Recognition: 2 theorem links
· Lean TheoremTMRL: Diffusion Timestep-Modulated Pretraining Enables Exploration for Efficient Policy Finetuning
Pith reviewed 2026-05-13 04:14 UTC · model grok-4.3
The pith
Pretraining robot policies with injected diffusion noise and then modulating the timestep during RL fine-tuning creates controllable exploration that improves sample efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
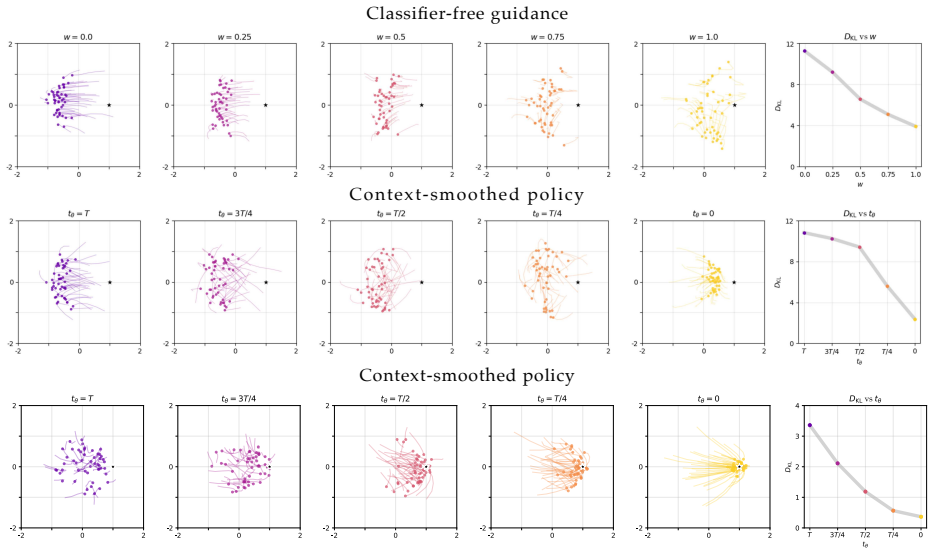
The central claim is that Context-Smoothed Pre-training injects forward-diffusion noise into policy inputs to create a tunable continuum between precise imitation and broad coverage, and that Timestep-Modulated Reinforcement Learning then lets the policy choose the conditioning timestep at each step so that exploration can be adjusted on the fly, yielding higher sample efficiency in downstream RL fine-tuning.
What carries the argument
Timestep-Modulated Reinforcement Learning (TMRL) that conditions the policy on a selected diffusion timestep during fine-tuning, built on top of Context-Smoothed Pre-training (CSP) that adds controlled forward-diffusion noise to the inputs.
If this is right
- The method integrates directly with policies that take states, 3D point clouds, or image inputs without requiring architectural changes.
- RL fine-tuning reaches successful policies with substantially fewer environment interactions than standard approaches.
- Complex real-world manipulation tasks become solvable within one hour of robot fine-tuning time.
Where Pith is reading between the lines
- The same noise-injection-plus-timestep-control pattern could be tested in non-robot RL domains where pretraining is used to initialize policies.
- If the timestep selection proves stable, it might reduce the amount of real-world data collection needed for new robot skills.
- Future work could examine whether the same mechanism helps when the pretraining data itself comes from noisy or incomplete demonstrations.
Load-bearing premise
That the noise levels introduced in pretraining actually produce a useful, continuous range of behaviors that can be selected via timestep without harming the policy's ability to imitate or to learn.
What would settle it
A controlled comparison on the same pre-trained policy showing that standard RL fine-tuning without timestep modulation reaches the same success rate with equal or fewer samples, or that real-world manipulation tasks still require more than one hour of fine-tuning, would falsify the central claim.
Figures



















read the original abstract
Fine-tuning pre-trained robot policies with reinforcement learning (RL) often inherits the bottlenecks introduced by pre-training with behavioral cloning (BC), which produces narrow action distributions that lack the coverage necessary for downstream exploration. We present a unified framework that enables the exploration necessary to enable efficient robot policy finetuning by bridging BC pre-training and RL fine-tuning. Our pre-training method, Context-Smoothed Pre-training (CSP), injects forward-diffusion noise into policy inputs, creating a continuum between precise imitation and broad action coverage. We then fine-tune pre-trained policies via Timestep-Modulated Reinforcement Learning (TMRL), which trains the agent to dynamically adjust this conditioning during fine-tuning by modulating the diffusion timestep, granting explicit control over exploration. Integrating seamlessly with arbitrary policy inputs, e.g., states, 3D point clouds, or image-based VLA policies, we show that TMRL improves RL fine-tuning sample efficiency. Notably, TMRL enables successful real-world fine-tuning on complex manipulation tasks in under one hour. Videos and code available at https://weirdlabuw.github.io/tmrl/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Context-Smoothed Pre-training (CSP), which injects forward-diffusion noise into policy inputs during behavioral cloning to create a continuum between precise imitation and broad action coverage, and Timestep-Modulated Reinforcement Learning (TMRL), which conditions the policy on the diffusion timestep during RL fine-tuning to explicitly modulate exploration. It claims seamless integration with arbitrary inputs (states, 3D point clouds, image-based VLA policies), improved RL fine-tuning sample efficiency, and successful real-world fine-tuning on complex manipulation tasks in under one hour, with code and videos released.
Significance. If the empirical claims hold, this could be a significant contribution to robot learning by offering a unified, conditioning-based bridge between BC pre-training and RL fine-tuning that directly addresses the exploration bottleneck through diffusion timestep modulation. The approach's compatibility with modern multimodal policies and the real-world demonstration would be impactful; the release of code and videos is a clear strength for reproducibility.
major comments (1)
- Abstract: The abstract states performance improvements and real-world success but provides no quantitative results, baselines, experimental details, or error analysis, making it impossible to assess whether the data supports the claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the potential significance of our approach for bridging BC pre-training and RL fine-tuning in robot learning. We address the major comment point by point below.
read point-by-point responses
-
Referee: Abstract: The abstract states performance improvements and real-world success but provides no quantitative results, baselines, experimental details, or error analysis, making it impossible to assess whether the data supports the claims.
Authors: We agree that the abstract would be strengthened by including specific quantitative results to better substantiate the claims. In the revised version, we will update the abstract to incorporate key metrics such as sample efficiency improvements (e.g., achieving target performance with X% fewer environment interactions than standard BC+RL baselines), details on the baselines compared (including vanilla diffusion policies and other exploration methods), and reference to error analysis from multiple random seeds. These additions will be kept concise to maintain abstract length while providing sufficient evidence for the reported gains in simulation and the real-world one-hour fine-tuning results. We believe this directly addresses the concern without altering the core narrative. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a high-level methodological framework (CSP for pretraining via forward-diffusion noise injection on inputs, followed by TMRL conditioning on diffusion timestep during RL finetuning) without presenting any equations, derivations, or parameter-fitting procedures in the abstract or summary. No load-bearing steps reduce to self-definitions, fitted inputs renamed as predictions, or self-citation chains. Claims of improved sample efficiency and real-world applicability are positioned as empirical outcomes rather than tautological constructions, rendering the argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Forward diffusion noise can be injected into policy inputs to create a controllable continuum between imitation and exploration.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Smoothing increases overlap... TV(p_σ(·|c),p_σ(·|c')) ≤ (E∥w∥/σ)∥c-c'∥
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Posterior behavioral cloning: Pretraining bc policies for efficient rl finetuning,
A. Wagenmaker, P. Dong, R. Tsao, C. Finn, and S. Levine, “Posterior behavioral cloning: Pretraining bc policies for efficient rl finetuning,”arXiv preprint arXiv:2512.16911, 2025
-
[2]
Steering your diffusion policy with latent space rein- forcement learning,
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine, “Steering your diffusion policy with latent space rein- forcement learning,” inConference on Robot Learning, 2025
work page 2025
-
[3]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dha- balia, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glossop, T. Godden, I. Gory- achev, L. Groom, H. Hancock, K. Hausman, G. Hussein, B. Ichter, S. Jakubczak, R. Jen, T. Jones, B. Katz, L. Ke, C. Kuchi, M. Lamb, D. LeBlanc, S. L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bootstrap your own skills: Learning to solve new tasks with large language model guidance,
J. Zhang, J. Zhang, K. Pertsch, Z. Liu, X. Ren, M. Chang, S.-H. Sun, and J. J. Lim, “Bootstrap your own skills: Learning to solve new tasks with large language model guidance,” inConference on Robot Learning (CoRL), 2023
work page 2023
-
[5]
Sprint: Scalable policy pre-training via language instruction re- labeling,
J. Zhang, K. Pertsch, J. Zhang, and J. J. Lim, “Sprint: Scalable policy pre-training via language instruction re- labeling,” inInternational Conference on Robotics and Automation (ICRA), 2024
work page 2024
-
[6]
Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,
J. Luo, C. Xu, J. Wu, and S. Levine, “Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,”Science Robotics, vol. 10, no. 105, p. eads5033, 2025
work page 2025
-
[7]
EXTRACT: Efficient policy learning by extracting transferrable robot skills from offline data,
J. Zhang, M. Heo, Z. Liu, E. Biyik, J. J. Lim, Y . Liu, and R. Fakoor, “EXTRACT: Efficient policy learning by extracting transferrable robot skills from offline data,” in Conference on Robot Learning, 2024
work page 2024
-
[8]
J. Hu, R. Hendrix, A. Farhadi, A. Kembhavi, R. Mart ´ın- Mart´ın, P. Stone, K.-H. Zeng, and K. Ehsani, “Flare: Achieving masterful and adaptive robot policies with large-scale reinforcement learning fine-tuning,” in2025 IEEE International Conference on Robotics and Automa- tion (ICRA). IEEE, 2025, pp. 3617–3624
work page 2025
-
[9]
Rapidly adapting policies to the real-world via simulation-guided fine- tuning,
P. Yin, T. Westenbroek, S. Bagaria, K. Huang, C.-A. Cheng, A. Kolobov, and A. Gupta, “Rapidly adapting policies to the real-world via simulation-guided fine- tuning,” inInternational Conference on Learning Rep- resentations (ICLR), 2025
work page 2025
-
[10]
J. Yang, M. S. Mark, B. Vu, A. Sharma, J. Bohg, and C. Finn, “Robot fine-tuning made easy: Pre-training re- wards and policies for autonomous real-world reinforce- ment learning,” inInternational Conference on Robotics and Automation (ICRA), 2024
work page 2024
-
[11]
Rl-100: Performant robotic ma- nipulation with real-world reinforcement learning,
K. Lei, H. Li, D. Yu, Z. Wei, L. Guo, Z. Jiang, Z. Wang, S. Liang, and H. Xu, “Rl-100: Performant robotic ma- nipulation with real-world reinforcement learning,”arXiv preprint arXiv: 2510.14830, 2026
-
[12]
Gr-rl: Going dexterous and precise for long-horizon robotic manipulation
Y . Li, X. Ma, J. Xu, Y . Cui, Z. Cui, Z. Han, L. Huang, T. Kong, Y . Liu, H. Niu, W. Peng, J. Qiao, Z. Ren, H. Shi, Z. Su, J. Tian, Y . Xiao, S. Zhang, L. Zheng, H. Li, and Y . Wu, “Gr-rl: Going dexterous and precise for long-horizon robotic manipulation,”arXiv preprint arXiv:2512.01801, 2025
-
[13]
Alvinn: An autonomous land vehicle in a neural network,
D. Pomerleau, “Alvinn: An autonomous land vehicle in a neural network,” inProceedings of (NeurIPS) Neural Information Processing Systems, D. Touretzky, Ed. Mor- gan Kaufmann, December 1989, pp. 305 – 313
work page 1989
-
[14]
A framework for behavioural cloning,
M. Bain and C. Sammut, “A framework for behavioural cloning,” inMachine Intelligence 15, 1995
work page 1995
-
[15]
P. Florence, C. Lynch, A. Zeng, O. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tomp- son, “Implicit behavioral cloning,”Conference on Robot Learning (CoRL), 2021
work page 2021
-
[16]
Diffusion policy: Visuomotor pol- icy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burch- fiel, and S. Song, “Diffusion policy: Visuomotor pol- icy learning via action diffusion,” inProceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[17]
Over- trained language models are harder to fine-tune,
J. M. Springer, S. Goyal, K. Wen, T. Kumar, X. Yue, S. Malladi, G. Neubig, and A. Raghunathan, “Over- trained language models are harder to fine-tune,” inForty-second International Conference on Machine Learning, 2025
work page 2025
-
[18]
F. Chen, A. Raventos, N. Cheng, S. Ganguli, and S. Druckmann, “Rethinking fine-tuning when scaling test-time compute: Limiting confidence improves math- ematical reasoning,” inThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems, 2025
work page 2025
-
[19]
arXiv preprint arXiv:2504.12491 , year=
H. Zeng, K. Hui, H. Zhuang, Z. Qin, Z. Yue, H. Za- mani, and D. Alon, “Can pre-training indicators reliably predict fine-tuning outcomes of llms?”arXiv preprint arXiv:2504.12491, 2025
-
[20]
The cov- erage principle: How pre-training enables post-training,
F. Chen, A. Huang, N. Golowich, S. Malladi, A. Block, J. T. Ash, A. Krishnamurthy, and D. J. Foster, “The cov- erage principle: How pre-training enables post-training,” inThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[21]
K. Hu, Z. Rui, Y . He, Y . Liu, P. Hua, and H. Xu, “Stem- OB: Generalizable visual imitation learning with stem- like convergent observation through diffusion inversion,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[22]
Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets,
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta, “Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets,” inProceedings of Robotics: Science and Systems (RSS), 2025
work page 2025
-
[23]
Behavior Regularized Offline Reinforcement Learning
Y . Wu, G. Tucker, and O. Nachum, “Behavior regu- larized offline reinforcement learning,”arXiv preprint arXiv:1911.11361, 2019
work page internal anchor Pith review arXiv 1911
-
[24]
Con- servative q-learning for offline reinforcement learning,
A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Con- servative q-learning for offline reinforcement learning,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 1179–1191
work page 2020
-
[25]
Ef- ficient online reinforcement learning with offline data,
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine, “Ef- ficient online reinforcement learning with offline data,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 202. PMLR, 23–29 Jul 2023, pp. 1577– 1594
work page 2023
-
[26]
Diffusion policy policy optimization,
A. Ren, J. Lidard, L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz, “Diffusion policy policy optimization,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 77 288–77 329
work page 2025
-
[27]
Accelerating reinforce- ment learning with learned skill priors,
K. Pertsch, Y . Lee, and J. J. Lim, “Accelerating reinforce- ment learning with learned skill priors,” inConference on Robot Learning (CoRL), 2020
work page 2020
-
[28]
Parrot: Data-driven behavioral priors for reinforcement learning,
A. Singh, H. Liu, G. Zhou, A. Yu, N. Rhinehart, and S. Levine, “Parrot: Data-driven behavioral priors for reinforcement learning,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[29]
{OPAL}: Offline primitive discovery for accelerating offline reinforcement learning,
A. Ajay, A. Kumar, P. Agrawal, S. Levine, and O. Nachum, “{OPAL}: Offline primitive discovery for accelerating offline reinforcement learning,” inInterna- tional Conference on Learning Representations, 2021
work page 2021
-
[30]
Demonstration- guided reinforcement learning with learned skills,
K. Pertsch, Y . Lee, Y . Wu, and J. J. Lim, “Demonstration- guided reinforcement learning with learned skills,” in5th Conference on Robot Learning, 2021
work page 2021
-
[31]
EXPO: Stable Reinforcement Learning with Expressive Policies
P. Dong, Q. Li, D. Sadigh, and C. Finn, “EXPO: Stable reinforcement learning with expressive policies,”arXiv preprint arXiv:2507.07986, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Ignorance is bliss: Robust control via information gating,
M. Tomar, R. Islam, M. E. Taylor, S. Levine, and P. Bachman, “Ignorance is bliss: Robust control via information gating,” inThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[33]
Infobot: Trans- fer and exploration via the information bottleneck,
A. Goyal, R. Islam, D. Strouse, Z. Ahmed, M. Botvinick, H. Larochelle, Y . Bengio, and S. Levine, “Infobot: Trans- fer and exploration via the information bottleneck,”arXiv preprint arXiv:1901.10902, 2023
-
[34]
History-guided video diffusion,
K. Song, B. Chen, M. Simchowitz, Y . Du, R. Tedrake, and V . Sitzmann, “History-guided video diffusion,” inForty-second International Conference on Machine Learning, 2025
work page 2025
-
[35]
Diffusion forcing: Next-token prediction meets full-sequence diffusion,
B. Chen, D. Mart ´ı Mons ´o, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann, “Diffusion forcing: Next-token prediction meets full-sequence diffusion,” Advances in Neural Information Processing Systems, vol. 37, pp. 24 081–24 125, 2025
work page 2025
-
[36]
J. Zhang, M. Memmel, K. Kim, D. Fox, J. Thomason, F. Ramos, E. Bıyık, A. Gupta, and A. Li, “Peek: Guiding and minimal image representations for zero-shot gener- alization of robot manipulation policies,” in2026 IEEE International Conference on Robotics and Automation (ICRA), 2026
work page 2026
-
[37]
Blindfolded experts generalize better: Insights from robotic manipulation and videogames,
E. Zisselman, M. Mutti, S. Francis-Meretzki, E. Shafer, and A. Tamar, “Blindfolded experts generalize better: Insights from robotic manipulation and videogames,” in The Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2025
work page 2025
-
[38]
Aug- mented reality for robots (arro): Pointing visuomotor policies towards visual robustness,
R. Mirjalili, T. J ¨ulg, F. Walter, and W. Burgard, “Aug- mented reality for robots (arro): Pointing visuomotor policies towards visual robustness,”IEEE Robotics and Automation Letters, 2026
work page 2026
-
[39]
Controlvla: Few-shot object-centric adaptation for pre-trained vision- language-action models,
P. Li, Y . Wu, Z. Xi, W. Li, Y . Huang, Z. Zhang, Y . Chen, J. Wang, S.-C. Zhu, T. Liu, and S. Huang, “Controlvla: Few-shot object-centric adaptation for pre-trained vision- language-action models,”CoRR, vol. abs/2506.16211, June 2025
-
[40]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guid- ance,”arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Ran- domized smoothing for stochastic optimization,
J. C. Duchi, P. L. Bartlett, and M. J. Wainwright, “Ran- domized smoothing for stochastic optimization,”SIAM Journal on Optimization, vol. 22, no. 2, pp. 674–701, 2012
work page 2012
-
[42]
Bundled gradi- ents through contact via randomized smoothing,
H. J. T. Suh, T. Pang, and R. Tedrake, “Bundled gradi- ents through contact via randomized smoothing,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4000– 4007, 2022
work page 2022
-
[43]
Certified adver- sarial robustness via randomized smoothing,
J. Cohen, E. Rosenfeld, and Z. Kolter, “Certified adver- sarial robustness via randomized smoothing,” inInterna- tional Conference on Machine Learning. PMLR, 2019, pp. 1310–1320
work page 2019
-
[44]
Og- bench: Benchmarking offline goal-conditioned rl,
S. Park, K. Frans, B. Eysenbach, and S. Levine, “Og- bench: Benchmarking offline goal-conditioned rl,” in International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[45]
Affordance-based robot manipulation with flow matching,
F. Zhang and M. Gienger, “Affordance-based robot manipulation with flow matching,”arXiv preprint arXiv:2409.01083, 2025
-
[46]
Much ado about noising: Dispelling the myths of generative robotic control,
C. Pan, G. Anantharaman, N.-C. Huang, C. Jin, D. Pfrommer, C. Yuan, F. Permenter, G. Qu, N. Boffi, G. Shi, and M. Simchowitz, “Much ado about noising: Dispelling the myths of generative robotic control,”arXiv preprint arXiv:2512.01809, 2025
-
[47]
Rfs: Reinforcement learning with residual flow steering for dexterous manipulation,
E. Su, T. Westenbroek, A. Nagabandi, and A. Gupta, “Rfs: Reinforcement learning with residual flow steering for dexterous manipulation,” inThe Fourteenth Interna- tional Conference on Learning Representations, 2026
work page 2026
-
[48]
Generative modeling by esti- mating gradients of the data distribution,
Y . Song and S. Ermon, “Generative modeling by esti- mating gradients of the data distribution,” inAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch ´e-Buc, E. Fox, and R. Garnett, Eds., vol. 32. Curran Associates, Inc., 2019
work page 2019
-
[49]
Denoising Diffusion Probabilistic Models
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”arXiv preprint arxiv:2006.11239, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[50]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learn- ing Representations, 2021
work page 2021
-
[51]
Soft actor-critic: Off-policy maximum entropy deep reinforce- ment learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforce- ment learning with a stochastic actor,” inProceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 1861–1870
work page 2018
-
[52]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π 0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,”arXiv preprint arXiv:2306.03310, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun, “Libero-pro: Towards robust and fair evaluation of vision-language-action models be- yond memorization,”[arXiv preprint arXiv:2510.03827], 2025
-
[55]
Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning,
K. Shaw, A. Agarwal, and D. Pathak, “Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning,”Robotics: Science and Systems (RSS), 2023
work page 2023
-
[56]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. Anwar, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G. Malczyk, H...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Bridgedata v2: A dataset for robot learning at scale,
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . Myers, M. J. Kim, M. Du, A. Lee, K. Fang, C. Finn, and S. Levine, “Bridgedata v2: A dataset for robot learning at scale,” in Proceedings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., ...
work page 2023
-
[58]
Droid: A large-scale in-the-wild robot manipulation dataset,
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
work page 2024
-
[59]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF interna- tional conference on computer vision, 2023, pp. 4195– 4205
work page 2023
-
[60]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Comput., vol. 9, no. 8, p. 1735–1780, Nov. 1997
work page 1997
-
[61]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[62]
A system for general in-hand object re-orientation,
T. Chen, J. Xu, and P. Agrawal, “A system for general in-hand object re-orientation,” inProceedings of the 5th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, A. Faust, D. Hsu, and G. Neumann, Eds., vol. 164. PMLR, 08–11 Nov 2022, pp. 297–307
work page 2022
-
[63]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” inarXiv preprint: 1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[64]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features without supe...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.