Seeing Together: Multi-Robot Cooperative Egocentric Spatial Reasoning with Multimodal Large Language Models
Pith reviewed 2026-05-20 10:32 UTC · model grok-4.3
The pith
SP-CoR lets MLLMs fuse multiple robots' egocentric views for stronger cooperative spatial reasoning at test time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SP-CoR is an MLLM framework that combines dynamics-aware multi-robot frame sampling, spectral- and physics-guided view fusion, and physics-aligned prompt distillation. This design lets the model exploit privileged robot-pose supervision during training yet requires only egocentric videos at test time, producing consistent gains in cooperative reasoning across 22 baselines.
What carries the argument
Spectral and Physics-Informed Cooperative Reasoner (SP-CoR) that performs spectral- and physics-guided view fusion to integrate information across multiple robot viewpoints.
If this is right
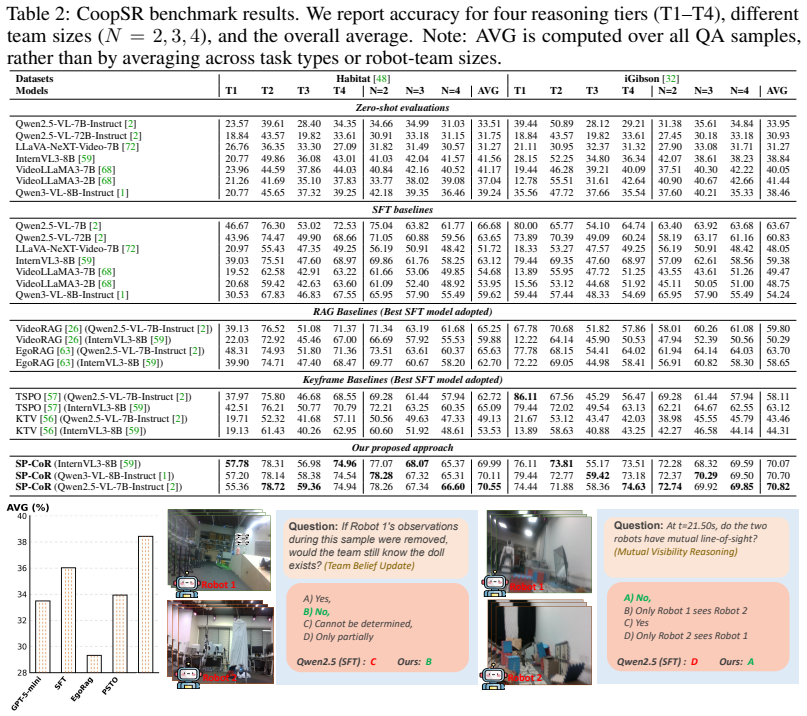
- SP-CoR outperforms the strongest fine-tuned baseline by 3.87 percent on Habitat and 7.12 percent on iGibson.
- The method generalizes more robustly to team sizes not seen during training.
- Performance holds up in real-world tests collected with two quadruped robots.
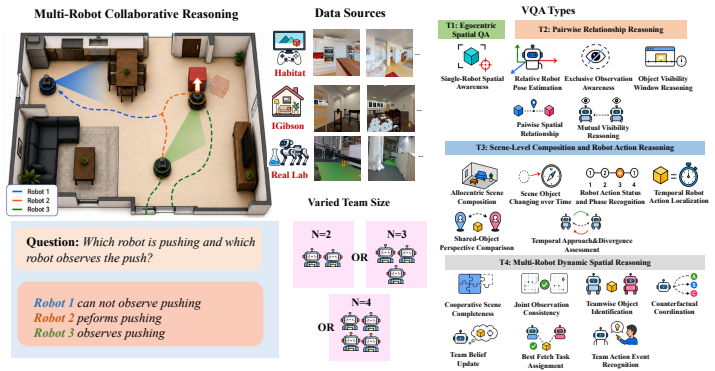
- The approach covers 19 question types across four difficulty tiers and three team sizes in simulation.
Where Pith is reading between the lines
- The same fusion approach could be tested on collaborative mapping or object search tasks where multiple agents share partial views.
- Physics-informed distillation may offer a general route to shrink the simulation-to-real gap in other vision-language robotics settings.
- Scaling the method to larger or heterogeneous robot teams would test whether the current gains persist without extra supervision.
Load-bearing premise
Spectral- and physics-guided view fusion plus physics-aligned prompt distillation can transfer knowledge from privileged pose supervision in training to improve performance when only egocentric videos are available at test time.
What would settle it
SP-CoR shows no gain or a reversal of gains over fine-tuned baselines when evaluated on new environments, larger unseen team sizes, or additional real-world robot tests without any pose information.
Figures





read the original abstract
Multimodal Large Language Models (MLLMs) have made substantial progress in egocentric video understanding, but their ability to reason cooperatively from multiple embodied viewpoints remains largely unexplored. We study this problem through multi-robot cooperative dynamic spatial reasoning, where a model must answer spatial, temporal, visibility, and coordination questions by integrating synchronized egocentric videos from a team of moving robots. To support this setting, we introduce CoopSR, the first benchmark for this task, together with EgoTeam, a multi-robot egocentric QA dataset. EgoTeam contains 114,227 QA pairs spanning 19 question types, four difficulty tiers, and three team sizes in Habitat and iGibson, along with a real-world test set of around 2,326 QAs collected using two quadruped robots. We further propose SP-CoR (Spectral and Physics-Informed Cooperative Reasoner), an MLLM framework for fine-grained cooperative spatial reasoning. SP-CoR combines dynamics-aware multi-robot frame sampling, spectral- and physics-guided view fusion, and physics-aligned prompt distillation, enabling the model to benefit from privileged robot-pose supervision during training while requiring only egocentric videos at test time. Across 22 MLLM baselines, SP-CoR consistently improves cooperative reasoning, outperforming the strongest fine-tuned baseline by +3.87% on Habitat and +7.12% on iGibson. It also shows stronger generalization to unseen team sizes and real-world robot tests. Code can be found at https://github.com/KPeng9510/seeing-together.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoopSR, the first benchmark for multi-robot cooperative dynamic spatial reasoning, and the EgoTeam dataset with 114,227 QA pairs across simulation (Habitat, iGibson) and real-robot settings. It proposes SP-CoR, an MLLM framework using dynamics-aware frame sampling, spectral- and physics-guided view fusion, and physics-aligned prompt distillation. The method is designed to leverage privileged robot-pose supervision during training while requiring only synchronized egocentric videos at inference. Experiments across 22 baselines report consistent gains, including +3.87% on Habitat and +7.12% on iGibson, plus improved generalization to unseen team sizes and real-world quadruped-robot tests.
Significance. If the central claims hold, the work fills a clear gap in embodied multi-agent reasoning by releasing a new benchmark and dataset with real-world validation, while the physics-informed components and code release at the provided GitHub repository represent concrete strengths for reproducibility and extension. The reported generalization results, if robust, would be a meaningful step toward practical cooperative spatial reasoning with MLLMs.
major comments (2)
- [§3.3] §3.3 (Physics-Aligned Prompt Distillation): The manuscript states that this component distills privileged pose information into the MLLM for egocentric-only inference, yet provides neither the explicit loss formulation nor an ablation that isolates its contribution from standard MLLM fine-tuning. This is load-bearing for the claim that gains arise from the proposed transfer mechanism rather than extra training compute.
- [Table 4] Table 4 (Generalization to unseen team sizes): The reported improvements on held-out team sizes are central to the generalization claim, but without per-run standard deviations or statistical significance tests the +3.87% / +7.12% margins cannot be confidently distinguished from training variance.
minor comments (2)
- [Figure 2] Figure 2 (Architecture diagram): The flow from spectral fusion to prompt distillation would be clearer with explicit arrows indicating which components receive privileged pose input only at training time.
- [§5.1] §5.1 (Real-world experiments): The description of the two-quadruped test set mentions 2,326 QAs but does not specify how question generation was controlled to avoid dataset biases present in the simulation splits.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments identify areas where additional technical detail and statistical reporting would strengthen the manuscript. We address each point below and commit to incorporating the requested changes in the revised version.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Physics-Aligned Prompt Distillation): The manuscript states that this component distills privileged pose information into the MLLM for egocentric-only inference, yet provides neither the explicit loss formulation nor an ablation that isolates its contribution from standard MLLM fine-tuning. This is load-bearing for the claim that gains arise from the proposed transfer mechanism rather than extra training compute.
Authors: We agree that an explicit loss formulation and a controlled ablation are necessary to substantiate the contribution of physics-aligned prompt distillation. In the revised manuscript we will add the precise loss equation (a pose-conditioned distillation objective that aligns prompt embeddings with privileged robot-pose features) and an ablation that compares SP-CoR against a version trained with identical compute but without the distillation term. This will isolate the effect of the proposed transfer mechanism from generic fine-tuning. revision: yes
-
Referee: [Table 4] Table 4 (Generalization to unseen team sizes): The reported improvements on held-out team sizes are central to the generalization claim, but without per-run standard deviations or statistical significance tests the +3.87% / +7.12% margins cannot be confidently distinguished from training variance.
Authors: We acknowledge that reporting only point estimates limits confidence in the generalization results. In the revision we will rerun the relevant experiments with multiple random seeds, report mean performance together with standard deviations, and include statistical significance tests (paired t-tests) between SP-CoR and the strongest baseline to demonstrate that the observed margins are unlikely to arise from training variance alone. revision: yes
Circularity Check
No significant circularity; performance claims rest on held-out benchmarks independent of training inputs.
full rationale
The paper reports accuracy gains on explicitly held-out test sets in Habitat, iGibson, and real-robot collections. SP-CoR's use of privileged pose supervision occurs only at training time through standard distillation-style components (dynamics-aware sampling, spectral/physics-guided fusion, physics-aligned prompt distillation); test-time inference uses only egocentric video. No equations, fitted parameters, or self-citations are shown to reduce the reported test metrics to quantities defined by the training inputs themselves. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs pretrained on egocentric video can be adapted to multi-view cooperative reasoning via fine-tuning and auxiliary supervision
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Sven Bambach, Stefan Lee, David J. Crandall, and Chen Yu. Lending a hand: Detecting hands and recognizing activities in complex egocentric interactions. InICCV, 2015
work page 2015
-
[4]
Siddhant Bansal, Chetan Arora, and C.V . Jawahar. My view is the best view: Procedure learning from egocentric videos. InECCV, 2022
work page 2022
-
[5]
Andy Bonnetto, Haozhe Qi, Franklin Leong, Matea Tashkovska, Mahdi Rad, Solaiman Shokur, Friedhelm Hummel, Silvestro Micera, Marc Pollefeys, and Alexander Mathis. EPFL-Smart- Kitchen: An ego-exo multi-modal dataset for challenging action and motion understanding in video-language models. InNeurIPS, 2025
work page 2025
-
[6]
CausalMACE: Causality empowered multi-agents in minecraft cooperative tasks
Qi Chai, Zhang Zheng, Junlong Ren, Deheng Ye, Zichuan Lin, and Hao Wang. CausalMACE: Causality empowered multi-agents in minecraft cooperative tasks. InEMNLP (Findings), 2025
work page 2025
-
[7]
Keshigeyan Chandrasegaran, Agrim Gupta, Lea M. Hadzic, Taran Kota, Jimming He, Cristóbal Eyzaguirre, Zane Durante, Manling Li, Jiajun Wu, and Li Fei-Fei. HourVideo: 1-hour video- language understanding. InNeurIPS, 2024
work page 2024
-
[8]
Matthew Chang, Gunjan Chhablani, Alexander Clegg, Mikael Dallaire Cote, Ruta Desai, Michal Hlavac, Vladimir Karashchuk, Jacob Krantz, Roozbeh Mottaghi, Priyam Parashar, Siddharth Patki, Ishita Prasad, Xavier Puig, Akshara Rai, Ram Ramrakhya, Daniel Tran, Joanne Truong, John M. Turner, Eric Undersander, and Tsung-Yen Yang. PARTNR: A benchmark for planning ...
-
[9]
CrossViT: Cross-attention multi- scale vision transformer for image classification
Chun-Fu Richard Chen, Quanfu Fan, and Rameswar Panda. CrossViT: Cross-attention multi- scale vision transformer for image classification. InICCV, 2021
work page 2021
-
[10]
Yi Chen, Yuying Ge, Yixiao Ge, Mingyu Ding, Bohao Li, Rui Wang, Ruifeng Xu, Ying Shan, and Xihui Liu. EgoPlan-Bench: Benchmarking multimodal large language models for human-level planning.International Journal of Computer Vision, 2026. 10
work page 2026
-
[11]
InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InCVPR, 2024
work page 2024
-
[12]
EgoThink: Evaluating first-person perspective thinking capability of vision-language models
Sijie Cheng, Zhicheng Guo, Jingwen Wu, Kechen Fang, Peng Li, Huaping Liu, and Yang Liu. EgoThink: Evaluating first-person perspective thinking capability of vision-language models. InCVPR, 2024
work page 2024
-
[13]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. The EPIC-KITCHENS dataset: Collection, challenges and baselines.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
work page 2021
-
[14]
EPIC-KITCHENS VISOR benchmark: Video segmentations and object relations
Ahmad Darkhalil, Dandan Shan, Bin Zhu, Jian Ma, Amlan Kar, Richard Higgins, Sanja Fidler, David Fouhey, and Dima Damen. EPIC-KITCHENS VISOR benchmark: Video segmentations and object relations. InNeurIPS, 2022
work page 2022
-
[15]
Guide to the carnegie mellon university multimodal activity (CMU- MMAC) database
Fernando De la Torre, Jessica Hodgins, Adam Bargteil, Xavier Martin, Justin Macey, Alex Collado, and Pep Beltran. Guide to the carnegie mellon university multimodal activity (CMU- MMAC) database. 2009
work page 2009
-
[16]
EgoVQA-an egocentric video question answering benchmark dataset
Chenyou Fan. EgoVQA-an egocentric video question answering benchmark dataset. InICCVW, 2019
work page 2019
-
[17]
Alircza Fathi, Jessica K. Hodgins, and James M. Rehg. Social interactions: A first-person perspective. InCVPR, 2012
work page 2012
-
[18]
Ego4D: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4D: Around the world in 3,000 hours of egocentric video. InCVPR, 2022
work page 2022
-
[19]
Ego-Exo4D: Understanding skilled human activity from first- and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyl- los Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, et al. Ego-Exo4D: Understanding skilled human activity from first- and third-person perspectives. InCVPR, 2024
work page 2024
-
[20]
Xudong Guo, Kaixuan Huang, Jiale Liu, Wenhui Fan, Natalia Vélez, Qingyun Wu, Huazheng Wang, Thomas L. Griffiths, and Mengdi Wang. Embodied LLM agents learn to cooperate in organized teams.IEEE Transactions on Computational Social Systems, 2026
work page 2026
-
[21]
Egoexobench: A benchmark for first-and third-person view video understanding in mllms
Yuping He, Yifei Huang, Guo Chen, Baoqi Pei, Jilan Xu, Tong Lu, and Jiangmiao Pang. EgoExoBench: A benchmark for first- and third-person view video understanding in mllms. arXiv preprint arXiv:2507.18342, 2025
-
[22]
Lora: Low-rank adaptation of large language models.ICLR, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 2022
work page 2022
-
[23]
Yifei Huang, Guo Chen, Jilan Xu, Mingfang Zhang, Lijin Yang, Baoqi Pei, Hongjie Zhang, Lu Dong, Yali Wang, Limin Wang, and Yu Qiao. EgoExoLearn: A dataset for bridging asynchronous ego- and exo-centric view of procedural activities in real world. InCVPR, 2024
work page 2024
-
[24]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jia- jun Zhang, Bowen Yu, Keming Lu, et al. Qwen2.5-Coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
A cordial sync: Going beyond marginal policies for multi-agent embodied tasks
Unnat Jain, Luca Weihs, Eric Kolve, Ali Farhadi, Svetlana Lazebnik, Aniruddha Kembhavi, and Alexander Schwing. A cordial sync: Going beyond marginal policies for multi-agent embodied tasks. InECCV, 2020
work page 2020
-
[26]
VideoRAG: Retrieval- augmented generation over video corpus
Soyeong Jeong, Kangsan Kim, Jinheon Baek, and Sung Ju Hwang. VideoRAG: Retrieval- augmented generation over video corpus. InACL (Findings), 2025
work page 2025
-
[27]
EgoTaskQA: Understanding human tasks in egocentric videos
Baoxiong Jia, Ting Lei, Song-Chun Zhu, and Siyuan Huang. EgoTaskQA: Understanding human tasks in egocentric videos. InNeurIPS, 2022. 11
work page 2022
-
[28]
Minjoon Jung, Junbin Xiao, Junghyun Kim, Byoung-Tak Zhang, and Angela Yao. EgoExo-Con: Exploring view-invariant video temporal understanding.arXiv preprint arXiv:2510.26113, 2025
-
[29]
Kangsan Kim, Yanlai Yang, Suji Kim, Woongyeong Yeo, Youngwan Lee, Mengye Ren, and Sung Ju Hwang. MA-EgoQA: Question answering over egocentric videos from multiple embodied agents.arXiv preprint arXiv:2603.09827, 2026
-
[30]
Discovering important people and objects for egocentric video summarization
Yong Jae Lee, Joydeep Ghosh, and Kristen Grauman. Discovering important people and objects for egocentric video summarization. InCVPR, 2012
work page 2012
-
[31]
SEED-Bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. SEED-Bench: Benchmarking multimodal large language models. InCVPR, 2024
work page 2024
-
[32]
Karen Liu, Hyowon Gweon, Jiajun Wu, Li Fei-Fei, and Silvio Savarese
Chengshu Li, Fei Xia, Roberto Martín-Martín, Michael Lingelbach, Sanjana Srivastava, Bokui Shen, Kent Elliott Vainio, Cem Gokmen, Gokul Dharan, Tanish Jain, Andrey Kurenkov, C. Karen Liu, Hyowon Gweon, Jiajun Wu, Li Fei-Fei, and Silvio Savarese. iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks. InCoRL, 2021
work page 2021
-
[33]
Video-LLaV A: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning united visual representation by alignment before projection. InEMNLP, 2024
work page 2024
-
[34]
Egocentric video-language pretraining
Kevin Qinghong Lin, Jinpeng Wang, Mattia Soldan, Michael Wray, Rui Yan, Eric Zhongcong Xu, Difei Gao, Rong-Cheng Tu, Wenzhe Zhao, Weijie Kong, Chengfei Cai, Hongfa Wang, Dima Damen, Bernard Ghanem, Wei Liu, and Mike Zheng Shou. Egocentric video-language pretraining. InNeurIPS, 2022
work page 2022
-
[35]
Coarse correspondences boost spatial-temporal reasoning in multimodal language model
Benlin Liu, Yuhao Dong, Yiqin Wang, Zixian Ma, Yansong Tang, Luming Tang, Yongming Rao, Wei-Chiu Ma, and Ranjay Krishna. Coarse correspondences boost spatial-temporal reasoning in multimodal language model. InCVPR, 2025
work page 2025
-
[36]
COHERENT: Collaboration of heterogeneous multi-robot system with large language models
Kehui Liu, Zixin Tang, Dong Wang, Zhigang Wang, Xuelong Li, and Bin Zhao. COHERENT: Collaboration of heterogeneous multi-robot system with large language models. InICRA, 2025
work page 2025
-
[37]
Youzhi Liu, Li Gao, Liu Liu, Mingyang Lv, and Yang Cai. CoMaTrack: Competitive multi-agent game-theoretic tracking with vision-language-action models.arXiv preprint arXiv:2603.22846, 2026
-
[38]
Zhongyuang Liu, Min He, Shaonan Yu, Xinhang Xu, Muqing Cao, Jianping Li, Jianfei Yang, and Lihua Xie. OmniVLN: Omnidirectional 3D perception and token-efficient LLM reasoning for visual-language navigation across air and ground platforms.arXiv preprint arXiv:2603.17351, 2026
-
[39]
Qian Long, Zhi Li, Ran Gong, Ying Nian Wu, Demetri Terzopoulos, and Xiaofeng Gao. TeamCraft: A benchmark for multi-modal multi-agent systems in minecraft.arXiv preprint arXiv:2412.05255, 2024
-
[40]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Video-RAG: Visually-aligned retrieval-augmented long video comprehension
Yongdong Luo, Xiawu Zheng, Xiao Yang, Guilin Li, Haojia Lin, Jinfa Huang, Jiayi Ji, Fei Chao, Jiebo Luo, and Rongrong Ji. Video-RAG: Visually-aligned retrieval-augmented long video comprehension. InNeurIPS, 2025
work page 2025
-
[42]
EgoSchema: A diagnostic benchmark for very long-form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. EgoSchema: A diagnostic benchmark for very long-form video language understanding. InNeurIPS, 2023
work page 2023
-
[43]
Real-time hand tracking under occlusion from an egocentric RGB-D sensor
Franziska Mueller, Dushyant Mehta, Oleksandr Sotnychenko, Srinath Sridhar, Dan Casas, and Christian Theobalt. Real-time hand tracking under occlusion from an egocentric RGB-D sensor. InICCV, 2017
work page 2017
- [44]
-
[45]
Andrea Palazzi, Davide Abati, Simone Calderara, Francesco Solera, and Rita Cucchiara. Pre- dicting the driver’s focus of attention: The DR(eye)VE project.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019
work page 2019
-
[46]
YouHome system and dataset: Making your home know you better
Junhao Pan, Zehua Yuan, Xiaofan Zhang, and Deming Chen. YouHome system and dataset: Making your home know you better. IniSES, 2022
work page 2022
-
[47]
E 2(GO)MOTION: Motion augmented event stream for egocentric action recognition
Chiara Plizzari, Mirco Planamente, Gabriele Goletto, Marco Cannici, Emanuele Gusso, Mat- teo Matteucci, and Barbara Caputo. E 2(GO)MOTION: Motion augmented event stream for egocentric action recognition. InCVPR, 2022
work page 2022
-
[48]
Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, Rus- lan Partsey, Ruta Desai, Alexander Clegg, Michal Hlavac, So Yeon Min, Vladimir V ondrus, Théophile Gervet, Vincent-Pierre Berges, John M. Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakrishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Ak- s...
-
[49]
RoboFactory: Exploring embodied agent collaboration with compositional constraints
Yiran Qin, Li Kang, Xiufeng Song, Zhenfei Yin, Xiaohong Liu, Xihui Liu, Ruimao Zhang, and Lei Bai. RoboFactory: Exploring embodied agent collaboration with compositional constraints. InICCV, 2025
work page 2025
-
[50]
Heqian Qiu, Zhaofeng Shi, Lanxiao Wang, Huiyu Xiong, Xiang Li, and Hongliang Li. EgoMe: A new dataset and challenge for following me via egocentric view in real world.arXiv preprint arXiv:2501.19061, 2025
-
[51]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021
work page 2021
-
[52]
First-person activity recognition: What are they doing to me? InCVPR, 2013
Michael S Ryoo and Larry Matthies. First-person activity recognition: What are they doing to me? InCVPR, 2013
work page 2013
-
[53]
Solaris: Building a multiplayer video world model in minecraft
Georgy Savva, Oscar Michel, Daohan Lu, Suppakit Waiwitlikhit, Timothy Meehan, Dhairya Mishra, Srivats Poddar, Jack Lu, and Saining Xie. Solaris: Building a multiplayer video world model in minecraft.arXiv preprint arXiv:2602.22208, 2026
-
[54]
Schoonbeek, Tim Houben, Hans Onvlee, Peter H
Tim J. Schoonbeek, Tim Houben, Hans Onvlee, Peter H. N. de With, and Fons van der Sommen. IndustReal: A dataset for procedure step recognition handling execution errors in egocentric videos in an industrial-like setting. InWACV, 2024
work page 2024
-
[55]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Baiyang Song, Jun Peng, Yuxin Zhang, Guangyao Chen, Feidiao Yang, and Jianyuan Guo. KTV: Keyframes and key tokens selection for efficient training-free video LLMs.arXiv preprint arXiv:2602.03615, 2026
-
[57]
TSPO: Temporal sampling policy optimization for long-form video language understanding
Canhui Tang, Zifan Han, Hongbo Sun, Sanping Zhou, Xuchong Zhang, Xin Wei, Ye Yuan, Huayu Zhang, Jinglin Xu, and Hao Sun. TSPO: Temporal sampling policy optimization for long-form video language understanding. InAAAI, 2026
work page 2026
-
[58]
Breaking the “object” in video object segmentation
Pavel Tokmakov, Jie Li, and Adrien Gaidon. Breaking the “object” in video object segmentation. InCVPR, 2023
work page 2023
-
[59]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
HoloAssist: an egocentric human interaction dataset for interactive AI assistants in the real world
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Feniello, Bugra Tekin, Felipe Vieira Frujeri, Neel Joshi, and Marc Pollefeys. HoloAssist: an egocentric human interaction dataset for interactive AI assistants in the real world. InICCV, 2023. 13
work page 2023
-
[61]
Yaxuan Wang, Yifan Xiang, Ke Li, Xun Zhang, BoWen Ye, Zhuochen Fan, Fei Wei, and Tong Yang. Can a robot walk the robotic dog: Triple-zero collaborative navigation for heterogeneous multi-agent systems.arXiv preprint arXiv:2603.21723, 2026
-
[62]
MultiWorld: Scalable Multi-Agent Multi-View Video World Models
Haoyu Wu, Jiwen Yu, Yingtian Zou, and Xihui Liu. MultiWorld: Scalable multi-agent multi- view video world models.arXiv preprint arXiv:2604.18564, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
EgoLife: Towards egocentric life assistant
Jingkang Yang, Shuai Liu, Hongming Guo, Yuhao Dong, Xiamengwei Zhang, Sicheng Zhang, Pengyun Wang, Zitang Zhou, Binzhu Xie, Ziyue Wang, Bei Ouyang, Zhengyu Lin, Marco Cominelli, Zhongang Cai, Bo Li, Yuanhan Zhang, Peiyuan Zhang, Fangzhou Hong, Joerg Widmer, Francesco Gringoli, Lei Yang, and Ziwei Liu. EgoLife: Towards egocentric life assistant. InCVPR, 2025
work page 2025
-
[64]
Mm-ego: Towards building ego- centric multimodal llms
Hanrong Ye, Haotian Zhang, Erik A. Daxberger, Lin Chen, Zongyu Lin, Yanghao Li, Bowen Zhang, Haoxuan You, Dan Xu, Zhe Gan, Jiasen Lu, and Yinfei Yang. MM-Ego: Towards building egocentric multimodal LLMs.arXiv preprint arXiv:2410.07177, 2024
-
[65]
Bangguo Yu, Hamidreza Kasaei, and Ming Cao. Co-NavGPT: Multi-robot cooperative visual semantic navigation using vision language models.arXiv preprint arXiv:2310.07937, 2023
-
[66]
Chao Yu, Xinyi Yang, Jiaxuan Gao, Jiayu Chen, Yunfei Li, Jijia Liu, Yunfei Xiang, Ruixin Huang, Huazhong Yang, Yi Wu, and Yu Wang. Asynchronous multi-agent reinforcement learning for efficient real-time multi-robot cooperative exploration. InAAMAS, 2023
work page 2023
-
[67]
AirCopBench: A benchmark for multi-drone collaborative embodied perception and reasoning
Jirong Zha, Yuxuan Fan, Tianyu Zhang, Geng Chen, Yingfeng Chen, Chen Gao, and Xinlei Chen. AirCopBench: A benchmark for multi-drone collaborative embodied perception and reasoning. InAAAI, 2026
work page 2026
-
[68]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. VideoLLaMA 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
EgoNight: Towards egocentric vision understanding at night with a challenging benchmark
Deheng Zhang, Yuqian Fu, Runyi Yang, Yang Miao, Tianwen Qian, Xu Zheng, Guolei Sun, Ajad Chhatkuli, Xuanjing Huang, Yu-Gang Jiang, Luc Van Gool, and Danda Pani Paudel. EgoNight: Towards egocentric vision understanding at night with a challenging benchmark. In ICLR, 2026
work page 2026
-
[70]
Tenenbaum, Tianmin Shu, and Chuang Gan
Hongxin Zhang, Weihua Du, Jiaming Shan, Qinhong Zhou, Yilun Du, Joshua B. Tenenbaum, Tianmin Shu, and Chuang Gan. Building cooperative embodied agents modularly with large language models. InICLR, 2024
work page 2024
-
[71]
COMBO: Compositional world models for embodied multi-agent cooperation
Hongxin Zhang, Zeyuan Wang, Qiushi Lyu, Zheyuan Zhang, Sunli Chen, Tianmin Shu, Behzad Dariush, Kwonjoon Lee, Yilun Du, and Chuang Gan. COMBO: Compositional world models for embodied multi-agent cooperation. InICLR, 2025
work page 2025
-
[72]
LLaV A-NeXT: A strong zero-shot video understanding model, April 2024
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. LLaV A-NeXT: A strong zero-shot video understanding model, April 2024
work page 2024
-
[73]
Empowering Multi-Robot Cooperation via Sequential World Models
Zijie Zhao, Honglei Guo, Shengqian Chen, Kaixuan Xu, Bo Jiang, Yuanheng Zhu, and Dongbin Zhao. Empowering multi-robot cooperation via sequential world models.arXiv preprint arXiv:2509.13095, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
DeCoNav: Dialog enhanced Long-Horizon Collaborative Vision-Language Navigation
Sunyao Zhou, Yunzi Wu, Tianhang Wang, Xinhai Li, Guang Chen, Lizheng Liu, Chenjia Bai, and Xuelong Li. DeCoNav: Dialog enhanced long-horizon collaborative vision-language navigation.arXiv preprint arXiv:2604.12486, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[75]
Bingwen Zhu, Yuqian Fu, Qiaole Dong, Guolei Sun, Tianwen Qian, Yuzheng Wu, Danda Pani Paudel, Xiangyang Xue, and Yanwei Fu. EgoSound: Benchmarking sound understanding in egocentric videos. InCVPR, 2026. 14 A Technical Appendices and Supplementary Material A.1 Society Impact and Limitations This work advances cooperative spatial reasoning for multi-robot t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.