Recognition: no theorem link
Context Learning for Multi-Agent Discussion
Pith reviewed 2026-05-16 08:06 UTC · model grok-4.3
The pith
A method learns context generators for each LLM agent to dynamically refine discussion instructions and reach coherent consensus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
M2CL learns a context generator for each LLM agent that dynamically produces context instructions per discussion round through automatic information organization and refinement. Guided by theoretical insights on context instructions, a self-adaptive mechanism inside the generators controls context coherence and output discrepancies. This setup stops agents from converging prematurely on majority noise and lets them progressively reach the correct consensus.
What carries the argument
The self-adaptive mechanism in the learned context generators, which dynamically adjusts instructions to enforce coherence across agents while reducing output discrepancies.
If this is right
- Agents reach correct consensus on academic reasoning tasks more reliably than in prior multi-agent setups.
- Performance rises on embodied AI tasks and mobile control problems without added external rules.
- The learned generators transfer to new tasks while keeping computational costs low.
- Discussion inconsistency drops because each agent maintains its own refined context stream.
Where Pith is reading between the lines
- Similar per-agent generators could stabilize coordination in other multi-model systems that lack shared memory.
- Applying the mechanism to longer-running discussions might reduce gradual drift on open problems.
- Testing the same generators on creative or adversarial tasks would show whether coherence benefits extend beyond factual benchmarks.
Load-bearing premise
The self-adaptive mechanism inside the generators actually prevents premature convergence on majority noise by controlling coherence and discrepancies as described.
What would settle it
Running M2CL alongside existing MAD baselines on the same academic reasoning benchmark and observing no measurable reduction in discussion inconsistency or performance gain.
Figures































read the original abstract
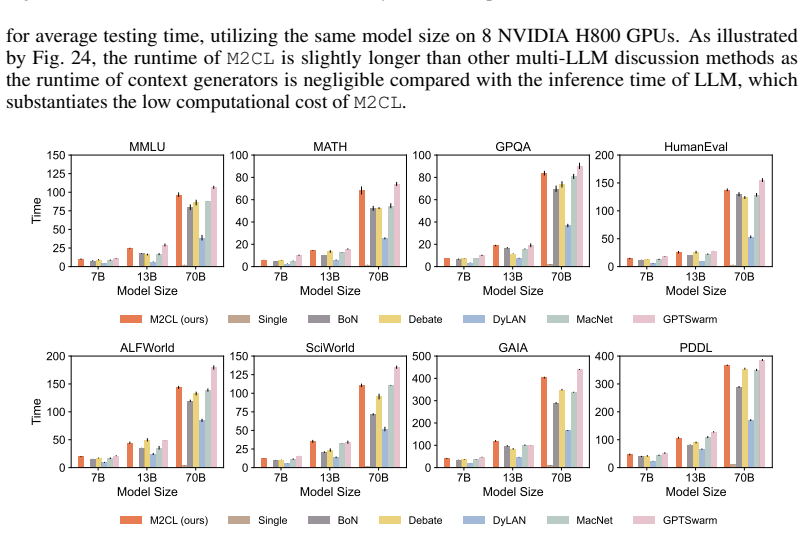
Multi-Agent Discussion (MAD) has garnered increasing attention very recently, where multiple LLM instances collaboratively solve problems via structured discussion. However, we find that current MAD methods easily suffer from discussion inconsistency, LLMs fail to reach a coherent solution, due to the misalignment between their individual contexts.In this paper, we introduce a multi-LLM context learning method (M2CL) that learns a context generator for each agent, capable of dynamically generating context instructions per discussion round via automatic information organization and refinement. Specifically, inspired by our theoretical insights on the context instruction, M2CL train the generators to control context coherence and output discrepancies via a carefully crafted self-adaptive mechanism.It enables LLMs to avoid premature convergence on majority noise and progressively reach the correct consensus. We evaluate M2CL on challenging tasks, including academic reasoning, embodied tasks, and mobile control. The results show that the performance of M2CL significantly surpasses existing methods by 20%--50%, while enjoying favorable transferability and computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces M2CL, a multi-LLM context learning approach for Multi-Agent Discussion (MAD). It learns per-agent context generators that dynamically produce context instructions each round through automatic information organization and refinement. Inspired by theoretical insights on context instructions, a self-adaptive mechanism is used to control coherence and output discrepancies, preventing premature convergence on majority noise and enabling progressive consensus. Experiments on academic reasoning, embodied tasks, and mobile control report 20-50% gains over prior MAD methods, plus favorable transferability and efficiency.
Significance. If the self-adaptive mechanism can be shown to measurably control coherence and discrepancy (rather than the gains arising from generic context organization), the work would offer a concrete advance for multi-agent LLM systems by addressing a key failure mode of discussion inconsistency. The learning-based generator plus adaptive control combination is a natural extension of current MAD frameworks and could influence follow-on work on scalable consensus protocols, provided the empirical linkage is strengthened.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The central performance claim of 20-50% improvement is stated without error bars, number of runs, baseline implementation details, data exclusion rules, or statistical significance tests. This makes it impossible to determine whether the gains are robust or specifically attributable to the self-adaptive mechanism rather than other factors.
- [§3] §3 (Method): The self-adaptive mechanism is presented as controlling context coherence and output discrepancies to avoid premature convergence, yet no equations, pseudocode, discrepancy metrics, or ablation (e.g., mechanism disabled vs. enabled) are supplied. Without such evidence the claimed causal link between the mechanism and the reported gains remains unverified.
- [§2] §2 (Theoretical Insights): The paper invokes 'theoretical insights on the context instruction' to motivate the self-adaptive design, but provides no derivation, formal statement, or proof sketch. This leaves the connection between the insights and the concrete mechanism opaque and difficult to assess for correctness.
minor comments (2)
- [§3] Clarify the exact training objective and loss used for the context generators; the current description leaves open whether any metric reduces to a fitted quantity by construction.
- [§4] Add a table or figure showing per-round discrepancy or coherence metrics across methods to directly support the narrative about avoiding majority noise.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will incorporate revisions to strengthen the empirical, methodological, and theoretical aspects of the work.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central performance claim of 20-50% improvement is stated without error bars, number of runs, baseline implementation details, data exclusion rules, or statistical significance tests. This makes it impossible to determine whether the gains are robust or specifically attributable to the self-adaptive mechanism rather than other factors.
Authors: We agree that rigorous statistical reporting is essential. In the revised manuscript, we will include error bars from 5 independent runs with different random seeds, provide complete baseline implementation details and hyperparameters, specify data exclusion rules, and report statistical significance via paired t-tests to confirm robustness and attribution to the self-adaptive mechanism. revision: yes
-
Referee: [§3] §3 (Method): The self-adaptive mechanism is presented as controlling context coherence and output discrepancies to avoid premature convergence, yet no equations, pseudocode, discrepancy metrics, or ablation (e.g., mechanism disabled vs. enabled) are supplied. Without such evidence the claimed causal link between the mechanism and the reported gains remains unverified.
Authors: We will revise §3 to include the full mathematical formulation of the self-adaptive mechanism (using output variance as the discrepancy metric), pseudocode for generator training and adaptive control, and a new ablation study with the mechanism disabled to empirically verify its role in preventing premature convergence and driving the performance gains. revision: yes
-
Referee: [§2] §2 (Theoretical Insights): The paper invokes 'theoretical insights on the context instruction' to motivate the self-adaptive design, but provides no derivation, formal statement, or proof sketch. This leaves the connection between the insights and the concrete mechanism opaque and difficult to assess for correctness.
Authors: We will expand §2 with a formal statement of the key insight on context misalignment and a derivation sketch demonstrating how discrepancy control reduces convergence to majority noise, thereby clarifying the direct link to the self-adaptive mechanism. revision: yes
Circularity Check
No significant circularity in M2CL derivation chain
full rationale
The paper describes M2CL as a training procedure that learns context generators from data using a self-adaptive mechanism, with performance measured on held-out tasks. No equations, definitions, or steps are shown that equate any claimed output (coherence control, discrepancy reduction, or 20-50% gains) to the inputs by construction, rename a fitted quantity as a prediction, or rest the central result solely on an unverified self-citation chain. The theoretical insights are invoked to motivate the mechanism design, but the mechanism itself is implemented and evaluated empirically rather than derived tautologically from its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- context generator weights
axioms (1)
- domain assumption LLMs can be trained to generate dynamic context instructions that control coherence and discrepancies
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Chateval: Towards better llm-based evaluators through multi-agent debate
10 Under review as a conference paper at ICLR 2026 Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. In Proceedings of The 11st International Conference on Learning Representations,
work page 2026
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Shima Imani, Liang Du, and Harsh Shrivastava. Mathprompter: Mathematical reasoning using large language models.arXiv preprint arXiv:2303.05398,
-
[9]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 5880–5895
Doohyuk Jang, Yoonjeon Kim, Chanjae Park, Hyun Ryu, and Eunho Yang. Reasoning model is stubborn: Diagnosing instruction overriding in reasoning models.arXiv preprint arXiv:2505.17225,
-
[10]
Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. Llm-blender: Ensembling large language models with pairwise ranking and generative fusion.arXiv preprint arXiv:2306.02561,
-
[11]
Implicit in-context learning.arXiv preprint arXiv:2405.14660, 2024b
11 Under review as a conference paper at ICLR 2026 Zhuowei Li, Zihao Xu, Ligong Han, Yunhe Gao, Song Wen, Di Liu, Hao Wang, and Dimitris N Metaxas. Implicit in-context learning.arXiv preprint arXiv:2405.14660, 2024b. Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinkin...
-
[12]
Ziru Liu, Cheng Gong, Xinyu Fu, Yaofang Liu, Ran Chen, Shoubo Hu, Suiyun Zhang, Rui Liu, Qingfu Zhang, and Dandan Tu. Ghpo: Adaptive guidance for stable and efficient llm reinforcement learning.arXiv preprint arXiv:2507.10628,
-
[13]
Li-Chun Lu, Shou-Jen Chen, Tsung-Min Pai, Chan-Hung Yu, Hung-yi Lee, and Shao-Hua Sun. Llm discussion: Enhancing the creativity of large language models via discussion framework and role-play.arXiv preprint arXiv:2405.06373,
-
[14]
Prorefine: Inference-time prompt refinement with textual feedback.arXiv preprint arXiv:2506.05305,
Deepak Pandita, Tharindu Cyril Weerasooriya, Ankit Parag Shah, Isabelle Diana May-Xin Ng, Christopher M Homan, and Wei Wei. Prorefine: Inference-time prompt refinement with textual feedback.arXiv preprint arXiv:2506.05305,
-
[15]
arXiv preprint arXiv:2304.01904 , year=
Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. Refiner: Reasoning feedback on intermediate representations.arXiv preprint arXiv:2304.01904,
-
[16]
12 Under review as a conference paper at ICLR 2026 Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67,
work page 2026
-
[17]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Small llms are weak tool learners: A multi-llm agent
Weizhou Shen, Chenliang Li, Hongzhan Chen, Ming Yan, Xiaojun Quan, Hehong Chen, Ji Zhang, and Fei Huang. Small llms are weak tool learners: A multi-llm agent. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 16658–16680,
work page 2024
-
[19]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. Scienceworld: Is your agent smarter than a 5th grader? InProceedings of The 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11279–11298,
work page 2022
-
[21]
CodeFlowBench: A Multi-turn, Iterative Benchmark for Complex Code Generation
Sizhe Wang, Zhengren Wang, Dongsheng Ma, Yongan Yu, Rui Ling, Zhiyu Li, Feiyu Xiong, and Wentao Zhang. Codeflowbench: A multi-turn, iterative benchmark for complex code generation. arXiv preprint arXiv:2504.21751,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
13 Under review as a conference paper at ICLR 2026 Jimmy Wei, Kurt Shuster, Arthur Szlam, Jason Weston, Jack Urbanek, and Mojtaba Komeili. Multi- party chat: Conversational agents in group settings with humans and models.arXiv preprint arXiv:2304.13835,
-
[23]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024a. Hao Yang, Qianghua Zhao, and Lei Li. Chain-of-thought in large language models: Decoding, projection, and activation.arXiv preprint arXiv:2412.03944, 2024b. Jingyu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
G-memory: Tracing hierarchical memory for multi-agent systems.arXiv preprint arXiv:2506.07398, 2025a
Guibin Zhang, Muxin Fu, Guancheng Wan, Miao Yu, Kun Wang, and Shuicheng Yan. G-memory: Tracing hierarchical memory for multi-agent systems.arXiv preprint arXiv:2506.07398, 2025a. Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong-Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, et al. Aflow: Automating agentic workflow gen...
-
[25]
Simulating classroom education with llm-empowered agents.arXiv preprint arXiv:2406.19226,
Zheyuan Zhang, Daniel Zhang-Li, Jifan Yu, Linlu Gong, Jinchang Zhou, Zhanxin Hao, Jianxiao Jiang, Jie Cao, Huiqin Liu, Zhiyuan Liu, et al. Simulating classroom education with llm-empowered agents.arXiv preprint arXiv:2406.19226,
-
[26]
14 Under review as a conference paper at ICLR 2026 A USAGE OFLLMS We use large language models (LLMs) solely as an assistive tool for polishing the writing and improving clarity of exposition. All content generated by LLMs was carefully reviewed, verified, and, where necessary, revised by the authors. The authors take full responsibility for the correctne...
work page 2026
-
[27]
Finally, we utilize the smoothness property of the activation function to bound the second term Substituting into Eq. (18), we can derive: NX i=1 ∥ac −a(C t i )∥ ≤ NX i=1 NX j=1 ∥a(C t i )−a(C t j)∥+ (N+ 1)L a∥C t i −C b i ∥ +Nmin ω ∥ac − NX i=1 ωia(C b i )∥,(21) 15 Under review as a conference paper at ICLR 2026 C DECOUPLEDCRITERIONFUCNTION Lemma C.1.Und...
work page 2026
-
[28]
Then, we derive the upper bound of δ by finding the upper bound of each element ofδ
(26) Summing them up, we can derive: ∥D−1 exp(S)−exp(S)∥ ≤ ∥D −1 exp(S)−exp(S)∥ F = vuut nX i=1 nX j=1 ∆2 ij ≤2nexp(2ρ 2)(27) Define δ= exp(S)−S , where S= (W KX) T WQX. Then, we derive the upper bound of δ by finding the upper bound of each element ofδ. δij = exp(Sij)−S ij ≤max{exp(ρ 2)−ρ 2, ρ2 + exp(−ρ2)} ≤exp(ρ 2)(28) 16 Under review as a conference pa...
work page 2026
-
[29]
≤3nexp(2ρ 2)(30) Therefore, we derive the difference between the activation of softmax attention and linear attention as: ∥WV Xsoftmax (WKX) T WQX√ d −W V X(W KX) T WQX∥ ≤∥WV X∥ · ∥softmax (WKX) T WQX√ d −(W KX) T WQX∥ ≤LV · ∥D−1 exp(S)−S∥ ≤3LV nexp(2ρ 2)(31) Lemma D.2.Define the activation of linear attention: a′(Y) .=W V [Y, P](W K[Y, P]) T WQY a′(P) .=...
work page 2026
-
[30]
( DyLAN), a discussion-style framework which incorporates an LLM selection algorithm based on an unsupervised metric, namely the Agent Importance Score, which identifies the most contributive LLMs through a preliminary trial tailored to the specific task. • GPTSwarm(Zhuge et al., 2024), formalizing a swarm of autonomous agents as computational graphs, wit...
work page 2024
-
[31]
( MacNet), a representative framework for decentralized and scalable multi-LLM systems. It introduces edge agents that mediate interactions by generating actionable instructions for the next agent based on the outputs of the previous one. F.3 IMPLEMENTATIONDETAILS The context pool is constructed using GPT-4o, where we prompt it to generate a large collect...
work page 2026
-
[32]
It begins with training the context initialization, then the context generators are trained along with the weight α during the discussion. Algorithm 1:Pseudocode ofM2CL 1Initialize parametersϕ f ,ϕ F ,{θ i}N i=1, and{α i}N i=1; 2foreach questiondo 3ϕ f ←ϕ f −η f ∇L(ϕf),ϕ F ←ϕ F −η F ∇L(ϕF ); 4end 5foreach epochdo 6Obtain initial contexts{I b i }N i=1 via ...
work page 2026
-
[33]
This highlights its ability to tackle intricate reasoning tasks
Summary of key findings.The results show that M2CL significantly improves MAD performance, consistently surpassing existing methods by 20%−50% , particularly in complex tasks like math and tool-using. This highlights its ability to tackle intricate reasoning tasks. M2CL also exhibits a more effective multi-agent scaling law, where performance consistently...
work page 2026
-
[34]
We observe that M2CL consistently outperforms existing baselines across different model scales up to 50%, with performance gains becoming more pronounced as the number of participating LLMs increases. The superior scalability of M2CL in this setting highlights its ability to exploit diverse responses and maintain consistent under complex, real-world style...
work page 2026
-
[35]
As illustrated in Figs. 12 to 16, a larger value of β results in a high degree of consistency among LLMs, leading them to produce similar answers. Conversely, a smaller value of β is associated with reduced collaboration among LLMs. Therefore, it is important to adjust β to control the degree of consistency among LLMs for better collaboration. /uni0000001...
work page 2026
-
[36]
M2CL can improve consistency with fewer rounds
Lower values represent a lower degree of disagreement. M2CL can improve consistency with fewer rounds. Of note, M2CL displays both a lower initial value and a faster decreasing speed, indicating its capability of assigning appropriate contexts based on the given question and current discussion situation. 35 Under review as a conference paper at ICLR 2026 ...
work page 2026
-
[37]
Lower values represent a lower degree of disagreement.M2CLcan improve consistency with fewer rounds. 36 Under review as a conference paper at ICLR 2026 /uni00000013/uni00000015/uni00000017/uni00000019/uni0000001b /uni00000013 /uni00000016 /uni00000019 /uni0000001c /uni00000014/uni00000015 /uni00000014/uni00000018/uni00000027/uni0000004c/uni00000056/uni000...
work page 2026
-
[38]
Lower values represent a lower degree of disagreement.M2CLcan improve consistency with fewer rounds. 37 Under review as a conference paper at ICLR 2026 G.6 TRANSFERABILITY OFCONTEXTS To further study the generalization of the generated contexts, we implement the multi-agent system using GPT-4 as the base model with the context generator trained on llama-7...
work page 2026
-
[39]
Uncertainty intervals depict standard deviation over three seeds. 41 Under review as a conference paper at ICLR 2026 H CASE STUDY We used a problem from the MATH Hendrycks et al. (2021). The number of LLMs is set as8. For each LLM, we present their instructions, responses, and final answers for4discussion rounds. H.1 CASE STUDY OFM2CL(OURS) We provide the...
work page 2026
-
[40]
Use the Law of Cosines: cos∠𝐵𝑃𝐶=":!6%:!8"%!9":⋅%:.Solve forcos∠𝐵𝑃𝐶 and determine ∠𝐵𝑃𝐶=120∘ . Final Answer: 120∘ Problem: In the diagram, square ABCD has sides of length 4, and △𝐴𝐵𝐸 is equilateral. Line segments BE and AC intersect at P. Point Q is on BC so thatPQ is perpendicular to BC and PQ=x. A=(0,0); B=(4,0); C=(4,4); D=(0,4); E=(2,3.464); P=(2.535,2....
work page 2026
-
[41]
Law of Cosines: cos𝜃 = BP2+CP2−BC2 2BP∙CP = −0.25. So ∠𝐵𝑃𝐶 = 105∘. Final Answer: 105∘ Agent 8 Instruction: You must act as an expert in Algebraic Geometry and Triangle Theory. You are instructed to apply exact algebraic rules like the Law of Cosines, while quietly checking if your angle agrees with the analytic agent. Response: With BP = 2.92, CP = 2.07, ...
work page 2026
-
[42]
Law of Cosines gives cos ∠𝐵𝑃𝐶 = −0.25. Hence, ∠𝐵𝑃𝐶 = 105∘. This aligns with the construction and vector consensus, correcting the earlier 120∘ from analytic geometry, showing that algebraic methods must be cross-checked with geometric intuition. Final Answer: 105∘ Problem: In the diagram, square ABCD has sides of length 4, and △ 𝐴𝐵𝐸 is equilateral. Line s...
work page 2026
-
[43]
Solve for cos∠ 𝐵𝑃𝐶 and find cos∠ 𝐵𝑃𝐶
Use the Law of Cosines: cos∠ 𝐵𝑃𝐶 = 𝐵𝑃2+𝐶𝑃2−𝐵𝐶2 2𝐵𝑃⋅𝐶𝑃 . Solve for cos∠ 𝐵𝑃𝐶 and find cos∠ 𝐵𝑃𝐶. Result: 105∘. Final Answer: 105∘ Problem: In the diagram, square ABCD has sides of length 4, and △ 𝐴𝐵𝐸 is equilateral. Line segments BE and AC intersect at P. Point Q is on BC so that PQ is perpendicular to BC and PQ=x. A=(0,0); B=(4,0); C=(4,4); D=(0,4); E=(2,3....
work page 2026
-
[44]
Solve for cos∠ 𝐵𝑃𝐶 and determine ∠𝐵𝑃𝐶 = 120∘
Apply the Law of Cosines: cos∠ 𝐵𝑃𝐶 = 𝐵𝑃2+𝐶𝑃2−𝐵𝐶2 2𝐵𝑃⋅𝐶𝑃 . Solve for cos∠ 𝐵𝑃𝐶 and determine ∠𝐵𝑃𝐶 = 120∘ . Final Answer: 120∘ Problem: In the diagram, square ABCD has sides of length 4, and △ 𝐴𝐵𝐸 is equilateral. Line segments BE and AC intersect at P. Point Q is on BC so that PQ is perpendicular to BC and PQ=x. A=(0,0); B=(4,0); C=(4,4); D=(0,4); E=(2,3.464...
work page 2026
-
[45]
Law of Cosines: cos𝜃 = BP2+CP2−BC2 2BP∙CP = −0.25. So ∠𝐵𝑃𝐶 = 105∘. Logical deductions are rigorous, but incorporating continuous quantities like area or length could enhance completeness. Final Answer: 105∘ Agent 8 Instruction: You are an expert in Algebraic Geometry and Triangle Theory. Your job is to apply algebraic techniques, such as the Law of Cosine...
work page 2026
-
[46]
Law of Cosines gives cos ∠𝐵𝑃𝐶 = −0.25. Hence, ∠𝐵𝑃𝐶 = 105∘. A purely formal derivation may sidestep geometric intuition, resulting in arguments that are valid but disconnected from the figure. Final Answer: 120∘ Problem: In the diagram, square ABCD has sides of length 4, and △ 𝐴𝐵𝐸 is equilateral. Line segments BE and AC intersect at P. Point Q is on BC so ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.