Recognition: 2 theorem links
· Lean TheoremSelf-Mined Hardness for Safety Fine-Tuning
Pith reviewed 2026-05-08 18:17 UTC · model grok-4.3
The pith
Models can improve safety fine-tuning by selecting prompts based on how often their own responses are judged harmful.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
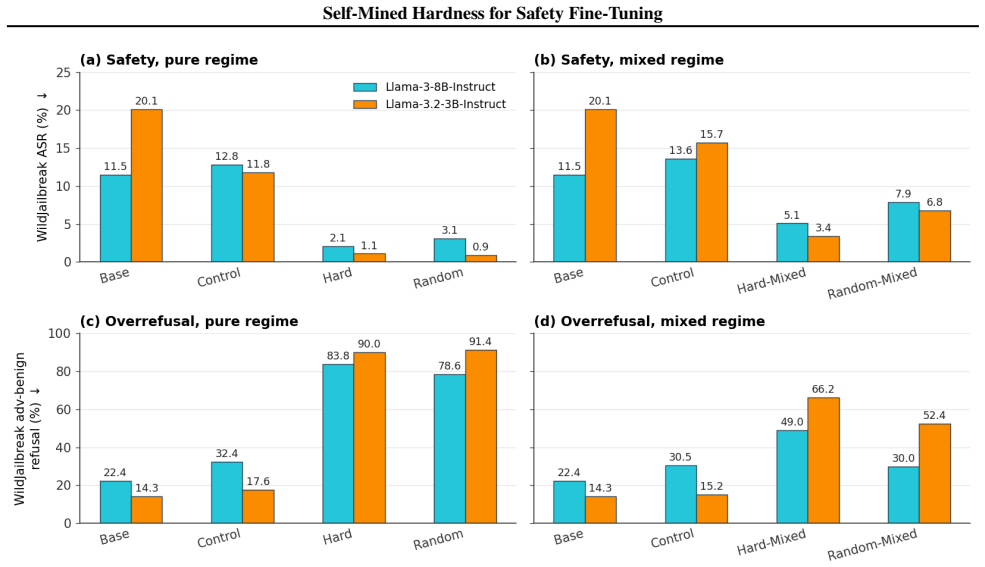
Scoring each candidate prompt by the share of the model's own rollouts judged harmful, then fine-tuning on the hardest prompts together with the model's safe responses, lowers WildJailbreak attack success from 11.5 percent and 20.1 percent to 1-3 percent on the 8B and 3B Llama-3 variants while the addition of 1:1 adversarially framed benign prompts reduces over-refusal from 74-94 percent back to 30-72 percent at only a 2-6 point cost in attack success.
What carries the argument
self-mined hardness, the fraction of a model's own outputs on a prompt that an external judge labels harmful, used to rank and select training examples
Load-bearing premise
The frequency with which the model's own answers are judged harmful is a reliable indicator of how useful that prompt will be for safety fine-tuning.
What would settle it
A controlled test in which prompts ranked high by self-mined hardness do not produce higher rates of harmful model responses than low-ranked prompts would falsify the selection criterion.
Figures
read the original abstract
Safety fine-tuning of language models typically requires a curated adversarial dataset. We take a different approach: score each candidate prompt's difficulty by how often the target model's own rollouts are judged harmful, then fine-tune on the hardest prompts paired with the model's own non-jailbroken rollouts. On Llama-3-8B-Instruct and Llama-3.2-3B-Instruct, this approach cuts the WildJailbreak attack success rate from 11.5% and 20.1% down to 1-3%, but pushes refusal on jailbreak-shaped benign prompts from 14-22% to 74-94%. Interleaving the same hard prompts 1:1 with adversarially-framed benign prompts (prompts that look like jailbreaks but have benign intent) cuts that refusal back down to 30-51% on 8B and 52-72% on 3B, at a cost of 2-6 percentage points of attack success rate. Within the mixed regime, training on the hardest half of the eligible pool rather than a random half cuts the remaining ASR by 35-50% (about 3 percentage points) on both models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-mining approach to safety fine-tuning in which candidate prompts are scored by the fraction of the target model's own rollouts that an external judge labels harmful; the model is then fine-tuned on the hardest prompts paired with its own safe responses. On Llama-3-8B-Instruct and Llama-3.2-3B-Instruct the method reduces WildJailbreak attack success rate from 11.5% and 20.1% to 1-3%, while raising over-refusal on jailbreak-shaped benign prompts from 14-22% to 74-94%. Interleaving the hard prompts 1:1 with adversarially-framed benign prompts lowers over-refusal to 30-51% (8B) and 52-72% (3B) at the cost of 2-6 percentage points in ASR; within this mixed regime, training on the hardest half of the pool rather than a random half further cuts remaining ASR by 35-50% (approximately 3 pp).
Significance. If the hardness signal proves robust, the approach supplies a scalable, largely automated route to high-difficulty safety data that does not require large-scale manual curation of adversarial examples. The concrete ASR reductions and the practical interleaving mitigation are potentially useful for production alignment pipelines. The additional gain from selecting the hardest subset within the mixed regime is a modest but falsifiable empirical finding that could be replicated on other models and benchmarks.
major comments (3)
- [Abstract] Abstract: the central claim that self-mined hardness yields the reported 11.5%→1-3% and 20.1%→1-3% ASR reductions rests on the external harm judgment used to score prompts. The manuscript supplies no information on judge identity, number of rollouts per prompt, sampling temperature, or any calibration against human labels, leaving open the possibility that the selected set simply triggers the judge's particular refusal heuristics rather than reflecting genuine prompt difficulty.
- [Abstract] Abstract: no statistical significance, standard deviations across runs, or exact training hyperparameters (learning rate, epochs, batch size) are reported for any of the fine-tuning experiments. Without these, it is impossible to determine whether the 1-3% ASR figures or the 35-50% relative improvement from the hardest-half selection are reliable or could be explained by run-to-run variance.
- [Abstract] Abstract: the construction of the 'adversarially-framed benign prompts' used for interleaving is not described. Because these prompts are central to the over-refusal mitigation result (74-94% → 30-51%/52-72%), the lack of detail on how they are generated or filtered makes it difficult to assess whether the mitigation generalizes or merely trades one form of bias for another.
minor comments (2)
- The abstract refers to 'WildJailbreak' without citation or a one-sentence description of the benchmark; a brief parenthetical or reference would aid readers unfamiliar with the dataset.
- The phrase 'eligible pool' in the final sentence of the abstract is undefined; clarifying whether it includes only prompts that produced at least one harmful rollout, or all candidate prompts, would improve precision.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We address each of the major comments below and have prepared revisions to enhance the clarity, reproducibility, and completeness of the manuscript.
read point-by-point responses
-
Referee: the central claim that self-mined hardness yields the reported 11.5%→1-3% and 20.1%→1-3% ASR reductions rests on the external harm judgment used to score prompts. The manuscript supplies no information on judge identity, number of rollouts per prompt, sampling temperature, or any calibration against human labels, leaving open the possibility that the selected set simply triggers the judge's particular refusal heuristics rather than reflecting genuine prompt difficulty.
Authors: We appreciate the referee highlighting the need for transparency regarding the external harm judgment process. We will revise the manuscript to include detailed information on the judge model used, the number of rollouts per prompt, the sampling temperature, and any available calibration details against human labels. This addition will allow readers to better assess whether the hardness scoring reflects genuine difficulty or judge-specific behaviors. revision: yes
-
Referee: no statistical significance, standard deviations across runs, or exact training hyperparameters (learning rate, epochs, batch size) are reported for any of the fine-tuning experiments. Without these, it is impossible to determine whether the 1-3% ASR figures or the 35-50% relative improvement from the hardest-half selection are reliable or could be explained by run-to-run variance.
Authors: We agree that the absence of statistical significance testing, standard deviations, and specific hyperparameters limits the interpretability of the results. In the revised version, we will report results with standard deviations across multiple independent runs, include p-values for key comparisons, and provide the complete set of training hyperparameters including learning rate, number of epochs, and batch size. These revisions will strengthen the reliability claims. revision: yes
-
Referee: the construction of the 'adversarially-framed benign prompts' used for interleaving is not described. Because these prompts are central to the over-refusal mitigation result (74-94% → 30-51%/52-72%), the lack of detail on how they are generated or filtered makes it difficult to assess whether the mitigation generalizes or merely trades one form of bias for another.
Authors: We acknowledge that the generation process for the adversarially-framed benign prompts requires more elaboration. We will expand the methods section to describe how these prompts were constructed—by reformulating benign queries into jailbreak-style formats while preserving benign intent—and the filtering steps applied to ensure they do not trigger refusals. Examples will also be provided to facilitate assessment of generalizability. revision: yes
Circularity Check
No significant circularity; purely empirical selection and fine-tuning
full rationale
The paper describes an empirical pipeline: score candidate prompts by the fraction of the target model's own rollouts labeled harmful by an external judge, then fine-tune on the highest-scoring prompts paired with safe responses. No equations, derivations, or parameter-fitting steps are presented that could reduce any claimed result to its own inputs by construction. The central claims rest on reported attack-success-rate reductions and over-refusal measurements from concrete experiments on Llama-3 models, not on any self-definitional loop or self-citation chain. The reader's assessment of zero circularity is therefore confirmed.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and others , title =. arXiv preprint arXiv:2212.08073 , year =
work page internal anchor Pith review arXiv
-
[3]
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Yang, Amy and Fan, Angela and others , title =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review arXiv
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[5]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, Andy and Wang, Zifan and Kolter, J. Zico and Fredrikson, Matt , title =. arXiv preprint arXiv:2307.15043 , year =
-
[6]
doi:10.48550/arXiv.2406.18510 , abstract =
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , title =. arXiv preprint arXiv:2406.18510 , year =
-
[7]
Han, Seungju and Rao, Kavel and Ettinger, Allyson and Jiang, Liwei and Lin, Bill Yuchen and Dziri, Nouha and Choi, Yejin and Sap, Maarten , title =. arXiv preprint arXiv:2406.18495 , year =
-
[8]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan, Hakan and Upasani, Kartikeya and Chi, Jianfeng and Rungta, Rashi and Iyer, Krithika and Mao, Yuning and Tontchev, Michael and Hu, Qing and Fuller, Brian and Testuggine, Davide and Khabsa, Madian , title =. arXiv preprint arXiv:2312.06674 , year =
work page internal anchor Pith review arXiv
-
[9]
arXiv:2402.05044 (2024), https://arxiv.org/abs/2402.05044
Li, Lijun and Dong, Bowen and Wang, Ruohui and Hu, Xuhao and Zuo, Wangmeng and Lin, Dahua and Qiao, Yu and Shao, Jing , title =. arXiv preprint arXiv:2402.05044 , year =
-
[10]
and Michael, Julian and Perez, Ethan and Treutlein, Johannes , title =
Chua, James and Rees, Edward and Batra, Hunar and Bowman, Samuel R. and Michael, Julian and Perez, Ethan and Treutlein, Johannes , title =. arXiv preprint arXiv:2403.05518 , year =
-
[11]
Irpan, Alex and Turner, Alexander Matt and Kurzeja, Mark and Elson, David K. and Shah, Rohin , title =. arXiv preprint arXiv:2510.27062 , year =
-
[12]
Curriculum Learning , booktitle =
Bengio, Yoshua and Louradour, J. Curriculum Learning , booktitle =. 2009 , pages =
2009
-
[13]
Proceedings of the
Shrivastava, Abhinav and Gupta, Abhinav and Girshick, Ross , title =. Proceedings of the. 2016 , pages =
2016
-
[14]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =. International Conference on Learning Representations (
-
[15]
Proceedings of the 29th Symposium on Operating Systems Principles (
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles (
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.