Recognition: 2 theorem links
· Lean TheoremTrackCraft3R: Repurposing Video Diffusion Transformers for Dense 3D Tracking
Pith reviewed 2026-05-14 21:25 UTC · model grok-4.3
The pith
A video diffusion transformer can be repurposed as a feed-forward dense 3D tracker that follows every pixel from a reference frame across a monocular video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
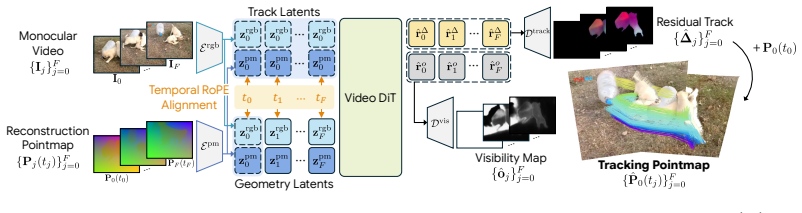
TrackCraft3R takes a monocular video together with its per-frame reconstruction pointmap and outputs a reference-anchored tracking pointmap that follows every pixel of the first frame through time, plus visibility, by means of a dual-latent representation (per-frame geometry latents paired with reference-anchored track latents) and temporal RoPE alignment that sets the target timestamp for each track latent, all achieved via LoRA fine-tuning of a pre-trained video DiT.
What carries the argument
Dual-latent representation that pairs per-frame geometry latents with reference-anchored track latents, plus temporal RoPE alignment to specify timestamps, converting the model's frame-anchored generation into reference-anchored tracking.
If this is right
- Dense 3D tracking becomes possible in a single forward pass without iterative optimization or multi-stage pipelines.
- Both sparse and dense 3D tracking benchmarks reach state-of-the-art accuracy using the same model.
- Runtime drops by a factor of 1.3 and peak memory by a factor of 4.6 relative to the strongest prior method.
- Tracking remains stable on long videos and under large motions without additional retraining.
Where Pith is reading between the lines
- Similar dual-latent and alignment tricks could be applied to other generative video models to extract additional geometric or motion outputs.
- The same conversion strategy might reduce the need for task-specific training data in other video understanding problems such as optical flow or instance segmentation.
- Real-time robotics or augmented-reality pipelines could adopt the resulting feed-forward tracker for on-device 3D motion estimation.
Load-bearing premise
The frame-anchored generative priors inside pre-trained video diffusion transformers can be reliably redirected to reference-anchored dense 3D tracking with only a dual-latent design, temporal RoPE changes, and LoRA fine-tuning.
What would settle it
A monocular video sequence containing rapid large-scale object deformation or camera shake in which the predicted 3D tracks show position errors substantially larger than those reported on standard benchmarks.
Figures










read the original abstract
Dense 3D tracking from monocular video is fundamental to dynamic scene understanding. While recent 3D foundation models provide reliable per-frame geometry, recovering object motion in this geometry remains challenging and benefits from strong motion priors learned from real-world videos. Existing 3D trackers either follow iterative paradigms trained from scratch on synthetic data or fine-tune 3D reconstruction models learned from static multi-view images, both lacking real-world motion priors. Pre-trained video diffusion transformers (video DiTs) offer rich spatio-temporal priors from internet-scale videos, making them a promising foundation for 3D tracking. However, their frame-anchored formulation, which generates each frame's content, is fundamentally mismatched with reference-anchored dense 3D tracking, which must follow the same physical points from a reference frame across time. We present TrackCraft3R, the first method to repurpose a video DiT as a feed-forward dense 3D tracker. Given a monocular video and its frame-anchored reconstruction pointmap, TrackCraft3R predicts a reference-anchored tracking pointmap that follows every pixel of the first frame across time in a single forward pass, along with its visibility. We achieve this through two designs: (i) a dual-latent representation that uses per-frame geometry latents and reference-anchored track latents as dense queries, and (ii) temporal RoPE alignment, which specifies the target timestamp of each track latent. Together, these designs convert the per-frame generative paradigm of video DiTs into a reference-anchored tracking formulation with LoRA fine-tuning. TrackCraft3R achieves state-of-the-art performance on standard sparse and dense 3D tracking benchmarks, while running 1.3x faster and using 4.6x less peak memory than the strongest prior method. We further demonstrate robustness to large motions and long videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TrackCraft3R, the first method to repurpose a pre-trained video diffusion transformer (DiT) as a feed-forward dense 3D tracker. Given a monocular video and its frame-anchored per-frame pointmap reconstruction, the approach predicts a reference-anchored tracking pointmap (following every pixel from the first frame) together with visibility in a single forward pass. This is achieved via a dual-latent representation that combines per-frame geometry latents with reference-anchored track latents as dense queries, plus temporal RoPE alignment to specify target timestamps for each track latent, all under LoRA fine-tuning. The authors report state-of-the-art results on standard sparse and dense 3D tracking benchmarks, 1.3x faster inference, and 4.6x lower peak memory than the strongest prior method, along with robustness to large motions and long sequences.
Significance. If the quantitative claims hold, the work would be significant for dynamic scene understanding. It successfully transfers rich real-world motion priors learned by internet-scale video DiTs to reference-anchored 3D tracking, sidestepping the limitations of synthetic-data training or static multi-view reconstruction models. The dual-latent and temporal RoPE mechanisms provide a concrete, low-cost adaptation strategy (LoRA only) that converts a generative per-frame paradigm into a tracking formulation. The reported efficiency gains are practically relevant for deployment, and the approach may generalize to other generative-to-tracking repurposing tasks.
major comments (2)
- [§4.3, Table 3] §4.3 and Table 3: the SOTA claim on dense tracking benchmarks rests on quantitative margins that are not accompanied by per-sequence error breakdowns or statistical significance tests across multiple runs; without these, it is difficult to confirm that the dual-latent plus temporal RoPE design is the load-bearing factor rather than dataset-specific tuning.
- [§3.2, Eq. (7)–(9)] §3.2, Eq. (7)–(9): the temporal RoPE alignment is presented as aligning track latents to target timestamps, yet the manuscript does not show an explicit derivation that this alignment preserves the original DiT’s positional encoding properties under the reference-anchored query formulation; a short proof or controlled ablation isolating RoPE from the dual-latent component would strengthen the central adaptation argument.
minor comments (2)
- [Abstract, §2] Abstract and §2: the term 'pointmap' is used before any definition; a one-sentence clarification on first appearance would improve readability for readers outside the immediate 3D reconstruction community.
- [Figure 4] Figure 4: the qualitative comparison panels would benefit from explicit arrows or callouts highlighting the specific failure modes of the strongest baseline that TrackCraft3R corrects.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation for minor revision, and the constructive comments on our quantitative claims and methodological details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4.3, Table 3] §4.3 and Table 3: the SOTA claim on dense tracking benchmarks rests on quantitative margins that are not accompanied by per-sequence error breakdowns or statistical significance tests across multiple runs; without these, it is difficult to confirm that the dual-latent plus temporal RoPE design is the load-bearing factor rather than dataset-specific tuning.
Authors: We appreciate the referee's point that additional analysis would strengthen confidence in the source of the gains. Table 3 already reports consistent improvements across the full DAVIS and TAP-Vid test sets. In the revised manuscript we will add a supplementary table with per-sequence error breakdowns for representative sequences and report standard deviations over three independent runs with different random seeds. This will allow readers to assess whether the dual-latent and temporal RoPE components are the primary drivers of performance. revision: yes
-
Referee: [§3.2, Eq. (7)–(9)] §3.2, Eq. (7)–(9): the temporal RoPE alignment is presented as aligning track latents to target timestamps, yet the manuscript does not show an explicit derivation that this alignment preserves the original DiT’s positional encoding properties under the reference-anchored query formulation; a short proof or controlled ablation isolating RoPE from the dual-latent component would strengthen the central adaptation argument.
Authors: We agree that an explicit derivation and isolating ablation would clarify the adaptation mechanism. In the revised §3.2 we will insert a short proof sketch showing that the temporal RoPE shift preserves the original sinusoidal properties when mapping reference-anchored track latents to target timestamps. We will also add a controlled ablation that isolates the temporal RoPE component from the dual-latent representation to quantify its contribution to the overall tracking formulation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central derivation introduces two explicit new architectural components—a dual-latent representation (per-frame geometry latents plus reference-anchored track latents) and temporal RoPE alignment—to shift a pre-trained video DiT from frame-anchored generation to reference-anchored tracking, followed by LoRA fine-tuning. These elements are presented as novel design choices rather than quantities derived from or fitted to the target outputs. No equations reduce the predicted reference-anchored pointmap to a re-expression of the input frame-anchored pointmap by construction, and no load-bearing premise rests on a self-citation chain whose validity is assumed without external verification. Performance claims are framed as empirical results, not logical necessities, leaving the derivation self-contained against the stated inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained video diffusion transformers contain rich spatio-temporal priors from internet-scale videos that are useful for 3D tracking.
invented entities (2)
-
dual-latent representation
no independent evidence
-
temporal RoPE alignment
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual-latent representation that uses per-frame geometry latents and reference-anchored track latents as dense queries, and (ii) temporal RoPE alignment, which specifies the target timestamp of each track latent
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We achieve this through two designs: (i) a dual-latent representation... (ii) temporal RoPE alignment... with LoRA fine-tuning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mapillary planet-scale depth dataset
Manuel López Antequera, Pau Gargallo, Markus Hofinger, Samuel Rota Bulo, Yubin Kuang, and Peter Kontschieder. Mapillary planet-scale depth dataset. InEuropean Conference on Computer Vision, pages 589–604. Springer, 2020
work page 2020
-
[2]
Track2Act: Predicting point tracks from internet videos enables generalizable robot manipulation
Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2Act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision, pages 306–324. Springer, 2024
work page 2024
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual KITTI 2.arXiv preprint arXiv:2001.10773, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[5]
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin. VideoJam: Joint appearance-motion representations for enhanced motion generation in video models.arXiv preprint arXiv:2502.02492, 2025
-
[6]
Local all-pair correspondence for point tracking
Seokju Cho, Jiahui Huang, Jisu Nam, Honggyu An, Seungryong Kim, and Joon-Young Lee. Local all-pair correspondence for point tracking. InEuropean conference on computer vision, pages 306–325. Springer, 2024
work page 2024
-
[7]
Seurat: From moving points to depth
Seokju Cho, Jiahui Huang, Seungryong Kim, and Joon-Young Lee. Seurat: From moving points to depth. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7211–7221, 2025
work page 2025
-
[8]
ScanNet: Richly-annotated 3D reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
work page 2017
-
[9]
Objaverse: A universe of annotated 3D objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3D objects. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023
work page 2023
-
[10]
Is this tracker on? a benchmark protocol for dynamic tracking.arXiv preprint arXiv:2510.19819, 2025
Ilona Demler, Saumya Chauhan, and Georgia Gkioxari. Is this tracker on? a benchmark protocol for dynamic tracking.arXiv preprint arXiv:2510.19819, 2025
-
[11]
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adria Recasens, Lucas Smaira, Yusuf Aytar, Joao Carreira, Andrew Zisserman, and Yi Yang. Tap-Vid: A benchmark for tracking any point in a video.Advances in Neural Information Processing Systems, 35:13610–13626, 2022
work page 2022
-
[12]
TAPIR: Tracking any point with per-frame initialization and temporal refinement
Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, Joao Carreira, and Andrew Zisserman. TAPIR: Tracking any point with per-frame initialization and temporal refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10061–10072, 2023
work page 2023
-
[13]
Black, Trevor Darrell, and Angjoo Kanazawa
Haiwen Feng, Junyi Zhang, Qianqian Wang, Yufei Ye, Pengcheng Yu, Michael J. Black, Trevor Darrell, and Angjoo Kanazawa. St4RTrack: Simultaneous 4D reconstruction and tracking in the world. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8503–8513, 2025
work page 2025
-
[14]
GeoWizard: Unleashing the diffusion priors for 3D geometry estimation from a single image
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. GeoWizard: Unleashing the diffusion priors for 3D geometry estimation from a single image. In European Conference on Computer Vision, pages 241–258. Springer, 2024
work page 2024
-
[15]
Motion prompting: Controlling video generation with motion trajectories
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez- Guevara, Yusuf Aytar, Michael Rubinstein, Chen Sun, et al. Motion prompting: Controlling video generation with motion trajectories. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1–12, 2025
work page 2025
-
[16]
Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, et al
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J. Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, et al. Kubric: A scalable dataset generator. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3749–3761, 2022
work page 2022
-
[17]
D 2USt3R: Enhancing 3D reconstruction for dynamic scenes.arXiv preprint arXiv:2504.06264, 2025
Jisang Han, Honggyu An, Jaewoo Jung, Takuya Narihira, Junyoung Seo, Kazumi Fukuda, Chaehyun Kim, Sunghwan Hong, Yuki Mitsufuji, and Seungryong Kim. D 2USt3R: Enhancing 3D reconstruction for dynamic scenes.arXiv preprint arXiv:2504.06264, 2025. 10
-
[18]
Jisang Han, Sunghwan Hong, Jaewoo Jung, Wooseok Jang, Honggyu An, Qianqian Wang, Seungryong Kim, and Chen Feng. Emergent outlier view rejection in visual geometry grounded transformers.arXiv preprint arXiv:2512.04012, 2025
-
[19]
Harley, Zhaoyuan Fang, and Katerina Fragkiadaki
Adam W. Harley, Zhaoyuan Fang, and Katerina Fragkiadaki. Particle video revisited: Tracking through occlusions using point trajectories. InEuropean Conference on Computer Vision, pages 59–75. Springer, 2022
work page 2022
-
[20]
Adam W. Harley, Yang You, Xinglong Sun, Yang Zheng, Nikhil Raghuraman, Yunqi Gu, Sheldon Liang, Wen-Hsuan Chu, Achal Dave, Suya You, et al. AllTracker: Efficient dense point tracking at high resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5253–5262, 2025
work page 2025
-
[21]
Lotus: Diffusion-based visual foundation model for high-quality dense prediction
Jing He, Haodong Li, Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Zhang, Bingbing Liu, and Ying-Cong Chen. Lotus: Diffusion-based visual foundation model for high-quality dense prediction. arXiv preprint arXiv:2409.18124, 2024
-
[22]
Eric Hedlin, Gopal Sharma, Shweta Mahajan, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. Unsupervised semantic correspondence using stable diffusion.Advances in Neural Information Processing Systems, 36:8266–8279, 2023
work page 2023
-
[23]
Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022
work page 2022
-
[24]
DepthCrafter: Generating consistent long depth sequences for open-world videos
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. DepthCrafter: Generating consistent long depth sequences for open-world videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2005–2015, 2025
work page 2005
-
[25]
arXiv preprint arXiv:2508.10934 (2025)
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Korovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, et al. ViPE: Video pose engine for 3D geometric perception.arXiv preprint arXiv:2508.10934, 2025
-
[26]
DeepMVS: Learning multi-view stereopsis
Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. DeepMVS: Learning multi-view stereopsis. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2821–2830, 2018
work page 2018
-
[27]
Wenlong Huang, Yu-Wei Chao, Arsalan Mousavian, Ming-Yu Liu, Dieter Fox, Kaichun Mo, and Li Fei- Fei. PointWorld: Scaling 3D world models for in-the-wild robotic manipulation.arXiv preprint arXiv:2601.03782, 2026
-
[28]
Rays as Pixels: Learning A Joint Distribution of Videos and Camera Trajectories
Wonbong Jang, Shikun Liu, Soubhik Sanyal, Juan Camilo Perez, Kam Woh Ng, Sanskar Agrawal, Juan- Manuel Perez-Rua, Yiannis Douratsos, and Tao Xiang. Rays as pixels: Learning a joint distribution of videos and camera trajectories.arXiv preprint arXiv:2604.09429, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Geo4D: Leveraging video gen- erators for geometric 4D scene reconstruction
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and Andrea Vedaldi. Geo4D: Leveraging video gen- erators for geometric 4D scene reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20658–20671, 2025
work page 2025
-
[30]
Linyi Jin, Richard Tucker, Zhengqi Li, David Fouhey, Noah Snavely, and Aleksander Holynski. Stereo4D: Learning how things move in 3D from internet stereo videos.arXiv preprint arXiv:2412.09621, 2024
-
[31]
Panoptic studio: A massively multiview system for social motion capture
Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview system for social motion capture. InProceedings of the IEEE international conference on computer vision, pages 3334–3342, 2015
work page 2015
-
[32]
DynamicStereo: Consistent dynamic depth from stereo videos
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. DynamicStereo: Consistent dynamic depth from stereo videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13229–13239, 2023
work page 2023
-
[33]
CoTracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. CoTracker: It is better to track together. InEuropean conference on computer vision, pages 18–35. Springer, 2024
work page 2024
-
[34]
CoTracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. CoTracker3: Simpler and better point tracking by pseudo-labelling real videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6013–6022, 2025. 11
work page 2025
-
[35]
Any4D: Unified feed-forward metric 4D reconstruction.arXiv preprint arXiv:2512.10935, 2025
Jay Karhade, Nikhil Keetha, Yuchen Zhang, Tanisha Gupta, Akash Sharma, Sebastian Scherer, and Deva Ramanan. Any4D: Unified feed-forward metric 4D reconstruction.arXiv preprint arXiv:2512.10935, 2025
-
[36]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9492–9502, 2024
work page 2024
-
[37]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. MapAnything: Universal feed-forward metric 3D reconstruction.arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Jisoo Kim, Jungbin Cho, Sanghyeok Chu, Ananya Bal, Jinhyung Kim, Gunhee Lee, Sihaeng Lee, Se- ung Hwan Kim, Bohyung Han, Hyunmin Lee, et al. Pri4R: Learning world dynamics for vision-language- action models with privileged 4D representation.arXiv preprint arXiv:2603.01549, 2026
- [39]
-
[40]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. HunyuanVideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Skanda Koppula, Ignacio Rocco, Yi Yang, Joe Heyward, Joao Carreira, Andrew Zisserman, Gabriel Brostow, and Carl Doersch. TapVid-3D: A benchmark for tracking any point in 3D.Advances in Neural Information Processing Systems, 37:82149–82165, 2024
work page 2024
-
[42]
Grounding image matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3D with MASt3R. In European conference on computer vision, pages 71–91. Springer, 2024
work page 2024
-
[43]
MegaDepth: Learning single-view depth prediction from internet photos
Zhengqi Li and Noah Snavely. MegaDepth: Learning single-view depth prediction from internet photos. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2041–2050, 2018
work page 2041
-
[44]
MegaSaM: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. MegaSaM: Accurate, fast and robust structure and motion from casual dynamic videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10486–10496, 2025
work page 2025
-
[45]
Zero-shot monocular scene flow estimation in the wild
Yiqing Liang, Abhishek Badki, Hang Su, James Tompkin, and Orazio Gallo. Zero-shot monocular scene flow estimation in the wild. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21031–21044, 2025
work page 2025
-
[46]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth Anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
DL3DV-10K: A large-scale scene dataset for deep learning-based 3D vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. DL3DV-10K: A large-scale scene dataset for deep learning-based 3D vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160– 22169, 2024
work page 2024
-
[48]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
Xinhang Liu, Yuxi Xiao, Donny Y Chen, Jiashi Feng, Yu-Wing Tai, Chi-Keung Tang, and Bingyi Kang. Trace Anything: Representing any video in 4D via trajectory fields.arXiv preprint arXiv:2510.13802, 2025
-
[50]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[51]
Can video diffusion model reconstruct 4D geometry?arXiv preprint arXiv:2503.21082, 2025
Jinjie Mai, Wenxuan Zhu, Haozhe Liu, Bing Li, Cheng Zheng, Jürgen Schmidhuber, and Bernard Ghanem. Can video diffusion model reconstruct 4D geometry?arXiv preprint arXiv:2503.21082, 2025
-
[52]
Diffusion model for dense matching.arXiv preprint arXiv:2305.19094, 2023
Jisu Nam, Gyuseong Lee, Sunwoo Kim, Hyeonsu Kim, Hyoungwon Cho, Seyeon Kim, and Seungryong Kim. Diffusion model for dense matching.arXiv preprint arXiv:2305.19094, 2023
-
[53]
Jisu Nam, Soowon Son, Dahyun Chung, Jiyoung Kim, Siyoon Jin, Junhwa Hur, and Seungryong Kim. Emergent temporal correspondences from video diffusion transformers.arXiv preprint arXiv:2506.17220, 2025. 12
-
[54]
DELTA: Dense efficient long-range 3D tracking for any video.arXiv preprint arXiv:2410.24211, 2024
Tuan Duc Ngo, Peiye Zhuang, Chuang Gan, Evangelos Kalogerakis, Sergey Tulyakov, Hsin-Ying Lee, and Chaoyang Wang. DELTA: Dense efficient long-range 3D tracking for any video.arXiv preprint arXiv:2410.24211, 2024
-
[55]
DELTAv2: Accelerating dense 3D tracking.arXiv preprint arXiv:2508.01170, 2025
Tuan Duc Ngo, Ashkan Mirzaei, Guocheng Qian, Hanwen Liang, Chuang Gan, Evangelos Kaloger- akis, Peter Wonka, and Chaoyang Wang. DELTAv2: Accelerating dense 3D tracking.arXiv preprint arXiv:2508.01170, 2025
-
[56]
Aria Digital Twin: A new benchmark dataset for egocentric 3D machine perception
Xiaqing Pan, Nicholas Charron, Yongqian Yang, Scott Peters, Thomas Whelan, Chen Kong, Omkar Parkhi, Richard Newcombe, and Yuheng Carl Ren. Aria Digital Twin: A new benchmark dataset for egocentric 3D machine perception. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20133–20143, 2023
work page 2023
-
[57]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 DA VIS challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
Common objects in 3D: Large-scale learning and evaluation of real-life 3D category reconstruc- tion
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3D: Large-scale learning and evaluation of real-life 3D category reconstruc- tion. InProceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021
work page 2021
-
[59]
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 10912–10922, 2021
work page 2021
-
[60]
Peter Sand and Seth Teller. Particle video: Long-range motion estimation using point trajectories.Interna- tional journal of computer vision, 80(1):72–91, 2008
work page 2008
-
[61]
Saurabh Saxena, Charles Herrmann, Junhwa Hur, Abhishek Kar, Mohammad Norouzi, Deqing Sun, and David J. Fleet. The surprising effectiveness of diffusion models for optical flow and monocular depth estimation.Advances in Neural Information Processing Systems, 36:39443–39469, 2023
work page 2023
-
[62]
Learning temporally consistent video depth from video diffusion priors
Jiahao Shao, Yuanbo Yang, Hongyu Zhou, Youmin Zhang, Yujun Shen, Vitor Guizilini, Yue Wang, Matteo Poggi, and Yiyi Liao. Learning temporally consistent video depth from video diffusion priors. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22841–22852, 2025
work page 2025
-
[63]
Soowon Son, Honggyu An, Chaehyun Kim, Hyunah Ko, Jisu Nam, Dahyun Chung, Siyoon Jin, Jung Yi, Jaewon Min, Junhwa Hur, et al. Repurposing video diffusion transformers for robust point tracking.arXiv preprint arXiv:2512.20606, 2025
-
[64]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[65]
V-DPM: 4D video reconstruction with dynamic point maps.arXiv preprint arXiv:2601.09499, 2026
Edgar Sucar, Eldar Insafutdinov, Zihang Lai, and Andrea Vedaldi. V-DPM: 4D video reconstruction with dynamic point maps.arXiv preprint arXiv:2601.09499, 2026
-
[66]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
work page 2020
-
[67]
Andrew Szot, Alexander Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Singh Chaplot, Oleksandr Maksymets, et al. Habitat 2.0: Training home assistants to rearrange their habitat.Advances in neural information processing systems, 34:251–266, 2021
work page 2021
-
[68]
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emergent correspondence from image diffusion.Advances in neural information processing systems, 36:1363–1389, 2023
work page 2023
-
[69]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Bo Wang, Jian Li, Yang Yu, Li Liu, Zhenping Sun, and Dewen Hu. SceneTracker: Long-term scene flow estimation network.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 13
work page 2025
-
[71]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[72]
DUSt3R: Geometric 3D vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3D vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
work page 2024
-
[73]
TartanAir: A dataset to push the limits of visual SLAM
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. TartanAir: A dataset to push the limits of visual SLAM. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4909–4916. IEEE, 2020
work page 2020
-
[74]
RGBD objects in the wild: Scaling real-world 3D object learning from RGB-D videos
Hongchi Xia, Yang Fu, Sifei Liu, and Xiaolong Wang. RGBD objects in the wild: Scaling real-world 3D object learning from RGB-D videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22378–22389, 2024
work page 2024
-
[75]
SpatialTracker: Tracking any 2D pixels in 3D space
Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, and Xiaowei Zhou. SpatialTracker: Tracking any 2D pixels in 3D space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20406–20417, 2024
work page 2024
-
[76]
SpatialTrackerV2: 3D point tracking made easy.arXiv preprint arXiv:2507.12462, 2025
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. SpatialTrackerV2: 3D point tracking made easy.arXiv preprint arXiv:2507.12462, 2025
-
[77]
DynamiCrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. DynamiCrafter: Animating open-domain images with video diffusion priors. InEuropean Conference on Computer Vision, pages 399–417. Springer, 2024
work page 2024
-
[78]
GeometryCrafter: Consistent geometry estimation for open-world videos with diffusion priors
Tian-Xing Xu, Xiangjun Gao, Wenbo Hu, Xiaoyu Li, Song-Hai Zhang, and Ying Shan. GeometryCrafter: Consistent geometry estimation for open-world videos with diffusion priors. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6632–6644, 2025
work page 2025
-
[79]
Fast3R: Towards 3D reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3R: Towards 3D reconstruction of 1000+ images in one forward pass. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
work page 2025
-
[80]
Depth Anything V2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth Anything V2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.