Recognition: 2 theorem links
· Lean TheoremReward-Forcing: Autoregressive Video Generation with Reward Feedback
Pith reviewed 2026-05-16 11:50 UTC · model grok-4.3
The pith
Reward signals can guide autoregressive video generation to match or exceed teacher-dependent methods in visual quality and consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reward signals can guide the autoregressive generation process so that the model produces videos with high visual fidelity and temporal consistency without relying on a strong teacher model or performing distillation, thereby simplifying training and allowing performance that matches state-of-the-art autoregressive baselines and sometimes exceeds similarly sized bidirectional models.
What carries the argument
Reward-forcing, in which external reward signals steer each successive frame prediction during autoregressive decoding to enforce desired quality properties.
If this is right
- Training no longer requires heterogeneous distillation from a bidirectional teacher.
- The method reaches a VBench total score of 84.92, comparable to top autoregressive systems that depend on distillation.
- Performance can exceed that of similarly sized bidirectional models because teacher constraints are removed.
- High visual fidelity and frame-to-frame temporal consistency are retained through reward guidance alone.
Where Pith is reading between the lines
- The same reward-guidance pattern could be applied to other sequential generation tasks such as audio or 3D scene synthesis.
- Jointly optimizing the reward model with the generator might further reduce the performance gap to fully bidirectional systems.
- Real-time video pipelines could become more practical once the dependence on large teacher models is eliminated.
- Different reward formulations might trade off specific qualities such as motion realism versus semantic alignment.
Load-bearing premise
Reward signals computed by a separate model are sufficient to steer autoregressive frame-by-frame generation toward high visual fidelity and temporal consistency.
What would settle it
A controlled experiment in which videos produced by the reward-guided model receive markedly lower temporal consistency or motion smoothness scores than bidirectional baselines on identical prompts and benchmarks would falsify the central claim.
Figures



read the original abstract
While most prior work in video generation relies on bidirectional architectures, recent efforts have sought to adapt these models into autoregressive variants to support near real-time generation. However, such adaptations often depend heavily on teacher models, which can limit performance, particularly in the absence of a strong autoregressive teacher, resulting in output quality that typically lags behind their bidirectional counterparts. In this paper, we explore an alternative approach that uses reward signals to guide the generation process, enabling more efficient and scalable autoregressive generation. By using reward signals to guide the model, our method simplifies training while preserving high visual fidelity and temporal consistency. Through extensive experiments on standard benchmarks, we find that our approach performs comparably to existing autoregressive models and, in some cases, surpasses similarly sized bidirectional models by avoiding constraints imposed by teacher architectures. For example, on VBench, our method achieves a total score of 84.92, closely matching state-of-the-art autoregressive methods that score 84.31 but require significant heterogeneous distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Reward-Forcing, a method for autoregressive video generation that incorporates external reward signals to guide frame-by-frame generation. It claims this simplifies training relative to teacher-model distillation approaches, while preserving visual fidelity and temporal consistency, and reports competitive or superior benchmark performance such as a VBench total score of 84.92 compared to 84.31 for prior autoregressive methods.
Significance. If the empirical claims hold after full verification, the work could meaningfully advance autoregressive video generation by reducing dependence on strong bidirectional teachers and heterogeneous distillation. The reward-feedback paradigm offers a scalable alternative that may generalize beyond current distillation-heavy pipelines, with potential implications for real-time generation systems.
major comments (1)
- [Abstract] Abstract: the central claim that reward signals enable high-fidelity autoregressive generation 'without a strong teacher model or distillation' rests on reported benchmark scores (e.g., VBench 84.92). However, the abstract provides no description of the reward model architecture, how rewards are computed or back-propagated into the autoregressive decoder, the training objective, or any ablation isolating the reward component. This absence prevents evaluation of whether the results actually support the claim.
minor comments (2)
- Add error bars, number of evaluation samples, and statistical significance tests to all reported benchmark comparisons to substantiate claims of comparability.
- Clarify the precise formulation of the reward signal and its integration schedule (e.g., per-frame vs. sequence-level) in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional detail is needed to substantiate the central claims and will revise the abstract accordingly while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that reward signals enable high-fidelity autoregressive generation 'without a strong teacher model or distillation' rests on reported benchmark scores (e.g., VBench 84.92). However, the abstract provides no description of the reward model architecture, how rewards are computed or back-propagated into the autoregressive decoder, the training objective, or any ablation isolating the reward component. This absence prevents evaluation of whether the results actually support the claim.
Authors: We agree that the current abstract is too terse on these points. In the revised manuscript we will expand the abstract by one or two sentences to briefly describe: (i) the reward model as a lightweight, frozen video-quality scorer whose output is used as an auxiliary loss; (ii) the reward-forcing objective that adds a scalar reward term to the standard autoregressive negative-log-likelihood loss and back-propagates through the decoder via straight-through estimation; and (iii) the fact that no teacher-model distillation is performed. The full architecture, reward computation, training objective, and ablations isolating the reward component are already presented in Sections 3.2–3.4 and Table 3 of the main paper; the abstract revision will simply surface these elements at the front. We believe this change directly addresses the concern while keeping the abstract within length limits. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper describes an empirical training procedure that incorporates external reward signals from a separate model to guide autoregressive frame generation. No equations or steps are shown that reduce the claimed performance gains to fitted parameters, self-definitions, or self-citation chains. Benchmark results (e.g., VBench scores) are presented as direct experimental outcomes rather than predictions forced by construction from the inputs. The approach is self-contained against external benchmarks with no load-bearing self-referential reductions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lreward(θ) =−E z∼Z [R(ˆxT )] ... reward-guided optimization stage to enhance video quality
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that the performance of existing methods for converting bidirectional video diffusion models into autoregressive models are bounded by the teacher’s performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023a. Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanj...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URLhttps://openai.com/research/ video-generation-models-as-world-simulators. Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin. Videojam: Joint appearance-motion representations for enhanced motion generation in video models.arXiv preprint arXiv:2502.02492,
-
[3]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025a. Jingyuan Chen, Fuchen Long, Jie An, Zhaofan Qiu, Ting Yao, Jiebo Luo, and Tao Mei. Ouroboros- diffusion: Exploring consistent con...
work page internal anchor Pith review Pith/arXiv arXiv 2079
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
S4s: Solving for a diffusion model solver.arXiv preprint arXiv:2502.17423,
Eric Frankel, Sitan Chen, Jerry Li, Pang Wei Koh, Lillian J Ratliff, and Sewoong Oh. S4s: Solving for a diffusion model solver.arXiv preprint arXiv:2502.17423,
-
[6]
LTX-Video: Realtime Video Latent Diffusion
URLhttps://deepmind.google/models/veo/. Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
10 ICLR 2026 the 2nd Workshop on World Models Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851,
work page 2026
-
[8]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022a. Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Jing Jiang, Yiran Ling, Binzhu Li, Pengxiang Li, Junming Piao, and Yu Zhang. Poetry2image: An iterative correction framework for images generated from chinese classical poetry.arXiv preprint arXiv:2407.06196,
-
[10]
Streamdit: Real-time streaming text-to-video generation.arXiv preprint arXiv:2507.03745,
Akio Kodaira, Tingbo Hou, Ji Hou, Masayoshi Tomizuka, and Yue Zhao. Streamdit: Real-time streaming text-to-video generation.arXiv preprint arXiv:2507.03745,
-
[11]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Wenyu Qin, Menghan Xia, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025a. Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Yiheng Liu, Liao Qu, Huichao Zhang, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Xian Li, Shuai Wang, Daniel K Du, et al. Detailflow: 1d coarse-to-fine autoregressive image generation via next-detail prediction.arXiv preprint arXiv:2505.21473, 2025b. 11 ICLR 2026 the 2nd Workshop on World Models Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun ...
-
[16]
Yihong Luo, Tianyang Hu, Weijian Luo, Kenji Kawaguchi, and Jing Tang. Reward- instruct: A reward-centric approach to fast photo-realistic image generation.arXiv preprint arXiv:2503.13070,
-
[17]
Self-Attention with Relative Position Representations
URLhttps://static. magi.world/static/files/MAGI_1.pdf. Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representa- tions.arXiv preprint arXiv:1803.02155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Rocm: Rlhf on consistency models.arXiv preprint arXiv:2503.06171,
Shivanshu Shekhar and Tong Zhang. Rocm: Rlhf on consistency models.arXiv preprint arXiv:2503.06171,
-
[19]
Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling
Xiaoyu Shi, Zhaoyang Huang, Fu-Yun Wang, Weikang Bian, Dasong Li, Yi Zhang, Manyuan Zhang, Ka Chun Cheung, Simon See, Hongwei Qin, et al. Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling. InACM SIGGRAPH 2024 Conference Papers, pp. 1–11,
work page 2024
-
[20]
History-Guided Video Diffusion
Kiwhan Song, Boyuan Chen, Max Simchowitz, Yilun Du, Russ Tedrake, and Vincent Sitzmann. History-guided video diffusion.arXiv preprint arXiv:2502.06764,
work page internal anchor Pith review arXiv
-
[21]
12 ICLR 2026 the 2nd Workshop on World Models Xianbing Sun, Yan Hong, Jiahui Zhan, Jun Lan, Huijia Zhu, Weiqiang Wang, Liqing Zhang, and Jianfu Zhang. Ds-vton: High-quality virtual try-on via disentangled dual-scale generation.arXiv preprint arXiv:2506.00908,
-
[23]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. Visionreward: Fine-grained multi-dimensional human prefer- ence learning for image and video generation.arXiv preprint arXiv:2412.21059,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
13 ICLR 2026 the 2nd Workshop on World Models A APPENDIX A.1 MORE RELATED WORKS Motion in Video Diffusion ModelsMotion modeling remains a central challenge in video dif- fusion. Many early video diffusion models, such as Video Diffusion Models (Ho et al., 2022b) primarily focus on spatiotemporal attention mechanisms but treat motion implicitly. More recen...
work page 2026
-
[26]
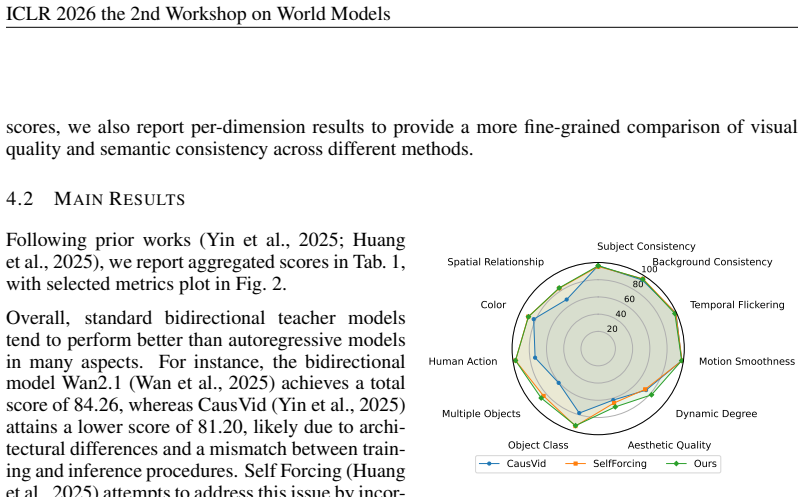
and Self Forcing (Huang et al., 2025), thus the model can be used to generate long videos as well. E.g. Causvid generates long videos by conditioning on previous generated frames which could be utilized to generate long videos by our method too. 14 ICLR 2026 the 2nd Workshop on World Models Metric Score↑ CausVid Self Forcing Ours Subject Consistency 96.32...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.