Recognition: 2 theorem links
· Lean TheoremPokeGym: A Visually-Driven Long-Horizon Benchmark for Vision-Language Models
Pith reviewed 2026-05-10 17:55 UTC · model grok-4.3
The pith
PokeGym reveals that vision-language models bottleneck on recovering from physical deadlocks in long 3D tasks, not on planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PokeGym enforces strict visual-only input and automated evaluation in a 3D open-world game to show that physical deadlock recovery, rather than high-level planning, is the primary bottleneck for current vision-language models in long-horizon tasks, with a metacognitive divergence where weaker models suffer unaware deadlocks and advanced models suffer aware deadlocks.
What carries the argument
PokeGym benchmark that isolates raw RGB observations from an independent memory-scanning evaluator to test pure vision-based decision making in 30 long-horizon tasks with varying instruction granularities.
If this is right
- Models that improve deadlock recovery will achieve higher success on navigation and interaction tasks in complex environments.
- Advanced models recognize entrapment but still fail to act, suggesting a gap in action generation despite awareness.
- Integrating explicit spatial intuition into VLM architectures would address the main limitation identified.
- Task success rates will improve more from better recovery mechanisms than from enhanced planning modules.
Where Pith is reading between the lines
- Similar bottlenecks likely exist in other embodied AI settings like robotics navigation where physical stuck states occur frequently.
- Future benchmarks could measure awareness and recovery separately to track progress on this specific skill.
- Training data focused on recovery sequences from entrapment might close the performance gap faster than general scaling.
Load-bearing premise
That the Pokemon game environment and the memory-scanning evaluator provide a faithful test of pure vision-based decision making without any unintended information leakage or bias in task design.
What would settle it
If a VLM with added spatial modules or recovery training shows no reduction in deadlock rates or no improvement in task success compared to baselines, the claim that deadlock recovery is the primary bottleneck would be falsified.
Figures
















read the original abstract
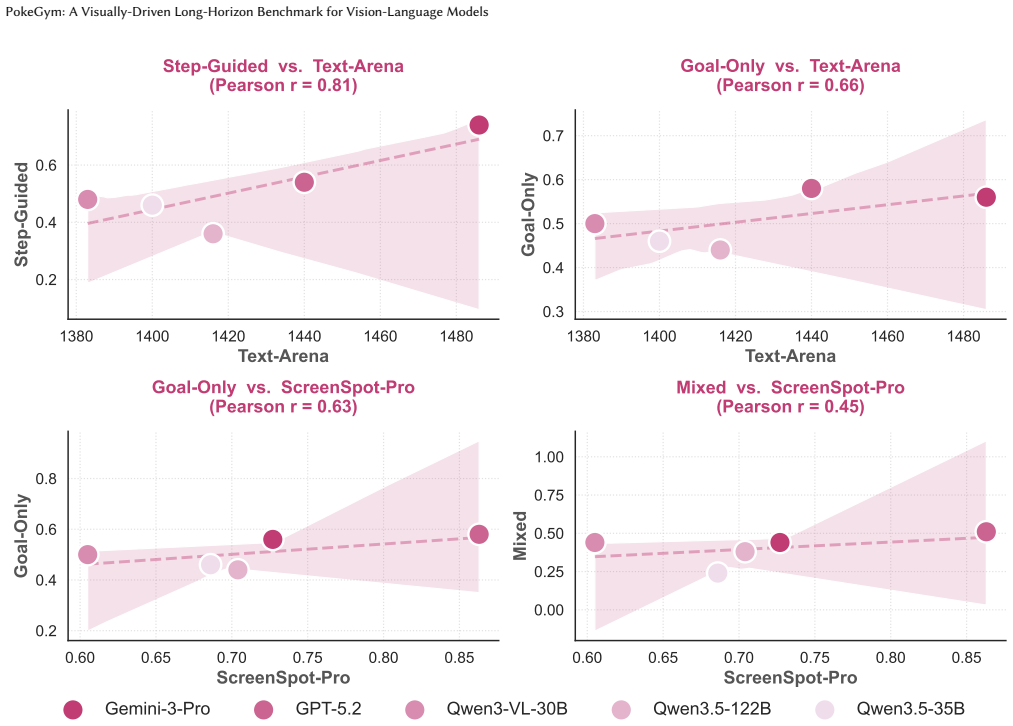
While Vision-Language Models (VLMs) have achieved remarkable progress in static visual understanding, their deployment in complex 3D embodied environments remains severely limited. Existing benchmarks suffer from four critical deficiencies: (1) passive perception tasks circumvent interactive dynamics; (2) simplified 2D environments fail to assess depth perception; (3) privileged state leakage bypasses genuine visual processing; and (4) human evaluation is prohibitively expensive and unscalable. We introduce PokeGym, a visually-driven long-horizon benchmark instantiated within Pokemon Legends: Z-A, a visually complex 3D open-world Role-Playing Game. PokeGym enforces strict code-level isolation: agents operate solely on raw RGB observations while an independent evaluator verifies success via memory scanning, ensuring pure vision-based decision-making and automated, scalable assessment. The benchmark comprises 30 tasks (30-220 steps) spanning navigation, interaction, and mixed scenarios, with three instruction granularities (Visual-Guided, Step-Guided, Goal-Only) to systematically deconstruct visual grounding, semantic reasoning, and autonomous exploration capabilities. Our evaluation reveals a key limitation of current VLMs: physical deadlock recovery, rather than high-level planning, constitutes the primary bottleneck, with deadlocks showing a strong negative correlation with task success. Furthermore, we uncover a metacognitive divergence: weaker models predominantly suffer from Unaware Deadlocks (oblivious to entrapment), whereas advanced models exhibit Aware Deadlocks (recognizing entrapment yet failing to recover). These findings highlight the need to integrate explicit spatial intuition into VLM architectures. The code and benchmark will be available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PokeGym, a benchmark for VLMs instantiated in the 3D open-world game Pokemon Legends: Z-A. It enforces strict visual isolation (raw RGB inputs only) with independent memory-scanning success verification, defines 30 long-horizon tasks (navigation, interaction, mixed) across three instruction granularities, and reports that physical deadlock recovery is the dominant failure mode (strong negative correlation with success) while revealing a metacognitive split: weaker models exhibit unaware deadlocks and stronger models exhibit aware deadlocks.
Significance. If the isolation and evaluation protocols hold, PokeGym supplies a scalable, automated, and reproducible testbed that directly targets embodied long-horizon reasoning gaps in current VLMs. The emphasis on deadlock recovery as the primary bottleneck, together with the planned GitHub release of code and tasks, offers a concrete, falsifiable direction for improving spatial intuition in VLM architectures.
major comments (2)
- [Methods / Benchmark Design] The central deadlock-bottleneck and metacognitive-divergence claims rest on the assumption that success criteria and deadlock states are fully recoverable from raw RGB alone. The methods section does not report an explicit visual-sufficiency audit (e.g., human or oracle inspection confirming that every task goal across the 30 tasks and three granularities can be inferred without memory leakage), which directly affects the validity of the reported correlations.
- [Evaluation Protocol and Results] Deadlock detection and the aware/unaware classification appear to rely on trajectory logging and model-output analysis. Without a precise operational definition (including how prompting, action-space discretization, or game-mechanic priors are controlled), it is unclear whether the observed split between weaker and advanced models is an architectural property or an artifact of evaluation choices.
minor comments (2)
- [Abstract and §3] The abstract states that the benchmark 'comprises 30 tasks (30-220 steps)'; the main text should include a table or appendix listing task IDs, step ranges, and success criteria for reproducibility.
- [Results figures] Figure captions and axis labels for the deadlock-success correlation plots should explicitly state the number of runs per model and the statistical test used to establish the 'strong negative correlation'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of benchmark validity and evaluation transparency, which we address point-by-point below. We have prepared revisions to incorporate additional methodological details and audits.
read point-by-point responses
-
Referee: [Methods / Benchmark Design] The central deadlock-bottleneck and metacognitive-divergence claims rest on the assumption that success criteria and deadlock states are fully recoverable from raw RGB alone. The methods section does not report an explicit visual-sufficiency audit (e.g., human or oracle inspection confirming that every task goal across the 30 tasks and three granularities can be inferred without memory leakage), which directly affects the validity of the reported correlations.
Authors: We agree that an explicit visual-sufficiency audit would further strengthen the claims. The manuscript already specifies code-level isolation (raw RGB inputs only to the agent) with independent memory-scanning verification, but we did not include a formal audit in the original submission. In the revised manuscript, we will add an appendix with a human inspection audit: for each of the 30 tasks and all three instruction granularities, we confirm that success conditions (e.g., object interaction or location reach) are visually distinguishable from raw RGB frames alone, without internal state access. Examples of key frames will be provided. revision: yes
-
Referee: [Evaluation Protocol and Results] Deadlock detection and the aware/unaware classification appear to rely on trajectory logging and model-output analysis. Without a precise operational definition (including how prompting, action-space discretization, or game-mechanic priors are controlled), it is unclear whether the observed split between weaker and advanced models is an architectural property or an artifact of evaluation choices.
Authors: We acknowledge the value of precise definitions to rule out artifacts. The original manuscript describes deadlock as the dominant failure mode with negative correlation to success and the aware/unaware split, but operational details were summarized rather than fully specified. In the revised Evaluation Protocol section, we will add: (1) deadlock detection criteria (no positional progress or repeated actions over a fixed step threshold, verified via trajectory logs for analysis only); (2) aware/unaware classification rules based on explicit model outputs acknowledging entrapment; and (3) controls for prompting templates, discretized action space, and absence of game-mechanic priors beyond visual input. These additions will clarify that the metacognitive divergence reflects model differences. revision: yes
Circularity Check
No circularity: empirical benchmark with independent experimental claims
full rationale
This paper introduces an empirical benchmark (PokeGym) and reports experimental findings on VLM performance in a 3D game environment. The key claims—physical deadlock recovery as primary bottleneck with negative correlation to success, and metacognitive divergence between unaware/aware deadlocks—are grounded in observed results from running models on 30 tasks across instruction granularities, using raw RGB inputs and independent memory-scanning verification. No derivations, equations, fitted parameters, predictions, or self-citations appear in the text that reduce to inputs by construction. The evaluation setup is presented as code-level isolation without any self-referential definitions or ansatz smuggling. This is a standard empirical benchmark paper whose central results are falsifiable via replication and do not rely on tautological steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
physical deadlock recovery, rather than high-level planning, constitutes the primary bottleneck, with deadlocks showing a strong negative correlation with task success
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Unaware Deadlocks (oblivious to entrapment), whereas advanced models exhibit Aware Deadlocks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2026. Claude Sonnet 4.6. https://www.anthropic.com/news/claude- sonnet-4-6
2026
-
[2]
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. 2015. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision. 2425–2433
2015
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, et al. 2025. Qwen3-VL Technical Report. arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
- [5]
-
[6]
Center for AI Safety, Scale AI, and HLE Contributors Consortium. 2026. A benchmark of expert-level academic questions to assess AI capabilities.Nature 649 (2026), 1139–1146. arXiv:2501.14249 [cs.LG] doi:10.1038/s41586-025-09962-4
work page internal anchor Pith review doi:10.1038/s41586-025-09962-4 2026
- [7]
-
[8]
Zhihong Chen, Ruifei Zhang, Yibing Song, Xiang Wan, and Guanbin Li. 2023. Advancing visual grounding with scene knowledge: Benchmark and method. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. 15039–15049
2023
-
[9]
Kanzhi Cheng, Wenpo Song, Jiaxin Fan, Zheng Ma, Qiushi Sun, Fangzhi Xu, Chenyang Yan, Nuo Chen, Jianbing Zhang, and Jiajun Chen. 2025. Caparena: Benchmarking and analyzing detailed image captioning in the llm era. InFindings of the Association for Computational Linguistics: ACL 2025. 14077–14094
2025
- [10]
-
[11]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems36 (2023), 49250–49267
2023
-
[12]
Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra. 2018. Embodied question answering. InProceedings of the IEEE conference on computer vision and pattern recognition. 1–10
2018
-
[13]
Google DeepMind. 2025. Gemini 3 Pro. https://deepmind.google/models/gemini/ pro/
2025
-
[14]
Ning Ding, Yehui Tang, Zhongqian Fu, Chao Xu, Kai Han, and Yunhe Wang
-
[15]
InCompanion Proceedings of the ACM on Web Conference
GPT4Image: Large Pre-trained Models Help Vision Models Learn Better on Perception Task. InCompanion Proceedings of the ACM on Web Conference
-
[16]
Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. 2022. MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowl- edge. InAdvances in Neural Information Processing Systems, S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. ...
2022
-
[17]
Qiaozi Gao, Govind Thattai, Suhaila Shakiah, Xiaofeng Gao, Shreyas Pansare, Vasu Sharma, Gaurav Sukhatme, Hangjie Shi, Bofei Yang, Desheng Zhang, et al
-
[18]
Alexa arena: A user-centric interactive platform for embodied ai.Advances in Neural Information Processing Systems36 (2023), 19170–19194
2023
- [19]
- [20]
- [21]
-
[22]
Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. 2025. Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos. (2025). https://arxiv.org/abs/2501.13826
work page internal anchor Pith review arXiv 2025
-
[23]
Xing, Ion Stoica, Tajana Rosing, Haojian Jin, and Hao Zhang
Lanxiang Hu, Mingjia Huo, Yuxuan Zhang, Haoyang Yu, Eric P. Xing, Ion Stoica, Tajana Rosing, Haojian Jin, and Hao Zhang. 2026. lmgame-Bench: How Good are LLMs at Playing Games?. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=qeziG97WUZ
2026
- [24]
-
[25]
Zixia Jia, Mengmeng Wang, Baichen Tong, Song-Chun Zhu, and Zilong Zheng
-
[26]
InFindings of the Association for Compu- tational Linguistics: ACL 2024
LangSuit·E: Planning, controlling and interacting with large language models in embodied text environments. InFindings of the Association for Compu- tational Linguistics: ACL 2024. 14778–14814
2024
-
[27]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=VTF8yNQM66
2024
-
[28]
Michał Kempka, Marek Wydmuch, Grzegorz Runc, et al . 2016. Vizdoom: A doom-based ai research platform for visual reinforcement learning. In2016 IEEE conference on computational intelligence and games (CIG). IEEE, 1–8
2016
-
[29]
Heinrich Küttler, Nantas Nardelli, Alexander Miller, et al. 2020. The nethack learning environment.Advances in Neural Information Processing Systems33 (2020), 7671–7684
2020
-
[30]
Tony Lee, Haoqin Tu, Chi H Wong, et al. 2024. Vhelm: A holistic evaluation of vision language models.Advances in Neural Information Processing Systems37 (2024), 140632–140666
2024
-
[31]
Guanzhen Li, Yuxi Xie, and Min-Yen Kan. 2024. MVP-Bench: Can Large Vision- Language Models Conduct Multi-level Visual Perception Like Humans?. InFind- ings of the Association for Computational Linguistics: EMNLP 2024. 13505–13527
2024
-
[32]
Kaixin Li, Meng Ziyang, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. 2025. ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use. InWorkshop on Reasoning and Plan- ning for Large Language Models. https://openreview.net/forum?id=XaKNDIAHas
2025
-
[33]
Muyao Li, Zihao Wang, Kaichen He, Xiaojian Ma, and Yitao Liang. 2025. Jarvis- vla: Post-training large-scale vision language models to play visual games with keyboards and mouse. InFindings of the Association for Computational Linguistics: ACL 2025. 17878–17899
2025
- [34]
- [35]
- [36]
-
[38]
Fan Lu, Wei Wu, Kecheng Zheng, Shuailei Ma, Biao Gong, Jiawei Liu, Wei Zhai, Yang Cao, Yujun Shen, and Zheng-Jun Zha. 2025. Benchmarking large vision- language models via directed scene graph for comprehensive image captioning. InProceedings of the Computer Vision and Pattern Recognition Conference. 19618– 19627
2025
-
[39]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, et al . 2025. Toolsandbox: A stateful, conversational, interactive evaluation benchmark for llm tool use capabilities. InFindings of the Association for Computational Linguistics: NAACL
2025
-
[40]
Feipeng Ma, Hongwei Xue, Yizhou Zhou, Guangting Wang, Fengyun Rao, Shilin Yan, Yueyi Zhang, Siying Wu, Mike Zheng Shou, and Xiaoyan Sun. 2024. Visual perception by large language model’s weights.Advances in Neural Information Processing Systems37 (2024), 28615–28635
2024
- [41]
-
[42]
Loïc Magne, Anas Awadalla, Guanzhi Wang, Yinzhen Xu, Joshua Belofsky, Fengyuan Hu, Joohwan Kim, Ludwig Schmidt, Georgia Gkioxari, Jan Kautz, Yisong Yue, Yejin Choi, Yuke Zhu, and Linxi "Jim" Fan. 2026. NitroGen: An Open Foundation Model for Generalist Gaming Agents. arXiv:2601.02427 [cs.CV] https://arxiv.org/abs/2601.02427
- [43]
-
[44]
Thomas Mensink, Jasper Uijlings, Lluis Castrejon, Arushi Goel, Felipe Cadar, Howard Zhou, Fei Sha, André Araujo, and Vittorio Ferrari. 2023. Encyclopedic vqa: Visual questions about detailed properties of fine-grained categories. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3113– 3124
2023
-
[45]
Filippo Momentè, Alessandro Suglia, Mario Giulianelli, Ambra Ferrari, Alexander Koller, Oliver Lemon, David Schlangen, Raquel Fernández, and Raffaella Bernardi
- [46]
-
[47]
Muhammad Umair Nasir, Steven James, and Julian Togelius. 2024. Gametraver- salbenchmark: Evaluating planning abilities of large language models through Ruizhi Zhang, Ye Huang, Yuangang Pan, Chuanfu Shen, Zhilin Liu, Ting Xie, Wen Li, and Lixin Duan traversing 2d game maps.Advances in Neural Information Processing Systems37 (2024), 31813–31827
2024
-
[48]
OpenAI. 2025. GPT-5.2. https://openai.com/index/introducing-gpt-5-2/
2025
-
[49]
OpenAI. 2026. GPT-5.4. https://openai.com/index/introducing-gpt-5-4/
2026
-
[50]
OpenAI. 2026. GPT-5.4 mini and nano. https://openai.com/index/introducing- gpt-5-4-mini-and-nano/
2026
-
[51]
Davide Paglieri, Bartłomiej Cupiał, Sam Coward, Ulyana Piterbarg, Maciej Wołczyk, Akbir Khan, Eduardo Pignatelli, Łukasz Kuciński, Lerrel Pinto, Rob Fergus, Jakob Nicolaus Foerster, Jack Parker-Holder, and Tim Rocktäschel. 2024. BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games.arXiv preprint arXiv:2411.13543(2024)
-
[52]
Dongmin Park, Minkyu Kim, Beongjun Choi, Junhyuck Kim, Keon Lee, Jonghyun Lee, Inkyu Park, Byeong-Uk Lee, Jaeyoung Hwang, Jaewoo Ahn, Ameya Sunil Mahabaleshwarkar, Bilal Kartal, Pritam Biswas, Yoshi Suhara, Kangwook Lee, and Jaewoong Cho. 2026. Orak: A Foundational Benchmark for Training and Evaluating LLM Agents on Diverse Video Games. InThe Fourteenth I...
2026
-
[53]
Marco Pleines, Daniel Addis, David Rubinstein, Frank Zimmer, Mike Preuss, and Peter Whidden. 2025. Pokémon Red via Reinforcement Learning. In2025 IEEE Conference on Games (CoG). 1–8. doi:10.1109/CoG64752.2025.11114399
- [54]
-
[55]
Yun Qu, Boyuan Wang, Jianzhun Shao, Yuhang Jiang, Chen Chen, Zhenbin Ye, Liu Linc, Yang Feng, Lin Lai, Hongyang Qin, et al . 2023. Hokoff: Real game dataset from honor of kings and its offline reinforcement learning benchmarks. Advances in Neural Information Processing Systems36 (2023), 22166–22190
2023
-
[56]
Qwen Team. 2026. Qwen3.5: Towards Native Multimodal Agents. https://qwen. ai/blog?id=qwen3.5
2026
-
[58]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2024. GPQA: A Graduate-Level Google-Proof Q&A Benchmark. InFirst Conference on Language Modeling. https://openreview.net/forum?id=Ti67584b98
2024
- [59]
-
[60]
Burak Satar, Zhixin Ma, Patrick Amadeus Irawan, Wilfried Ariel Mulyawan, Jing Jiang, Ee-Peng Lim, and Chong-Wah Ngo. 2025. Seeing culture: A benchmark for visual reasoning and grounding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 22238–22254
2025
-
[61]
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. 2020. ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10737– 10746. doi:10.1109/CVPR42600.2020.01075
-
[62]
Yuchong Sun, Che Liu, Kun Zhou, Jinwen Huang, Ruihua Song, Wayne Xin Zhao, Fuzheng Zhang, Di Zhang, and Kun Gai. 2024. Parrot: Enhancing multi- turn instruction following for large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9729–9750
2024
-
[63]
Sinan Tan, Weilai Xiang, Huaping Liu, Di Guo, and Fuchun Sun. 2020. Multi- agent embodied question answering in interactive environments. InEuropean Conference on Computer Vision. Springer, 663–678
2020
-
[64]
Weihao Tan, Changjiu Jiang, Yu Duan, Mingcong Lei, Li JiaGeng, Yitian Hong, Xinrun Wang, and Bo An. 2025. StarDojo: Benchmarking Open-Ended Behaviors of Agentic Multimodal LLMs in Production–Living Simulations with Stardew Valley. InFirst Workshop on Multi-Turn Interactions in Large Language Models. https://openreview.net/forum?id=R0mmX6BEau
2025
-
[65]
Weihao Tan, Xiangyang Li, Yunhao Fang, Heyuan Yao, Shi Yan, Hao Luo, Ten- glong Ao, Huihui Li, Hongbin Ren, Bairen Yi, Yujia Qin, Bo An, Libin Liu, and Guang Shi. 2025. Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds. arXiv:2511.08892 [cs.AI] https://arxiv.org/abs/2511.08892
-
[66]
Karlsson, Bo An, Shuicheng Yan, and Zongqing Lu
Weihao Tan, Wentao Zhang, Xinrun Xu, Haochong Xia, Ziluo Ding, Boyu Li, Bohan Zhou, Junpeng Yue, Jiechuan Jiang, Yewen Li, Ruyi An, Molei Qin, Chuqiao Zong, Longtao Zheng, Yujie Wu, Xiaoqiang Chai, Yifei Bi, Tianbao Xie, Pengjie Gu, Xiyun Li, Ceyao Zhang, Long Tian, Chaojie Wang, Xinrun Wang, Börje F. Karlsson, Bo An, Shuicheng Yan, and Zongqing Lu. 2025....
2025
-
[67]
Arena Team. 2026. Arena Leaderboard Dataset. https://arena.ai/blog/arena- leaderboard-dataset/
2026
-
[68]
Qwen Team. 2026. Qwen3.5: Accelerating Productivity with Native Multimodal Agents. https://qwen.ai/blog?id=qwen3.5
2026
- [69]
-
[70]
V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Chen, J...
work page internal anchor Pith review arXiv 2025
-
[71]
Tristan Tomilin, Meng Fang, Yudi Zhang, and Mykola Pechenizkiy. 2023. Coom: A game benchmark for continual reinforcement learning.Advances in Neural Information Processing Systems36 (2023), 67794–67832
2023
-
[72]
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian
-
[73]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 16022–16076
- [74]
-
[75]
Zihao Wang, Shaofei Cai, Anji Liu, Yonggang Jin, Jinbing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zilong Zheng, Yaodong Yang, et al. 2024. Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models.IEEE Transactions on Pattern Analysis and Machine Intelligence47, 3 (2024), 1894–1907
2024
-
[76]
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, Alexis Chevalier, Sanjeev Arora, and Danqi Chen. 2024. CharXiv: charting gaps in realistic chart under- standing in multimodal LLMs. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouv...
2024
-
[77]
Zirui Wang, Junyi Zhang, Jiaxin Ge, Long Lian, Letian Fu, Lisa Dunlap, Ken Goldberg, Xudong Wang, Ion Stoica, David M. Chan, Sewon Min, and Joseph E. Gonzalez. 2026. VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents.arXiv preprint arXiv:2601.16973(2026). https://arxiv.org/ abs/2601.16973
-
[78]
Iqramul Hoque, Shahriyar Zaman Ridoy, Mo- hammed Eunus Ali, Majd Hawasly, Mohammad Raza, and Md Rizwan Parvez
Azmine Toushik Wasi, Wahid Faisal, Abdur Rahman, Mahfuz Ahmed Anik, Munem Shahriar, Mohsin Mahmud Topu, Sadia Tasnim Meem, Rahatun Nesa Priti, Sabrina Afroz Mitu, Md. Iqramul Hoque, Shahriyar Zaman Ridoy, Mo- hammed Eunus Ali, Majd Hawasly, Mohammad Raza, and Md Rizwan Parvez
-
[79]
SpatiaLab: Can Vision-Language Models Perform Spatial Reasoning in the Wild? arXiv:2602.03916 [cs.CV] https://arxiv.org/abs/2602.03916
work page internal anchor Pith review arXiv
- [80]
-
[81]
Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Xin Guo, Dingwen Yang, Chenyang Liao, Wei He, et al . 2025. Agent- gym: Evaluating and training large language model-based agents across diverse environments. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 27914–27961
2025
-
[82]
Peng Xu, Wenqi Shao, Kaipeng Zhang, Peng Gao, Shuo Liu, Meng Lei, Fanqing Meng, Siyuan Huang, Yu Qiao, and Ping Luo. 2024. Lvlm-ehub: A comprehensive evaluation benchmark for large vision-language models.IEEE Transactions on Pattern Analysis and Machine Intelligence47, 3 (2024), 1877–1893
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.