Recognition: no theorem link
Understanding Asynchronous Inference Methods for Vision-Language-Action Models
Pith reviewed 2026-05-12 01:40 UTC · model grok-4.3
The pith
Per-step residual correction outperforms other methods for handling delays in vision-language-action robot models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
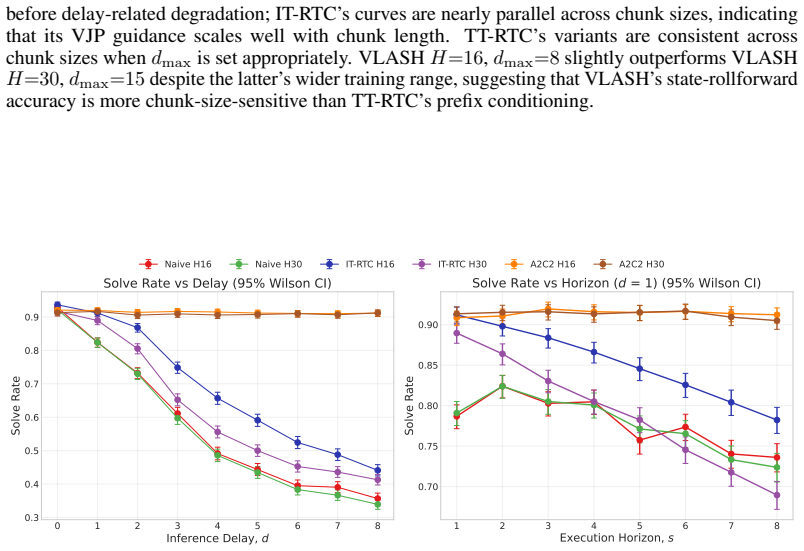
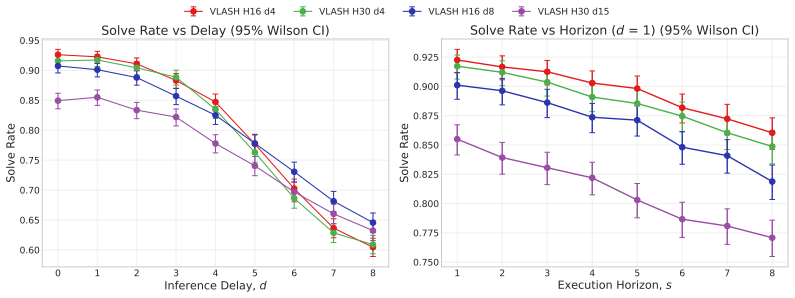
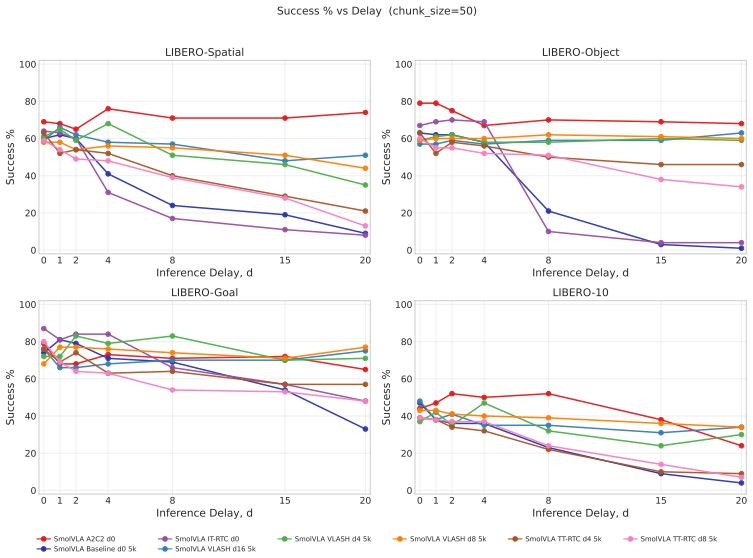
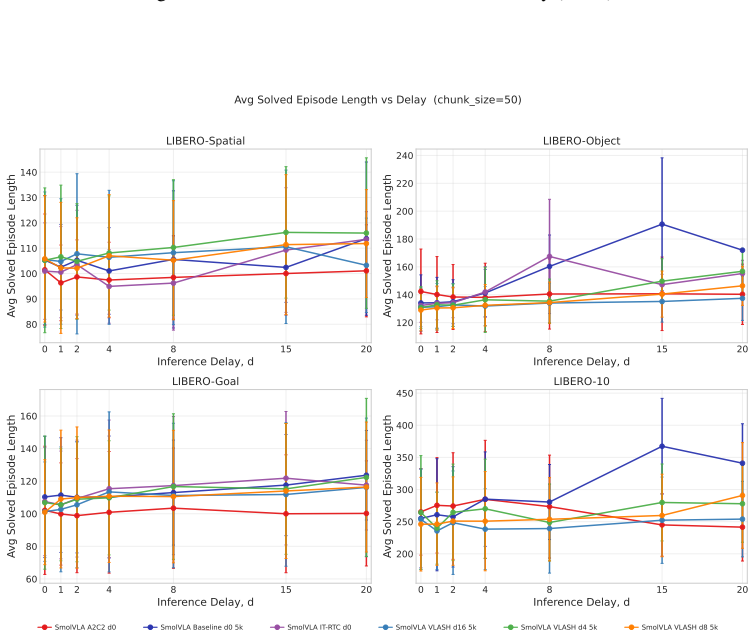
Under harmonized evaluation conditions, A2C2's per-step residual correction is the most effective method on Kinetix, holding above 90% solve rate up to d=8, and also leads on LIBERO from d=4 onwards. TT-RTC is the most robust training-based method: stable across d_max choices, generalizes beyond its training delay distribution, and adds zero inference overhead. IT-RTC is competitive at low delays but degrades sharply under long chunks and high delays, while VLASH shows a clear low-delay versus high-delay trade-off governed by the fine-tuning delay range.
What carries the argument
Unified codebases that integrate all four methods (IT-RTC, TT-RTC, VLASH, A2C2) with harmonized library and dataset versions, then benchmark them on Kinetix with MLPMixer policies and LIBERO with SmolVLA across controlled inference delays.
Load-bearing premise
Harmonized library versions, dataset versions, and unified codebases produce a fair comparison without hidden implementation differences biasing the performance rankings.
What would settle it
Re-running the Kinetix and LIBERO benchmarks after re-implementing the four methods from scratch in fully independent codebases and checking whether A2C2 still leads at higher delays and TT-RTC remains the most stable training method.
Figures











read the original abstract
Vision-Language-Action (VLA) models offer a promising path to generalist robot control, but their inference latency causes observation staleness when generated actions are executed asynchronously. Several methods have been proposed concurrently to mitigate this problem: inference-time inpainting (IT-RTC), training-time delay simulation (TT-RTC), future-state-aware conditioning (VLASH), and lightweight residual correction (A2C2). Each takes a fundamentally different approach, but they have so far been evaluated independently with different codebases, base policies, and protocols. We present a systematic comparison of these four methods under controlled conditions. We develop two unified codebases that integrate all methods with harmonized library and dataset versions, and we benchmark them on the Kinetix suite with MLPMixer policies and on the LIBERO manipulation benchmark with SmolVLA, sweeping inference delays up to $d=20$ control steps. A2C2's per-step residual correction is the most effective method on Kinetix, holding above 90% solve rate up to $d=8$, and also leads on LIBERO from $d=4$ onwards. IT-RTC is competitive at low delays but degrades sharply under long chunks ($H=30$) and high delays. TT-RTC is the most robust training-based method: stable across $d_\max$ choices, generalizes beyond its training delay distribution, and adds zero inference overhead. VLASH exhibits a clear low-delay vs. high-delay trade-off governed by the fine-tuning delay range $[0,d_\max]$. Code is available at https://github.com/TheAyos/async-vla-inference
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver the first controlled, apples-to-apples comparison of four concurrent approaches to asynchronous inference in Vision-Language-Action models (IT-RTC, TT-RTC, VLASH, and A2C2). By integrating all methods into two unified codebases with harmonized library and dataset versions, the authors benchmark them on the Kinetix suite (MLPMixer policies) and LIBERO (SmolVLA), sweeping inference delays up to d=20. They report that A2C2’s per-step residual correction is the strongest performer on Kinetix (above 90 % solve rate through d=8) and leads on LIBERO from d=4 onward, while TT-RTC is the most robust training-based method—stable across d_max choices, generalizes beyond its training delay distribution, and incurs zero inference overhead. VLASH shows a clear low-delay versus high-delay trade-off governed by its fine-tuning range, and IT-RTC degrades under long action chunks and high delays.
Significance. If the reported rankings are reproducible under the claimed controlled conditions, the work supplies a much-needed reference point for practitioners choosing among asynchronous VLA inference strategies. The explicit trade-off characterizations (performance vs. robustness vs. overhead) and the public release of the unified codebases are concrete strengths that could accelerate follow-on research and reduce the fragmentation that has characterized this sub-area.
major comments (2)
- The central empirical claims (A2C2 leading on Kinetix up to d=8 and on LIBERO from d=4; TT-RTC most robust) rest on the premise that the two unified codebases eliminate hidden implementation differences. The manuscript states that all four methods were integrated with harmonized library/dataset versions, yet provides no audit or verification of porting fidelity—e.g., whether A2C2’s per-step residual correction uses identical update logic to the original formulation or whether TT-RTC’s delay sampling exactly reproduces the training distribution. Any mismatch could shift solve rates by the margins that separate the reported rankings.
- Abstract and experimental results: the paper reports precise solve-rate thresholds and method orderings from sweeps up to d=20 without error bars, standard deviations, number of seeds, or raw data. This absence prevents readers from assessing whether the claimed superiority of A2C2 (above 90 % up to d=8) or the stability of TT-RTC is statistically distinguishable from noise or implementation variance.
minor comments (1)
- The abstract and results sections would benefit from a concise table summarizing the four methods’ core mechanisms, inference overhead, and training requirements for quick reference.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments highlight important aspects of reproducibility and statistical rigor that we have addressed in the revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: The central empirical claims (A2C2 leading on Kinetix up to d=8 and on LIBERO from d=4; TT-RTC most robust) rest on the premise that the two unified codebases eliminate hidden implementation differences. The manuscript states that all four methods were integrated with harmonized library/dataset versions, yet provides no audit or verification of porting fidelity—e.g., whether A2C2’s per-step residual correction uses identical update logic to the original formulation or whether TT-RTC’s delay sampling exactly reproduces the training distribution. Any mismatch could shift solve rates by the margins that separate the reported rankings.
Authors: We agree that an explicit audit of porting fidelity strengthens the central claims. In the revised manuscript we have added a new subsection titled 'Implementation Details and Fidelity Verification' that documents the porting process for each method. For A2C2 we include the exact per-step residual correction formula used and confirm it matches the original formulation described in the source paper. For TT-RTC we describe the delay sampling procedure and verify that it reproduces the training distribution (including the same d_max range and sampling strategy). The public code repository now contains inline comments and test scripts that reproduce the key integration steps. While we cannot perform a bit-for-bit comparison without the original authors' private codebases, the added documentation and code make any remaining discrepancies transparent and auditable. revision: yes
-
Referee: Abstract and experimental results: the paper reports precise solve-rate thresholds and method orderings from sweeps up to d=20 without error bars, standard deviations, number of seeds, or raw data. This absence prevents readers from assessing whether the claimed superiority of A2C2 (above 90 % up to d=8) or the stability of TT-RTC is statistically distinguishable from noise or implementation variance.
Authors: We accept that the original submission lacked sufficient statistical reporting. The revised manuscript now states that all Kinetix results are averaged over 5 independent random seeds and all LIBERO results over 3 seeds (the lower number on LIBERO reflects computational cost). Standard-deviation error bars have been added to every figure and table that reports solve rates. We also include a brief discussion of variance and note that the raw per-seed data are released alongside the code. These changes allow readers to evaluate whether the reported thresholds and orderings are statistically distinguishable. revision: yes
Circularity Check
No circularity: purely empirical benchmark comparison
full rationale
The paper conducts a controlled empirical evaluation of four existing asynchronous inference methods (IT-RTC, TT-RTC, VLASH, A2C2) on external benchmarks (Kinetix with MLPMixer, LIBERO with SmolVLA). It reports measured solve rates under swept delays, using two unified codebases with harmonized libraries and datasets. No equations, derivations, fitted parameters, or mathematical claims appear that could reduce to inputs by construction. Central results (A2C2 leading on Kinetix up to d=8, TT-RTC most robust) are direct performance measurements on held-out suites, not predictions or self-referential fits. No load-bearing self-citations or uniqueness theorems are invoked. The work is self-contained against external benchmarks and contains no derivation chain to inspect for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv. org/abs/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Cadene. Smolvla: A vision-language-action model for affordable and efficient robotics, 2025. URLhttps://arxiv.org/abs/2506.01844. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware, 2023. URLhttps://arxiv.org/abs/2304.13705
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
arXiv preprint arXiv:2510.26742 (2025)
Yunchao Ma, Yizhuang Zhou, Yunhuan Yang, Tiancai Wang, and Haoqiang Fan. Running vlas at real-time speed, 2025. URLhttps://arxiv.org/abs/2510.26742
-
[8]
Wenqi Jiang, Jason Clemons, Karu Sankaralingam, and Christos Kozyrakis. How fast can i run my vla? demystifying vla inference performance with vla-perf, 2026. URL https: //arxiv.org/abs/2602.18397
-
[9]
Real-Time Execution of Action Chunking Flow Policies
Kevin Black, Manuel Y . Galliker, and Sergey Levine. Real-time execution of action chunking flow policies, 2025. URLhttps://arxiv.org/abs/2506.07339
work page internal anchor Pith review arXiv 2025
-
[10]
arXiv preprint arXiv:2512.05964 (2025)
Kevin Black, Allen Z. Ren, Michael Equi, and Sergey Levine. Training-time action conditioning for efficient real-time chunking, 2025. URLhttps://arxiv.org/abs/2512.05964
-
[11]
arXiv preprint arXiv:2512.01031 (2025)
Jiaming Tang, Yufei Sun, Yilong Zhao, Shang Yang, Yujun Lin, Zhuoyang Zhang, James Hou, Yao Lu, Zhijian Liu, and Song Han. Vlash: Real-time vlas via future-state-aware asynchronous inference, 2025. URLhttps://arxiv.org/abs/2512.01031
-
[12]
Leave no observation behind: Real-time correction for vla action chunks.ArXiv, abs/2509.23224, 2025
Kohei Sendai, Maxime Alvarez, Tatsuya Matsushima, Yutaka Matsuo, and Yusuke Iwasawa. Leave no observation behind: Real-time correction for vla action chunks, 2025. URL https: //arxiv.org/abs/2509.23224
-
[13]
Michael Matthews, Michael Beukman, Chris Lu, and Jakob Foerster. Kinetix: Investigating the training of general agents through open-ended physics-based control tasks, 2025. URL https://arxiv.org/abs/2410.23208
-
[14]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URL https: //arxiv.org/abs/2306.03310
work page internal anchor Pith review arXiv 2023
-
[15]
Training-free linear image inverses via flows.arXiv preprint arXiv:2310.04432, 2023
Ashwini Pokle, Matthew J. Muckley, Ricky T. Q. Chen, and Brian Karrer. Training-free linear image inverses via flows, 2024. URLhttps://arxiv.org/abs/2310.04432
-
[16]
Pseudoinverse-guided diffusion models for inverse problems
Jiaming Song, Arash Vahdat, Morteza Mardani, and Jan Kautz. Pseudoinverse-guided diffusion models for inverse problems. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=9_gsMA8MRKQ
work page 2023
-
[17]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. URL https://arxiv.org/abs/2212.09748
work page internal anchor Pith review arXiv 2023
-
[18]
Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, and Alexey Dosovitskiy. Mlp-mixer: An all-mlp architecture for vision, 2021. URL https: //arxiv.org/abs/2105.01601
-
[19]
Society for Industrial and Applied Mathematics, 2 edition, 2008
Andreas Griewank and Andrea Walther.Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation. Society for Industrial and Applied Mathematics, 2 edition, 2008. doi: 10.1137/1.9780898717761. A Detailed Method Descriptions A.1 IT-RTC: Pseudoinverse Guidance Details The soft mask used to blend frozen and free actions is Wi =c i · eci −...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.