Recognition: unknown
GRIP-VLM: Group-Relative Importance Pruning for Efficient Vision-Language Models
Pith reviewed 2026-05-14 19:12 UTC · model grok-4.3
The pith
GRIP-VLM uses reinforcement learning to optimize discrete visual token pruning in VLMs, avoiding suboptimal local minima from gradient relaxations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRIP-VLM formulates pruning as a Markov Decision Process, employing a Group Relative Policy Optimization (GRPO) paradigm anchored by supervised warm-up to directly explore the discrete selection space, integrated with a budget-aware scorer that dynamically evaluates per-token importance and adapts to arbitrary compression ratios without retraining.
What carries the argument
The Group Relative Policy Optimization (GRPO) agent paired with a budget-aware scorer that produces discrete pruning masks.
If this is right
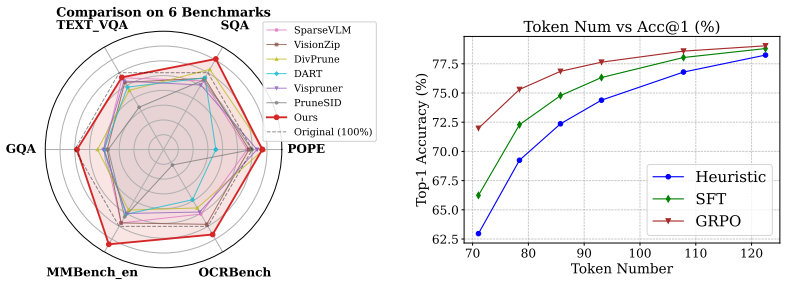
- GRIP-VLM achieves a superior Pareto frontier relative to heuristic and supervised-learning baselines.
- The method delivers up to 15% inference speedup at equal accuracy on multimodal tasks.
- The lightweight agent adapts to any compression ratio without retraining.
- Consistent gains appear across diverse vision-language benchmarks.
Where Pith is reading between the lines
- The same discrete-optimization framing could transfer to token pruning inside pure language models or other multimodal architectures.
- Stability from the group-relative formulation may support larger token budgets than prior RL attempts.
- Pairing GRIP-VLM masks with quantization or distillation could produce compounded efficiency improvements.
Load-bearing premise
The Group Relative Policy Optimization agent can reliably discover high-quality discrete pruning masks across varying compression budgets without retraining and without the instability typical of RL on combinatorial spaces.
What would settle it
A head-to-head run on the same VLM architectures and benchmarks showing that the best continuous-gradient baseline matches or exceeds GRIP-VLM accuracy and latency at 50% or higher token compression.
Figures









read the original abstract
In Vision-Language Models (VLMs), processing a massive number of visual tokens incurs prohibitive computational overhead. While recent training-aware pruning methods attempt to selectively discard redundant tokens, they largely rely on continuous-gradient relaxations. However, visual token pruning is inherently a discrete, non-convex combinatorial problem; consequently, these continuous approximations frequently trap the optimization in sub-optimal local minima, especially under aggressive compression budgets. To overcome this fundamental bottleneck, we propose GRIP-VLM, a Group-Relative Importance Pruning framework driven by Reinforcement Learning. Rather than relying on smooth-gradient assumptions, GRIP-VLM formulates pruning as a Markov Decision Process, employing a Group Relative Policy Optimization (GRPO) paradigm anchored by supervised warm-up to directly explore the discrete selection space. Integrated with a budget-aware scorer, our lightweight agent dynamically evaluates per-token importance and adapts to arbitrary compression ratios without retraining. Extensive experiments across diverse multimodal benchmarks demonstrate that GRIP-VLM consistently outperforms heuristic and supervised-learning baselines, achieving a superior Pareto frontier and delivering up to a 15\% inference speedup at equal accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GRIP-VLM, a reinforcement-learning framework for pruning visual tokens in Vision-Language Models. It formulates token selection as a Markov Decision Process solved via Group Relative Policy Optimization (GRPO) with supervised warm-up and a budget-aware scorer, claiming this discrete approach avoids sub-optimal minima of continuous relaxations. The method is presented as adaptive to arbitrary compression ratios without retraining and is reported to outperform heuristic and supervised baselines on multimodal benchmarks, achieving a superior accuracy-speed Pareto frontier with up to 15% inference speedup at matched accuracy.
Significance. If the empirical claims hold under rigorous validation, the work would be significant for efficient VLM inference by directly optimizing the inherently discrete pruning problem rather than relying on gradient relaxations. The budget-adaptive, retraining-free property and the use of group-relative policy optimization to stabilize combinatorial search represent potentially useful technical contributions. However, the current manuscript provides no quantitative tables, ablation studies, training curves, or multi-seed statistics, which substantially weakens the assessed impact.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim that GRIP-VLM 'consistently outperforms' baselines and delivers a 'superior Pareto frontier' with 'up to 15% inference speedup' is unsupported by any reported tables, numerical results, ablation studies, or statistical significance tests. Without these data the superiority assertion cannot be evaluated and is load-bearing for the paper's contribution.
- [§3 and §4] §3 (Method) and §4: The GRPO formulation treats pruning as an MDP over a combinatorial action space (2^N token subsets). No training curves, multi-seed averages, variance estimates, or hyperparameter sensitivity analysis are provided, despite the known high-variance policy gradients in such spaces. This omission directly undermines the claim that the agent 'reliably discovers high-quality discrete masks' across budgets.
minor comments (2)
- [Abstract] The abstract introduces GRPO without spelling out 'Group Relative Policy Optimization' on first use; this should be expanded for clarity.
- [§3] Notation for the budget-aware scorer and the MDP state/action definitions should be introduced with explicit equations rather than prose descriptions to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the empirical validation of our claims. We address each major comment below and will revise the manuscript accordingly to include the requested quantitative support.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim that GRIP-VLM 'consistently outperforms' baselines and delivers a 'superior Pareto frontier' with 'up to 15% inference speedup' is unsupported by any reported tables, numerical results, ablation studies, or statistical significance tests. Without these data the superiority assertion cannot be evaluated and is load-bearing for the paper's contribution.
Authors: We agree that the current manuscript version does not present the supporting tables, numerical results, ablation studies, or statistical tests in the abstract and §4. In the revised manuscript we will add detailed tables reporting accuracy, latency, and speedup metrics across multiple multimodal benchmarks, Pareto frontier plots, ablation studies on the budget-aware scorer and GRPO components, and multi-seed statistical significance tests (means, standard deviations, and p-values). These additions will directly substantiate the performance claims. revision: yes
-
Referee: [§3 and §4] §3 (Method) and §4: The GRPO formulation treats pruning as an MDP over a combinatorial action space (2^N token subsets). No training curves, multi-seed averages, variance estimates, or hyperparameter sensitivity analysis are provided, despite the known high-variance policy gradients in such spaces. This omission directly undermines the claim that the agent 'reliably discovers high-quality discrete masks' across budgets.
Authors: We acknowledge that the stability of GRPO in the combinatorial action space requires explicit demonstration. The revised manuscript will incorporate training curves for policy reward over episodes, averages and variance estimates across multiple independent seeds (e.g., 5 runs), and hyperparameter sensitivity analysis for group size, learning rate, and budget constraints. These elements will support the reliability of the discovered discrete masks. revision: yes
Circularity Check
No circularity: GRPO-based discrete pruning is an independent optimization procedure
full rationale
The paper formulates token pruning as an MDP solved by Group Relative Policy Optimization (GRPO) with supervised warm-up and a budget-aware scorer. No equations, fitted parameters, or self-citations are shown that would make the reported Pareto gains or 15% speedup equivalent to the inputs by construction. The central claim rests on experimental comparison against baselines rather than any definitional or self-referential reduction. This is the normal case of an empirical RL method whose validity is tested externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[2]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: En- hancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024
2024
-
[4]
Visual instruction tuning.Advances in neural information processing systems, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 2024
2024
-
[5]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Shaobo Wang, Xiangqi Jin, Ziming Wang, Jize Wang, Jiajun Zhang, Kaixin Li, Zichen Wen, Zhong Li, Conghui He, Xuming Hu, et al. Data whisperer: Efficient data selection for task- specific llm fine-tuning via few-shot in-context learning.arXiv preprint arXiv:2505.12212, 2025
-
[10]
Internvideo2: Scaling video foundation models for multimodal video understanding.Arxiv e-prints, pages arXiv–2403, 2024
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Jilan Xu, Zun Wang, et al. Internvideo2: Scaling video foundation models for multimodal video understanding.Arxiv e-prints, pages arXiv–2403, 2024
2024
-
[11]
Yiqi Wang, Wentao Chen, Xiaotian Han, Xudong Lin, Haiteng Zhao, Yongfei Liu, Bohan Zhai, Jianbo Yuan, Quanzeng You, and Hongxia Yang. Exploring the reasoning abilities of multimodal large language models (mllms): A comprehensive survey on emerging trends in multimodal reasoning.arXiv preprint arXiv:2401.06805, 2024
-
[12]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[13]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
2025
-
[14]
Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-gemini: Mining the potential of multi-modality vision language models.arXiv:2403.18814, 2024. 10
-
[15]
Video understanding with large language models: A survey.arXiv preprint arXiv:2312.17432, 2023
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, et al. Video understanding with large language models: A survey.arXiv preprint arXiv:2312.17432, 2023
-
[16]
arXiv preprint arXiv:2403.15388 , year=
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models.arXiv preprint arXiv:2403.15388, 2024
-
[17]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
2024
-
[18]
Sparsevlm: Visual token sparsification for efficient vision-language model inference, 2025
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, and Shanghang Zhang. Sparsevlm: Visual token sparsification for efficient vision-language model inference, 2025
2025
-
[19]
Token merging: Your vit but faster, 2023
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster, 2023
2023
-
[20]
Framefusion: Combining similarity and importance for video token reduction on large vision language models, 2025
Tianyu Fu, Tengxuan Liu, Qinghao Han, Guohao Dai, Shengen Yan, Huazhong Yang, Xuefei Ning, and Yu Wang. Framefusion: Combining similarity and importance for video token reduction on large vision language models, 2025
2025
-
[21]
Dynamicvit: Efficient vision transformers with dynamic token sparsification, 2021
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification, 2021
2021
-
[22]
Smarttrim: Adaptive tokens and attention pruning for efficient vision-language models, 2024
Zekun Wang, Jingchang Chen, Wangchunshu Zhou, Haichao Zhu, Jiafeng Liang, Liping Shan, Ming Liu, Dongliang Xu, Qing Yang, and Bing Qin. Smarttrim: Adaptive tokens and attention pruning for efficient vision-language models, 2024
2024
-
[23]
Visionselector: End-to-end learnable visual token compression for efficient multimodal llms, 2025
Jiaying Zhu, Yurui Zhu, Xin Lu, Wenrui Yan, Dong Li, Kunlin Liu, Xueyang Fu, and Zheng-Jun Zha. Visionselector: End-to-end learnable visual token compression for efficient multimodal llms, 2025
2025
-
[24]
Efficient multi-modal large language models via progressive consistency distillation, 2025
Zichen Wen, Shaobo Wang, Yufa Zhou, Junyuan Zhang, Qintong Zhang, Yifeng Gao, Zhaorun Chen, Bin Wang, Weijia Li, Conghui He, and Linfeng Zhang. Efficient multi-modal large language models via progressive consistency distillation, 2025
2025
-
[25]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021
2021
-
[26]
Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023
2023
-
[27]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
2024
-
[28]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 11
2017
-
[32]
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zenghui Ding, Xianjun Yang, and Yining Sun. Beyond training: Dynamic token merging for zero-shot video understanding.arXiv preprint arXiv:2411.14401, 2024
-
[33]
Film: Visual reasoning with a general conditioning layer, 2017
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer, 2017
2017
-
[34]
Sft or rl? an early investigation into training r1-like reasoning large vision-language models, 2025
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models, 2025
2025
-
[35]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models.arXiv preprint arXiv:2305.10355, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35:2507–2521, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35:2507–2521, 2022
2022
-
[38]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019
2019
-
[39]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InEuropean conference on computer vision, pages 235–251. Springer, 2016
2016
-
[40]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InCVPR, 2019
2019
-
[41]
MMBench: Is Your Multi-modal Model an All-around Player?
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player?arXiv preprint arXiv:2307.06281, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024. 12 A Full Motivation Results Figure 8:Per-Sample Performance Cliff.Each curve shows the true class proba...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.