Recognition: 2 theorem links
· Lean TheoremEnabling Performant and Flexible Model-Internal Observability for LLM Inference
Pith reviewed 2026-05-13 07:12 UTC · model grok-4.3
The pith
DMI-Lib decouples internal LLM state access from the inference hot path to keep overhead under 7 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DMI-Lib treats internal observability as a first-class systems primitive, decoupling it from the inference hot path via an asynchronous observability substrate built from Ring^2, a GPU-CPU memory abstraction for capturing and staging tensors, and a policy-controlled host backend that exports them. This enables the placement of observation points across a rich space of internal signals and diverse inference backends while preserving serving optimizations and adhering to tight GPU memory budgets.
What carries the argument
Ring^2, the GPU-CPU memory abstraction for asynchronous tensor capture and staging, together with the policy-controlled host backend for export.
If this is right
- Observation points can be placed flexibly across many internal signals without disrupting the main inference computation.
- GPU memory budgets and existing serving optimizations remain intact during observability operations.
- Offline batch inference runs with 0.4 to 6.8 percent added overhead.
- Moderate online serving runs with roughly 6 percent average overhead.
- Latency overhead drops by a factor of 2 to 15 compared with prior systems that provide similar observability.
Where Pith is reading between the lines
- The same decoupling pattern could support continuous internal-state streaming for production safety checks or model calibration without pausing inference.
- Ring^2-style abstractions may transfer to other latency-sensitive systems that need auxiliary data movement without contention on the critical path.
- Implementation on newer accelerator types would test whether the GPU-CPU staging logic generalizes beyond current hardware.
- Connection to distributed tracing tools could turn per-request internal signals into cluster-wide diagnostics.
Load-bearing premise
The design assumes that asynchronous tensor staging via Ring^2 and the policy-controlled backend can be fully decoupled from the inference hot path without introducing data races, correctness errors, or hidden synchronization costs under all realistic serving loads and backends.
What would settle it
A high-load online serving test on a new backend that shows either overhead above 7 percent or any data races, tensor corruption, or extra synchronization delays would disprove the low-overhead and correctness claims.
Figures









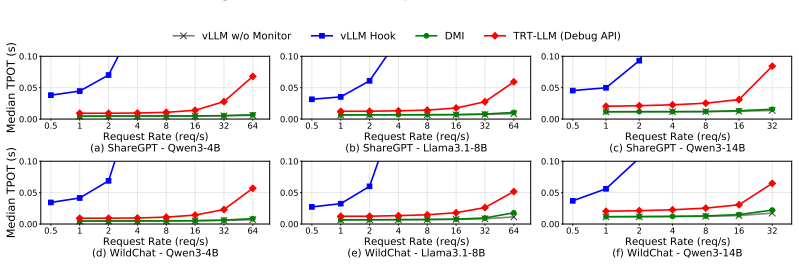




read the original abstract
Today's inference-time workloads increasingly depend on timely access to a model's internal states. We present DMI-Lib, a high-speed deep model inspector that treats internal observability as a first-class systems primitive, decoupling it from the inference hot path via an asynchronous observability substrate built from Ring^2, a GPU-CPU memory abstraction for capturing and staging tensors, and a policy-controlled host backend that exports them. DMI-Lib enables the placement of observation points across a rich space of internal signals and diverse inference backends while preserving serving optimizations and adhering to tight GPU memory budgets. Our experiments demonstrate that DMI-Lib incurs only 0.4%--6.8% overhead in offline batch inference and an average of 6% in moderate online serving, reducing latency overhead by 2x-15x compared to existing baselines with similar observability features. DMI-Lib is open-sourced at https://github.com/ProjectDMX/DMI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DMI-Lib, a library for model-internal observability during LLM inference. It decouples observation from the hot path via an asynchronous substrate built on Ring^2 (a GPU-CPU tensor staging abstraction) and a policy-controlled host backend, enabling flexible placement of observation points across signals and backends while respecting GPU memory budgets. Experiments report 0.4%--6.8% overhead for offline batch inference, ~6% average overhead for moderate online serving, and 2x--15x latency reduction relative to baselines with comparable observability features.
Significance. If the performance numbers hold under realistic loads and backends, the work would be significant for production LLM serving by making internal-state access a low-cost primitive, directly supporting debugging, interpretability, and safety monitoring without forcing trade-offs against serving optimizations. The open-source release aids reproducibility.
major comments (2)
- [§3.1] §3.1 (Ring^2 design): the claim of full decoupling from the inference hot path lacks any latency bounds on GPU-CPU transfers, analysis of ring-buffer contention, or proof of absence of data races under high-frequency observation or diverse tensor sizes; this assumption is load-bearing for all reported overhead figures.
- [§4] §4 (experimental evaluation): the headline numbers (0.4%--6.8% offline, 6% online, 2x--15x latency reduction) are presented without error bars, explicit request-rate or tensor-size ranges for the 'moderate' online case, or stress-test results across backends, so the central performance claim cannot be verified from the given data.
minor comments (2)
- [Abstract] Abstract: 'moderate online serving' is undefined; add concrete QPS or batch-size ranges.
- [§3] Notation: Ring^2 is introduced without a formal definition or pseudocode in the main text; move or expand the description from any appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the analysis and experimental presentation.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Ring^2 design): the claim of full decoupling from the inference hot path lacks any latency bounds on GPU-CPU transfers, analysis of ring-buffer contention, or proof of absence of data races under high-frequency observation or diverse tensor sizes; this assumption is load-bearing for all reported overhead figures.
Authors: We agree that §3.1 would benefit from additional quantitative support. The Ring^2 abstraction relies on asynchronous CUDA streams and a lock-free ring buffer with atomic flags for synchronization. In the revision we will add (i) measured PCIe transfer latency bounds across representative tensor sizes, (ii) microbenchmark results quantifying ring-buffer contention at varying observation frequencies, and (iii) an explicit description of the synchronization primitives together with empirical checks for data races. These additions will be supported by new figures and will directly address the load-bearing nature of the decoupling claim. revision: yes
-
Referee: [§4] §4 (experimental evaluation): the headline numbers (0.4%--6.8% offline, 6% online, 2x--15x latency reduction) are presented without error bars, explicit request-rate or tensor-size ranges for the 'moderate' online case, or stress-test results across backends, so the central performance claim cannot be verified from the given data.
Authors: We accept that the current experimental section lacks sufficient detail for independent verification. We will revise §4 to report standard error bars from repeated runs, explicitly document the request-rate range (e.g., 10–100 QPS) and tensor-size distributions used for the moderate online case, and include stress-test results on at least two additional backends. These changes will make the reported overhead and latency-reduction figures reproducible and will strengthen the central performance claims. revision: yes
Circularity Check
No circularity: performance claims are direct empirical measurements
full rationale
The paper presents a systems design (Ring^2 GPU-CPU abstraction plus policy-controlled backend) and reports overhead numbers (0.4%–6.8% offline, ~6% online, 2×–15× latency reduction) from benchmark experiments. No derivation chain, fitted parameters, or equations exist that reduce to self-inputs. No self-citations are load-bearing for the central claims. The design assumptions about decoupling are stated but not proven mathematically; the reported numbers stand or fall on the measurements themselves, which are external to any internal definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Asynchronous staging of internal tensors via Ring^2 does not introduce data races or correctness violations under typical inference workloads
invented entities (1)
-
Ring^2
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearDMI-Lib routes captured tensors through Ring2, a GPU–CPU co-designed staging abstraction that keeps data movement inside CUDA graphs and a dedicated GPU-side ring buffer, then drains it asynchronously on the host via a data exporter
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDMI-Lib incurs only 0.4%–6.8% overhead in offline batch inference and an average of 6% in moderate online serving
Reference graph
Works this paper leans on
-
[1]
Taming{Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gula- vani, Alexey Tumanov, and Ramachandran Ramjee. Taming{Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In18th USENIX symposium on operating systems design and implementation (OSDI 24), pages 117–134, 2024
work page 2024
-
[2]
Yuetao Chen, Xuliang Wang, Xinzhou Zheng, Ming Li, Peng Wang, and Hong Xu. Make every draft count: Hidden state based speculative decoding.arXiv preprint arXiv:2602.21224, 2026. 18
-
[3]
Matthew Choi, Muhammad Adil Asif, John Willes, and David Emerson. Flexmodel: A frame- work for interpretability of distributed large language models.arXiv preprint arXiv:2312.03140, 2023
-
[4]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. What does BERT look at? an analysis of BERT’s attention. InProceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 276–286, 2019
work page 2019
-
[5]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[6]
Minder: Faulty machine detection for large-scale distributed model training
Yangtao Deng, Xiang Shi, Zhuo Jiang, Xingjian Zhang, Lei Zhang, Zhang Zhang, Bo Li, Zuquan Song, Hang Zhu, Gaohong Liu, et al. Minder: Faulty machine detection for large-scale distributed model training. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25), pages 505–521, 2025
work page 2025
-
[7]
Mycroft: Tracing dependencies in collective com- munication towards reliable llm training
Yangtao Deng, Lei Zhang, Qinlong Wang, Xiaoyun Zhi, Xinlei Zhang, Zhuo Jiang, Haohan Xu, Lei Wang, Zuquan Song, Gaohong Liu, et al. Mycroft: Tracing dependencies in collective com- munication towards reliable llm training. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, pages 254–269, 2025
work page 2025
-
[8]
Tianqi Du, Zeming Wei, Quan Chen, Chenheng Zhang, and Yisen Wang. Advancing llm safe alignment with safety representation ranking.arXiv preprint arXiv:2505.15710, 2025
-
[9]
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, and Marta R Costa-Jussà. A primer on the inner workings of transformer-based language models.arXiv preprint arXiv:2405.00208, 2024
-
[10]
Nnsight and ndif: Democratizing access to foundation model internals
Jaden Fiotto-Kaufman, Alexander R Loftus, Eric Todd, Jannik Brinkmann, Caden Juang, Koyena Pal, Can Rager, Aaron Mueller, Samuel Marks, Arnab Sen Sharma, Francesca Lucchetti, Michael Ripa, Adam Belfki, Nikhil Prakash, Sumeet Multani, Carla Brodley, Arjun Guha, Jonathan Bell, Byron Wallace, and David Bau. Nnsight and ndif: Democratizing access to foundatio...
-
[11]
llama.cpp: Llm inference in c/c++.https://github.com/ggml-org/ llama.cpp, 2023
Georgi Gerganov et al. llama.cpp: Llm inference in c/c++.https://github.com/ggml-org/ llama.cpp, 2023
work page 2023
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First conference on language modeling, 2024
work page 2024
-
[14]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, Hy- oukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
work page 2019
-
[15]
Hugging Face. Text generation inference: A toolkit for routing and serving large language models.https://github.com/huggingface/text-generation-inference, 2023
work page 2023
-
[16]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Ching-Yun Ko and Pin-Yu Chen. vllm hook v0: A plug-in for programming model internals on vllm.arXiv preprint arXiv:2603.06588, 2026
-
[18]
arXiv , author =:2009.07896 , primaryclass =
Narine Kokhlikyan, Vivek Miglani, Miguel Martin, Edward Wang, Bilal Alsallakh, Jonathan Reynolds, Alexander Melnikov, Natalia Kliushkina, Carlos Araya, Siqi Yan, et al. Captum: A unified and generic model interpretability library for pytorch.arXiv preprint arXiv:2009.07896, 2020. 19
-
[19]
Building production-ready probes for Gemini
János Kramár, Joshua Engels, Zheng Wang, Bilal Chughtai, Rohin Shah, Neel Nanda, and Arthur Conmy. Building production-ready probes for gemini.arXiv preprint arXiv:2601.11516, 2026
-
[20]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[21]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with condi- tional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[22]
arXiv preprint arXiv:2503.01840 (2025) 5 16 Z
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test.arXiv preprint arXiv:2503.01840, 2025
-
[23]
Fuliang Liu, Xue Li, Ketai Zhao, Yinxi Gao, Ziyan Zhou, Zhonghui Zhang, Zhibin Wang, Wanchun Dou, Sheng Zhong, and Chen Tian. Dart: Diffusion-inspired speculative decoding for fast llm inference.arXiv preprint arXiv:2601.19278, 2026
-
[24]
Detecting high-stakes interactions with activation probes
Alex McKenzie, Urja Pawar, Phil Blandfort, William Bankes, David Krueger, Ekdeep Singh Lubana, and Dmitrii Krasheninnikov. Detecting high-stakes interactions with activation probes. arXiv preprint arXiv:2506.10805, 2025
-
[25]
Neel Nanda and Joseph Bloom. Transformerlens. https://github.com/ TransformerLensOrg/TransformerLens, 2022
work page 2022
-
[26]
Pipedream: Generalized pipeline parallelism for dnn training
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. Pipedream: Generalized pipeline parallelism for dnn training. InProceedings of the 27th ACM symposium on operating systems principles, 2019
work page 2019
-
[27]
TensorRT-LLM.https://github.com/NVIDIA/TensorRT-LLM, 2024
NVIDIA. TensorRT-LLM.https://github.com/NVIDIA/TensorRT-LLM, 2024
work page 2024
-
[28]
Nvidia collective communications library (nccl)
NVIDIA. Nvidia collective communications library (nccl). https://github.com/NVIDIA/ nccl, 2026
work page 2026
-
[29]
NVIDIA Corporation. NVIDIA Nsight Systems. https://developer.nvidia.com/ nsight-systems. Accessed: 2026-04-01
work page 2026
-
[30]
NVIDIA Corporation. Triton inference server: An optimized cloud and edge inferencing solution.https://github.com/triton-inference-server/server, 2023
work page 2023
-
[31]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[32]
Prometheus Authors. Prometheus, 2026. URL https://prometheus.io/. Open-source monitoring system and time series database. Accessed 2026-04-01
work page 2026
-
[33]
Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao. A practical review of mech- anistic interpretability for transformer-based language models.arXiv preprint arXiv:2407.02646, 2024
-
[34]
Robert Schulze, Tom Schreiber, Ilya Yatsishin, Ryadh Dahimene, and Alexey Milovidov. Clickhouse-lightning fast analytics for everyone.Proceedings of the VLDB Endowment, 17(12): 3731–3744, 2024
work page 2024
-
[35]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017. 20
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[37]
Alessandro Stolfo, Vidhisha Balachandran, Safoora Yousefi, Eric Horvitz, and Besmira Nushi. Improving instruction-following in language models through activation steering.arXiv preprint arXiv:2410.12877, 2024
-
[38]
JohnMark Taylor and Nikolaus Kriegeskorte. Extracting and visualizing hidden activations and computational graphs of pytorch models with torchlens.Scientific Reports, 13(1):14375, 2023
work page 2023
-
[39]
Sharegpt.https://sharegpt.com/, 2023
ShareGPT Team. Sharegpt.https://sharegpt.com/, 2023
work page 2023
-
[40]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering, 2024.URL https://arxiv. org/abs/2308.10248, 2308, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[42]
Interpretability in the wild: a circuit for indirect object identification in GPT-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[43]
Wei Wang, Nengneng Yu, Sixian Xiong, and Zaoxing Liu. Reliable and resilient collective communication library for llm training and serving.arXiv preprint arXiv:2512.25059, 2025
-
[44]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the- ar...
work page 2020
-
[45]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[46]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Orca: A distributed serving system for {Transformer-Based} generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX symposium on operating systems design and implementation (OSDI 22), pages 521–538, 2022
work page 2022
-
[48]
Rongzhi Zhang, Liqin Ye, Yuzhao Heng, Xiang Chen, Tong Yu, Lingkai Kong, Sudheer Chava, and Chao Zhang. Precise attribute intensity control in large language models via targeted representation editing.arXiv preprint arXiv:2510.12121, 2025
-
[49]
Icr probe: Tracking hidden state dynamics for reliable hallucination detection in llms
Zhenliang Zhang, Xinyu Hu, Huixuan Zhang, Junzhe Zhang, and Xiaojun Wan. Icr probe: Tracking hidden state dynamics for reliable hallucination detection in llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 17986–18002, 2025
work page 2025
-
[50]
Wild- Chat: 1M ChatGPT interaction logs in the wild.arXiv preprint arXiv:2405.01470,
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatgpt interaction logs in the wild.arXiv preprint arXiv:2405.01470, 2024
-
[51]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37: 62557–62583, 2024. 21
work page 2024
-
[52]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, 2024
work page 2024
-
[53]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 22
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.