Recognition: 2 theorem links
· Lean TheoremCivBench: Progress-Based Evaluation for LLMs' Strategic Decision-Making in Civilization V
Pith reviewed 2026-05-10 17:55 UTC · model grok-4.3
The pith
CivBench evaluates LLM strategic decisions in Civilization V using turn-by-turn victory probability estimates instead of final win or loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
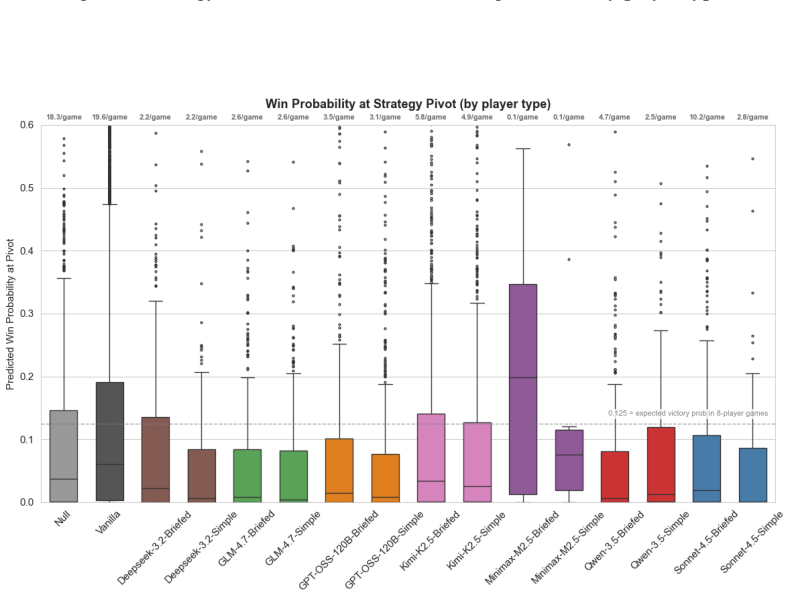
By training models to estimate victory probabilities from turn-level game states in multiplayer Civilization V, CivBench enables dense evaluation of strategic decision-making in LLM agents, with validity checks confirming the estimates track actual outcomes and strategic quality, leading to identification of distinct profiles across models and agent conditions in 307 games.
What carries the argument
A victory probability model trained on game state features at each turn to produce ongoing estimates of winning chances.
If this is right
- Strategic capabilities of LLMs can be tracked and compared throughout extended play rather than only at the end.
- Effects of different agent setups on decision-making become measurable for each model.
- Strategic profiles that differ from what outcome metrics show can be outlined.
- Unsaturated benchmarks for long-horizon multi-agent strategy are possible.
Where Pith is reading between the lines
- Agents could receive real-time feedback during play to improve their strategies iteratively.
- Similar progress-based signals might apply to evaluating strategy in other complex games with sparse rewards.
- Comparison between LLM profiles and human player data could highlight where models excel or fall short.
Load-bearing premise
Victory probability estimates from game states serve as a valid and rich enough signal for measuring the quality of strategic decisions.
What would settle it
A direct test showing that the estimated probabilities do not reliably predict who actually wins the games or do not align with independent measures of strategic strength would undermine the approach.
Figures














read the original abstract
Evaluating strategic decision-making in LLM-based agents requires generative, competitive, and longitudinal environments, yet few benchmarks provide all three, and fewer still offer evaluation signals rich enough for long-horizon, multi-agent play. We introduce CivBench, a benchmark for LLM strategists (i.e., agentic setups) in multiplayer Civilization V. Because terminal win/loss is too sparse a signal in games spanning hundreds of turns and multiple opponents, CivBench trains models on turn-level game state to estimate victory probabilities throughout play, validated through predictive, construct, and convergent validity. Across 307 games with 7 LLMs and multiple CivBench agent conditions, we demonstrate CivBench's potential to estimate strategic capabilities as an unsaturated benchmark, reveal model-specific effects of agentic setup, and outline distinct strategic profiles not visible through outcome-only evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CivBench, a benchmark for LLM-based agents in multiplayer Civilization V. It replaces sparse terminal win/loss signals with turn-level victory probability estimates trained on game-state features, validated via predictive, construct, and convergent validity checks. Experiments across 307 games with 7 LLMs under multiple agent conditions are used to argue that the benchmark is unsaturated, reveals model-specific effects of agentic setups, and identifies distinct strategic profiles invisible to outcome-only metrics.
Significance. If the validity of the progress-based proxy holds, the work provides a denser evaluation signal for long-horizon strategic capabilities in generative multi-agent settings, addressing a recognized gap in current LLM agent benchmarks. The scale (307 games) and use of three distinct validity types are strengths that could support more granular analysis of planning and opponent modeling than win rates alone.
major comments (2)
- [§3.2] §3.2 (Victory Probability Estimator): The central claim that these estimates measure LLM-specific strategic decision-making rests on the assumption that the model captures more than aggregate progress metrics (e.g., unit counts, city development). No ablation on decision features or counterfactual state edits is described to isolate the contribution of LLM actions from general game-state progress, which directly bears on whether model-specific effects and distinct profiles can be attributed to strategy rather than shared progress signals.
- [§4.3] §4.3 (Strategic Profiles): The reported distinct profiles and model-specific agent effects are derived from the probability trajectories, yet the manuscript provides no statistical comparison (e.g., significance tests or variance decomposition) against outcome-only baselines or non-LLM agents to confirm these profiles are not artifacts of the estimator's sensitivity to state progress.
minor comments (2)
- [Abstract] The abstract states results from 'multiple CivBench agent conditions' without enumerating them; a brief list would improve readability.
- [§4] Figure legends in §4 could more explicitly label the different LLMs and agent variants to aid interpretation of the probability curves.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which identifies key areas for strengthening the validation of our progress-based evaluation. We respond to each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Victory Probability Estimator): The central claim that these estimates measure LLM-specific strategic decision-making rests on the assumption that the model captures more than aggregate progress metrics (e.g., unit counts, city development). No ablation on decision features or counterfactual state edits is described to isolate the contribution of LLM actions from general game-state progress, which directly bears on whether model-specific effects and distinct profiles can be attributed to strategy rather than shared progress signals.
Authors: We appreciate the referee highlighting this assumption. Our validation already includes predictive accuracy on held-out games, construct validity through alignment with known strategic indicators, and convergent validity with outcome metrics. Nevertheless, we agree that targeted ablations and counterfactual analyses would more directly isolate LLM decision contributions. In the revised manuscript we will add an ablation study training estimator variants with and without features tied to LLM actions (e.g., unit movement sequences and city-build decisions) and quantify performance degradation. We will also report results from feasible counterfactual state edits, generated by replaying games with perturbed LLM-derived actions while holding other state elements fixed, to demonstrate sensitivity to strategic choices beyond aggregate progress. revision: yes
-
Referee: [§4.3] §4.3 (Strategic Profiles): The reported distinct profiles and model-specific agent effects are derived from the probability trajectories, yet the manuscript provides no statistical comparison (e.g., significance tests or variance decomposition) against outcome-only baselines or non-LLM agents to confirm these profiles are not artifacts of the estimator's sensitivity to state progress.
Authors: We concur that statistical confirmation is needed to rule out artifacts. The observed profiles already differ visibly from win-rate outcomes across the 307 games, but we will strengthen this in revision. We will add formal statistical comparisons, including permutation tests and ANOVA on trajectory features (e.g., slope, variance, and inflection points) against both outcome-only baselines and non-LLM agents (rule-based and random). We will also include variance decomposition to partition the explained variance attributable to model-specific strategy versus general state progress, with results reported in the updated §4.3. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper trains a victory probability estimator on turn-level game states and applies it to evaluate LLM agents across 307 games, with validity established via separate predictive, construct, and convergent checks. No equations, self-citations, or definitional steps are shown that reduce the central claims (model-specific effects and distinct profiles) back to the training inputs by construction. The estimator serves as an independent proxy rather than a tautological renaming or fitted prediction of the LLM behaviors themselves.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CivBench trains ML models on turn-level game state to estimate victory probabilities... 23 game-state features spanning technology, policy, economy, military, diplomacy, and culture... AttentionMLP... Bradley-Terry ELO ratings
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define strategic capability as a strategist’s ability to convert decisions into winning potential... progress-weighted average of turn-level estimates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
https://www.reddit.com/r/civ5/comments/fklkzw/the_way_scores_are_calculated_bothers_me/, 2020
The way scores are calculated bothers me . https://www.reddit.com/r/civ5/comments/fklkzw/the_way_scores_are_calculated_bothers_me/, 2020. Community forum source. Accessed 2026-03-28
2020
-
[3]
https://forums.civfanatics.com/threads/650-ai-game-4uc-stats-analysis.689648/page-2, 2024
650 AI Game 4UC Stats / Analysis . https://forums.civfanatics.com/threads/650-ai-game-4uc-stats-analysis.689648/page-2, 2024. Community forum source. Accessed 2026-03-28
2024
-
[4]
Mubashara Akhtar, Anka Reuel, Prajna Soni, Sanchit Ahuja, Pawan Sasanka Ammanamanchi, Ruchit Rawal, Vilém Zouhar, Srishti Yadav, Chenxi Whitehouse, Dayeon Ki, Jennifer Mickel, Leshem Choshen, Marek Šuppa, Jan Batzner, Jenny Chim, Jeba Sania, Yanan Long, Hossein A. Rahmani, Christina Knight, Yiyang Nan, Jyoutir Raj, Yu Fan, Shubham Singh, Subramanyam Sahoo...
-
[5]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD '19, pp.\ 2623--2631, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450362016. doi...
-
[6]
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards
Norah Alzahrani, Hisham Alyahya, Yazeed Alnumay, Sultan AlRashed, Shaykhah Alsubaie, Yousef Almushayqih, Faisal Mirza, Nouf Alotaibi, Nora Al-Twairesh, Areeb Alowisheq, M Saiful Bari, and Haidar Khan. When benchmarks are targets: Revealing the sensitivity of large language model leaderboards. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Procee...
-
[7]
Harnessing language for coordination: A framework and benchmark for llm-driven multiagent control
Timothée Anne, Noah Syrkis, Meriem Elhosni, Florian Turati, Franck Legendre, Alain Jaquier, and Sebastian Risi. Harnessing language for coordination: A framework and benchmark for llm-driven multiagent control. IEEE Transactions on Games, 17 0 (4): 0 933--943, 2025. doi:10.1109/TG.2025.3564042
-
[8]
arXiv preprint arXiv:2502.15840 , year =
Axel Backlund and Lukas Petersson. Vending-bench: A benchmark for long-term coherence of autonomous agents, 2025. URL https://arxiv.org/abs/2502.15840
-
[9]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39 0 (3/4): 0 324--345, 1952. doi:10.1093/biomet/39.3-4.324. URL https://doi.org/10.1093/biomet/39.3-4.324
-
[10]
John Chen, Sihan Cheng, Can Gurkan, Ryan Lay, and Moez Salahuddin. Vox deorum: A hybrid llm architecture for 4x / grand strategy game ai -- lessons from civilization v, 2025 a . URL https://arxiv.org/abs/2512.18564
-
[11]
LLMA rena: Assessing capabilities of large language models in dynamic multi-agent environments
Junzhe Chen, Xuming Hu, Shuodi Liu, Shiyu Huang, Wei-Wei Tu, Zhaofeng He, and Lijie Wen. LLMA rena: Assessing capabilities of large language models in dynamic multi-agent environments. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp...
-
[12]
Simin Chen, Yiming Chen, Zexin Li, Yifan Jiang, Zhongwei Wan, Yixin He, Dezhi Ran, Tianle Gu, Haizhou Li, Tao Xie, and Baishakhi Ray. Benchmarking large language models under data contamination: A survey from static to dynamic evaluation. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Conf...
-
[13]
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD '16, pp.\ 785--794, New York, NY, USA, 2016. Association for Computing Machinery. ISBN 9781450342322. doi:10.1145/2939672.2939785. URL https://doi.org/10.1145/2939672.2939785
-
[14]
Gamebench: Evaluating strategic reasoning abilities of llm agents, 2024
Anthony Costarelli, Mat Allen, Roman Hauksson, Grace Sodunke, Suhas Hariharan, Carlson Cheng, Wenjie Li, Joshua Clymer, and Arjun Yadav. Gamebench: Evaluating strategic reasoning abilities of llm agents, 2024. URL https://arxiv.org/abs/2406.06613
-
[15]
Investigating data contamination in modern benchmarks for large language models
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan. Investigating data contamination in modern benchmarks for large language models. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volu...
-
[16]
Meta Fundamental AI Research Diplomacy Team (FAIR)†, Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, Athul Paul Jacob, Mojtaba Komeili, Karthik Konath, Minae Kwon, Adam Lerer, Mike Lewis, Alexander H. Miller, Sasha Mitts, Adithya Renduchintala, Stephen Roller, Dirk Rowe, Weiya...
-
[17]
A gent Q uest: A modular benchmark framework to measure progress and improve LLM agents
Luca Gioacchini, Giuseppe Siracusano, Davide Sanvito, Kiril Gashteovski, David Friede, Roberto Bifulco, and Carolin Lawrence. A gent Q uest: A modular benchmark framework to measure progress and improve LLM agents. In Kai-Wei Chang, Annie Lee, and Nazneen Rajani (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association fo...
-
[18]
Multilayer feedforward networks are universal approximators , journal =
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators. Neural Networks, 2 0 (5): 0 359--366, 1989. ISSN 0893-6080. doi:https://doi.org/10.1016/0893-6080(89)90020-8. URL https://www.sciencedirect.com/science/article/pii/0893608089900208
-
[19]
Ecogym: Evaluating llms for long-horizon plan-and-execute in interactive economies, 2026
Xavier Hu, Jinxiang Xia, Shengze Xu, Kangqi Song, Yishuo Yuan, Guibin Zhang, JinCheng Ren, Boyu Feng, Li Lu, Tieyong Zeng, Jiaheng Liu, Minghao Liu, He Zhu, Yuchen Eleanor Jiang, Wei Wang, and Wangchunshu Zhou. Ecogym: Evaluating llms for long-horizon plan-and-execute in interactive economies, 2026. URL https://arxiv.org/abs/2602.09514
work page internal anchor Pith review arXiv 2026
-
[20]
Openskill: A faster asymmetric multi-team, multiplayer rating system
Vivek Joshy. Openskill: A faster asymmetric multi-team, multiplayer rating system. Journal of Open Source Software, 9 0 (93): 0 5901, 2024. doi:10.21105/joss.05901. URL https://doi.org/10.21105/joss.05901
-
[21]
Dynabench: Rethinking benchmarking in NLP
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Christopher Potts, and Adina Williams. Dynabench: Rethinking benchmarking in NLP . In Kristina Toutanova, ...
-
[22]
Liveagentbench: Comprehensive benchmarking of agentic systems across 104 real-world challenges, 2026
Hao Li, Huan Wang, Jinjie Gu, Wenjie Wang, Chenyi Zhuang, and Sikang Bian. Liveagentbench: Comprehensive benchmarking of agentic systems across 104 real-world challenges, 2026. URL https://arxiv.org/abs/2603.02586
-
[23]
An open-source data contamination report for large language models
Yucheng Li, Yunhao Guo, Frank Guerin, and Chenghua Lin. An open-source data contamination report for large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 528--541, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi:10....
-
[24]
Let's verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=v8L0pN6EOi
2024
-
[25]
Agentbench: Evaluating LLM s as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLM s as agents. In The Twelfth International Conference on Learning...
2024
-
[26]
Agentboard: An analytical evaluation board of multi- turn llm agents
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. Agentboard: An analytical evaluation board of multi-turn llm agents. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (eds.), Advances in Neural Information Processing Systems, volume 37, pp.\ 74325--743...
-
[27]
Large language models play starcraft ii:benchmarks and a chain of summarization approach
Weiyu Ma, Qirui Mi, Yongcheng Zeng, Xue Yan, Yuqiao Wu, Runji Lin, Haifeng Zhang, and Jun Wang. Large language models play starcraft ii:benchmarks and a chain of summarization approach. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (eds.), Advances in Neural Information Processing Systems, volume 37, pp.\ 133386--133...
-
[28]
Mahmoud Mohammadi, Yipeng Li, Jane Lo, and Wendy Yip. Evaluation and benchmarking of llm agents: A survey. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2, KDD '25, pp.\ 6129--6139, New York, NY, USA, 2025. Association for Computing Machinery. ISBN 9798400714542. doi:10.1145/3711896.3736570. URL https://doi.org/...
-
[29]
OpenAI, Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Debiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, Rafal Józefowicz, Scott Gray, Catherine Olsson, Jakub Pachocki, Michael Petrov, Henrique P. d. O. Pinto, Jonathan Raiman, Tim Salimans, Jeremy Schlatter, Jonas Schneider, Szymon Sidor, Ilya Sut...
work page internal anchor Pith review arXiv 2019
-
[30]
BALROG : Benchmarking agentic LLM and VLM reasoning on games
Davide Paglieri, Bart omiej Cupia , Samuel Coward, Ulyana Piterbarg, Maciej Wolczyk, Akbir Khan, Eduardo Pignatelli, ukasz Kuci \'n ski, Lerrel Pinto, Rob Fergus, Jakob Nicolaus Foerster, Jack Parker-Holder, and Tim Rockt \"a schel. BALROG : Benchmarking agentic LLM and VLM reasoning on games. In The Thirteenth International Conference on Learning Represe...
2025
-
[31]
Sourav Panda, Shreyash Kale, Tanmay Ambadkar, Abhinav Verma, and Jonathan Dodge. Scaling strategy, not compute: A stand-alone, open-source starcraft ii benchmark for accessible reinforcement learning research, 2026. URL https://arxiv.org/abs/2603.06608
-
[32]
Civrealm: A learning and reasoning odyssey in civilization for decision-making agents
Siyuan Qi, Shuo Chen, Yexin Li, Xiangyu Kong, Junqi Wang, Bangcheng Yang, Pring Wong, Yifan Zhong, Xiaoyuan Zhang, Zhaowei Zhang, Nian Liu, Yaodong Yang, and Song-Chun Zhu. Civrealm: A learning and reasoning odyssey in civilization for decision-making agents. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview...
2024
-
[33]
A bayesian approach to in-game win probability in soccer
Pieter Robberechts, Jan Van Haaren, and Jesse Davis. A bayesian approach to in-game win probability in soccer. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, KDD '21, pp.\ 3512--3521, New York, NY, USA, 2021. Association for Computing Machinery. ISBN 9781450383325. doi:10.1145/3447548.3467194. URL https://doi.org/10...
-
[34]
Workbench: a benchmark dataset for agents in a realistic workplace setting
Olly Styles, Sam Miller, Patricio Cerda-Mardini, Tanaya Guha, Victor Sanchez, and Bertie Vidgen. Workbench: a benchmark dataset for agents in a realistic workplace setting. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=4HNAwZFDcH
2024
-
[35]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https:...
2017
-
[36]
Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang, Laurent Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander S. Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibar...
-
[37]
arXiv preprint arXiv:2410.10479 , year =
Haochuan Wang, Xiachong Feng, Lei Li, Yu Guo, Zhanyue Qin, Dianbo Sui, and Lingpeng Kong. Tmgbench: A systematic game benchmark for evaluating strategic reasoning abilities of llms, 2025 a . URL https://arxiv.org/abs/2410.10479
-
[38]
Digital player: Evaluating large language models based human-like agent in games, 2025 b
Jiawei Wang, Kai Wang, Shaojie Lin, Runze Wu, Bihan Xu, Lingeng Jiang, Shiwei Zhao, Renyu Zhu, Haoyu Liu, Zhipeng Hu, Zhong Fan, Le Li, Tangjie Lyu, and Changjie Fan. Digital player: Evaluating large language models based human-like agent in games, 2025 b . URL https://arxiv.org/abs/2502.20807
-
[39]
arXiv preprint arXiv:2408.15971 , year =
Wei Wang, Dan Zhang, Tao Feng, Boyan Wang, and Jie Tang. Battleagentbench: A benchmark for evaluating cooperation and competition capabilities of language models in multi-agent systems, 2024. URL https://arxiv.org/abs/2408.15971
-
[40]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. In A. Globerson, L. Mackey, D. Bel...
-
[41]
SPIN -bench: How well do LLM s plan strategically and reason socially? In Second Conference on Language Modeling, 2025
Jianzhu Yao, Kevin Wang, Ryan Hsieh, Haisu Zhou, Tianqing Zou, Zerui Cheng, Zhangyang Wang, and Pramod Viswanath. SPIN -bench: How well do LLM s plan strategically and reason socially? In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=mgsS73kvOA
2025
-
[42]
Survey on Evaluation of LLM-based Agents
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar-Haim, Arman Cohan, and Michal Shmueli-Scheuer. Survey on evaluation of llm-based agents, 2025. URL https://arxiv.org/abs/2503.16416
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Deep sets
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexander J Smola. Deep sets. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/pap...
2017
- [44]
-
[45]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. In The Twelfth International Conference on Learning Representations, 2024 a . URL https://openreview.net/forum?id=oKn9c6ytLx
2024
-
[46]
SOTOPIA : Interactive evaluation for social intelligence in language agents
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and Maarten Sap. SOTOPIA : Interactive evaluation for social intelligence in language agents. In The Twelfth International Conference on Learning Representations, 2024 b . URL https://openreview.net/forum?id=mM7VurbA4r
2024
-
[47]
MultiAgentBench : Evaluating the collaboration and competition of LLM agents
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Zhe Wang, Zhenhailong Wang, Cheng Qian, Xiangru Tang, Heng Ji, and Jiaxuan You. M ulti A gent B ench : Evaluating the collaboration and competition of LLM agents. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of ...
-
[48]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[49]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[50]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.