Recognition: unknown
PhyCo: Learning Controllable Physical Priors for Generative Motion
Pith reviewed 2026-05-07 05:31 UTC · model grok-4.3
The pith
PhyCo conditions video diffusion models on explicit physical properties like friction and restitution to generate consistent motions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
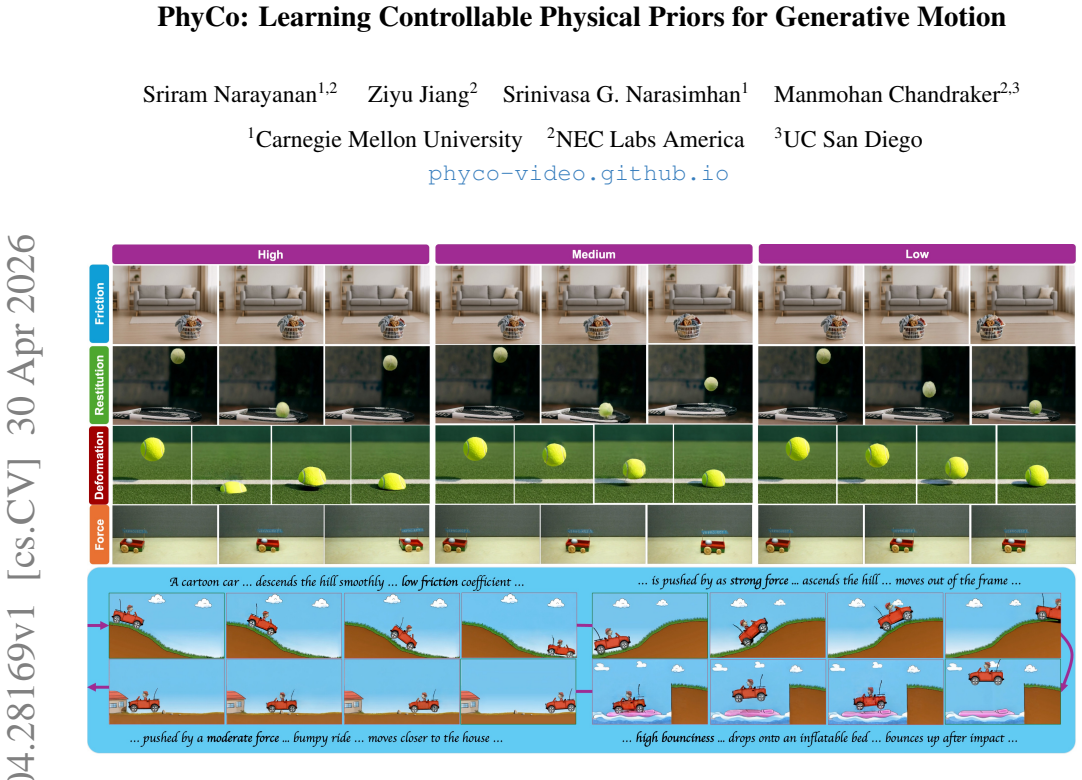
PhyCo integrates three components: a large-scale dataset of over 100K photorealistic simulation videos where friction, restitution, deformation, and force are systematically varied; physics-supervised fine-tuning of a pretrained diffusion model using a ControlNet conditioned on pixel-aligned physical property maps; and VLM-guided reward optimization in which a fine-tuned vision-language model evaluates generated videos with targeted physics queries and supplies differentiable feedback. This enables a generative model to produce physically consistent and controllable outputs through variations in physical attributes without any simulator or geometry reconstruction at inference. On the Physics
What carries the argument
The PhyCo framework of ControlNet-conditioned diffusion fine-tuning on pixel-aligned physical property maps combined with VLM-guided reward optimization.
If this is right
- Generative video models can vary outputs continuously along physical dimensions such as friction or restitution by changing the input property maps.
- Physical realism improves on the Physics-IQ benchmark without any simulator or geometry reconstruction required at test time.
- Human observers rate the control over physical attributes as clearer and more faithful than in baseline models.
- The same conditioning and reward mechanism supports generalization beyond the synthetic training environments to new scenes.
Where Pith is reading between the lines
- The approach could be adapted to condition on other measurable scene properties if suitable property maps and VLM queries can be defined.
- Combining the physical maps with existing text or image prompts would let users specify both appearance and mechanics in a single generation call.
- If the VLM reward generalizes reliably, it offers a way to curate or refine large-scale video training sets without exhaustive manual physics annotation.
Load-bearing premise
The fine-tuned vision-language model can reliably and differentiably evaluate physical properties such as friction, restitution, and deformation in generated videos and supply accurate reward signals that improve physical consistency without introducing new artifacts or degrading visual quality.
What would settle it
A head-to-head evaluation on the Physics-IQ benchmark in which PhyCo-generated videos show no measurable reduction in physical inconsistency metrics compared to strong unconditioned diffusion baselines.
Figures










read the original abstract
Modern video diffusion models excel at appearance synthesis but still struggle with physical consistency: objects drift, collisions lack realistic rebound, and material responses seldom match their underlying properties. We present PhyCo, a framework that introduces continuous, interpretable, and physically grounded control into video generation. Our approach integrates three key components: (i) a large-scale dataset of over 100K photorealistic simulation videos where friction, restitution, deformation, and force are systematically varied across diverse scenarios; (ii) physics-supervised fine-tuning of a pretrained diffusion model using a ControlNet conditioned on pixel-aligned physical property maps; and (iii) VLM-guided reward optimization, where a fine-tuned vision-language model evaluates generated videos with targeted physics queries and provides differentiable feedback. This combination enables a generative model to produce physically consistent and controllable outputs through variations in physical attributes-without any simulator or geometry reconstruction at inference. On the Physics-IQ benchmark, PhyCo significantly improves physical realism over strong baselines, and human studies confirm clearer and more faithful control over physical attributes. Our results demonstrate a scalable path toward physically consistent, controllable generative video models that generalize beyond synthetic training environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PhyCo, a framework for introducing continuous, interpretable physical control into video diffusion models. It combines (i) a 100K-scale dataset of photorealistic simulation videos with systematically varied friction, restitution, deformation, and force; (ii) ControlNet-based physics-supervised fine-tuning conditioned on pixel-aligned physical property maps; and (iii) VLM-guided reward optimization, in which a fine-tuned vision-language model issues targeted physics queries and supplies differentiable rewards. The method claims to produce physically consistent, controllable outputs at inference without any simulator or geometry reconstruction, with significant gains on the Physics-IQ benchmark and improved human-rated control.
Significance. If the central results hold, the work offers a practical route toward physically grounded generative video models that remain controllable via explicit physical attributes. The large simulation dataset and the integration of ControlNet conditioning with VLM feedback constitute a scalable alternative to explicit physics engines. Credit is due for the attempt to make physical parameters both continuous and interpretable. However, the significance is tempered by the absence of quantitative validation that the VLM component actually tracks ground-truth physics rather than model-specific artifacts.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the claim that PhyCo 'significantly improves physical realism' on Physics-IQ supplies no numerical scores, deltas versus baselines, ablation tables, or error bars. Without these data it is impossible to determine whether the reported lift is attributable to the VLM reward loop, the ControlNet stage, or the dataset alone.
- [§3.3] §3.3 (VLM-guided reward optimization): the manuscript must demonstrate that the fine-tuned VLM’s scalar or ranking outputs correlate with ground-truth simulation parameters (friction, restitution, deformation). Correlation coefficients, MAE, or rank-order statistics between VLM predictions and simulator labels are required; absent this evidence the optimization loop may be fitting VLM idiosyncrasies rather than physics, undermining both the Physics-IQ gains and the controllability claims.
- [§5] §5 (Human Studies): the description of the human evaluation lacks participant count, rating protocol, inter-rater reliability, statistical tests, and direct comparison tables against baselines. These details are load-bearing for the assertion of 'clearer and more faithful control over physical attributes.'
minor comments (2)
- [§3.2] The construction and pixel-alignment procedure for the physical property maps (mentioned in §3.2) should be illustrated with a diagram or pseudocode; the current textual description leaves the exact conditioning mechanism unclear.
- [§3] Notation for physical parameters (e.g., how restitution is encoded in the ControlNet input) is used inconsistently between the method section and the dataset description; a single table of symbols would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where additional quantitative evidence will strengthen the manuscript. We address each major comment below and have prepared revisions to incorporate the requested data, analyses, and details.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim that PhyCo 'significantly improves physical realism' on Physics-IQ supplies no numerical scores, deltas versus baselines, ablation tables, or error bars. Without these data it is impossible to determine whether the reported lift is attributable to the VLM reward loop, the ControlNet stage, or the dataset alone.
Authors: We agree that the abstract and Section 4 would benefit from explicit numerical support. In the revised manuscript we will add a results table reporting Physics-IQ scores for PhyCo and all baselines, absolute and relative deltas, component-wise ablations (dataset only, ControlNet fine-tuning, full VLM optimization), and error bars computed across multiple random seeds. These additions will make the source of the observed gains transparent. revision: yes
-
Referee: [§3.3] §3.3 (VLM-guided reward optimization): the manuscript must demonstrate that the fine-tuned VLM’s scalar or ranking outputs correlate with ground-truth simulation parameters (friction, restitution, deformation). Correlation coefficients, MAE, or rank-order statistics between VLM predictions and simulator labels are required; absent this evidence the optimization loop may be fitting VLM idiosyncrasies rather than physics, undermining both the Physics-IQ gains and the controllability claims.
Authors: We concur that direct validation of the VLM against simulator ground truth is essential. We have conducted this analysis on a held-out set of simulation videos. The revised Section 3.3 will report Pearson and Spearman correlation coefficients, mean absolute error, and rank-order statistics for each physical parameter (friction, restitution, deformation). These results will be accompanied by scatter plots to demonstrate that the VLM predictions align with ground-truth values, thereby confirming that the reward loop optimizes for physics rather than model-specific artifacts. revision: yes
-
Referee: [§5] §5 (Human Studies): the description of the human evaluation lacks participant count, rating protocol, inter-rater reliability, statistical tests, and direct comparison tables against baselines. These details are load-bearing for the assertion of 'clearer and more faithful control over physical attributes.'
Authors: We acknowledge the omission of these methodological details. In the revised Section 5 we will specify the participant count, the exact rating protocol (including attribute-specific Likert scales), inter-rater reliability measures, the statistical tests performed (with p-values), and a comparison table of mean ratings versus baselines. The expanded description will also reference the supplementary material for the full questionnaire and consent procedure. revision: yes
Circularity Check
No circularity: claims rest on external benchmark and human evaluation rather than internal fitting or self-referential derivation.
full rationale
The paper constructs a 100K simulation dataset with controlled physical parameters, performs standard physics-supervised fine-tuning of a diffusion model via ControlNet on pixel-aligned maps, and applies VLM-guided reward optimization. The central results (improved Physics-IQ scores and human-rated control) are measured against an external benchmark and separate human studies. No equations, self-citations, or ansatzes are shown to reduce the reported gains to quantities fitted inside the same loop by construction. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Simulation videos with systematically varied friction, restitution, deformation, and force accurately represent the corresponding real-world physical behaviors.
- domain assumption A fine-tuned vision-language model can produce reliable, differentiable scores for targeted physics queries on generated video frames.
Reference graph
Works this paper leans on
-
[1]
Cophy: Counterfactual learning of physi- cal dynamics.arXiv preprint arXiv:1909.12000, 2019
Fabien Baradel, Natalia Neverova, Julien Mille, Greg Mori, and Christian Wolf. Cophy: Counterfactual learning of physi- cal dynamics.arXiv preprint arXiv:1909.12000, 2019. 2
-
[2]
Physion: Evaluating physical prediction from vision in humans and machines
Daniel M Bear, Elias Wang, Damian Mrowca, Felix J Binder, Hsiao-Yu Fish Tung, RT Pramod, Cameron Holdaway, Sirui Tao, Kevin Smith, Fan-Yun Sun, et al. Physion: Evaluating physical prediction from vision in humans and machines. arXiv preprint arXiv:2106.08261, 2021. 2
-
[3]
Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023. 6
2023
-
[4]
Blender – a 3d modelling and rendering package
Blender Online Community. Blender – a 3d modelling and rendering package. http://www.blender.org, 2018. 2, 4
2018
-
[5]
Pymunk.https://pymunk.org
Victor Blomqvist. Pymunk.https://pymunk.org. 3
-
[6]
Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise
Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Mingming He, Li Ma, Yitong Deng, Lingxiao Li, Mohsen Mousavi, Michael Ryoo, Paul Debevec, and Ning Yu. Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 13–2...
2025
-
[7]
Vid2sim: Generalizable, video-based reconstruction of appearance, ge- ometry and physics for mesh-free simulation
Chuhao Chen, Zhiyang Dou, Chen Wang, Yiming Huang, Anjun Chen, Qiao Feng, Jiatao Gu, and Lingjie Liu. Vid2sim: Generalizable, video-based reconstruction of appearance, ge- ometry and physics for mesh-free simulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26545–26555, 2025. 3
2025
-
[8]
Zhenfang Chen, Kexin Yi, Yunzhu Li, Mingyu Ding, Antonio Torralba, Joshua B Tenenbaum, and Chuang Gan. Comphy: Compositional physical reasoning of objects and events from videos.arXiv preprint arXiv:2205.01089, 2022. 2
-
[9]
Directly fine-tuning diffusion models on differentiable re- wards, 2024
Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable re- wards, 2024. 4
2024
-
[10]
Pybullet, a python module for physics simu- lation for games, robotics and machine learning
Erwin Coumans. Pybullet, a python module for physics simu- lation for games, robotics and machine learning. InProceed- ings of the ACM SIGGRAPH 2016 Talks. ACM, 2016. 2, 4, 1
2016
-
[11]
Force prompting: Video generation models can learn and generalize physics-based control signals, 2025
Nate Gillman, Charles Herrmann, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun. Force prompting: Video generation models can learn and generalize physics-based control signals, 2025. 2, 3, 4, 6, 8
2025
-
[12]
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapra- gasam, Florian Golemo, Charles Herrmann, Thomas Kipf, Ab- hijit Kundu, Dmitry Lagun, Issam Laradji, Hsueh-Ti (Derek) Liu, Henning Meyer, Yishu Miao, Derek Nowrouzezahrai, Cengiz Oztireli, Etienne Pot, Noha Radwan, Daniel Rebain, Sara Sabour,...
2022
-
[13]
Shapestacks: Learning vision-based physical in- tuition for generalised object stacking
Oliver Groth, Fabian B Fuchs, Ingmar Posner, and Andrea Vedaldi. Shapestacks: Learning vision-based physical in- tuition for generalised object stacking. InProceedings of the european conference on computer vision (eccv), pages 702–717, 2018. 2
2018
-
[14]
Ltx-video: Realtime video latent diffusion, 2024
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weiss- buch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. Ltx-video: Realtime video latent diffusion, 2024. 6
2024
-
[15]
Cameractrl: Enabling camera control for text-to-video generation, 2024
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation, 2024. 3
2024
-
[16]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video gen- eration via transformers.arXiv preprint arXiv:2205.15868,
work page internal anchor Pith review arXiv
-
[17]
The material point method for simulating continuum materials
Chenfanfu Jiang, Craig Schroeder, Joseph Teran, Alexey Stomakhin, and Andrew Selle. The material point method for simulating continuum materials. InACM SIGGRAPH 2016 Courses, New York, NY , USA, 2016. Association for Computing Machinery. 3
2016
-
[18]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Sys- tems, pages 26565–26577. Curran Associates, Inc., 2022. 5, 1
2022
-
[19]
Analyzing and improving the training dynamics of diffusion models
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24174–24184, 2024. 5, 1
2024
-
[20]
Learning an im- age editing model without image editing pairs.arXiv preprint arXiv:, 2025
Nupur Kumari, Sheng-Yu Wang, Nanxuan Zhao, Yotam Nitzan, Yuheng Li, Krishna Kumar Singh, Richard Zhang, Eli Shechtman, Jun-Yan Zhu, and Xun Huang. Learning an im- age editing model without image editing pairs.arXiv preprint arXiv:, 2025. 4, 5
2025
-
[21]
Pisa experiments: Exploring physics post-training for video diffusion models by watching stuff drop, 2025
Chenyu Li, Oscar Michel, Xichen Pan, Sainan Liu, Mike Roberts, and Saining Xie. Pisa experiments: Exploring physics post-training for video diffusion models by watching stuff drop, 2025. 2, 4
2025
-
[22]
Wonderplay: Dynamic 3d scene generation from a single image and actions
Zizhang Li, Hong-Xing Yu, Wei Liu, Yin Yang, Charles Herrmann, Gordon Wetzstein, and Jiajun Wu. Wonderplay: Dynamic 3d scene generation from a single image and actions. InProceedings of the IEEE/CVF international conference on computer vision, 2025. 2, 3
2025
-
[23]
Fr ´echet video motion distance: A metric for evaluating motion consistency in videos, 2024
Jiahe Liu, Youran Qu, Qi Yan, Xiaohui Zeng, Lele Wang, and Renjie Liao. Fr ´echet video motion distance: A metric for evaluating motion consistency in videos, 2024. 2
2024
-
[24]
Springer Nature Switzer- land, 2024
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang.PhysGen: Rigid-Body Physics-Grounded Image-to- Video Generation, page 360–378. Springer Nature Switzer- land, 2024. 2, 3
2024
-
[25]
Dual-process image generation, 2025
Grace Luo, Jonathan Granskog, Aleksander Holynski, and Trevor Darrell. Dual-process image generation, 2025. 4, 5
2025
-
[26]
Do generative video models understand physical principles?, 2025
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles?, 2025. 2, 6
2025
-
[27]
Koichi Namekata, Sherwin Bahmani, Ziyi Wu, Yash Kant, Igor Gilitschenski, and David B. Lindell. Sg-i2v: Self-guided trajectory control in image-to-video generation, 2025. 6
2025
-
[28]
Cosmos world foundation model platform for physical ai, 2025
NVIDIA, :, Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, Daniel Dworakowski, Jiaojiao Fan, Michele Fenzi, Francesco Ferroni, Sanja Fidler, Dieter Fox, Songwei Ge, Yunhao Ge, Jinwei Gu, Siddharth Gururani, Ethan He, Jiahui Huang, Jacob Huffman, Pooya Jannaty, Ji...
2025
-
[29]
Aligning text-to-image diffusion models with reward backpropagation, 2024
Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, and Ka- terina Fragkiadaki. Aligning text-to-image diffusion models with reward backpropagation, 2024. 4
2024
-
[30]
Video diffusion align- ment via reward gradients, 2024
Mihir Prabhudesai, Russell Mendonca, Zheyang Qin, Kate- rina Fragkiadaki, and Deepak Pathak. Video diffusion align- ment via reward gradients, 2024. 4
2024
-
[31]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Jun- yang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao L...
2025
-
[32]
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, V´eronique Izard, and Emmanuel Dupoux. Intphys: A framework and benchmark for visual intuitive physics reasoning.arXiv preprint arXiv:1803.07616,
-
[33]
Physmotion: Physics- grounded dynamics from a single image, 2024
Xiyang Tan, Ying Jiang, Xuan Li, Zeshun Zong, Tianyi Xie, Yin Yang, and Chenfanfu Jiang. Physmotion: Physics- grounded dynamics from a single image, 2024. 3
2024
-
[34]
Maham Tanveer, Yang Zhou, Simon Niklaus, Ali Mahdavi Amiri, Hao Zhang, Krishna Kumar Singh, and Nanxuan Zhao. Motionbridge: Dynamic video inbetweening with flexible controls.arXiv preprint arXiv:2412.13190, 2024. 3
-
[35]
Tenenbaum, Daniel LK Yamins, Ju- dith E Fan, and Kevin A
Hsiao-Yu Tung, Mingyu Ding, Zhenfang Chen, Daniel Bear, Chuang Gan, Joshua B. Tenenbaum, Daniel LK Yamins, Ju- dith E Fan, and Kevin A. Smith. Physion++: Evaluating physical scene understanding that requires online inference of different physical properties, 2023. 2
2023
-
[36]
Ati: Any trajectory instruction for controllable video generation, 2025
Angtian Wang, Haibin Huang, Jacob Zhiyuan Fang, Yiding Yang, and Chongyang Ma. Ati: Any trajectory instruction for controllable video generation, 2025. 3
2025
-
[37]
Physctrl: Generative physics for controllable and physics-grounded video genera- tion
Chen Wang*, Chuhao Chen*, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu. Physctrl: Generative physics for controllable and physics-grounded video genera- tion. InNeurIPS, 2025. 2, 3
2025
-
[38]
Jiawei Wang, Yuchen Zhang, Jiaxin Zou, Yan Zeng, Guoqiang Wei, Liping Yuan, and Hang Li. Boximator: Generating rich and controllable motions for video synthesis.arXiv preprint arXiv:2402.01566, 2024. 3
-
[39]
Draganything: Motion control for any- thing using entity representation
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, and Di Zhang. Draganything: Motion control for any- thing using entity representation. InEuropean Conference on Computer Vision, pages 331–348. Springer, 2024. 3
2024
-
[40]
Physgaussian: Physics- integrated 3d gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. Physgaussian: Physics- integrated 3d gaussians for generative dynamics. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4389–4398, 2024. 3
2024
-
[41]
Physanimator: Physics-guided generative cartoon animation
Tianyi Xie, Yiwei Zhao, Ying Jiang, and Chenfanfu Jiang. Physanimator: Physics-guided generative cartoon animation. InProceedings of the Computer Vision and Pattern Recogni- tion Conference (CVPR), pages 10793–10804, 2025. 3
2025
-
[42]
Dejia Xu, Weili Nie, Chao Liu, Sifei Liu, Jan Kautz, Zhangyang Wang, and Arash Vahdat. Camco: Camera- controllable 3d-consistent image-to-video generation.arXiv preprint arXiv:2406.02509, 2024. 3
-
[43]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. InAdvances in Neural Information Processing Systems, pages 15903–15935. Curran Associates, Inc., 2023. 4
2023
-
[44]
Direct-a-video: Customized video generation with user- directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-video: Customized video generation with user- directed camera movement and object motion. InACM SIG- GRAPH 2024 Conference Papers, pages 1–12, 2024. 3
2024
-
[45]
Vlipp: Towards physically plausible video generation with vision and language informed physical prior, 2025
Xindi Yang, Baolu Li, Yiming Zhang, Zhenfei Yin, Lei Bai, Liqian Ma, Zhiyong Wang, Jianfei Cai, Tien-Tsin Wong, Huchuan Lu, and Xu Jia. Vlipp: Towards physically plausible video generation with vision and language informed physical prior, 2025. 2, 3, 6
2025
-
[46]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 6, 8
work page internal anchor Pith review arXiv 2024
-
[47]
Clevrer: Collision events for video representation and reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning.arXiv preprint arXiv:1910.01442, 2019. 2
-
[48]
arXiv preprint arXiv:2308.08089 , year=
Shengming Yin, Chenfei Wu, Jian Liang, Jie Shi, Houqiang Li, Gong Ming, and Nan Duan. Dragnuwa: Fine-grained control in video generation by integrating text, image, and trajectory.arXiv preprint arXiv:2308.08089, 2023. 3
-
[49]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In 2023 IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 3813–3824, 2023. 2, 4
2023
-
[50]
Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y . Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T. Freeman. PhysDreamer: Physics-based interaction with 3d objects via video generation. InEuropean Conference on Computer Vision. Springer, 2024. 2, 3
2024
-
[51]
arXiv preprint arXiv:2410.15957 , year=
Guangcong Zheng, Teng Li, Rui Jiang, Yehao Lu, Tao Wu, and Xi Li. Cami2v: Camera-controlled image-to-video diffu- sion model.arXiv preprint arXiv:2410.15957, 2024. 3
-
[52]
Reconstruction and simulation of elastic objects with spring- mass 3d gaussians
Licheng Zhong, Hong-Xing Yu, Jiajun Wu, and Yunzhu Li. Reconstruction and simulation of elastic objects with spring- mass 3d gaussians. InEuropean Conference on Computer Vision, pages 407–423. Springer, 2024. 3 PhyCo: Learning Controllable Physical Priors for Generative Motion Supplementary Material A. Video Results on Webpage All video results are availa...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.