PluRule: A Benchmark for Moderating Pluralistic Communities on Social Media
Pith reviewed 2026-05-20 13:59 UTC · model grok-4.3
The pith
State-of-the-art vision-language models barely outperform a trivial baseline when identifying rule violations in pluralistic communities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
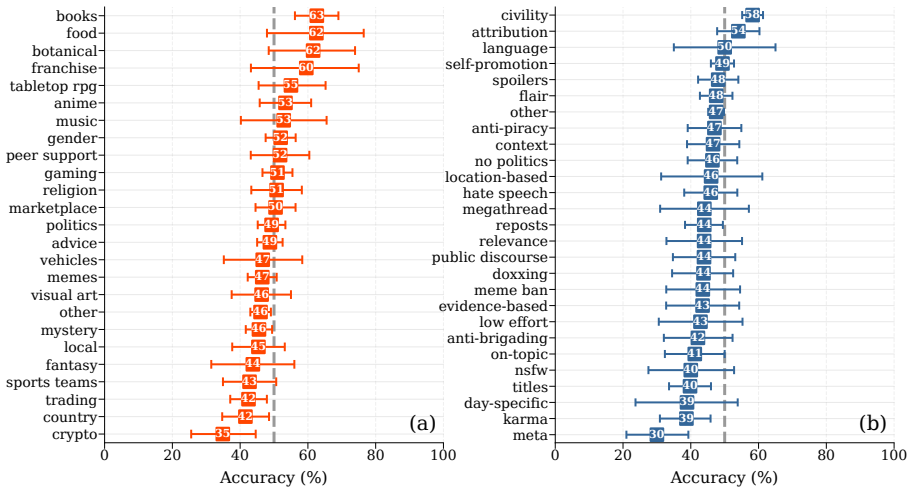
We introduce PluRule, a multimodal, multilingual benchmark for detecting 13,371 rule violations across 1,989 Reddit communities spanning 2,885 rules in 9 languages. Using this benchmark, we show that state-of-the-art vision-language models struggle significantly: even GPT-5.2 with high reasoning performs only slightly better than a trivial baseline.
What carries the argument
The PluRule benchmark, which formalizes moderation as a multiple-choice problem of selecting the specific violated rule given a comment and its context.
If this is right
- Bigger models and increased context provide only marginal gains in detection accuracy.
- Universal rules such as civility and self-promotion are detected more reliably than community-specific rules.
- Moderation of pluralistic communities remains a fundamental challenge for current language models.
Where Pith is reading between the lines
- The benchmark could be used to train models that learn community norms from examples instead of relying on explicit rule lists.
- Success on this task might enable moderation tools better suited to decentralized or community-governed platforms.
- The performance gap suggests exploring hybrid systems where AI assists rather than replaces human moderators in diverse groups.
Load-bearing premise
The multiple-choice formulation with provided context and rules accurately mirrors how human moderators operate when deciding violations in real pluralistic communities.
What would settle it
A direct comparison measuring how often the benchmark's multiple-choice answers match the actual violation decisions made by human moderators reviewing the same comments in their communities.
Figures















read the original abstract
Social media are shifting towards pluralism -- community-governed platforms where groups define their own norms. What violates rules in one community may be perfectly acceptable in another. Can AI models help moderate such pluralistic communities? We formalize the task as a multiple-choice problem, mirroring how human moderators operate in the real world: given a comment and its surrounding context, identify which specific rule, if any, is violated. We introduce PluRule, a multimodal, multilingual benchmark for detecting 13,371 rule violations across 1,989 Reddit communities spanning 2,885 rules in 9 languages. Using this benchmark, we show that state-of-the-art vision-language models struggle significantly: even GPT-5.2 with high reasoning performs only slightly better than a trivial baseline. We also find that bigger models and increased context provide marginal gains, and universal rules like civility and self-promotion are easier to detect. Our results show that moderation of pluralistic communities on social media is a fundamental challenge for language models. Our code and benchmark are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PluRule, a multimodal and multilingual benchmark with 13,371 rule violations across 1,989 Reddit communities and 2,885 rules in 9 languages. It formalizes pluralistic moderation as a multiple-choice task—given a comment, context, and rule list, identify the violated rule (or none)—and reports that state-of-the-art vision-language models, including GPT-5.2, achieve only marginal gains over a trivial baseline. The authors conclude that moderating pluralistic communities constitutes a fundamental challenge for current language models, with additional findings on model scale, context length, and rule type difficulty. Code and benchmark are released publicly.
Significance. If the benchmark and evaluation setup are shown to be a faithful proxy, the work provides a timely, large-scale resource for studying AI moderation in community-governed platforms where norms vary. The public release of data and code is a clear strength that enables follow-up research. The reported performance gaps versus baselines highlight practical difficulties with context-dependent rules, though the strength of this implication rests on the validity of the multiple-choice framing.
major comments (2)
- [Abstract / Task Formalization] Abstract and task-formalization section: the claim that the multiple-choice formulation 'mirrors how human moderators operate in the real world' is load-bearing for the central conclusion that poor model performance demonstrates a 'fundamental challenge.' Real moderators typically retrieve and apply rules from memory or guidelines rather than selecting from an explicit enumerated option set for each comment; this difference introduces the possibility that observed gaps reflect surface-level lexical matching or elimination strategies rather than genuine rule-understanding deficits. A concrete test (e.g., comparison to open-ended generation or human moderator simulation without options) is needed to establish that the performance gap is not an artifact of the evaluation design.
- [Evaluation / Data Construction] Evaluation and data-construction sections: the abstract reports clear performance gaps but provides no details on the data-labeling process, inter-annotator agreement, potential selection biases in community or rule sampling, or statistical significance tests for the reported margins over the trivial baseline. These omissions make it difficult to assess whether the headline result (GPT-5.2 only slightly above baseline) is robust or sensitive to annotation artifacts.
minor comments (2)
- [Results] Clarify the exact construction of the 'trivial baseline' (e.g., random selection among rules or majority-class) and report per-rule and per-language breakdowns to support the claim that universal rules are easier to detect.
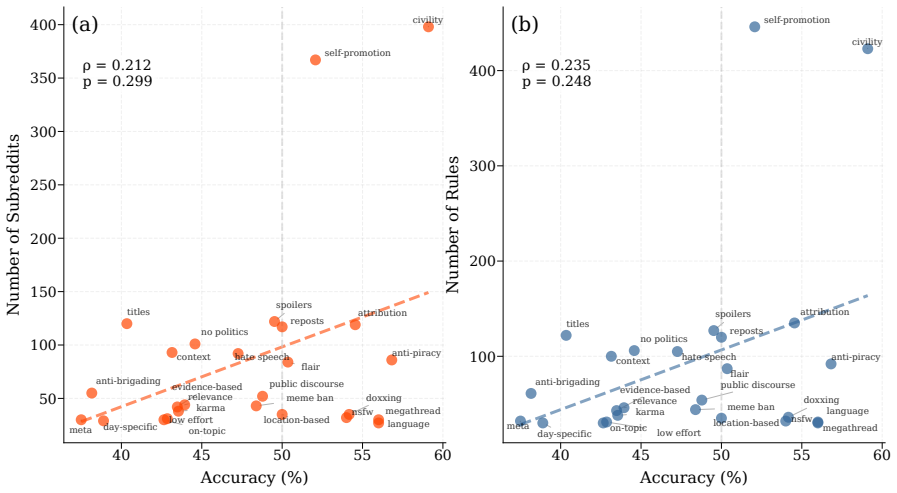
- [Figures / Tables] Figure and table captions should explicitly state the number of communities, rules, and languages represented in each split to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important aspects of task design and evaluation transparency that we have addressed through targeted revisions and clarifications.
read point-by-point responses
-
Referee: The claim that the multiple-choice formulation 'mirrors how human moderators operate in the real world' is load-bearing. Real moderators typically retrieve and apply rules from memory or guidelines rather than selecting from an explicit enumerated option set; gaps may reflect lexical matching rather than genuine understanding. A concrete test (e.g., open-ended generation) is needed.
Authors: We agree the multiple-choice framing is a controlled proxy rather than an exact replica of moderator cognition. Moderators often consult explicit rule lists or guidelines when reviewing content, and our setup tests the core ability to match a comment to a specific rule from the community's set. We have revised the abstract and task formalization section to describe the formulation as 'a controlled multiple-choice evaluation of rule violation detection given explicit rule lists' instead of claiming it directly mirrors real-world operation. We added a limitations paragraph noting the distinction and the possibility of surface-level strategies. A full open-ended generation comparison was outside the scope of this benchmark-focused paper due to evaluation challenges with free-form outputs, but we view the current results as still informative since models show only marginal gains even with options provided. revision: partial
-
Referee: The abstract reports performance gaps but provides no details on the data-labeling process, inter-annotator agreement, potential selection biases in community or rule sampling, or statistical significance tests for margins over the trivial baseline. This makes it difficult to assess robustness or sensitivity to annotation artifacts.
Authors: We appreciate this observation and agree these details are essential for evaluating result reliability. In the revised manuscript we have substantially expanded the data construction and evaluation sections to include: a step-by-step description of the labeling process and annotator guidelines, inter-annotator agreement statistics, discussion of our stratified sampling approach for communities and rules to promote diversity, and statistical significance tests (including p-values) confirming the reported margins over the baseline. These additions directly address concerns about potential artifacts. revision: yes
Circularity Check
No circularity: independent benchmark construction and external model evaluation
full rationale
The paper introduces PluRule as a newly collected multimodal multilingual dataset of 13,371 rule violations from 1,989 Reddit communities and evaluates external state-of-the-art vision-language models (including GPT-5.2) against trivial baselines. The central claim that models struggle on pluralistic moderation follows directly from these empirical results on the held-out benchmark rather than any fitted parameters, self-defined quantities, or predictions that reduce to the paper's own inputs by construction. The multiple-choice formalization is an explicit modeling choice presented as mirroring real-world moderation but does not create a self-referential loop in the reported performance gaps. No load-bearing self-citations or uniqueness theorems are invoked to force the outcomes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The multiple-choice problem with context mirrors how human moderators operate in the real world.
- domain assumption Reddit communities provide representative examples of pluralistic rule sets across languages and topics.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize the task as a multiple-choice problem... identify which specific rule, if any, is violated.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gomez, Raul and Gibert, Jaume and Gomez, Lluis and Karatzas, Dimosthenis , month = mar, year =. Exploring. 2020. doi:10.1109/WACV45572.2020.9093414 , abstract =
-
[2]
Baumgartner, Jason and Zannettou, Savvas and Keegan, Brian and Squire, Megan and Blackburn, Jeremy , month = jan, year =. The. doi:10.48550/arXiv.2001.08435 , abstract =
-
[3]
Wulczyn, Ellery and Thain, Nithum and Dixon, Lucas , month = apr, year =. Ex. Proceedings of the 26th. doi:10.1145/3038912.3052591 , abstract =
-
[4]
Blodgett, Su Lin and Green, Lisa and O'Connor, Brendan , editor =. Demographic. Proceedings of the 2016. 2016 , pages =. doi:10.18653/v1/D16-1120 , urldate =
-
[5]
Hovy, Dirk , editor =. Demographic. Proceedings of the 53rd. 2015 , pages =. doi:10.3115/v1/P15-1073 , urldate =
-
[6]
Computational Linguistics , author =
Argument. Computational Linguistics , author =. 2019 , note =. doi:10.1162/coli_a_00364 , abstract =
-
[7]
Ghosh, Aniruddha and Veale, Tony , editor =. Fracking. Proceedings of the 7th. 2016 , pages =. doi:10.18653/v1/W16-0425 , urldate =
-
[8]
Stance. ACM Comput. Surv. , author =. 2020 , pages =. doi:10.1145/3369026 , abstract =
-
[9]
Social Media + Society , author =
The. Social Media + Society , author =. 2019 , note =. doi:10.1177/2056305119836778 , abstract =
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
A. Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2023 , keywords =. doi:10.1609/aaai.v37i12.26752 , abstract =
-
[11]
Lees, Alyssa and Tran, Vinh Q. and Tay, Yi and Sorensen, Jeffrey and Gupta, Jai and Metzler, Donald and Vasserman, Lucy , month = feb, year =. A. doi:10.48550/arXiv.2202.11176 , abstract =
-
[12]
Borkan, Daniel and Dixon, Lucas and Sorensen, Jeffrey and Thain, Nithum and Vasserman, Lucy , month = may, year =. Nuanced. doi:10.48550/arXiv.1903.04561 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1903.04561 1903
-
[13]
Hartvigsen, Thomas and Gabriel, Saadia and Palangi, Hamid and Sap, Maarten and Ray, Dipankar and Kamar, Ece , editor =. Proceedings of the 60th. 2022 , pages =. doi:10.18653/v1/2022.acl-long.234 , abstract =
-
[14]
Kiela, Douwe and Firooz, Hamed and Mohan, Aravind and Goswami, Vedanuj and Singh, Amanpreet and Ringshia, Pratik and Testuggine, Davide , year =. The. Advances in
-
[15]
Proceedings of the International AAAI Conference on Web and Social Media , author =
Reddit. Proceedings of the International AAAI Conference on Web and Social Media , author =. 2018 , keywords =. doi:10.1609/icwsm.v12i1.15033 , abstract =
-
[16]
Binns, Reuben and Veale, Michael and Van Kleek, Max and Shadbolt, Nigel , editor =. Like. Social. 2017 , keywords =. doi:10.1007/978-3-319-67256-4_32 , abstract =
-
[17]
Shahid, Farhana and Vashistha, Aditya , month = apr, year =. Decolonizing. Proceedings of the 2023. doi:10.1145/3544548.3581538 , abstract =
-
[18]
Dosono, Bryan and Semaan, Bryan , month = may, year =. Moderation. Proceedings of the 2019. doi:10.1145/3290605.3300372 , abstract =
-
[19]
'. Proc. ACM Hum.-Comput. Interact. , author =. 2025 , pages =. doi:10.1145/3757445 , abstract =
-
[20]
Proceedings of the ACM on Human-Computer Interaction , author =
Crossmod:. Proceedings of the ACM on Human-Computer Interaction , author =. 2019 , note =. doi:10.1145/3359276 , abstract =
- [21]
-
[22]
and Yang, Kai-Cheng and Yan, Harry Yaojun and Menczer, Filippo , month = nov, year =
DeVerna, Matthew R. and Yang, Kai-Cheng and Yan, Harry Yaojun and Menczer, Filippo , month = nov, year =. Large. doi:10.48550/arXiv.2511.18749 , abstract =
-
[23]
Threats to the sustainability of
Arjmandi-Lari, Zahra and Mantzarlis, Alexios and Stafford, Tom , month = oct, year =. Threats to the sustainability of. doi:10.48550/arXiv.2510.00650 , abstract =
- [24]
-
[25]
252 and 7845 , month = dec, year =. Double
-
[26]
Content moderation,. Big Data & Society , author =. 2020 , note =. doi:10.1177/2053951720943234 , abstract =
-
[27]
Sheppard, Brooklyn and Richter, Anna and Cohen, Allison and Smith, Elizabeth and Kneese, Tamara and Pelletier, Carolyne and Baldini, Ioana and Dong, Yue , editor =. Biasly:. Findings of the. 2024 , pages =. doi:10.18653/v1/2024.findings-acl.24 , abstract =
-
[28]
Nghiem, Huy and Daumé Iii, Hal , editor =. Findings of the. 2024 , pages =. doi:10.18653/v1/2024.findings-emnlp.343 , abstract =
-
[29]
and Do, Xuan Long and Do, Duc Anh and Vu, Duc Anh and Anh Tuan, Luu , editor =
Hoang, Nhat M. and Do, Xuan Long and Do, Duc Anh and Vu, Duc Anh and Anh Tuan, Luu , editor =. Proceedings of the 2024. 2024 , pages =. doi:10.18653/v1/2024.naacl-long.359 , abstract =
-
[30]
Proceedings of the International AAAI Conference on Web and Social Media , author =. 2024 , pages =. doi:10.1609/icwsm.v18i1.31335 , abstract =
-
[31]
Cohen, Joseph Paul and Lo, Henry Z. , month = jul, year =. Academic. Proceedings of the 2014. doi:10.1145/2616498.2616528 , abstract =
-
[32]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Korbak, Tomek and Balesni, Mikita and Barnes, Elizabeth and Bengio, Yoshua and Benton, Joe and Bloom, Joseph and Chen, Mark and Cooney, Alan and Dafoe, Allan and Dragan, Anca and Emmons, Scott and Evans, Owain and Farhi, David and Greenblatt, Ryan and Hendrycks, Dan and Hobbhahn, Marius and Hubinger, Evan and Irving, Geoffrey and Jenner, Erik and Kokotajl...
work page internal anchor Pith review doi:10.48550/arxiv.2507.11473
-
[33]
Bogdan, Uzay Macar, Neel Nanda, and Arthur Conmy
Bogdan, Paul C. and Macar, Uzay and Nanda, Neel and Conmy, Arthur , month = oct, year =. Thought. doi:10.48550/arXiv.2506.19143 , abstract =
-
[34]
Venhoff, Constantin and Arcuschin, Iván and Torr, Philip and Conmy, Arthur and Nanda, Neel , month = oct, year =. Base. doi:10.48550/arXiv.2510.07364 , abstract =
-
[35]
Ferrando, Javier and Obeso, Oscar and Rajamanoharan, Senthooran and Nanda, Neel , month = feb, year =. Do. doi:10.48550/arXiv.2411.14257 , abstract =
-
[36]
doi:10.48550/arXiv.2503.02863 , abstract =
Zhou, Ziang and Jin, Tianyuan and Shi, Jieming and Li, Qing , month = may, year =. doi:10.48550/arXiv.2503.02863 , abstract =
-
[37]
Wang, Shenzhi and Yu, Le and Gao, Chang and Zheng, Chujie and Liu, Shixuan and Lu, Rui and Dang, Kai and Chen, Xionghui and Yang, Jianxin and Zhang, Zhenru and Liu, Yuqiong and Yang, An and Zhao, Andrew and Yue, Yang and Song, Shiji and Yu, Bowen and Huang, Gao and Lin, Junyang , month = nov, year =. Beyond the 80/20. doi:10.48550/arXiv.2506.01939 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.01939
-
[38]
arXiv.org , author =
-
[39]
Jiang, Jiachen and Zhou, Jinxin and Peng, Bo and Ning, Xia and Zhu, Zhihui , month = may, year =. Analyzing. doi:10.48550/arXiv.2505.17316 , abstract =
-
[40]
Ma, Jie and Qu, Ning and Gao, Zhitao and Xing, Rui and Liu, Jun and Pei, Hongbin and Xie, Jiang and Song, Linyun and Wang, Pinghui and Tao, Jing and Su, Zhou , month = oct, year =. Deliberation on. doi:10.48550/arXiv.2505.15210 , abstract =
-
[41]
Wang, Xingliang and Liu, Zemin and Han, Junxiao and Deng, Shuiguang , month = oct, year =
-
[42]
Xu, Haolei and Yan, Yuchen and Shen, Yongliang and Zhang, Wenqi and Hou, Guiyang and Jiang, Shengpei and Song, Kaitao and Lu, Weiming and Xiao, Jun and Zhuang, Yueting , month = nov, year =. Mind the. doi:10.48550/arXiv.2505.14684 , abstract =
-
[43]
Sarukkai, Vishnu and Xie, Zhiqiang and Fatahalian, Kayvon , month = may, year =. Self-. doi:10.48550/arXiv.2505.00234 , abstract =
-
[44]
Park, Young-Jin and Greenewald, Kristjan and Alim, Kaveh and Wang, Hao and Azizan, Navid , month = nov, year =. Know. doi:10.48550/arXiv.2506.09338 , abstract =
-
[45]
Sam, Dylan and Finzi, Marc and Kolter, J. Zico , month = nov, year =. Predicting the. doi:10.48550/arXiv.2501.01558 , abstract =
-
[46]
Davidson, Guy and Gureckis, Todd M. and Lake, Brenden M. and Williams, Adina , month = nov, year =. Do different prompting methods yield a common task representation in language models? , url =. doi:10.48550/arXiv.2505.12075 , abstract =
-
[47]
and Ren, Xiang and Swayamdipta, Swabha , month = jun, year =
Nazir, Murtaza and Finlayson, Matthew and Morris, John X. and Ren, Xiang and Swayamdipta, Swabha , month = jun, year =. Better. doi:10.48550/arXiv.2506.17090 , abstract =
-
[48]
doi:10.48550/arXiv.2502.08904 , abstract =
You, Xinxin and Liu, Xien and Sun, Qixin and Zhang, Huan and Zhou, Kaiyin and Liu, Shaohui and Hu, GuoPing and Wang, ShiJin and Liu, Si and Wu, Ji , month = feb, year =. doi:10.48550/arXiv.2502.08904 , abstract =
-
[49]
Yoon, Dongkeun and Kim, Seungone and Yang, Sohee and Kim, Sunkyoung and Kim, Soyeon and Kim, Yongil and Choi, Eunbi and Kim, Yireun and Seo, Minjoon , month = oct, year =. Reasoning. doi:10.48550/arXiv.2505.14489 , abstract =
-
[50]
Zhang, Qingyang and Wu, Haitao and Zhang, Changqing and Zhao, Peilin and Bian, Yatao , month = may, year =. Right. doi:10.48550/arXiv.2504.05812 , abstract =
-
[51]
Xu, Xiaoang and Wang, Shuo and Han, Xu and Liu, Zhenghao and Wu, Huijia and Li, Peipei and Liu, Zhiyuan and Sun, Maosong and He, Zhaofeng , month = oct, year =. A*-. doi:10.48550/arXiv.2505.24550 , abstract =
-
[52]
doi:10.48550/arXiv.2506.15710 , abstract =
Ouyang, Siru and Zhu, Xinyu and Xiao, Zilin and Jiang, Minhao and Meng, Yu and Han, Jiawei , month = may, year =. doi:10.48550/arXiv.2506.15710 , abstract =
-
[53]
Choi, Yumin and Baek, Jinheon and Hwang, Sung Ju , month = oct, year =. System. doi:10.48550/arXiv.2505.09666 , abstract =
-
[54]
Zhang, Zhen and He, Xuehai and Yan, Weixiang and Shen, Ao and Zhao, Chenyang and Wang, Shuohang and Shen, Yelong and Wang, Xin Eric , month = may, year =. Soft. doi:10.48550/arXiv.2505.15778 , abstract =
-
[55]
OpenThoughts: Data Recipes for Reasoning Models
Guha, Etash and Marten, Ryan and Keh, Sedrick and Raoof, Negin and Smyrnis, Georgios and Bansal, Hritik and Nezhurina, Marianna and Mercat, Jean and Vu, Trung and Sprague, Zayne and Suvarna, Ashima and Feuer, Benjamin and Chen, Liangyu and Khan, Zaid and Frankel, Eric and Grover, Sachin and Choi, Caroline and Muennighoff, Niklas and Su, Shiye and Zhao, Wa...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.04178
-
[56]
Friedman, Dan and Dieng, Adji Bousso , month = jul, year =. The. doi:10.48550/arXiv.2210.02410 , abstract =
-
[57]
Yue, Yang and Chen, Zhiqi and Lu, Rui and Zhao, Andrew and Wang, Zhaokai and Yue, Yang and Song, Shiji and Huang, Gao , month = nov, year =. Does. doi:10.48550/arXiv.2504.13837 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13837
-
[58]
Journal of Personality and Social Psychology , author =
Unskilled and unaware of it: how difficulties in recognizing one's own incompetence lead to inflated self-assessments , volume =. Journal of Personality and Social Psychology , author =. 1999 , pmid =. doi:10.1037//0022-3514.77.6.1121 , abstract =
-
[59]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Agrawal, Lakshya A. and Tan, Shangyin and Soylu, Dilara and Ziems, Noah and Khare, Rishi and Opsahl-Ong, Krista and Singhvi, Arnav and Shandilya, Herumb and Ryan, Michael J. and Jiang, Meng and Potts, Christopher and Sen, Koushik and Dimakis, Alexandros G. and Stoica, Ion and Klein, Dan and Zaharia, Matei and Khattab, Omar , month = jul, year =. doi:10.48...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.19457
-
[60]
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau , editor =. Dense. Proceedings of the 2020. 2020 , pages =. doi:10.18653/v1/2020.emnlp-main.550 , abstract =
-
[61]
Proceedings of the International AAAI Conference on Web and Social Media , author =
All. Proceedings of the International AAAI Conference on Web and Social Media , author =. 2022 , keywords =. doi:10.1609/icwsm.v16i1.19317 , abstract =
-
[62]
Proceedings of the International AAAI Conference on Web and Social Media , author =
Measuring the. Proceedings of the International AAAI Conference on Web and Social Media , author =. 2022 , keywords =. doi:10.1609/icwsm.v16i1.19318 , abstract =
-
[63]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Park, Joon Sung and Zou, Carolyn Q. and Shaw, Aaron and Hill, Benjamin Mako and Cai, Carrie and Morris, Meredith Ringel and Willer, Robb and Liang, Percy and Bernstein, Michael S. , month = nov, year =. Generative. doi:10.48550/arXiv.2411.10109 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.10109
-
[64]
Chen, Xinyun and Chi, Ryan Andrew and Wang, Xuezhi and Zhou, Denny , month = jul, year =. Premise. Proceedings of the 41st
-
[66]
Roberts, Sarah T. , month = sep, year =. Behind the screen: the hidden digital labor of commercial content moderation , copyright =
-
[67]
Guess, Andrew M. and Lyons, Benjamin A. , editor =. Misinformation,. Social. 2020 , keywords =
work page 2020
-
[68]
Zeng (Jing) and Babwah), Brennen (Scott , month = nov, year =. Misinformation , copyright =. doi:10.14763/2023.4.1725 , note =
-
[69]
Zhang, Ruohong and Zhang, Bowen and Li, Yanghao and Zhang, Haotian and Sun, Zhiqing and Gan, Zhe and Yang, Yinfei and Pang, Ruoming and Yang, Yiming , editor =. Improve. Proceedings of the 63rd. 2025 , pages =. doi:10.18653/v1/2025.acl-long.82 , abstract =
-
[70]
Behavioral Sciences , author =
Content. Behavioral Sciences , author =. 2025 , pmid =. doi:10.3390/bs15040487 , abstract =
-
[71]
Cyberpsychology: Journal of Psychosocial Research on Cyberspace , author =
The psychological impacts of content moderation on content moderators:. Cyberpsychology: Journal of Psychosocial Research on Cyberspace , author =. 2023 , keywords =. doi:10.5817/CP2023-4-8 , abstract =
-
[72]
Deepfakes and scientific knowledge dissemination , volume =. Scientific Reports , author =. 2023 , note =. doi:10.1038/s41598-023-39944-3 , abstract =
- [73]
- [74]
-
[75]
Pew Research Center , author =
False information online as a threat , url =. Pew Research Center , author =
-
[76]
Nature Communications , author =
Human detection of political speech deepfakes across transcripts, audio, and video , volume =. Nature Communications , author =. 2024 , note =. doi:10.1038/s41467-024-51998-z , abstract =
-
[77]
The spread of true and false news online , volume =. Science , author =. 2018 , note =. doi:10.1126/science.aap9559 , abstract =
-
[78]
Panchendrarajan, Rrubaa and Pérez, Rubén Míguez and Zubiaga, Arkaitz , editor =. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-emnlp.599 , abstract =
-
[79]
Pikuliak, Matúš and Srba, Ivan and Moro, Robert and Hromadka, Timo and Smoleň, Timotej and Melišek, Martin and Vykopal, Ivan and Simko, Jakub and Podroužek, Juraj and Bielikova, Maria , editor =. Multilingual. Proceedings of the 2023. 2023 , pages =. doi:10.18653/v1/2023.emnlp-main.1027 , abstract =
-
[80]
Ribeiro, Leonardo F. R. and Liu, Mengwen and Gurevych, Iryna and Dreyer, Markus and Bansal, Mohit , month = jul, year =. doi:10.48550/arXiv.2204.06508 , abstract =
-
[81]
Jayaweera, Chathuri and Youm, Sangpil and Dorr, Bonnie J , editor =. Proceedings of the. 2024 , pages =. doi:10.18653/v1/2024.fever-1.26 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.