Recognition: unknown
3D-ReGen: A Unified 3D Geometry Regeneration Framework
Pith reviewed 2026-05-07 06:24 UTC · model grok-4.3
The pith
3D-ReGen regenerates objects from initial 3D shapes with VecSet conditioning to unify enhancement, reconstruction, and editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that 3D generation can be reframed as regeneration from an initial 3D shape using a new VecSet conditioning mechanism. This formulation directly enables 3D enhancement, reconstruction, and editing within one model. The regenerator learns a broadly applicable regeneration prior from existing 3D datasets via self-supervised pretext tasks and augmentations, without additional annotations. The approach yields state-of-the-art performance in both geometric consistency and fine-grained detail quality for controllable 3D generation.
What carries the argument
VecSet-based conditioning mechanism that encodes the initial 3D shape so the regenerator can update it with consistent fine-grained details.
If this is right
- A single model supports 3D enhancement by refining coarse input shapes.
- 3D reconstruction becomes possible by regenerating from an initial estimate guided by 2D images.
- 3D editing is achieved by conditioning on user-modified initial shapes.
- The regeneration prior is learned without task-specific annotations or separate models.
- Controllability improves over one-shot generators while maintaining geometric consistency.
Where Pith is reading between the lines
- The same conditioning strategy could be tested on dynamic or multi-object scenes to check whether consistency holds beyond single rigid objects.
- Iterative application of the regenerator might allow progressive refinement starting from very rough initial shapes.
- The self-supervised prior could be combined with text-to-3D pipelines to refine coarse outputs into higher-detail geometry.
Load-bearing premise
That a VecSet conditioning mechanism combined with self-supervised pretext tasks on off-the-shelf 3D datasets will produce consistent fine-grained geometry updates without artifacts or the need for task-specific annotations.
What would settle it
Quantitative comparison on 3D benchmarks measuring whether regenerated outputs preserve input shape structure (via metrics such as Chamfer distance or normal consistency) while adding expected details, or whether visible artifacts appear in edited or enhanced regions.
Figures



















read the original abstract
We consider the problem of regenerating 3D objects from 2D images and initial 3D shapes. Most 3D generators operate in a one-shot fashion, converting text or images to a 3D object with limited controllability. We introduce instead 3D-ReGen, a 3D regenerator that is conditioned on an initial 3D shape. This conceptually simple formulation allows us to support numerous useful tasks, including 3D enhancement, reconstruction, and editing. 3D-ReGen uses a new conditioning mechanism based on VecSet, which allows the regenerator to update or improve the input geometry with consistent fine-grained details. 3D-ReGen learns a widely applicable regeneration prior from off-the-shelf 3D datasets via self-supervised pretext tasks and augmentations, without additional annotations. We evaluate both the geometric consistency and fine-grained quality of 3D-ReGen, achieving state-of-the-art performance in controllable 3D generation across several tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 3D-ReGen, a unified 3D geometry regeneration framework conditioned on an initial 3D shape via a VecSet-based mechanism. It supports 3D enhancement, reconstruction, and editing through self-supervised pretext tasks and augmentations learned from off-the-shelf 3D datasets without additional annotations. The central claim is that this single model achieves state-of-the-art performance in controllable 3D generation with strong geometric consistency and fine-grained quality.
Significance. If the empirical findings hold, the significance is high as it offers a versatile approach to unify several 3D tasks in one framework, improving controllability over one-shot generators. The self-supervised nature and detailed ablations on geometric perturbations and multi-view consistency losses are notable strengths that support the broad applicability claim. The quantitative evaluations with standard metrics (Chamfer distance, normal consistency, F-score) and comparisons to recent methods, along with qualitative results on diverse topologies, provide solid grounding for the SOTA assertions.
minor comments (2)
- [Abstract] The abstract claims SOTA results on geometric consistency and fine-grained quality but omits any specific metrics, baselines, or ablation details. Including a brief mention of key quantitative improvements would better support the claims.
- [Method] The VecSet conditioning mechanism is central to fine-grained updates; ensure that the integration with the regenerator architecture is described with sufficient detail, including any relevant equations or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the positive review, recognition of the high significance of our unified 3D regeneration framework, and the recommendation for minor revision. We are pleased that the self-supervised learning approach, geometric consistency evaluations, and SOTA claims were viewed favorably. Since no major comments were raised, we will focus on addressing any minor points in the revised manuscript.
Circularity Check
No significant circularity detected
full rationale
The paper introduces 3D-ReGen as a conditioned 3D regenerator using a VecSet-based mechanism trained via self-supervised pretext tasks and geometric augmentations on off-the-shelf 3D datasets. No equations, derivations, or load-bearing steps are presented that reduce the regeneration prior or performance claims to fitted parameters, self-citations, or inputs by construction. The self-supervised tasks (including perturbations and multi-view consistency) are described as independent of the target tasks of enhancement, reconstruction, and editing, with ablations and empirical metrics (Chamfer distance, normal consistency, F-score) providing external validation. The central claims rest on these empirical results rather than any self-referential chain, rendering the framework self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Neural networks trained with self-supervised pretext tasks on 3D shape augmentations will learn a regeneration prior that generalizes to real input shapes and images.
- domain assumption VecSet provides a conditioning mechanism that allows consistent fine-grained geometry updates without introducing inconsistencies.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Barda, A., Gadelha, M., Kim, V.G., Aigerman, N., Bermano, A.H., Groueix, T.: Instant3dit: Multiview inpainting for fast editing of 3d objects. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16273–16282 (2025) 13, 11
2025
-
[2]
arXiv preprint arXiv:2403.12032 (2024) 13, 11
Chen, H., Shi, R., Liu, Y., Shen, B., Gu, J., Wetzstein, G., Su, H., Guibas, L.: Generic 3d diffusion adapter using controlled multi-view editing. arXiv preprint arXiv:2403.12032 (2024) 13, 11
-
[3]
In: Proceedings of the European Conference on Computer Vi- sion (ECCV) (2024) 11
Chen, M., Laina, I., Vedaldi, A.: DGE: Direct gaussian 3D editing by consistent multi-view editing. In: Proceedings of the European Conference on Computer Vi- sion (ECCV) (2024) 11
2024
-
[4]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025) 8
Chen, M., Shapovalov, R., Laina, I., Monnier, T., Wang, J., Novotny, D., Vedaldi, A.: PartGen: Part-level 3D generation and reconstruction with multi-view diffusion models. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025) 8
2025
-
[5]
Autopartgen: Autogressive 3d part generation and discovery.arXiv preprint arXiv:2507.13346, 2025
Chen, M., Wang, J., Shapovalov, R., Monnier, T., Jung, H., Wang, D., Ranjan, R., Laina, I., Vedaldi, A.: Autopartgen: Autogressive 3d part generation and discovery. arXiv preprint arXiv:2507.13346 (2025) 5, 8, 10
-
[6]
In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2025) 7
Chen, M., Wang, J., Shapovalov, R., Monnier, T., Jung, H., Wang, D., Ranjan, R., Laina, I., Vedaldi, A.: AutoPartGen: Autogressive 3D part generation and discovery. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2025) 7
2025
-
[7]
Chen, R., Zhang, J., Liang, Y., Luo, G., Li, W., Liu, J., Li, X., Long, X., Feng, J., Tan, P.: Dora: Sampling and benchmarking for 3D shape variational auto-encoders. arXiv2412.17808(2024) 4
-
[8]
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., VanderBilt, E., Kembhavi, A., Vondrick, C., Gkioxari, G., Ehsani, K., Schmidt, L., Farhadi, A.: Objaverse-XL: A universe of 10M+ 3D objects. CoRRabs/2307.05663(2023) 4
-
[9]
In: Proc
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3D objects. In: Proc. CVPR (2023) 4, 8
2023
-
[11]
arXiv2411.16820(2024) 3, 4, 6, 13, 11
Deng, K., Guo, Y., Sun, J., Zou, Z., Li, Y., Cai, X., Cao, Y., Liu, Y., Liang, D.: DetailGen3D: generative 3D geometry enhancement via data-dependent flow. arXiv2411.16820(2024) 3, 4, 6, 13, 11
-
[12]
In: Proc
Downs, L., Francis, A., Koenig, N., Kinman, B., Hickman, R., Reymann, K., McHugh, T.B., Vanhoucke, V.: Google Scanned Objects: A high-quality dataset of 3D scanned household items. In: Proc. ICRA (2022) 7, 11, 12, 8, 10
2022
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gao, W., Wang, D., Fan, Y., Bozic, A., Stuyck, T., Li, Z., Dong, Z., Ranjan, R., Sarafianos, N.: 3D mesh editing using masked LRMs. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7154–7165 (2025) 9
2025
-
[14]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024) 11
work page internal anchor Pith review arXiv 2024
-
[15]
Journal of the Engineering Mechanics Division102(5), 749–756 (1976) 9, 3
Herrmann, L.R.: Laplacian-isoparametric grid generation scheme. Journal of the Engineering Mechanics Division102(5), 749–756 (1976) 9, 3
1976
-
[16]
Advances in Neural Information Processing Systems33, 6840–6851 (2020) 2
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems33, 6840–6851 (2020) 2
2020
-
[17]
In: Proc
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: LRM: Large reconstruction model for single image to 3D. In: Proc. ICLR (2024) 11
2024
-
[18]
Hunyuan3D, T., Yang, S., Yang, M., Feng, Y., Huang, X., Zhang, S., He, Z., Luo, D., Liu, H., Zhao, Y., Lin, Q., Lai, Z., Yang, X., Shi, H., Zhao, Z., Zhang, B., Yan, H., Wang, L., Liu, S., Zhang, J., Chen, M., Dong, L., Jia, Y., Cai, Y., Yu, J., Tang, Y., Guo, D., Yu, J., Zhang, H., Ye, Z., He, P., Wu, R., Wei, S., Zhang, C., Tan, Y., Sun, Y., Niu, L., Hu...
-
[19]
arXiv preprint arXiv:2509.21245 (2025) 3, 4, 12, 14, 8, 11
Hunyuan3D, T., Zhang, B., Guo, C., Liu, H., Yan, H., Shi, H., Huang, J., Yu, J., Li, K., Wang, P., et al.: Hunyuan3d-omni: A unified framework for controllable generation of 3d assets. arXiv preprint arXiv:2509.21245 (2025) 3, 4, 12, 14, 8, 11
-
[20]
In: Proc
Jin, H., Jiang, H., Tan, H., Zhang, K., Bi, S., Zhang, T., Luan, F., Snavely, N., Xu, Z.: LVSM: a large view synthesis model with minimal 3D inductive bias. In: Proc. ICLR (2025) 11
2025
-
[21]
In: Proceed- ings of the fourth Eurographics symposium on Geometry processing (2006) 11, 12
Kazhdan, M., Bolitho, M., Hoppe, H.: Poisson surface reconstruction. In: Proceed- ings of the fourth Eurographics symposium on Geometry processing (2006) 11, 12
2006
-
[22]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: Ma- pAnything: universal feed-forward metric 3D reconstruction. arXiv2509.13414 (2025) 9
work page internal anchor Pith review arXiv 2025
-
[23]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: FLUX.1 kontext: Flow matching for in-context image generation and editing in latent space. arXiv2506.15742(2025) 4, 9, 13
work page internal anchor Pith review arXiv 2025
-
[24]
Lei, B., Li, Y., Liu, X., Yang, S., Xu, L., Huang, J., Tang, R., Weng, H., Liu, J., Xu, J., Zhou, Z., Zhu, Y., Xing, J., Xu, J., Ma, C., Yan, X., Yang, Y., Wang, C., Xu, D., Ma, X., Chen, Y., Li, J., Yang, M., Zhang, S., Feng, Y., Huang, X., Luo, 3D-ReGen: A Unified 3D Geometry Regeneration Framework 17 D., He, Z., Jiang, P., Hu, C., Qin, Z., Miao, S., Li...
-
[26]
Li, L., Huang, Z., Feng, H., Zhuang, G., Chen, R., Guo, C., Sheng, L.: Voxhammer: Training-free precise and coherent 3d editing in native 3d space. arXiv preprint arXiv:2508.19247 (2025) 9, 12, 13, 11
-
[28]
Li, W., Liu, J., Yan, H., Chen, R., Liang, Y., Chen, X., Tan, P., Long, X.: Crafts- man3d: High-fidelity mesh generation with 3d native generation and interactive geometry refiner (2024) 4
2024
-
[29]
Li, W., Liu, J., Yan, H., Chen, R., Liang, Y., Chen, X., Tan, P., Long, X.: Crafts- man3d: High-fidelity mesh generation with 3d native generation and interactive geometry refiner. arXiv preprint arXiv:2405.14979 (2024) 11
-
[30]
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., Cao, Y.P.: TripoSG: high-fidelity 3D shape synthesis using large- scale rectified flow models. arXiv2502.06608(2025) 5, 6, 10
-
[32]
arXiv preprint arXiv:2505.14521 , year=
Li, Z., Wang, Y., Zheng, H., Luo, Y., Wen, B.: Sparc3D: Sparse representation and construction for high-resolution 3d shapes modeling. arXiv2505.14521(2025) 6, 8, 10, 11
-
[33]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv2511.10647(2025) 9
work page internal anchor Pith review arXiv 2025
-
[34]
Lin, S., Liu, B., Li, J., Yang, X.: Common diffusion noise schedules and sample steps are flawed. arXiv.csabs/2305.08891(2023) 1
-
[35]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t14
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t14
2023
-
[36]
In: Proc
Liu, A., Lin, C., Liu, Y., Long, X., Dou, Z., Guo, H.X., Luo, P., Wang, W.: Part123: Part-aware 3D reconstruction from a single-view image. In: Proc. SIGGRAPH (2024) 8
2024
-
[37]
In: European Conference on Computer Vision
Liu, F., Wang, H., Chen, W., Sun, H., Duan, Y.: Make-your-3d: Fast and consis- tent subject-driven 3d content generation. In: European Conference on Computer Vision. pp. 389–406. Springer (2024) 13, 11
2024
-
[38]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z14 18 G
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and trans- fer data with rectified flow. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z14 18 G. Y. Park et al
2023
-
[39]
ACM Computer Graphocs21(24) (1987) 4
Lorensen, W., Cline, H.: Marching cubes: A high resolution 3D surface construction algorithm. ACM Computer Graphocs21(24) (1987) 4
1987
-
[40]
In: Proc
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: Proc. ICLR (2019) 1
2019
-
[41]
In: Proc
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: SDEdit: guided image synthesis and editing with stochastic differential equations. In: Proc. ICLR (2022) 8, 2
2022
-
[42]
In: Proceedings of the nineteenth annual symposium on Computational geometry
Mitra, N.J., Nguyen, A.: Estimating surface normals in noisy point cloud data. In: Proceedings of the nineteenth annual symposium on Computational geometry. pp. 322–328 (2003) 9
2003
-
[43]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 6
work page internal anchor Pith review arXiv 2023
-
[44]
In: Proc
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proc. ICCV (2023) 3, 6
2023
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10684–10695 (2022) 1
2022
-
[46]
In: Proc
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. In: Proc. ICLR (2022) 10
2022
-
[47]
In: Proceedings of the 19th annual conference on Computer graphics and interactive techniques
Schroeder, W.J., Zarge, J.A., Lorensen, W.E.: Decimation of triangle meshes. In: Proceedings of the 19th annual conference on Computer graphics and interactive techniques. pp. 65–70 (1992) 9, 3
1992
-
[48]
In: Proceedings of the IEEE/CVF international conference on computer vision
Sella, E., Fiebelman, G., Hedman, P., Averbuch-Elor, H.: Vox-e: Text-guided voxel editing of 3d objects. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 430–440 (2023) 13, 11
2023
-
[49]
In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2024) 4, 11, 12
Siddiqui, Y., Kokkinos, F., Monnier, T., Kariya, M., Kleiman, Y., Garreau, E., Gafni, O., Neverova, N., Vedaldi, A., Shapovalov, R., Novotny, D.: Meta 3D As- set Gen: Text-to-mesh generation with high-quality geometry, texture, and PBR materials. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2024) 4, 11, 12
2024
-
[50]
Advances in Neural Information Processing Systems37, 9532–9564 (2024) 11
Siddiqui, Y., Monnier, T., Kokkinos, F., Kariya, M., Kleiman, Y., Garreau, E., Gafni, O., Neverova, N., Vedaldi, A., Shapovalov, R., et al.: Meta 3d assetgen: Text-to-mesh generation with high-quality geometry, texture, and pbr materials. Advances in Neural Information Processing Systems37, 9532–9564 (2024) 11
2024
-
[51]
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- basedgenerativemodelingthroughstochasticdifferentialequations.In:Proc.ICLR (2021) 2
2021
-
[52]
In: Proceedings of the 2004 Eurographics/ACM SIGGRAPH symposium on Geometry processing
Sorkine, O., Cohen-Or, D., Lipman, Y., Alexa, M., Rössl, C., Seidel, H.P.: Lapla- cian surface editing. In: Proceedings of the 2004 Eurographics/ACM SIGGRAPH symposium on Geometry processing. pp. 175–184 (2004) 9, 3
2004
-
[53]
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: LGM: Large multi-view Gaussian model for high-resolution 3D content creation. arXiv2402.05054(2024) 11
-
[54]
In: Proceedings of IEEE international conference on computer vision
Taubin, G.: Curve and surface smoothing without shrinkage. In: Proceedings of IEEE international conference on computer vision. pp. 852–857. IEEE (1995) 3
1995
-
[55]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023) 4 3D-ReGen: A Unified 3D Geometry Regeneration Framework 19
work page internal anchor Pith review arXiv 2023
-
[56]
TripoAI: Tripo3D text-to-3D (2024),https://www.tripo3d.ai2, 4, 10
2024
-
[57]
In: Proc
Wang, D., Jung, H., Monnier, T., Sohn, K., Zou, C., Xiang, X., Yeh, Y.Y., Liu, D., Huang, Z., Nguyen-Phuoc, T., Fan, Y., Oprea, S., Wang, Z., Shapovalov, R., Sarafianos, N., Groueix, T., Toisoul, A., Dhar, P., Chu, X., Chen, M., Park, G.Y., Ranjan, R., Vedaldi, A.: WorldGen: From text to traversable and interactive 3D worlds. In: Proc. CVPR (2026) 8
2026
-
[58]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025) 7, 9
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: VGGT: Visual geometry grounded transformer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025) 7, 9
2025
-
[59]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025) 11
2025
-
[60]
In: Proc
Wang, J., Thiesson, B., Xu, Y., Cohen, M.F.: Image and video segmentation by anisotropic kernel mean shift. In: Proc. ECCV (2004) 12
2004
-
[61]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π 3: Permutation-equivariant visual geometry learning. arXiv 2507.13347(2025) 9
work page internal anchor Pith review arXiv 2025
-
[63]
arXiv preprint arXiv:2404.12385 , year=
Wei, X., Zhang, K., Bi, S., Tan, H., Luan, F., Deschaintre, V., Sunkavalli, K., Su, H., Xu, Z.: Meshlrm: Large reconstruction model for high-quality meshes. arXiv preprint arXiv:2404.12385 (2024) 11, 12
-
[64]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025) 4
work page internal anchor Pith review arXiv 2025
-
[66]
arXiv preprint arXiv:2412.01506 (2024) 4
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506 (2024) 4
-
[67]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21469–21480 (2025) 11, 12, 15
2025
-
[69]
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models. arXiv preprint arXiv:2404.07191 (2024) 11, 12
work page internal anchor Pith review arXiv 2024
-
[70]
Advances in Neural Information Processing Systems36, 15903–15935 (2023) 11
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023) 11
2023
-
[71]
Advances in Neural Information Processing Systems36(2024) 11
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36(2024) 11
2024
-
[72]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xue, L., Gao, M., Xing, C., Martín-Martín, R., Wu, J., Xiong, C., Xu, R., Niebles, J.C., Savarese, S.: Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1179–1189 (2023) 11 20 G. Y. Park et al
2023
-
[73]
arXiv preprint arXiv:2506.21076 (2025) 4, 8
Yan, H., Luo, K., Li, W., Liang, Y., Li, S., Huang, J., Guo, C., Tan, P.: Posemaster: Generating 3d characters in arbitrary poses from a single image. arXiv preprint arXiv:2506.21076 (2025) 4, 8
-
[74]
Holopart: Generative 3d part amodal segmentation.arXiv preprint arXiv:2504.07943, 2025
Yang, Y., Guo, Y.C., Huang, Y., Zou, Z.X., Yu, Z., Li, Y., Cao, Y.P., Liu, X.: HoloPart: generative 3d part amodal segmentation. arXiv2504.07943(2025) 8
-
[75]
ACM Trans- actions on Graphics (TOG)43(6), 1–18 (2024) 11
Ye, C., Qiu, L., Gu, X., Zuo, Q., Wu, Y., Dong, Z., Bo, L., Xiu, Y., Han, X.: Sta- blenormal: Reducing diffusion variance for stable and sharp normal. ACM Trans- actions on Graphics (TOG)43(6), 1–18 (2024) 11
2024
-
[76]
arXiv preprint (2025) 15
Yenphraphai, J., Mirzaei, A., Chen, J., Zou, J., Tulyakov, S., Yeh, R.A., Wonka, P., Wang, C.: Shapegen4d: Towards high quality 4d shape generation from videos. arXiv preprint (2025) 15
2025
-
[77]
Yin, S., Zhang, Z., Tang, Z., Gao, K., Xu, X., Yan, K., Li, J., Chen, Y., Chen, Y., Shum, H.Y., et al.: Qwen-image-layered: Towards inherent editability via layer decomposition. arXiv preprint arXiv:2512.15603 (2025) 4
-
[78]
In: ACM Transactions on Graphics (2023) 2, 3, 5
Zhang, B., Tang, J., Niessner, M., Wonka, P.: 3DShape2VecSet: A 3D shape repre- sentation for neural fields and generative diffusion models. In: ACM Transactions on Graphics (2023) 2, 3, 5
2023
-
[79]
ACM Transactions On Graphics (TOG)42(4), 1–16 (2023) 10
Zhang, B., Tang, J., Niessner, M., Wonka, P.: 3dshape2vecset: A 3d shape repre- sentation for neural fields and generative diffusion models. ACM Transactions On Graphics (TOG)42(4), 1–16 (2023) 10
2023
-
[80]
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: GS-LRM: large reconstruction model for 3D Gaussian splatting. arXiv2404.19702(2024) 11
-
[81]
In: Proc
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., Yu, J.: CLAY: A controllable large-scale generative model for creating high-quality 3D assets. In: Proc. SIGGRAPH (2024) 2, 3, 4, 12, 14, 6, 8, 10, 11
2024
-
[82]
In: Proc
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proc. CVPR (2023) 7
2023
-
[83]
Zhang,Q.,Jian,X.,Zhang,X.,Wang,W.,Hou,J.:Supercarver:Texture-consistent 3d geometry super-resolution for high-fidelity surface detail generation. arXiv 2503.09439(2025) 11
-
[84]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018) 12
2018
-
[86]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zhao, Z., Lai, Z., Lin, Q., Zhao, Y., Liu, H., Yang, S., Feng, Y., Yang, M., Zhang, S., Yang, X., et al.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation. arXiv preprint arXiv:2501.12202 (2025) 4
work page internal anchor Pith review arXiv 2025
-
[87]
In: Proc
Zhao, Z., Liu, W., Chen, X., Zeng, X., Wang, R., Cheng, P., Fu, B., Chen, T., Yu, G., Gao, S.: Michelangelo: Conditional 3D shape generation based on shape- image-text aligned latent representation. In: Proc. NeurIPS (2023) 4 3D-ReGen: A Unified 3D Geometry Regeneration Framework 21
2023
-
[88]
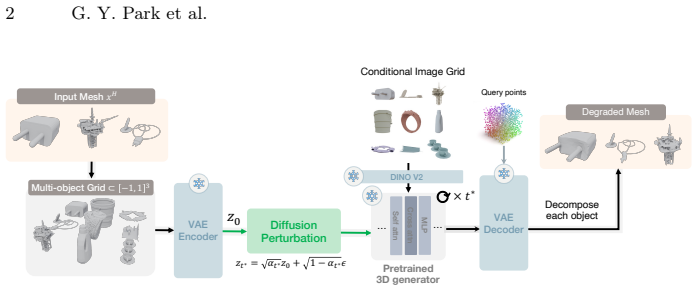
VAEEncoder Conditional Image Grid DINO V2 … Self attnCross attn⟳× 𝑡∗… MLPDiffusion Perturbation𝑧!∗=𝛼!∗𝑧
Zhuang, J., Kang, D., Cao, Y.P., Li, G., Lin, L., Shan, Y.: Tip-editor: An accurate 3d editor following both text-prompts and image-prompts. ACM Transactions on Graphics (TOG)43(4), 1–12 (2024) 13, 11 3D-ReGen: A Unified 3D Geometry Regeneration Framework 1 Supplementary Material of 3D-ReGen: A Unified 3D Geometry Regeneration Framework The supplementary ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.