Recognition: no theorem link
State-Centric Decision Process
Pith reviewed 2026-05-14 19:33 UTC · model grok-4.3
The pith
The State-Centric Decision Process lets agents build their own certified state spaces from raw language observations using natural-language predicates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
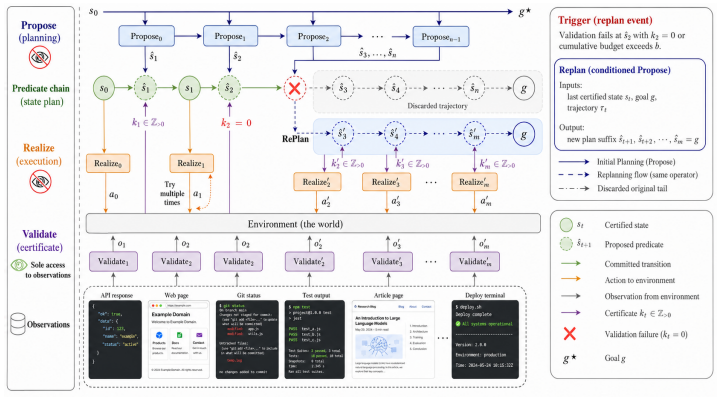
SDP is a runtime framework that constructs the four objects language environments lack—an explicit state space, an observation-to-state mapping, certified transitions, and a termination criterion—by requiring the agent to commit to a natural-language predicate at every step, act to make it true, and certify the observation against it. The resulting trajectories support standard analyses plus diagnostics unavailable to purely reactive agents.
What carries the argument
The predicate commitment-and-verification loop, which turns each raw observation into a certified state only after the agent has declared and checked a natural-language description of the target condition.
If this is right
- SDP records the highest training-free scores on all five evaluated benchmarks.
- The performance gap over reactive baselines increases with longer task horizons.
- Certified trajectories enable per-predicate credit assignment, failure localization, partial-progress measurement, and modular operator replacement.
Where Pith is reading between the lines
- The certified states could be fed directly into existing symbolic planners to replace exhaustive search with guided predicate sequences.
- Verification accuracy might be raised by cross-checking a predicate against multiple observations or external oracles.
- The same predicate loop could be applied to embodied agents whose sensors return text descriptions of physical scenes.
Load-bearing premise
An agent can reliably choose a natural-language predicate describing the desired next state and correctly verify whether the subsequent observation satisfies that predicate without external supervision.
What would settle it
A long-horizon benchmark run in which SDP produces verification errors on more than half the predicates and ends with lower success rates than a simple reactive baseline would falsify the claim that the loop reliably supplies usable certified states.
Figures


read the original abstract
Language environments such as web browsers, code terminals, and interactive simulations emit raw text rather than states, and provide none of the runtime structure that MDP analysis requires. No explicit state space, no observation-to-state mapping, no certified transitions, and no termination criterion. We introduce the State-Centric Decision Process (SDP), a runtime framework that constructs these missing inputs by having the agent build them, predicate by predicate, as it acts. At each step the agent commits to a natural-language predicate describing how the world should look, takes an action to make it true, and checks the observation against it. Predicates that pass become certified states, and the resulting trajectory carries the four objects language environments do not provide, namely a task-induced state space, an observation-to-state mapping, certified transitions, and a termination criterion. We evaluate SDP on five benchmarks spanning planning, scientific exploration, web reasoning, and multi-hop question answering. SDP achieves the best training-free results on all five, with the advantage widening as the horizon grows. The certified trajectories additionally support analyses unavailable to reactive agents, including per-predicate credit assignment, failure localization, partial-progress measurement, and modular operator replacement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the State-Centric Decision Process (SDP), a runtime framework for language environments (e.g., browsers, code terminals) that lack explicit MDP structure. The agent commits to natural-language predicates describing desired world states, takes actions to satisfy them, and verifies observations against the predicates; passing predicates become certified states. This yields a task-induced state space, observation-to-state mapping, certified transitions, and termination criterion. SDP is evaluated on five benchmarks spanning planning, scientific exploration, web reasoning, and multi-hop QA, claiming the best training-free results with the advantage widening as the horizon grows. The certified trajectories enable analyses unavailable to reactive agents, including per-predicate credit assignment, failure localization, partial-progress measurement, and modular operator replacement.
Significance. If the self-verification step is reliable, SDP offers a substantive contribution by retrofitting formal decision-process structure onto unstructured language agents without training. This could enable interpretable long-horizon reasoning and diagnostic tools in practical domains. The reported widening performance gap with horizon length, if substantiated with quantitative data, would strengthen the case for SDP over purely reactive baselines.
major comments (2)
- [SDP Construction] SDP Construction / Predicate Verification: The framework certifies states and transitions solely via the same language model verifying its own generated predicates against observations. No external oracle, ground-truth checker, or measured verification accuracy (e.g., false-positive rate on the NLI task) is described. This assumption is load-bearing for the 'certified' label, the constructed state space, termination criterion, and all downstream empirical claims and analyses.
- [Experimental Evaluation] Experimental Evaluation: The claim of achieving the best training-free results on all five benchmarks (with widening advantage as horizon grows) is presented without quantitative tables, specific metrics, error bars, baseline details, or any reporting on predicate verification accuracy in the evaluation. This prevents assessment of whether the superiority holds after accounting for potential verification errors.
minor comments (1)
- [Introduction] The paper would benefit from an early concrete example (e.g., one full predicate-verify cycle on a benchmark) to clarify the observation-to-state mapping and termination criterion.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline revisions that will strengthen the manuscript's clarity and empirical support.
read point-by-point responses
-
Referee: [SDP Construction] SDP Construction / Predicate Verification: The framework certifies states and transitions solely via the same language model verifying its own generated predicates against observations. No external oracle, ground-truth checker, or measured verification accuracy (e.g., false-positive rate on the NLI task) is described. This assumption is load-bearing for the 'certified' label, the constructed state space, termination criterion, and all downstream empirical claims and analyses.
Authors: We agree that SDP relies on the language model's self-verification for certification, as no external oracle is available in the unstructured language environments we target. This is a deliberate design choice to enable structured decision processes without additional infrastructure. In the revision we will add a dedicated subsection (new Section 4.3) that empirically measures verification reliability: we will sample 200 predicate-observation pairs across the benchmarks, obtain human annotations for correctness, and report precision, recall, and false-positive rates. This directly quantifies the load-bearing assumption and supports the certified state space claims. revision: yes
-
Referee: [Experimental Evaluation] Experimental Evaluation: The claim of achieving the best training-free results on all five benchmarks (with widening advantage as horizon grows) is presented without quantitative tables, specific metrics, error bars, baseline details, or any reporting on predicate verification accuracy in the evaluation. This prevents assessment of whether the superiority holds after accounting for potential verification errors.
Authors: The full manuscript contains quantitative tables in Section 5 comparing SDP against training-free baselines on all five benchmarks, along with a plot (Figure 3) demonstrating the widening performance gap as horizon length increases. We will revise the experimental section to include error bars from five independent runs per benchmark, expanded baseline implementation details, and a new paragraph linking the verification accuracy results (from the added Section 4.3) to the main performance claims. This will allow readers to evaluate robustness after accounting for verification errors. revision: partial
Circularity Check
No circularity: SDP is a runtime construction independent of fitted parameters or self-referential derivations
full rationale
The paper introduces SDP as a framework where an agent constructs state spaces, mappings, transitions, and termination criteria on the fly via natural-language predicates that are committed to and then checked against observations. No equations appear in the provided text that reduce any claimed result to a fitted input or self-definition. No self-citations are invoked to justify core premises, and the central claims rest on the runtime behavior rather than any parameter estimation or renaming of prior results. The derivation chain is self-contained against external benchmarks and does not reduce any prediction to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural language predicates can be reliably committed to and verified against raw text observations by the agent
invented entities (1)
-
State-Centric Decision Process (SDP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
State abstractions for lifelong rein- forcement learning
David Abel, Dilip Arumugam, Lucas Lehnert, and Michael Littman. State abstractions for lifelong rein- forcement learning. InInternational conference on machine learning, pages 10–19. PMLR, 2018
work page 2018
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Hindsight experience replay.Advances in neural information processing systems, 30, 2017
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob Mc- Grew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay.Advances in neural information processing systems, 30, 2017
work page 2017
-
[5]
Agent context protocols enhance collective in- ference.arXiv preprint arXiv:2505.14569, 2025
Devansh Bhardwaj, Arjun Beniwal, Shreyas Chaudhari, Ashwin Kalyan, Tanmay Rajpurohit, Karthik R Narasimhan, Ameet Deshpande, and Vishvak Murahari. Agent context protocols enhance collective in- ference.arXiv preprint arXiv:2505.14569, 2025
-
[6]
Reinforcement learning for mapping instructions to actions
Satchuthananthavale RK Branavan, Harr Chen, Luke Zettlemoyer, and Regina Barzilay. Reinforcement learning for mapping instructions to actions. InProceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, pages 82–90, 2009
work page 2009
-
[7]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[8]
arXiv preprint arXiv:2504.16563 , year=
Junjie Chen, Haitao Li, Jingli Yang, Yiqun Liu, and Qingyao Ai. Enhancing llm-based agents via global planning and hierarchical execution.arXiv preprint arXiv:2504.16563, 2025
-
[9]
Jihye Choi, Jinsung Yoon, Jiefeng Chen, Somesh Jha, and Tomas Pfister. Atlas: Constraints-aware multi- agent collaboration for real-world travel planning.arXiv preprint arXiv:2509.25586, 2025
-
[10]
Minh Pham Dinh, Munira Syed, G Yankoski Michael, and Trenton W Ford. Reasonplanner: Enhancing autonomous planning in dynamic environments with temporal knowledge graphs and llms.arXiv preprint arXiv:2410.09252, 2024. 10
-
[11]
arXiv preprint arXiv:2503.09572 , year =
Lutfi Eren Erdogan, Nicholas Lee, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. Plan-and-act: Improving planning of agents for long-horizon tasks. arXiv preprint arXiv:2503.09572, 2025
-
[12]
arXiv preprint arXiv:2411.04468 , year=
Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Gerrits, Jacob Alber, et al. Magentic-one: A generalist multi- agent system for solving complex tasks.arXiv preprint arXiv:2411.04468, 2024
-
[13]
Robert Givan, Thomas Dean, and Matthew Greig. Equivalence notions and model minimization in markov decision processes.Artificial intelligence, 147(1-2):163–223, 2003
work page 2003
-
[14]
Zikang Guo, Benfeng Xu, Xiaorui Wang, and Zhendong Mao. Mirror: Multi-agent intra-and inter- reflection for optimized reasoning in tool learning.arXiv preprint arXiv:2505.20670, 2025
-
[15]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8154–8173, 2023
work page 2023
-
[16]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pages 9118–9147. PMLR, 2022
work page 2022
-
[17]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Embodied reasoning through plan- ning with language models.arXiv preprint arXiv:2207.05608, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
work page 1998
-
[20]
Shifting from ranking to set selection for retrieval augmented generation
Dahyun Lee, Yongrae Jo, Haeju Park, and Moontae Lee. Shifting from ranking to set selection for retrieval augmented generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 17606–17619, 2025
work page 2025
-
[21]
Towards a unified theory of state abstraction for mdps.AI&M, 1(2):3, 2006
Lihong Li, Thomas J Walsh, and Michael L Littman. Towards a unified theory of state abstraction for mdps.AI&M, 1(2):3, 2006
work page 2006
-
[22]
Yunfan Li, Bingbing Xu, Xueyun Tian, Xiucheng Xu, and Huawei Shen. Beyond entangled planning: Task-decoupled planning for long-horizon agents.arXiv preprint arXiv:2601.07577, 2026
-
[23]
Bill Yuchen Lin, Yicheng Fu, Karina Yang, Faeze Brahman, Shiyu Huang, Chandra Bhagavatula, Prithvi- raj Ammanabrolu, Yejin Choi, and Xiang Ren. Swiftsage: A generative agent with fast and slow thinking for complex interactive tasks.Advances in Neural Information Processing Systems, 36:23813–23825, 2023
work page 2023
-
[24]
Positive experience reflection for agents in interactive text environments
Philip Lippmann, Matthijs TJ Spaan, and Jie Yang. Positive experience reflection for agents in interactive text environments. InProceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025), pages 131–142, 2025
work page 2025
-
[25]
Zhihan Liu, Hao Hu, Shenao Zhang, Hongyi Guo, Shuqi Ke, Boyi Liu, and Zhaoran Wang. Reason for future, act for now: A principled framework for autonomous llm agents with provable sample efficiency. arXiv preprint arXiv:2309.17382, 2023
-
[26]
Clin: A continually learning language agent for rapid task adaptation and generalization
Bodhisattwa Prasad Majumder, Bhavana Dalvi Mishra, Peter Jansen, Oyvind Tafjord, Niket Tandon, Li Zhang, Chris Callison-Burch, and Peter Clark. Clin: A continually learning language agent for rapid task adaptation and generalization.arXiv preprint arXiv:2310.10134, 2023
-
[27]
A survey of pomdp solution techniques.environment, 2(10):1–12, 2000
Kevin P Murphy et al. A survey of pomdp solution techniques.environment, 2(10):1–12, 2000
work page 2000
-
[28]
Md Mahadi Hasan Nahid and Davood Rafiei. Prism: Agentic retrieval with llms for multi-hop question answering.arXiv preprint arXiv:2510.14278, 2025
-
[29]
Ronak Pradeep, Sahel Sharifymoghaddam, and Jimmy Lin. Rankzephyr: Effective and robust zero-shot listwise reranking is a breeze!arXiv preprint arXiv:2312.02724, 2023. 11
-
[30]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023
work page 2023
-
[31]
Martin L Puterman.Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014
work page 2014
-
[32]
Infogent: An agent-based framework for web information aggregation
Revanth Gangi Reddy, Sagnik Mukherjee, Jeonghwan Kim, Zhenhailong Wang, Dilek Hakkani-Tur, and Heng Ji. Infogent: An agent-based framework for web information aggregation. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5745–5758, 2025
work page 2025
-
[33]
Universal value function approximators
Tom Schaul, Daniel Horgan, Karol Gregor, and David Silver. Universal value function approximators. In International conference on machine learning, pages 1312–1320. PMLR, 2015
work page 2015
-
[34]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach them- selves to use tools.Advances in neural information processing systems, 36:68539–68551, 2023
work page 2023
-
[35]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[36]
Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
work page 2017
-
[37]
Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023
Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L Griffiths. Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023
work page 2023
-
[38]
Haotian Sun, Yuchen Zhuang, Lingkai Kong, Bo Dai, and Chao Zhang. Adaplanner: Adaptive planning from feedback with language models.Advances in neural information processing systems, 36:58202– 58245, 2023
work page 2023
-
[39]
Is chatgpt good at search? investigating large language models as re-ranking agents
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. Is chatgpt good at search? investigating large language models as re-ranking agents. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 14918– 14937, 2023
work page 2023
-
[40]
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction. MIT press Cambridge, 1998
work page 1998
-
[41]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop ques- tions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
work page 2022
-
[42]
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 10014– 10037, 2023
work page 2023
-
[43]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
work page 2024
-
[45]
Plan- and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan- and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 2609–2634, 2023
work page 2023
-
[46]
Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. Scienceworld: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11279–11298, 2022. 12
work page 2022
-
[47]
Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian Ma, and Yitao Liang. Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents. arXiv preprint arXiv:2302.01560, 2023
-
[48]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural infor- mation processing systems, 35:24824–24837, 2022
work page 2022
-
[49]
Jason D Williams and Steve Young. Partially observable markov decision processes for spoken dialog systems.Computer Speech & Language, 21(2):393–422, 2007
work page 2007
-
[50]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learn- ing.Machine learning, 8(3):229–256, 1992
work page 1992
-
[51]
The rise and potential of large language model based agents: A survey
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey. Science China Information Sciences, 68(2):121101, 2025
work page 2025
-
[52]
Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. Travelplanner: A benchmark for real-world planning with language agents.arXiv preprint arXiv:2402.01622, 2024
-
[53]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 2369– 2380, 2018
work page 2018
-
[54]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[55]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. Assistantbench: Can web agents solve realistic and time-consuming tasks? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8938–8968, 2024
work page 2024
-
[57]
Steve Young, Milica Gaši ´c, Blaise Thomson, and Jason D Williams. Pomdp-based statistical spoken dialog systems: A review.Proceedings of the IEEE, 101(5):1160–1179, 2013
work page 2013
-
[58]
Evoagent: Towards automatic multi-agent generation via evolutionary algorithms
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Dongsheng Li, and Deqing Yang. Evoagent: Towards automatic multi-agent generation via evolutionary algorithms. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6192–6217, 2025
work page 2025
-
[59]
Planning with multi-constraints via collaborative language agents
Cong Zhang, Xin Deik Goh, Dexun Li, Hao Zhang, and Yong Liu. Planning with multi-constraints via collaborative language agents. InProceedings of the 31st International Conference on Computational Linguistics, pages 10054–10082, 2025
work page 2025
-
[60]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 38, pages 19632–19642, 2024
work page 2024
-
[61]
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. Gpt-4v (ision) is a generalist web agent, if grounded.arXiv preprint arXiv:2401.01614, 2024
-
[62]
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Lan- guage agent tree search unifies reasoning acting and planning in language models.arXiv preprint arXiv:2310.04406, 2023
-
[63]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 13 A Implementation details A.1 Common Settings All five benchmarks share the same SDP core loop; only the adapter...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.