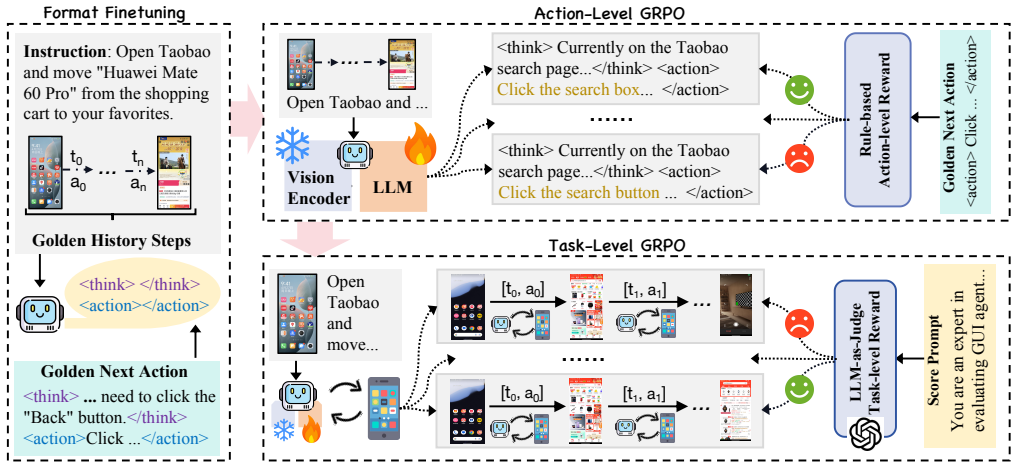
Mobile-R1 bridges atomic action execution and strategic task completion through a hierarchical curriculum of three stages: format alignment for reasoning structure, on-policy exploration with verifiable action feedback to ground basic execution, and multi-turn task-level training inside a realistic environment. This sequence bootstraps the agent and produces improved exploration together with self-correction capabilities that prior offline or local-reward approaches lacked.
What carries the argument
The three-stage hierarchical curriculum that progressively moves from reasoning alignment to grounded on-policy exploration to full task-level training with environment feedback.
If this is right
- Agents gain the ability to recover from mistakes during long GUI sequences rather than repeating failed actions.
- The method reduces reliance on large amounts of pre-collected offline trajectories for effective training.
- A publicly released Chinese GUI dataset and benchmark enable evaluation of agents in non-English mobile ecosystems.
- The approach can be applied to other VLM-based agents that interact with structured screen environments.
Where Pith is reading between the lines
- Similar staged curricula could be tested on web or desktop interfaces where feedback is also sparse.
- Combining the method with larger base models might further amplify the observed self-correction gains.
- The open-sourced resources could serve as a shared testbed for comparing interactive training recipes across research groups.
Load-bearing premise
On-policy exploration with verifiable action feedback plus multi-turn task training in a realistic environment will produce better exploration and error correction than offline or local-reward training without introducing new convergence or overfitting problems.
What would settle it
If agents trained with the full three-stage curriculum show no reduction in local-optima failures compared with agents trained only on the first two stages when evaluated on the 500-trajectory benchmark, the added value of the final multi-turn stage would be falsified.
Figures













read the original abstract
Vision-language model-based mobile agents have gained the ability to understand complex instructions and mobile screenshots, benefiting from reinforcement learning paradigms like Group Relative Policy Optimization (GRPO). However, existing approaches centers on offline training or local action-level rewards often trap agents in local optima, hindering effective exploration and error correction with the environment. Crucially, we find that directly applying task-level rewards often leads to convergence difficulties due to the sparse nature of GUI interactions. To address these challenges, we present \textbf{Mobile-R1}, a systematic training recipe that bridges atomic action execution and strategic task completion. We propose a hierarchical curriculum consisting of three stages: (1) format alignment for reasoning structure, (2) on-policy exploration with verifiable action feedback to ground basic execution, and (3) multi-turn task-level training with realistic environment to unlock exploration and self-correction. This hierarchical strategy effectively bootstraps the agent, significantly enhancing its capability for exploration and self-correction (the ``Eureka'' moments). Furthermore, addressing the critical scarcity of diverse GUI data in non-English ecosystems, we contribute a comprehensive Chinese mobile dataset covering 28 applications with 24,521 high-quality manual annotations, and establish a rigorous benchmark with 500 trajectories. We will open source all resources, including the dataset, benchmark, model weight, and codes: https://mobile-r1.github.io/Mobile-R1/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Mobile-R1, a hierarchical training recipe for VLM-based mobile agents consisting of three stages: (1) format alignment for reasoning structure, (2) on-policy exploration with verifiable action feedback to ground basic execution, and (3) multi-turn task-level training with realistic environment feedback. It claims this curriculum addresses limitations of offline training and local action-level rewards (local optima, sparse GUI interactions causing convergence issues) and unlocks improved exploration and self-correction ('Eureka' moments). The work also contributes a Chinese mobile GUI dataset covering 28 applications with 24,521 high-quality manual annotations and establishes a benchmark with 500 trajectories, with all resources to be open-sourced.
Significance. If the empirical results and ablations confirm that the three-stage curriculum produces measurably superior exploration and error-correction behavior without introducing instability or dataset-specific overfitting, the work would provide a practical, reproducible training recipe for interactive mobile agents and help address data scarcity in non-English GUI settings. The open-sourcing of the dataset, benchmark, model weights, and code would further strengthen its utility for the community.
major comments (3)
- [Abstract and method description] The central claim that the hierarchical strategy 'effectively bootstraps the agent, significantly enhancing its capability for exploration and self-correction' is load-bearing yet unsupported by any quantitative results, ablation studies isolating stage 3, training dynamics, variance metrics, or error analysis on the 500-trajectory benchmark. The abstract and method description provide no evidence that multi-turn task-level training reliably avoids the convergence difficulties or overfitting risks noted for direct task-level rewards.
- [Introduction and proposed approach] The assertion that 'directly applying task-level rewards often leads to convergence difficulties due to the sparse nature of GUI interactions' is presented without supporting data such as learning curves, success rates across stages, or comparisons to prior offline/local-reward baselines. This leaves the motivation for the specific three-stage ordering unverified.
- [Experiments and evaluation] No metrics are reported on self-correction frequency, exploration efficiency, or robustness to the 24,521 Chinese annotations that would demonstrate stage 3's contribution to 'Eureka' moments or rule out new convergence failures.
minor comments (2)
- [Method] A diagram or pseudocode outlining the transitions, reward signals, and data flow between the three stages would improve clarity of the curriculum.
- [Implementation details] The manuscript should explicitly state the base VLM, exact hyperparameters for each stage, and how on-policy exploration is implemented to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential utility of our hierarchical training recipe and the Chinese GUI dataset. We agree that the central claims regarding improved exploration and self-correction require stronger quantitative support, and we will revise the manuscript accordingly to address the identified gaps in evidence.
read point-by-point responses
-
Referee: [Abstract and method description] The central claim that the hierarchical strategy 'effectively bootstraps the agent, significantly enhancing its capability for exploration and self-correction' is load-bearing yet unsupported by any quantitative results, ablation studies isolating stage 3, training dynamics, variance metrics, or error analysis on the 500-trajectory benchmark. The abstract and method description provide no evidence that multi-turn task-level training reliably avoids the convergence difficulties or overfitting risks noted for direct task-level rewards.
Authors: We acknowledge that the abstract and method sections would benefit from more explicit quantitative backing for the load-bearing claims. While the full paper reports overall benchmark improvements from the full curriculum, we agree that isolating stage 3's contribution and providing supporting analyses are necessary. In the revision we will add: (i) ablation studies comparing the three-stage curriculum against a two-stage variant (omitting multi-turn task-level training), (ii) training dynamics and variance metrics across multiple runs on the 500-trajectory benchmark, and (iii) an error analysis quantifying self-correction events. We will also include a brief discussion of observed convergence behavior under direct task-level rewards versus the staged approach. revision: yes
-
Referee: [Introduction and proposed approach] The assertion that 'directly applying task-level rewards often leads to convergence difficulties due to the sparse nature of GUI interactions' is presented without supporting data such as learning curves, success rates across stages, or comparisons to prior offline/local-reward baselines. This leaves the motivation for the specific three-stage ordering unverified.
Authors: We agree that empirical motivation for the three-stage ordering should be strengthened with data. In the revised manuscript we will insert learning curves and per-stage success rates that compare direct task-level reward training against our staged curriculum, together with comparisons to the offline and local-reward baselines used in prior work. These additions will directly illustrate the convergence issues that motivated the hierarchical design. revision: yes
-
Referee: [Experiments and evaluation] No metrics are reported on self-correction frequency, exploration efficiency, or robustness to the 24,521 Chinese annotations that would demonstrate stage 3's contribution to 'Eureka' moments or rule out new convergence failures.
Authors: We thank the referee for highlighting this omission. The current evaluation emphasizes aggregate task success; we will augment the Experiments section with quantitative metrics including self-correction frequency (fraction of trajectories exhibiting successful recovery after an error), exploration efficiency (unique GUI states or actions visited per episode), and an analysis of performance robustness across the 24,521 Chinese annotations. These metrics will be reported both for the full curriculum and for ablated variants to isolate stage 3's role. revision: yes
Circularity Check
No significant circularity; empirical training recipe with external data
full rationale
The paper describes a three-stage hierarchical curriculum (format alignment, on-policy verifiable-action exploration, multi-turn task-level training) as an empirical training strategy that relies on external environment feedback, a newly contributed dataset of 24,521 Chinese GUI annotations across 28 apps, and a 500-trajectory benchmark. No equations, fitted parameters, or performance metrics are shown to reduce by construction to the target results; the central claim about bootstrapping exploration and self-correction is presented as an outcome of the training process evaluated on independent resources rather than a self-referential derivation. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way within the provided text.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage training process: format finetuning, action-level GRPO training, and task-level GRPO training
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-turn task-level training with realistic environment to unlock exploration and self-correction
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Turing Test on Screen: A Benchmark for Mobile GUI Agent Humanization
The work creates a new benchmark for humanizing GUI agent touch dynamics via a MinMax detector-agent model, a mobile touch dataset, and methods showing agents can match human behavior without losing task performance.
-
InquireMobile: Teaching VLM-based Mobile Agent to Request Human Assistance via Reinforcement Fine-Tuning
InquireMobile applies two-stage reinforcement fine-tuning and pre-action reasoning to VLM mobile agents, raising inquiry success rate by 46.8% on the introduced InquireBench benchmark.
-
A Survey of Reinforcement Learning for Large Reasoning Models
A survey compiling RL methods, challenges, data resources, and applications for enhancing reasoning in large language models and large reasoning models since DeepSeek-R1.
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923. Chen, L.; Li, L.; Zhao, H.; Song, Y .; and Vinci. 2025a. R1-V: Reinforcing Super Generalization Ability in Vision- Language Models with Less than $3. Accessed: 2025-02-
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Chen, L.; Li, L.; Zhao, H.; Song, Y .; Vinci; Kong, L.; Liu, Q.; and Chang, B. 2025b. RLVR in Vision Language Mod- els: Findings, Questions and Directions. Notion Post. Chen, P.; Bu, P.; Wang, Y .; Wang, X.; Wang, Z.; Guo, J.; Zhao, Y .; Zhu, Q.; Song, J.; Yang, S.; Wang, J.; and Zheng, B. 2025c. CombatVLA: An Efficient Vision-Language- Action Model for C...
-
[3]
”See the World, Discover Knowledge”: A Chinese Factuality Evaluation for Large Vision Language Models. arXiv:2502.11718. Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; et al
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948. Huang, X.; Liu, W.; Chen, X.; Wang, X.; Wang, H.; Lian, D.; Wang, Y .; Tang, R.; and Chen, E
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Understanding the planning of LLM agents: A survey
Understand- ing the planning of LLM agents: A survey. arXiv preprint arXiv:2402.02716. Li, J.; and Huang, K
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
A summary on gui agents with foundation models enhanced by reinforcement learning,
A Summary on GUI Agents with Foundation Models Enhanced by Reinforcement Learning. arXiv preprint arXiv:2504.20464. Li, W.; Bishop, W.; Li, A.; Rawles, C.; Campbell-Ajala, F.; Tyamagundlu, D.; and Riva, O. 2024a. On the effects of data scale on computer control agents. arXiv e-prints , arXiv–
-
[7]
E.; Li, A.; Rawles, C.; Campbell-Ajala, F.; Tyamagundlu, D.; and Riva, O
Li, W.; Bishop, W. E.; Li, A.; Rawles, C.; Campbell-Ajala, F.; Tyamagundlu, D.; and Riva, O. 2024b. On the effects of data scale on ui control agents. Advances in Neural Infor- mation Processing Systems, 37: 92130–92154. Li, Y .; Zhang, C.; Yang, W.; Fu, B.; Cheng, P.; Chen, X.; Chen, L.; and Wei, Y . 2024c. Appagent v2: Ad- vanced agent for flexible mobi...
-
[8]
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Showui: One vision- language-action model for gui visual agent. In Proceedings of the Computer Vision and Pattern Recognition Conference, 19498–19508. Liu, Y .; Li, P.; Xie, C.; Hu, X.; Han, X.; Zhang, S.; Yang, H.; and Wu, F. 2025a. InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reason- ers. arXiv:2504.14239. Liu, Z.; Su...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2406.08451
Gui odyssey: A comprehensive dataset for cross-app gui navigation on mo- bile devices. arXiv preprint arXiv:2406.08451. Lu, Z.; Chai, Y .; Guo, Y .; Yin, X.; Liu, L.; Wang, H.; Xiao, H.; Ren, S.; Xiong, G.; and Li, H. 2025b. Ui-r1: Enhancing action prediction of gui agents by reinforcement learning. arXiv preprint arXiv:2503.21620. Luo, R.; Wang, L.; He, ...
-
[10]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents. arXiv:2504.10458. Nguyen, D.; Chen, J.; Wang, Y .; Wu, G.; Park, N.; Hu, Z.; Lyu, H.; Wu, J.; Aponte, R.; Xia, Y .; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Gui agents: A survey. arXiv preprint arXiv:2412.13501. OpenAI, R
-
[12]
Gpt-4 technical report. arxiv 2303.08774. View in Article, 2(5). Peng, Y .; Wang, X.; Wei, Y .; Pei, J.; Qiu, W.; Jian, A.; Hao, Y .; Pan, J.; Xie, T.; Ge, L.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2504.05599
Skywork r1v: Pio- neering multimodal reasoning with chain-of-thought. arXiv preprint arXiv:2504.05599. Putta, P.; Mills, E.; Garg, N.; Motwani, S.; Finn, C.; Garg, D.; and Rafailov, R
-
[14]
Agent q: Advanced reasoning and learning for autonomous ai agents
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents. arXiv:2408.07199. Qin, Y .; Ye, Y .; Fang, J.; Wang, H.; Liang, S.; Tian, S.; Zhang, J.; Li, J.; Li, Y .; Huang, S.; et al
-
[15]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
UI-TARS: Pioneering Automated GUI Interaction with Native Agents. arXiv preprint arXiv:2501.12326. Shao, Y .; Li, L.; Dai, J.; and Qiu, X
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2310.10158
Character- llm: A trainable agent for role-playing. arXiv preprint arXiv:2310.10158. Shao, Z.; Wang, P.; Zhu, Q.; Xu, R.; Song, J.; Bi, X.; Zhang, H.; Zhang, M.; Li, Y .; Wu, Y .; et al
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open lan- guage models. arXiv preprint arXiv:2402.03300. Sun, Q.; Cheng, K.; Ding, Z.; Jin, C.; Wang, Y .; Xu, F.; Wu, Z.; Jia, C.; Chen, L.; Liu, Z.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Os-genesis: Automating gui agent trajectory construction via reverse task synthesis
OS-Genesis: Au- tomating GUI Agent Trajectory Construction via Reverse Task Synthesis. arXiv preprint arXiv:2412.19723. Wang, J.; Xu, H.; Jia, H.; Zhang, X.; Yan, M.; Shen, W.; Zhang, J.; Huang, F.; and Sang, J. 2024a. Mobile- agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration. arXiv preprint arXiv:2406.010...
-
[19]
Mobile-agent-e: Self-evolving mobile assistant for complex tasks
Mobile-Agent-E: Self- Evolving Mobile Assistant for Complex Tasks. arXiv preprint arXiv:2501.11733. Wanyan, Y .; Zhang, X.; Xu, H.; and et al
-
[20]
arXiv preprint arXiv:2506.04614
Look Be- fore You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation. arXiv preprint arXiv:2506.04614. Wu, Z.; Wu, Z.; Xu, F.; Wang, Y .; Sun, Q.; Jia, C.; Cheng, K.; Ding, Z.; Chen, L.; Liang, P. P.; et al
-
[21]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Os-atlas: A foundation action model for generalist gui agents. arXiv preprint arXiv:2410.23218. Xu, Y .; Wang, Z.; Wang, J.; Lu, D.; Xie, T.; Saha, A.; Sa- hoo, D.; Yu, T.; and Xiong, C
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Aguvis: Unified pure vision agents for autonomous gui interaction. arXiv preprint arXiv:2412.04454. Yang, Y .; He, X.; Pan, H.; Jiang, X.; Deng, Y .; Yang, X.; Lu, H.; Yin, D.; Rao, F.; Zhu, M.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
R1-onevision: Advancing generalized multimodal reasoning through cross- modal formalization. arXiv preprint arXiv:2503.10615. Yuan, S.; Song, K.; Chen, J.; Tan, X.; Shen, Y .; Kan, R.; Li, D.; and Yang, D
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
arXiv preprint arXiv:2401.06201
Easytool: Enhancing llm- based agents with concise tool instruction. arXiv preprint arXiv:2401.06201. Zhang, C.; Yang, Z.; Liu, J.; Li, Y .; Han, Y .; Chen, X.; Huang, Z.; Fu, B.; and Yu, G. 2025a. Appagent: Multimodal agents as smartphone users. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 1–20. Zhang, Z.; Lu, Y .; Fu,...
-
[25]
R1-Zero's "Aha Moment" in Visual Reasoning on a 2B Non-SFT Model
R1-Zero’s” Aha Moment” in Visual Reasoning on a 2B Non-SFT Model. arXiv preprint arXiv:2503.05132. Limitation From the perspective of training strategy, this paper em- ploys both action-level and task-level rewards to guide the RL training process, allowing the agent to gradually improve its capabilities. However, exploring how to enhance perfor- mance us...
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Specifically, we tracked the model’s tail success ratio as a function of the training steps. As illustrated in Figuree 13, the tail success ratio exhibits a consistent upward trend with the increase in steps. This finding suggests that a more prolonged phase of end-to-end exploration is beneficial for achieving final task success. Figure 13: Robustness An...
work page 2035
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.