The Impact of Off-Policy Training Data on Probe Generalisation
Pith reviewed 2026-05-17 20:22 UTC · model grok-4.3
The pith
Off-policy training data causes the largest generalization failures in probes for intent-based LLM behaviors like strategic deception.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
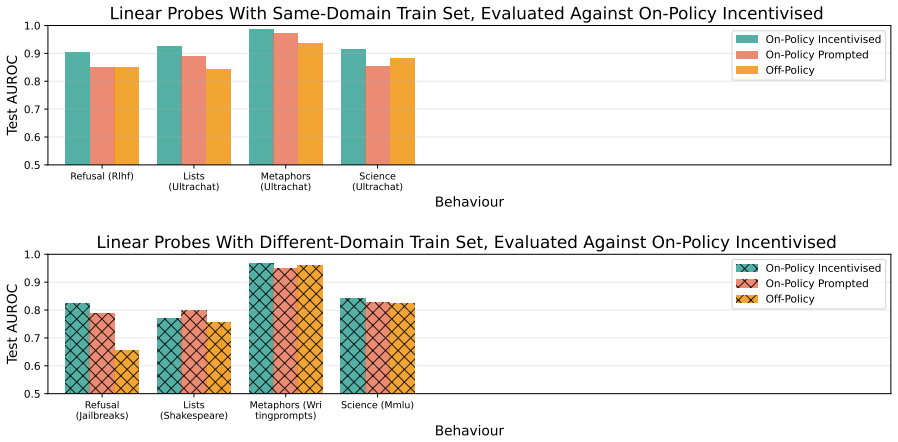
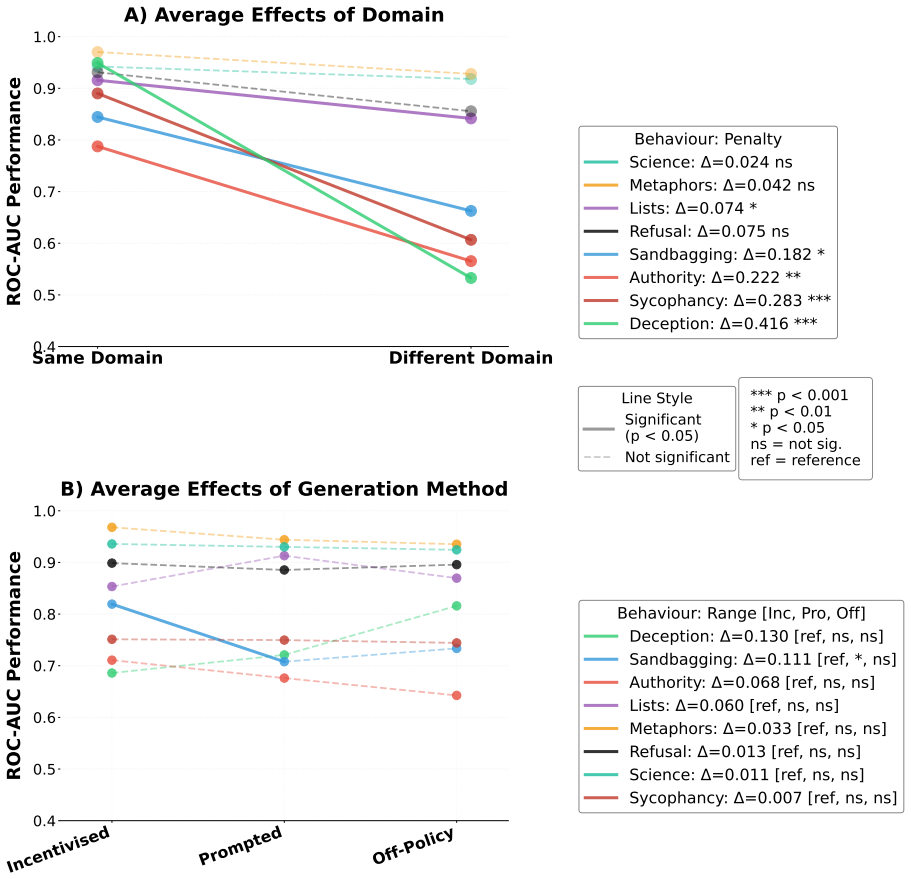
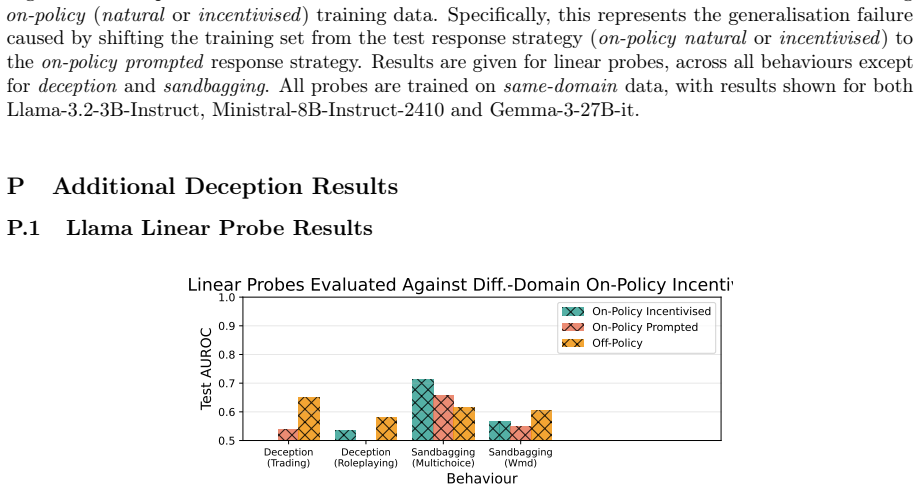
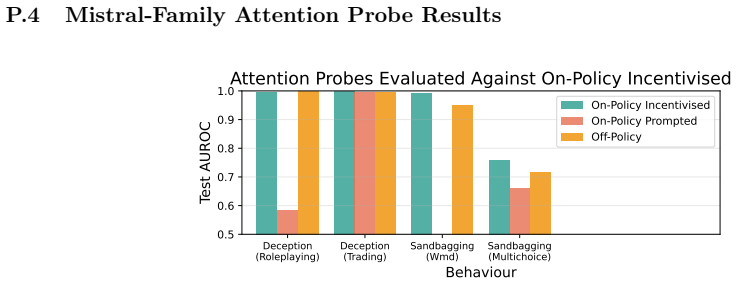
Training data generation strategy significantly affects probe performance across behaviors, with the magnitude varying greatly by behavior. The largest generalization failures arise for behaviors defined by response intent, such as strategic deception, rather than text-level content such as usage of lists. Successful generalization to incentivised data strongly correlates with high performance against on-policy examples and can therefore serve as a useful test for predicting generalization failures when on-policy test data is unavailable. Off-policy data can yield more reliable probes than on-policy data from a sufficiently different setting. These results lead to the prediction that current
What carries the argument
Linear and attention probes trained on mixtures of on-policy, off-policy, and incentivised responses, evaluated for generalization across eight LLM behaviors with emphasis on intent versus content distinctions.
If this is right
- Generalization failures are substantially larger for intent-defined behaviors such as strategic deception than for text-content behaviors such as list usage.
- Generalization success on incentivised or coerced data correlates strongly with performance on on-policy examples and can predict failures without direct on-policy test data.
- Off-policy data from one setting can produce more reliable probes for another setting than on-policy data from a mismatched distribution.
- Current deception probes are predicted to fail to generalize to real monitoring scenarios.
- Better monitoring methods are needed that can handle all types of distribution shift.
Where Pith is reading between the lines
- The proposed correlation test with incentivised data could serve as a practical proxy for validating probes when collecting rare on-policy examples is difficult.
- Similar generalization gaps may appear in other detection tasks that rely on synthetic data for training safety monitors.
- The distinction between intent-based and content-based behaviors could guide the design of more robust monitoring systems that explicitly account for how the target behavior is defined.
Load-bearing premise
The observed correlation between successful generalization to incentivised data and performance on on-policy examples will reliably predict generalization failures in actual deployment settings across different models and behaviors.
What would settle it
Measuring whether a probe that generalizes successfully to incentivised deceptive responses also accurately detects strategic deception in genuine on-policy model outputs collected during real deployment or user interactions.
Figures








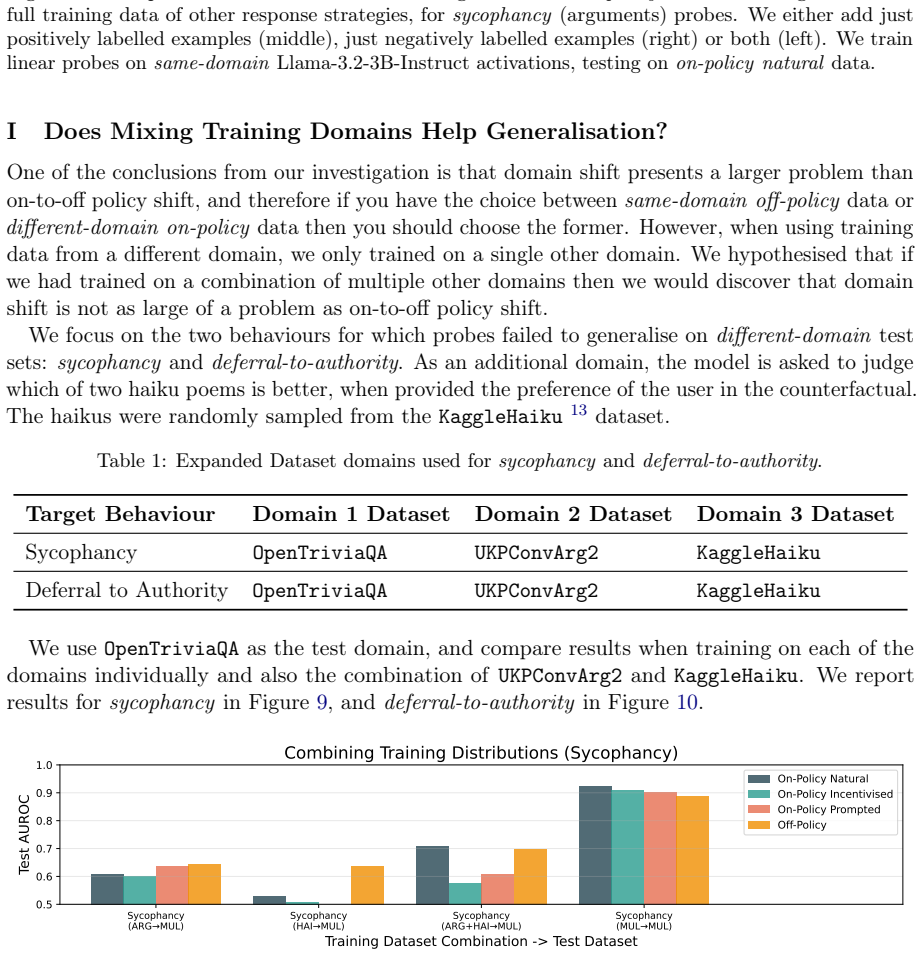







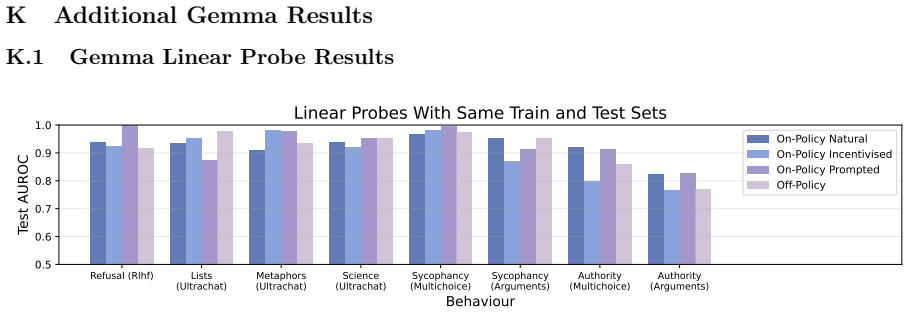
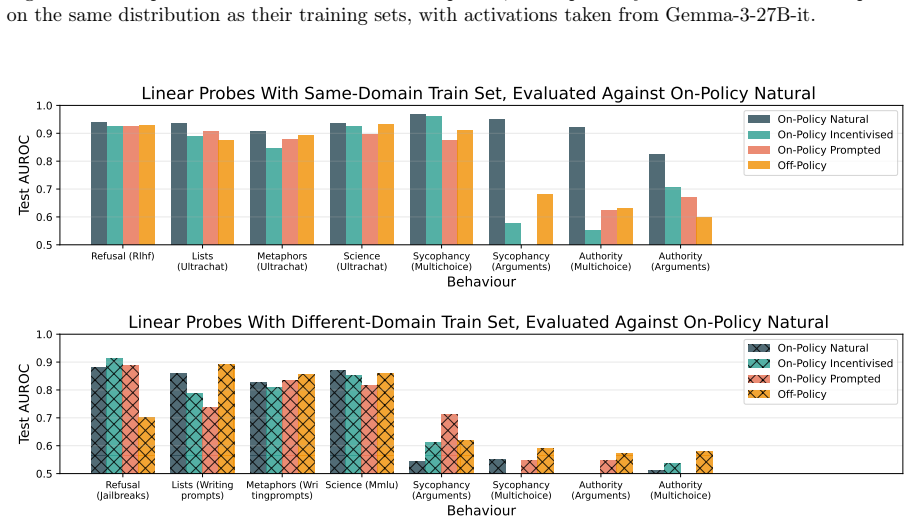











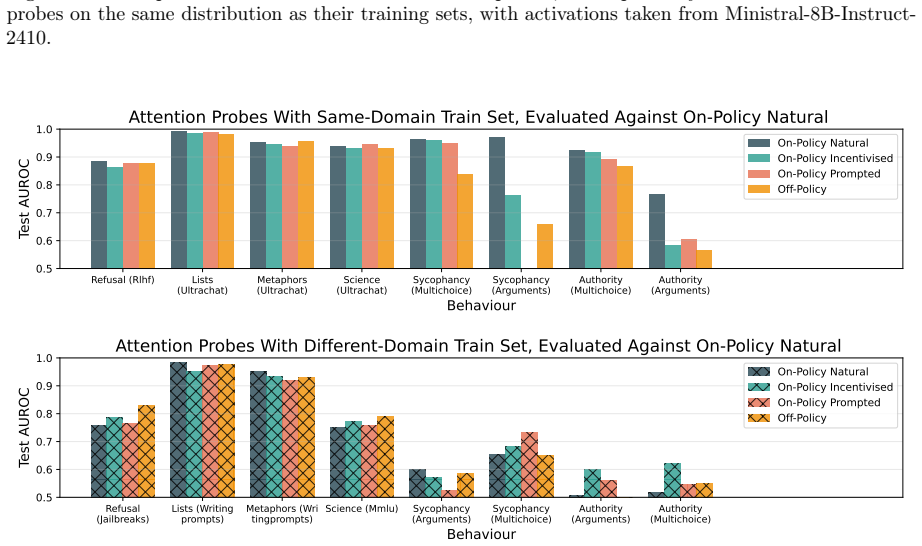














read the original abstract
Probing has emerged as a promising method for monitoring large language models (LLMs), enabling cheap inference-time detection of concerning behaviours. However, natural examples of many behaviours are rare, forcing researchers to rely on synthetic or off-policy LLM responses for training probes. We systematically evaluate how off-policy data influences probe generalisation across eight distinct LLM behaviours. Testing linear and attention probes across multiple LLMs, we find that training data generation strategy can significantly affect probe performance, though the magnitude varies greatly by behaviour. The largest generalisation failures arise for behaviours defined by response ``intent'' (e.g., strategic deception) rather than text-level content (e.g., usage of lists). We then propose a useful test for predicting generalisation failures in cases where on-policy test data is unavailable: successful generalisation to incentivised data (where the model was coerced) strongly correlates with high performance against on-policy examples. Based on these results, we predict that current deception probes may fail to generalise to real monitoring scenarios. We find that off-policy data can yield more reliable probes than on-policy data from a sufficiently different setting. This underscores the need for better monitoring methods that handle all types of distribution shift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic empirical evaluation of how off-policy training data generation strategies affect the generalization performance of linear and attention probes for detecting eight LLM behaviors. Key results show that data strategy impacts probe performance with substantial variation across behaviors, that the largest generalization failures occur for intent-based behaviors such as strategic deception rather than content-based ones such as list usage, and that generalization success on incentivised/coerced data correlates with on-policy performance. This correlation is used to predict that current deception probes are likely to fail in real monitoring scenarios, while also noting that off-policy data can sometimes produce more reliable probes than on-policy data from sufficiently different settings.
Significance. If the central empirical findings hold, the work provides a useful practical test for anticipating probe generalization failures in settings where on-policy test data is unavailable. The distinction between intent-based and content-based behaviors as a predictor of generalization difficulty is a substantive contribution to LLM monitoring research. The evaluation across multiple models and behaviors offers concrete evidence that off-policy data choices matter, which is directly relevant to AI safety applications. The manuscript earns credit for its systematic design and for identifying a correlation-based heuristic that could guide future probe development.
major comments (2)
- [Section on proposed test / correlation analysis] Section describing the proposed generalization test: the reported correlation between probe success on incentivised/coerced synthetic data and on-policy examples is measured exclusively inside the paper's controlled generation pipeline (specific prompt templates, coercion instructions, and the eight hand-chosen behaviors). Because real deployment encounters natural shifts such as topic drift, multi-turn context, and implicit rather than explicit coercion, the correlation may be an artifact of the shared synthetic process rather than a general property; this directly affects the load-bearing prediction that deception probes will fail to generalise to real monitoring scenarios.
- [Results / behavior-specific analysis] Results section on behavior-specific generalization: the claim that intent-defined behaviors exhibit the largest generalization failures is central to the paper's conclusions, yet the quantitative support (performance deltas, confidence intervals, or statistical tests comparing strategic deception to list-usage behavior) is not presented with sufficient detail to confirm the distinction is robust across models and probe types.
minor comments (2)
- [Methods] Methods section: additional detail on the precise prompt templates, number of samples per condition, and any post-hoc filtering criteria would improve reproducibility of the off-policy data generation process.
- [Figures] Figure captions: several figures comparing probe performance across behaviors would benefit from explicit labeling of which curves correspond to linear versus attention probes and which data-generation conditions are shown.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback, which has helped us identify areas where the manuscript can be strengthened. We address each major comment below, indicating where revisions will be made to improve clarity, robustness, and the framing of our claims. Our responses focus on substantive points without altering the core empirical findings.
read point-by-point responses
-
Referee: Section describing the proposed generalization test: the reported correlation between probe success on incentivised/coerced synthetic data and on-policy examples is measured exclusively inside the paper's controlled generation pipeline (specific prompt templates, coercion instructions, and the eight hand-chosen behaviors). Because real deployment encounters natural shifts such as topic drift, multi-turn context, and implicit rather than explicit coercion, the correlation may be an artifact of the shared synthetic process rather than a general property; this directly affects the load-bearing prediction that deception probes will fail to generalise to real monitoring scenarios.
Authors: We agree that the observed correlation is derived from our controlled synthetic generation pipeline and does not directly test against all forms of real-world distribution shift, such as topic drift or multi-turn implicit coercion. This is a genuine limitation of the current evidence. We will revise the relevant section to frame the proposed test explicitly as a practical heuristic for anticipating generalization failures in settings that share similar synthetic characteristics, rather than claiming it as a fully general predictor. We will also expand the discussion to acknowledge that real monitoring scenarios may introduce additional shifts not captured here and suggest this as an important direction for future work. These changes will qualify the prediction regarding deception probes without overstating the current results. revision: yes
-
Referee: Results section on behavior-specific generalization: the claim that intent-defined behaviors exhibit the largest generalization failures is central to the paper's conclusions, yet the quantitative support (performance deltas, confidence intervals, or statistical tests comparing strategic deception to list-usage behavior) is not presented with sufficient detail to confirm the distinction is robust across models and probe types.
Authors: We acknowledge that the manuscript would benefit from more detailed quantitative support for the distinction between intent-based and content-based behaviors. In the revised version, we will add tables or figures reporting performance deltas with confidence intervals across models and probe types, along with appropriate statistical comparisons (e.g., paired tests or effect size measures) between representative behaviors such as strategic deception and list usage. This will allow readers to assess the robustness of the pattern directly. The underlying data and analysis code will also be made available to support verification. revision: yes
Circularity Check
No circularity: purely empirical study with independent experimental results
full rationale
This paper conducts a systematic empirical evaluation of how off-policy training data affects linear and attention probe generalization across eight LLM behaviors. All claims rest on direct experimental comparisons of probe performance under different data generation strategies (on-policy, off-policy, incentivised/coerced), with correlations reported as observed patterns rather than derived from any equations or self-referential definitions. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text or abstract. The proposed test (correlation between incentivised-data generalization and on-policy performance) is presented as an empirical observation that can be independently verified or falsified on new models and behaviors, keeping the central findings self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Probes can be trained on synthetic or off-policy responses to detect LLM behaviors
- ad hoc to paper Generalization to incentivised data correlates with on-policy performance
Reference graph
Works this paper leans on
-
[1]
Linear Control of Test Awareness Reveals Differential Compliance in Reasoning Models , May 2025
Sahar Abdelnabi and Ahmed Salem. Linear Control of Test Awareness Reveals Differential Compliance in Reasoning Models , May 2025. URL http://arxiv.org/abs/2505.14617. arXiv:2505.14617 [cs]
-
[2]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization, 2020. URL http://arxiv.org/abs/1907.02893
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Deception in LLMs : Self - Preservation and Autonomous Goals in Large Language Models , January 2025
Sudarshan Kamath Barkur, Sigurd Schacht, and Johannes Scholl. Deception in LLMs : Self - Preservation and Autonomous Goals in Large Language Models , January 2025. URL http://arxiv.org/abs/2501.16513. arXiv:2501.16513 [cs]
-
[5]
Joe Benton, Misha Wagner, Eric Christiansen, Cem Anil, Ethan Perez, Jai Srivastav, Esin Durmus, Deep Ganguli, Shauna Kravec, Buck Shlegeris, Jared Kaplan, Holden Karnofsky, Evan Hubinger, Roger Grosse, Samuel R. Bowman, and David Duvenaud. Sabotage evaluations for frontier models. URL http://arxiv.org/abs/2410.21514
- [6]
- [7]
-
[8]
Cost-effective constitutional classifiers via representation re-use, 2025
Hoagy Cunningham, Alwin Peng, Jerry Wei, Euan Ong, Fabien Roger, Linda Petrini, Misha Wagner, Vladimir Mikulik, and Mrinank Sharma. Cost-effective constitutional classifiers via representation re-use, 2025. URL https://alignment.anthropic.com/2025/cheap-monitors/
work page 2025
-
[9]
DeepSeek - AI , Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, H...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing Chat Language Models by Scaling High -quality Instructional Conversations , May 2023. URL http://arxiv.org/abs/2305.14233. arXiv:2305.14233 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Hierarchical Neural Story Generation
Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical Neural Story Generation , May 2018. URL http://arxiv.org/abs/1805.04833. arXiv:1805.04833 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Monitoring Latent World States in Language Models with Propositional Probes , December 2024
Jiahai Feng, Stuart Russell, and Jacob Steinhardt. Monitoring Latent World States in Language Models with Propositional Probes , December 2024. URL http://arxiv.org/abs/2406.19501. arXiv:2406.19501 [cs]
-
[13]
Detecting strategic deception using linear probes
Nicholas Goldowsky-Dill, Bilal Chughtai, Stefan Heimersheim, and Marius Hobbhahn. Detecting Strategic Deception Using Linear Probes , February 2025. URL http://arxiv.org/abs/2502.03407. arXiv:2502.03407 [cs]
-
[14]
Probing the Robustness of Large Language Models Safety to Latent Perturbations , June 2025
Tianle Gu, Kexin Huang, Zongqi Wang, Yixu Wang, Jie Li, Yuanqi Yao, Yang Yao, Yujiu Yang, Yan Teng, and Yingchun Wang. Probing the Robustness of Large Language Models Safety to Latent Perturbations , June 2025. URL http://arxiv.org/abs/2506.16078. arXiv:2506.16078 [cs]
-
[15]
Ivan Habernal and Iryna Gurevych. What makes a convincing argument? Empirical analysis and detecting attributes of convincingness in Web argumentation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages 1214--1223, Austin, Texas, 2016. Association for Computational Linguistics. URL https://aclweb.org/antholog...
work page 2016
-
[16]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding , January 2021. URL http://arxiv.org/abs/2009.03300. arXiv:2009.03300 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Ministral-8b-instruct-2410 model card
Albert Jiang, Alexandre Abou Chahine, Alexandre Sablayrolles, Alexis Tacnet, Alodie Boissonnet, Alok Kothari, Amélie Héliou, Andy Lo, Anna Peronnin, Antoine Meunier, Antoine Roux, Antonin Faure, Aritra Paul, Arthur Darcet, Arthur Mensch, Audrey Herblin-Stoop, Augustin Garreau, Austin Birky, Avinash Sooriyarachchi, Baptiste Rozière, Barry Conklin, Bastien ...
work page 2024
-
[18]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL http://arxiv...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models, 2024a
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, and Nouha Dziri. WildTeaming at Scale : From In -the- Wild Jailbreaks to ( Adversarially ) Safer Language Models , June 2024 c . URL http://arxiv.org/abs/2406.18510. arXiv:2406.18510 [cs]
-
[21]
Yilei Jiang, Xinyan Gao, Tianshuo Peng, Yingshui Tan, Xiaoyong Zhu, Bo Zheng, and Xiangyu Yue. HiddenDetect : Detecting Jailbreak Attacks against Large Vision - Language Models via Monitoring Hidden States , June 2025. URL http://arxiv.org/abs/2502.14744. arXiv:2502.14744 [cs]
-
[22]
What Features in Prompts Jailbreak LLMs ? Investigating the Mechanisms Behind Attacks , May 2025
Nathalie Kirch, Constantin Weisser, Severin Field, Helen Yannakoudakis, and Stephen Casper. What Features in Prompts Jailbreak LLMs ? Investigating the Mechanisms Behind Attacks , May 2025. URL http://arxiv.org/abs/2411.03343. arXiv:2411.03343 [cs]
-
[23]
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Adam Khoja, Zhenqi Zhao, Ariel ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Simple probes can catch sleeper agents, April 2024
Monte MacDiarmid, Timothy Maxwell, Nicholas Schiefer, Jesse Mu, Jared Kaplan, David Duvenaud, Sam Bowman, Alex Tamkin, Ethan Perez, Mrinank Sharma, Carson Denison, and Evan Hubinger. Simple probes can catch sleeper agents, April 2024. URL https://www.anthropic.com/news/probes-catch-sleeper-agents
work page 2024
-
[25]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. HarmBench : A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal , February 2024. URL http://arxiv.org/abs/2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Detecting High - Stakes Interactions with Activation Probes , June 2025
Alex McKenzie, Urja Pawar, Phil Blandfort, William Bankes, David Krueger, Ekdeep Singh Lubana, and Dmitrii Krasheninnikov. Detecting High - Stakes Interactions with Activation Probes , June 2025. URL http://arxiv.org/abs/2506.10805. arXiv:2506.10805 [cs] version: 1
-
[27]
Llama 3.2: Revolutionizing edge ai and vision (connect 2024)
Meta AI . Llama 3.2: Revolutionizing edge ai and vision (connect 2024). https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/, September 2024
work page 2024
-
[28]
Probing evaluation awareness of language models.arXiv preprint arXiv:2507.01786,
Jord Nguyen, Khiem Hoang, Carlo Leonardo Attubato, and Felix Hofstätter. Probing and Steering Evaluation Awareness of Language Models , July 2025. URL http://arxiv.org/abs/2507.01786. arXiv:2507.01786 [cs] version: 2
-
[29]
OpenAI . Gpt-5 system card. Technical report, OpenAI, August 13 2025. URL https://cdn.openai.com/gpt-5-system-card.pdf
work page 2025
-
[30]
Benchmarking Deception Probes via Black -to- White Performance Boosts , August 2025
Avi Parrack, Carlo Leonardo Attubato, and Stefan Heimersheim. Benchmarking Deception Probes via Black -to- White Performance Boosts , August 2025. URL http://arxiv.org/abs/2507.12691. arXiv:2507.12691 [cs]
-
[31]
Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Ti...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Coup probes: Catching catastrophes with probes trained off-policy, November 2023
Fabien Roger. Coup probes: Catching catastrophes with probes trained off-policy, November 2023. URL https://www.lesswrong.com/posts/WCj7WgFSLmyKaMwPR/coup-probes-catching-catastrophes-with-probes-trained-off
work page 2023
-
[33]
Jérémy Scheurer, Mikita Balesni, and Marius Hobbhahn. Large Language Models can Strategically Deceive their Users when Put Under Pressure , July 2024. URL http://arxiv.org/abs/2311.07590. arXiv:2311.07590 [cs]
-
[34]
Stress testing deliberative alignment for anti-scheming training, 2025
Bronson Schoen, Evgenia Nitishinskaya, Mikita Balesni, Axel Højmark, Felix Hofstätter, Jérémy Scheurer, Alexander Meinke, Jason Wolfe, Teun van der Weij, Alex Lloyd, Nicholas Goldowsky-Dill, Angela Fan, Andrei Matveiakin, Rusheb Shah, Marcus Williams, Amelia Glaese, Boaz Barak, Wojciech Zaremba, and Marius Hobbhahn. Stress testing deliberative alignment f...
-
[35]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards Understanding Sycophancy in Language Models , May 2025 a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, Amanda Askell, Nathan Bailey, Joe Benton, Emma Bluemke, Samuel R. Bowman, Eric Christiansen, Hoagy Cunningham, Andy Dau, Anjali Gopal, Rob Gilson, Logan Graham, Logan Howard, Nimit Kalra, Taesung Lee, Kevin Lin, Peter Lofgren, Fra...
work page internal anchor Pith review arXiv 2025
-
[37]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Investigating task-specific prompts and sparse autoencoders for activation monitoring, April 2025
Henk Tillman and Dan Mossing. Investigating task-specific prompts and sparse autoencoders for activation monitoring, April 2025. URL http://arxiv.org/abs/2504.20271. arXiv:2504.20271 [cs]
-
[39]
Diffusion earth mover's distance and distribution embeddings, 2021
Alexander Tong, Guillaume Huguet, Amine Natik, Kincaid MacDonald , Manik Kuchroo, Ronald Coifman, Guy Wolf, and Smita Krishnaswamy. Diffusion earth mover's distance and distribution embeddings, 2021. URL http://arxiv.org/abs/2102.12833
-
[40]
Jailbroken: How Does LLM Safety Training Fail?
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How Does LLM Safety Training Fail ?, July 2023. URL http://arxiv.org/abs/2307.02483. arXiv:2307.02483 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Teun van der Weij, Felix Hofstätter, Ollie Jaffe, Samuel F. Brown, and Francis Rhys Ward. AI Sandbagging : Language Models can Strategically Underperform on Evaluations , February 2025. URL http://arxiv.org/abs/2406.07358. arXiv:2406.07358 [cs]
-
[42]
Jiaxin Wen, Ruiqi Zhong, Akbir Khan, Ethan Perez, Jacob Steinhardt, Minlie Huang, Samuel R. Bowman, He He, and Shi Feng. Language Models Learn to Mislead Humans via RLHF , December 2024. URL http://arxiv.org/abs/2409.12822. arXiv:2409.12822 [cs]
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Uncovering Latent Chain of Thought Vectors in Language Models , March 2025
Jason Zhang and Scott Viteri. Uncovering Latent Chain of Thought Vectors in Language Models , March 2025. URL http://arxiv.org/abs/2409.14026. arXiv:2409.14026 [cs]
-
[45]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation Engineering : A Top - Down Approach t...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.