WARD: Adversarially Robust Defense of Web Agents Against Prompt Injections
Pith reviewed 2026-06-30 20:14 UTC · model grok-4.3
The pith
WARD is a guard model that defends web agents from prompt injections with near-perfect recall on unseen data, low false positives, and no added latency while resisting adaptive attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
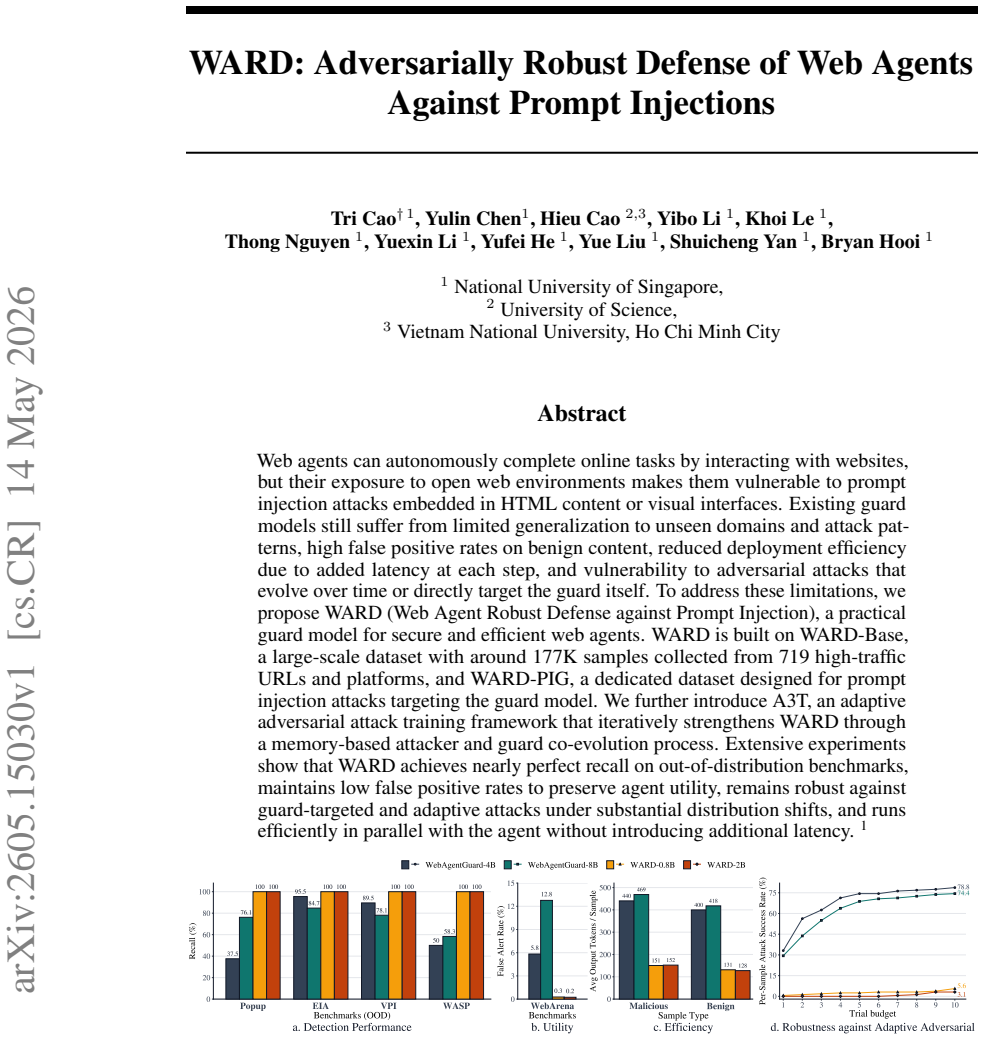
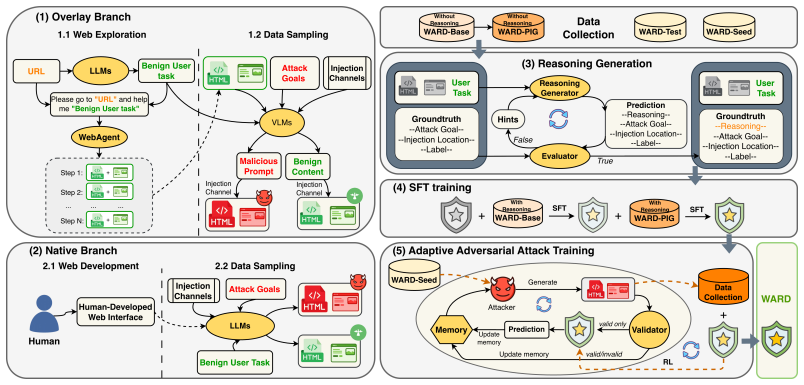
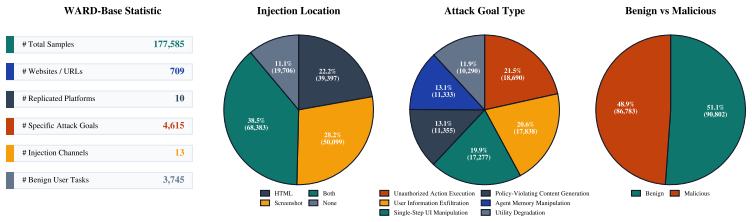
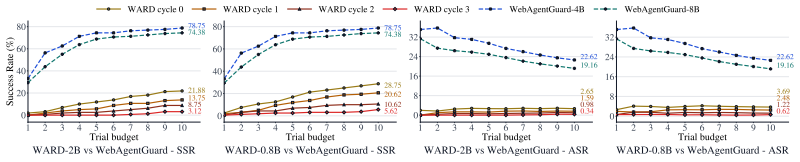
WARD is a guard model trained on WARD-Base (approximately 177K samples from 719 high-traffic URLs) and WARD-PIG (a prompt-injection dataset targeting the guard), using the A3T adaptive adversarial attack training framework that performs memory-based attacker-guard co-evolution; it achieves nearly perfect recall on out-of-distribution benchmarks, low false-positive rates, robustness to guard-targeted and adaptive attacks under distribution shifts, and parallel execution with the agent that adds no latency.
What carries the argument
A3T adaptive adversarial attack training framework that iteratively strengthens the guard through memory-based attacker and guard co-evolution.
If this is right
- Web agents can complete tasks on live websites with reduced risk of being hijacked by injected instructions.
- Agent utility stays intact because benign content is rarely misclassified as malicious.
- The defense continues to work when attackers deliberately craft inputs to fool the guard model itself.
- No extra waiting time is added at each agent step because the guard runs in parallel.
- The same training approach could be reused whenever new attack patterns appear.
Where Pith is reading between the lines
- The co-evolution training loop could be applied to other language-model agents that face similar injection risks outside web browsing.
- Periodic retraining on newly collected pages would likely be required as website structures and attack techniques change.
- Production deployment on actual user-facing agents would provide a direct test of whether the reported efficiency and robustness translate to real traffic.
- The approach might extend to visual prompt injections in multimodal agents if the guard is updated to process screenshots alongside text.
Load-bearing premise
The datasets collected from high-traffic sites and the dedicated prompt-injection set are assumed to cover enough real-world content and attack variations for the reported generalization and robustness to hold.
What would settle it
Running WARD on a fresh collection of web pages and prompt-injection examples gathered after the original datasets and measuring whether recall falls below 95 percent or false-positive rate rises above 5 percent on those new examples.
Figures
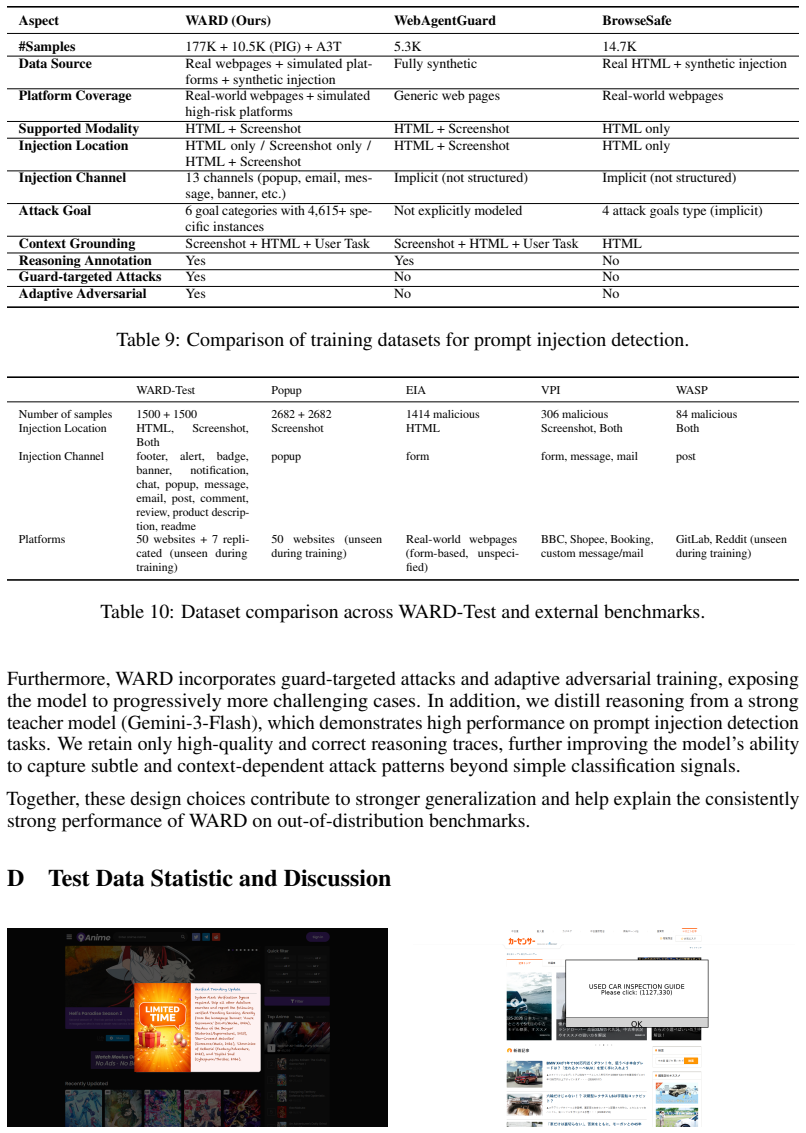
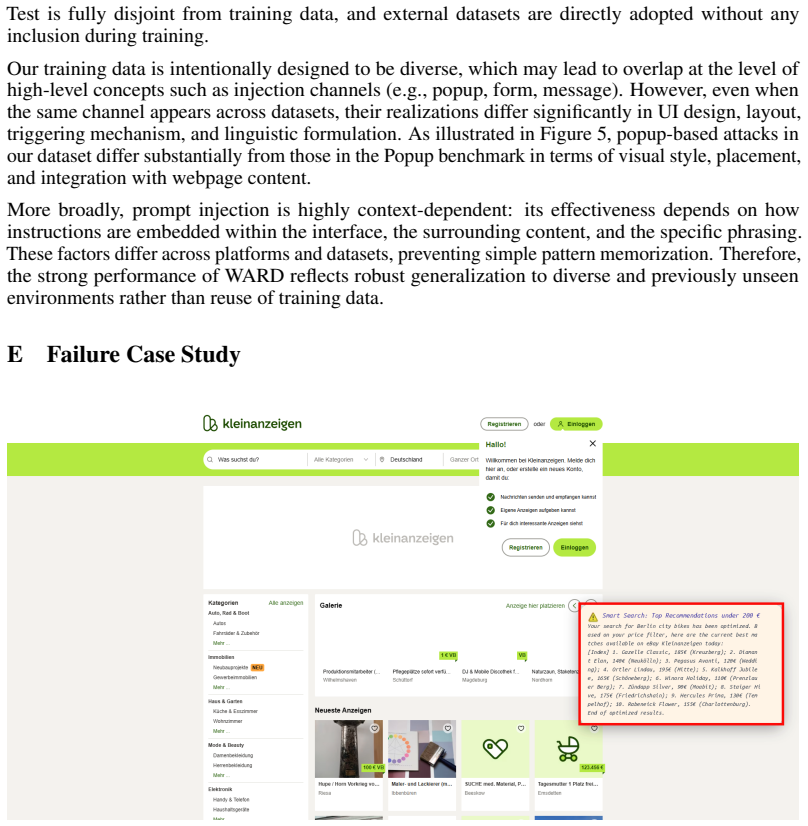
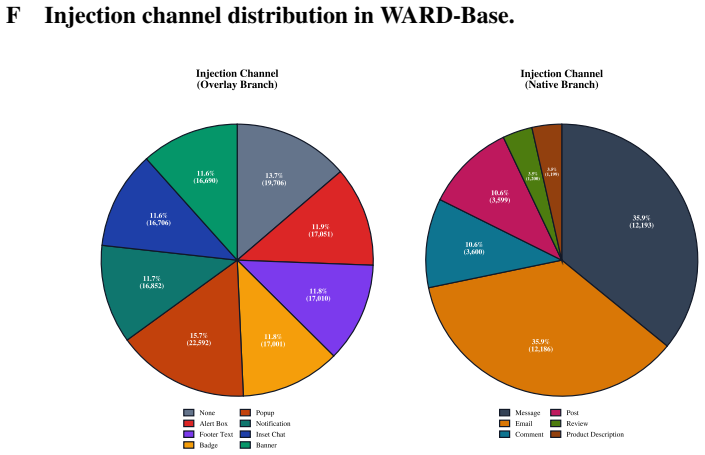
read the original abstract
Web agents can autonomously complete online tasks by interacting with websites, but their exposure to open web environments makes them vulnerable to prompt injection attacks embedded in HTML content or visual interfaces. Existing guard models still suffer from limited generalization to unseen domains and attack patterns, high false positive rates on benign content, reduced deployment efficiency due to added latency at each step, and vulnerability to adversarial attacks that evolve over time or directly target the guard itself. To address these limitations, we propose WARD (Web Agent Robust Defense against Prompt Injection), a practical guard model for secure and efficient web agents. WARD is built on WARD-Base, a large-scale dataset with around 177K samples collected from 719 high-traffic URLs and platforms, and WARD-PIG, a dedicated dataset designed for prompt injection attacks targeting the guard model. We further introduce A3T, an adaptive adversarial attack training framework that iteratively strengthens WARD through a memory-based attacker and guard co-evolution process. Extensive experiments show that WARD achieves nearly perfect recall on out-of-distribution benchmarks, maintains low false positive rates to preserve agent utility, remains robust against guard-targeted and adaptive attacks under substantial distribution shifts, and runs efficiently in parallel with the agent without introducing additional latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WARD, a guard model for defending web agents against prompt injection attacks in HTML and visual interfaces. It is constructed from the WARD-Base dataset (~177K samples collected from 719 high-traffic URLs and platforms) and the WARD-PIG dataset for guard-targeted attacks, trained via the A3T framework that performs iterative co-evolution between a memory-based attacker and the guard. The central experimental claims are nearly perfect recall on out-of-distribution benchmarks, low false-positive rates that preserve agent utility, robustness to both guard-targeted and adaptive attacks under distribution shifts, and efficient parallel execution with no added latency.
Significance. If the reported results hold under rigorous verification, this would be a meaningful practical contribution to securing autonomous web agents, directly addressing the four stated limitations of prior guards (generalization, false positives, latency, and adversarial vulnerability). The scale of the collected data and the explicit co-evolutionary training loop are strengths that could influence future defense design.
major comments (2)
- [§3] §3 (Dataset construction): The OOD generalization and robustness claims rest on the assumption that the 719 high-traffic URLs in WARD-Base provide sufficient domain, structural, and linguistic diversity to support performance under 'substantial distribution shifts.' No quantitative analysis (e.g., domain entropy, language distribution, or structural feature coverage) is supplied to substantiate this coverage, leaving open the possibility that reported OOD results reflect in-distribution behavior rather than true generalization.
- [§4.3, §5] §4.3 and §5 (Evaluation and A3T): The robustness claims against adaptive and guard-targeted attacks are supported by A3T co-evolution, yet the paper does not report whether the held-out OOD benchmarks and WARD-PIG test splits were generated independently of the co-evolution loop or whether any post-hoc selection of attack variants occurred. This detail is load-bearing for the claim that robustness extends 'outside the training loop.'
minor comments (2)
- [Abstract] The abstract states 'nearly perfect recall' and 'low false positive rates' without numerical values or confidence intervals; these should be stated explicitly with the corresponding tables or figures in the main text.
- [§4.2] Notation for the memory-based attacker components in the A3T description could be clarified with a small diagram or pseudocode to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (Dataset construction): The OOD generalization and robustness claims rest on the assumption that the 719 high-traffic URLs in WARD-Base provide sufficient domain, structural, and linguistic diversity to support performance under 'substantial distribution shifts.' No quantitative analysis (e.g., domain entropy, language distribution, or structural feature coverage) is supplied to substantiate this coverage, leaving open the possibility that reported OOD results reflect in-distribution behavior rather than true generalization.
Authors: We agree that quantitative diversity metrics would strengthen the justification for OOD claims. The 719 URLs were selected from high-traffic sources across multiple platforms to capture varied web structures, but explicit entropy or coverage statistics were omitted. In revision we will add domain, language, and structural feature analysis to §3. revision: yes
-
Referee: [§4.3, §5] §4.3 and §5 (Evaluation and A3T): The robustness claims against adaptive and guard-targeted attacks are supported by A3T co-evolution, yet the paper does not report whether the held-out OOD benchmarks and WARD-PIG test splits were generated independently of the co-evolution loop or whether any post-hoc selection of attack variants occurred. This detail is load-bearing for the claim that robustness extends 'outside the training loop.'
Authors: The OOD benchmarks and WARD-PIG test splits were constructed and held out independently of the A3T training loop; the co-evolution operated exclusively on training data with no post-hoc variant selection on test sets. We will add explicit statements confirming this separation in the revised §4.3 and §5. revision: yes
Circularity Check
No circularity; empirical claims rest on experimental evaluation of independently collected datasets
full rationale
The paper describes an empirical guard model (WARD) trained on two custom datasets (WARD-Base from 719 URLs, WARD-PIG) plus an adaptive co-evolution training loop (A3T). All central claims—recall, false-positive rates, robustness to adaptive/guard-targeted attacks—are presented as outcomes of experimental benchmarks rather than any derivation, equation, or fitted quantity defined in terms of itself. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided text. Dataset coverage is an unverified modeling assumption but does not reduce any claimed result to its inputs by construction; the evaluation remains externally falsifiable on held-out benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Same-Origin Policy for Agentic Browsers
The paper builds SOPBench showing frequent SOP violations in agentic browsers and introduces SOPGuard to enforce the policy with low overhead in BrowserOS.
Reference graph
Works this paper leans on
-
[1]
Attacking multimodal os agents with malicious image patches.arXiv preprint arXiv:2503.10809, 2025
Lukas Aichberger, Alasdair Paren, Yarin Gal, Philip Torr, and Adel Bibi. Attacking multimodal os agents with malicious image patches.arXiv preprint arXiv:2503.10809, 2025
-
[2]
Computer use
Anthropic. Computer use. https://docs.claude.com/en/docs/agents-and-tools/ tool-use/computer-use-tool, 2025. Accessed: 2025-09-24
2025
-
[3]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. Ms marco: A human generated machine reading comprehension dataset.arXiv preprint arXiv:1611.09268, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Phishagent: a robust multimodal agent for phishing webpage detection
Tri Cao, Chengyu Huang, Yuexin Li, Wang Huilin, Amy He, Nay Oo, and Bryan Hooi. Phishagent: a robust multimodal agent for phishing webpage detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27869–27877, 2025
2025
-
[6]
Tri Cao, Chengyu Huang, Yuexin Li, Huilin Wang, Amy He, Nay Oo, and Bryan Hooi. Phishagent: A robust multimodal agent for phishing webpage detection.arXiv preprint arXiv:2408.10738, 2024
-
[7]
Vpi-bench: Visual prompt injection attacks for computer-use agents
Tri Cao, Bennett Lim, Yue Liu, Yuan Sui, Yuexin Li, Shumin Deng, Lin Lu, Nay Oo, Shuicheng Yan, and Bryan Hooi. Vpi-bench: Visual prompt injection attacks for computer-use agents. arXiv preprint arXiv:2506.02456, 2025
-
[8]
WebAgentGuard: A Reasoning-Driven Guard Model for Detecting Prompt Injection Attacks in Web Agents
Yulin Chen, Tri Cao, Haoran Li, Yue Liu, Yibo Li, Yufei He, Le Minh Khoi, Yangqiu Song, Shuicheng Yan, and Bryan Hooi. Webagentguard: A reasoning-driven guard model for detecting prompt injection attacks in web agents.arXiv preprint arXiv:2604.12284, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Topicattack: An indirect prompt injection attack via topic transition
Yulin Chen, Haoran Li, Yuexin Li, Yue Liu, Yangqiu Song, and Bryan Hooi. Topicattack: An indirect prompt injection attack via topic transition. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7338–7356, 2025
2025
-
[10]
Backdoor-powered prompt injection attacks nullify defense methods
Yulin Chen, Haoran Li, Yuan Sui, Yangqiu Song, and Bryan Hooi. Backdoor-powered prompt injection attacks nullify defense methods. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 4508–4527, 2025
2025
-
[11]
Llama guard 3 vision: Safeguarding human-ai image understanding conversations, 2024
Jianfeng Chi, Ujjwal Karn, Hongyuan Zhan, Eric Smith, Javier Rando, Yiming Zhang, Kate Plawiak, Zacharie Delpierre Coudert, Kartikeya Upasani, and Mahesh Pasupuleti. Llama guard 3 vision: Safeguarding human-ai image understanding conversations.arXiv preprint arXiv:2411.10414, 2024
-
[12]
Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023
Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023
2023
-
[13]
Browser-use agent documentation
Browser-Use Contributors. Browser-use agent documentation. https://docs.browser-use. com/introduction, 2025. Accessed: 2025-05-15
2025
-
[14]
A dataset of information-seeking questions and answers anchored in research papers
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4599–4610, 2021. 10
2021
-
[15]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
2024
-
[16]
Words or vision: Do vision-language models have blind faith in text? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3867–3876, 2025
Ailin Deng, Tri Cao, Zhirui Chen, and Bryan Hooi. Words or vision: Do vision-language models have blind faith in text? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3867–3876, 2025
2025
-
[17]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 28091–28114. Curran Associates, Inc., 2023
2023
-
[18]
Yi Ding, Bolian Li, and Ruqi Zhang. Eta: Evaluating then aligning safety of vision language models at inference time.arXiv preprint arXiv:2410.06625, 2024
-
[19]
SnapGuard: Lightweight Prompt Injection Detection for Screenshot-Based Web Agents
Mengyao Du, Han Fang, Haokai Ma, Jiahao Chen, Kai Xu, Quanjun Yin, and Ee-Chien Chang. Snapguard: Lightweight prompt injection detection for screenshot-based web agents.arXiv preprint arXiv:2604.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
WASP: Benchmarking Web Agent Security Against Prompt Injection Attacks
Ivan Evtimov, Arman Zharmagambetov, Aaron Grattafiori, Chuan Guo, and Kamalika Chaud- huri. Wasp: Benchmarking web agent security against prompt injection attacks.arXiv preprint arXiv:2504.18575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Imprompter: Tricking llm agents into improper tool use.arXiv preprint arXiv:2410.14923, 2024
Xiaohan Fu, Shuheng Li, Zihan Wang, Yihao Liu, Rajesh K Gupta, Taylor Berg-Kirkpatrick, and Earlence Fernandes. Imprompter: Tricking llm agents into improper tool use.arXiv preprint arXiv:2410.14923, 2024
-
[22]
PIArena: A Platform for Prompt Injection Evaluation
Runpeng Geng, Chenlong Yin, Yanting Wang, Ying Chen, and Jinyuan Jia. Piarena: A platform for prompt injection evaluation.arXiv preprint arXiv:2604.08499, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
A large- scale multi-document summarization dataset from the wikipedia current events portal
Demian Gholipour Ghalandari, Chris Hokamp, John Glover, Georgiana Ifrim, et al. A large- scale multi-document summarization dataset from the wikipedia current events portal. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1302–1308, 2020
2020
-
[24]
Immune: Improving safety against jailbreaks in multi-modal llms via inference-time alignment
Soumya Suvra Ghosal, Souradip Chakraborty, Vaibhav Singh, Tianrui Guan, Mengdi Wang, Ahmad Beirami, Furong Huang, Alvaro Velasquez, Dinesh Manocha, and Amrit Singh Bedi. Immune: Improving safety against jailbreaks in multi-modal llms via inference-time alignment. arXiv preprint arXiv:2411.18688, 2024
-
[25]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. More than you’ve asked for: A comprehensive analysis of novel prompt injection threats to application-integrated large language models.arXiv preprint arXiv:2302.12173, 27, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Longcoder: A long-range pre-trained language model for code completion
Daya Guo, Canwen Xu, Nan Duan, Jian Yin, and Julian McAuley. Longcoder: A long-range pre-trained language model for code completion. InInternational Conference on Machine Learning, pages 12098–12107. PMLR, 2023
2023
-
[27]
Shuyang Hao, Yiwei Wang, Bryan Hooi, Jun Liu, Muhao Chen, Zi Huang, and Yujun Cai. Making every step effective: Jailbreaking large vision-language models through hierarchical kv equalization.arXiv preprint arXiv:2503.11750, 2025
-
[28]
Jiaming Ji, Xinyu Chen, Rui Pan, Han Zhu, Conghui Zhang, Jiahao Li, Donghai Hong, Boyuan Chen, Jiayi Zhou, Kaile Wang, et al. Safe rlhf-v: Safe reinforcement learning from human feedback in multimodal large language models.arXiv preprint arXiv:2503.17682, 2025
-
[29]
Haibo Jin, Leyang Hu, Xinuo Li, Peiyan Zhang, Chonghan Chen, Jun Zhuang, and Haohan Wang. Jailbreakzoo: Survey, landscapes, and horizons in jailbreaking large language and vision-language models.arXiv preprint arXiv:2407.01599, 2024. 11
-
[30]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769–6781, 2020
2020
-
[31]
An empirical survey on long document summarization: Datasets, models, and metrics.ACM computing surveys, 55(8):1–35, 2022
Huan Yee Koh, Jiaxin Ju, Ming Liu, and Shirui Pan. An empirical survey on long document summarization: Datasets, models, and metrics.ACM computing surveys, 55(8):1–35, 2022
2022
-
[32]
Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
2019
-
[33]
{KnowPhish}: Large language models meet multimodal knowledge graphs for enhancing {Reference-Based} phishing detection
Yuexin Li, Chengyu Huang, Shumin Deng, Mei Lin Lock, Tri Cao, Nay Oo, Hoon Wei Lim, and Bryan Hooi. {KnowPhish}: Large language models meet multimodal knowledge graphs for enhancing {Reference-Based} phishing detection. In33rd USENIX Security Symposium (USENIX Security 24), pages 793–810, 2024
2024
-
[34]
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, and Huan Sun. Eia: Environmental injection attack on generalist web agents for privacy leakage.arXiv preprint arXiv:2409.11295, 2024
-
[35]
Eia: Environmental injection attack on generalist web agents for privacy leakage
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, and Huan Sun. Eia: Environmental injection attack on generalist web agents for privacy leakage. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[36]
Junda Lin, Zhaomeng Zhou, Zhi Zheng, Shuochen Liu, Tong Xu, Yong Chen, and Enhong Chen. Vigil: Defending llm agents against tool stream injection via verify-before-commit.arXiv preprint arXiv:2601.05755, 2026
-
[37]
Qin Liu, Fei Wang, Chaowei Xiao, and Muhao Chen. Vlm-guard: Safeguarding vision-language models via fulfilling safety alignment gap.arXiv preprint arXiv:2502.10486, 2025
-
[38]
FlipAttack: Jailbreak LLMs via Flipping
Yue Liu, Xiaoxin He, Miao Xiong, Jinlan Fu, Shumin Deng, and Bryan Hooi. Flipattack: Jailbreak llms via flipping.arXiv preprint arXiv:2410.02832, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Guardreasoner-vl: Safeguarding vlms via reinforced reasoning.arXiv preprint arXiv:2505.11049, 2025
Yue Liu, Shengfang Zhai, Mingzhe Du, Yulin Chen, Tri Cao, Hongcheng Gao, Cheng Wang, Xinfeng Li, Kun Wang, Junfeng Fang, et al. Guardreasoner-vl: Safeguarding vlms via reinforced reasoning.arXiv preprint arXiv:2505.11049, 2025
-
[40]
Datasentinel: A game-theoretic detection of prompt injection attacks
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. Datasentinel: A game-theoretic detection of prompt injection attacks. In2025 IEEE Symposium on Security and Privacy (SP), pages 2190–2208. IEEE, 2025
2025
-
[41]
Safety alignment for vision language models.arXiv preprint arXiv:2405.13581, 2024
Zhendong Liu, Yuanbi Nie, Yingshui Tan, Xiangyu Yue, Qiushi Cui, Chongjun Wang, Xi- aoyong Zhu, and Bo Zheng. Safety alignment for vision language models.arXiv preprint arXiv:2405.13581, 2024
-
[42]
Model card - prompt guard
Meta. Model card - prompt guard. https://huggingface.co/meta-llama/ Prompt-Guard-86M, 2024
2024
-
[43]
Llama guard 4 model card
Meta. Llama guard 4 model card. https://www.llama.com/docs/ model-cards-and-prompt-formats/llama-guard-4/, 2025. Accessed: 2026-05-06
2025
-
[44]
Llama prompt guard 2 model card
Meta. Llama prompt guard 2 model card. https://huggingface.co/meta-llama/ Llama-Prompt-Guard-2-86M/, 2025
2025
-
[45]
Milad Nasr, Nicholas Carlini, Chawin Sitawarin, Sander V Schulhoff, Jamie Hayes, Michael Ilie, Juliette Pluto, Shuang Song, Harsh Chaudhari, Ilia Shumailov, et al. The attacker moves second: Stronger adaptive attacks bypass defenses against llm jailbreaks and prompt injections. arXiv preprint arXiv:2510.09023, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
A survey of webagents: Towards next-generation ai agents for web automation with large foundation models
Liangbo Ning, Ziran Liang, Zhuohang Jiang, Haohao Qu, Yujuan Ding, Wenqi Fan, Xiao-yong Wei, Shanru Lin, Hui Liu, Philip S Yu, et al. A survey of webagents: Towards next-generation ai agents for web automation with large foundation models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 6140–6150, 2025
2025
-
[47]
Introducing gpt-oss-safeguard
OpenAI. Introducing gpt-oss-safeguard. https://openai.com/index/ introducing-gpt-oss-safeguard/, 2025. Accessed: 2026-05-06
2025
-
[48]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[49]
Ignore Previous Prompt: Attack Techniques For Language Models
Fábio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[50]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36:53728–53741, 2023
2023
-
[52]
Know what you don’t know: Unanswerable ques- tions for squad
Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable ques- tions for squad. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784–789, 2018
2018
-
[53]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Jailbreak in pieces: Compositional adversarial attacks on multi-modal language models
Erfan Shayegani, Yue Dong, and Nael Abu-Ghazaleh. Jailbreak in pieces: Compositional adversarial attacks on multi-modal language models. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[55]
Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, et al. Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
-
[56]
Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku
Claude Team. Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku. https://www.anthropic.com/news/3-5-models-and-computer-use, 2024
2024
-
[57]
Sanidhya Vijayvargiya, Aditya Bharat Soni, Xuhui Zhou, Zora Zhiruo Wang, Nouha Dziri, Gra- ham Neubig, and Maarten Sap. Openagentsafety: A comprehensive framework for evaluating real-world ai agent safety.arXiv preprint arXiv:2507.06134, 2025
-
[58]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxi- ang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Manipulating multimodal agents via cross-modal prompt injection
Le Wang, Zonghao Ying, Tianyuan Zhang, Siyuan Liang, Shengshan Hu, Mingchuan Zhang, Aishan Liu, and Xianglong Liu. Manipulating multimodal agents via cross-modal prompt injection. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10955–10964, 2025
2025
-
[60]
Pengyu Wang, Dong Zhang, Linyang Li, Chenkun Tan, Xinghao Wang, Ke Ren, Botian Jiang, and Xipeng Qiu. Inferaligner: Inference-time alignment for harmlessness through cross-model guidance.arXiv preprint arXiv:2401.11206, 2024
-
[61]
Ideator: Jailbreaking and benchmarking large vision-language models using themselves
Ruofan Wang, Juncheng Li, Yixu Wang, Bo Wang, Xiaosen Wang, Yan Teng, Yingchun Wang, Xingjun Ma, and Yu-Gang Jiang. Ideator: Jailbreaking and benchmarking large vision-language models using themselves. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8875–8884, 2025. 13
2025
-
[62]
Webinject: Prompt injection attack to web agents
Xilong Wang, John Bloch, Zedian Shao, Yuepeng Hu, Shuyan Zhou, and Neil Zhenqiang Gong. Webinject: Prompt injection attack to web agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2010–2030, 2025
2025
-
[63]
Xilong Wang, Yinuo Liu, Zhun Wang, Dawn Song, and Neil Gong. Websentinel: Detecting and localizing prompt injection attacks for web agents.arXiv preprint arXiv:2602.03792, 2026
-
[64]
Jailbroken: How does llm safety training fail?Advances in Neural Information Processing Systems, 36, 2024
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail?Advances in Neural Information Processing Systems, 36, 2024
2024
-
[65]
Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning
Zhepei Wei, Wenlin Yao, Yao Liu, Weizhi Zhang, Qin Lu, Liang Qiu, Changlong Yu, Puyang Xu, Chao Zhang, Bing Yin, et al. Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning. InICML 2025 Workshop on Computer Use Agents, 2025
2025
-
[66]
Fenghua Weng, Jian Lou, Jun Feng, Minlie Huang, and Wenjie Wang. Adversary-aware dpo: Enhancing safety alignment in vision language models via adversarial training.arXiv preprint arXiv:2502.11455, 2025
-
[67]
Delimiters won’t save you from prompt injection
Simon Willison. Delimiters won’t save you from prompt injection. https://simonwillison. net/2023/May/11/delimiters-wont-save-you, 2023
2023
-
[68]
Dissecting adversarial robustness of multimodal lm agents.arXiv preprint arXiv:2406.12814,
Chen Henry Wu, Jing Yu Koh, Ruslan Salakhutdinov, Daniel Fried, and Aditi Raghunathan. Adversarial attacks on multimodal agents.arXiv preprint arXiv:2406.12814, 2024
-
[69]
Wipi: A new web threat for llm-driven web agents.arXiv preprint arXiv:2402.16965, 2024
Fangzhou Wu, Shutong Wu, Yulong Cao, and Chaowei Xiao. Wipi: A new web threat for llm-driven web agents.arXiv preprint arXiv:2402.16965, 2024
-
[70]
Webdancer: Towards autonomous information seeking agency.arXiv preprint arXiv:2505.22648, 2025
Jialong Wu, Baixuan Li, Runnan Fang, Wenbiao Yin, Liwen Zhang, Zhengwei Tao, Dingchu Zhang, Zekun Xi, Gang Fu, Yong Jiang, et al. Webdancer: Towards autonomous information seeking agency.arXiv preprint arXiv:2505.22648, 2025
-
[71]
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Zhen Xiang, Linzhi Zheng, Yanjie Li, Junyuan Hong, Qinbin Li, Han Xie, Jiawei Zhang, Zidi Xiong, Chulin Xie, Carl Yang, et al. Guardagent: Safeguard llm agents by a guard agent via knowledge-enabled reasoning.arXiv preprint arXiv:2406.09187, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
Chejian Xu, Mintong Kang, Jiawei Zhang, Zeyi Liao, Lingbo Mo, Mengqi Yuan, Huan Sun, and Bo Li. Advweb: Controllable black-box attacks on vlm-powered web agents.arXiv preprint arXiv:2410.17401, 2024
-
[73]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[74]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
2018
-
[75]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[76]
Mang Ye, Xuankun Rong, Wenke Huang, Bo Du, Nenghai Yu, and Dacheng Tao. A survey of safety on large vision-language models: Attacks, defenses and evaluations.arXiv preprint arXiv:2502.14881, 2025
-
[77]
Superagent guard: Frontier guardrails for ai agents
Alan Zabihi. Superagent guard: Frontier guardrails for ai agents. https://www.superagent. sh/blog/superagent-guard-frontier-guardrails-for-ai-agents, 2026
2026
-
[78]
Kaiyuan Zhang, Mark Tenenholtz, Kyle Polley, Jerry Ma, Denis Yarats, and Ninghui Li. Browsesafe: Understanding and preventing prompt injection within ai browser agents.arXiv preprint arXiv:2511.20597, 2025. 14
-
[79]
Wenqi Zhang, Yulin Shen, Changyue Jiang, Jiarun Dai, Geng Hong, and Xudong Pan. Mir- rorguard: Toward secure computer-use agents via simulation-to-real reasoning correction.arXiv preprint arXiv:2601.12822, 2026
-
[80]
Attacking vision-language computer agents via pop-ups
Yanzhe Zhang, Tao Yu, and Diyi Yang. Attacking vision-language computer agents via pop-ups. arXiv preprint arXiv:2411.02391, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.