LMM-Track4D: Eliciting 4D Dynamic Reasoning in LMMs via Trajectory-Grounded Dialogue
Pith reviewed 2026-05-20 06:04 UTC · model grok-4.3
The pith
LMMs sustain 4D dynamic reasoning when given explicit 3D trajectory tracking components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
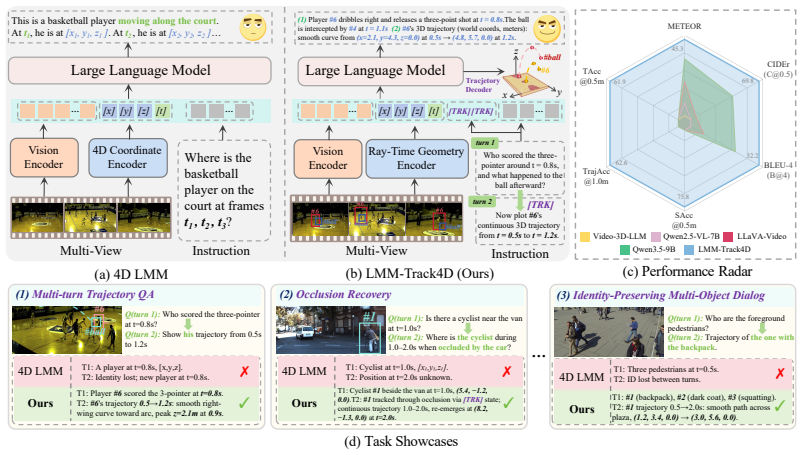
The authors claim that integrating ray-time geometry encoding, a streaming TRK token for state propagation, and an OSK-RA decoder for 3D state estimation enables large multimodal models to perform trajectory-grounded multi-turn spatiotemporal dialogue, with experiments on their Track4D-Bench showing consistent improvements over baselines that point to explicit dynamic state modeling as a key principle for 4D reasoning.
What carries the argument
RTGE for encoding geometry along rays over time, the TRK token for long-horizon dynamic state propagation, and the OSK-RA decoder for stable 4-step 3D estimation under occlusion.
If this is right
- Models return both natural language answers and structured 3D trajectories for queries about objects in video clips.
- Reasoning holds over entire short clips or specified segments of longer videos.
- State estimation remains stable despite occlusions and changes in camera viewpoint.
- Overall performance on spatiotemporal dialogue tasks increases when dynamic modeling is made explicit.
Where Pith is reading between the lines
- Similar explicit state mechanisms could help in other areas like predicting future object positions from partial video.
- Extending the approach might allow handling of even longer video sequences without losing track of objects.
- Applications in fields requiring persistent 3D awareness, such as autonomous navigation, could adopt these components.
Load-bearing premise
The benchmark performance gains are due to the ray-time geometry encoding, TRK token, and OSK-RA decoder specifically, not to unrelated choices in training or data selection.
What would settle it
An experiment that removes the TRK token or the RTGE while holding training data, schedule, and other elements fixed, and measures if accuracy on Track4D-Bench falls to the level of unmodified baselines.
Figures



read the original abstract
Recent large multimodal models (LMMs) have become increasingly capable on image and video understanding, yet still struggle to sustain 4D continuous spatiotemporal dynamic reasoning. To study this capability gap, we formulate trajectory-grounded multi-turn spatiotemporal dialogue, a new task in which a model must answer spatiotemporal queries while returning structured 3D target trajectories over an entire short clip or a specified segment of a longer clip, and introduce Track4D-Bench, a benchmark with 526 clip-level dialogue samples spanning 23.5k frames and 7.5k object annotations, for training and evaluation. Building on this task, we propose LMM-Track4D, which combines RTGE (Ray--Time Geometry Encoding), a dedicated streaming state token TRK for long-horizon dynamic propagation, and an Object-Slot Kinematic, Residual-Anchor (OSK-RA) decoder for stable 4-step 3D state estimation under occlusion and viewpoint variation. Experiments on Track4D-Bench show consistent improvements over strong baselines, suggesting that explicit dynamic state modeling is a useful design principle for eliciting 4D dynamic reasoning in LMMs. Our code and dataset will be publicly available at https://github.com/mikubaka88/LMM-Track4D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces trajectory-grounded multi-turn spatiotemporal dialogue as a new task for evaluating 4D dynamic reasoning in large multimodal models (LMMs). It presents Track4D-Bench, a benchmark with 526 clip-level dialogue samples across 23.5k frames and 7.5k object annotations. The proposed LMM-Track4D architecture incorporates Ray-Time Geometry Encoding (RTGE), a dedicated streaming TRK state token for long-horizon propagation, and an Object-Slot Kinematic Residual-Anchor (OSK-RA) decoder. Experiments on the benchmark are reported to show consistent improvements over strong baselines, supporting the claim that explicit dynamic state modeling aids 4D reasoning in LMMs. Code and dataset are to be released publicly.
Significance. If the performance gains can be causally attributed to the proposed components, the work offers a concrete design principle for improving spatiotemporal reasoning in LMMs along with a new benchmark and open resources that could facilitate further research in 4D video understanding. The emphasis on structured trajectory output and handling of occlusion/viewpoint changes addresses a recognized gap in current video LMMs.
major comments (2)
- [Experiments] Experiments section: The central claim that RTGE, the streaming TRK token, and OSK-RA decoder elicit 4D dynamic reasoning rests on observed improvements over baselines. However, the manuscript provides no component-wise ablations, no matched training protocols for baselines (e.g., identical schedule, data filtering, or prompt engineering), and no quantitative tables with metrics, error bars, or statistical significance. Without these, gains cannot be isolated from confounding implementation choices, weakening support for the dynamic-state hypothesis.
- [§3] §3 (Model) and Results: The description of the OSK-RA decoder for 'stable 4-step 3D state estimation' lacks explicit equations or pseudocode showing how residual anchoring interacts with the TRK token under occlusion; this makes it difficult to verify the claimed stability mechanism or reproduce the 4-step estimation process.
minor comments (3)
- [Abstract] Abstract: The statement 'consistent improvements' should be accompanied by at least one key metric (e.g., trajectory error or dialogue accuracy delta) to allow readers to gauge effect size without reading the full results section.
- [Benchmark] Benchmark description: Clarify the train/eval split ratios and whether any samples involve multi-object interactions or long-horizon clips beyond the stated 23.5k frames total.
- [§3] Notation: Define the exact input/output format of the TRK token (e.g., dimensionality and how it is injected into the LMM layers) more explicitly to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the work's potential impact. We address the major comments point by point below, outlining specific revisions to strengthen the experimental rigor and model clarity.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim that RTGE, the streaming TRK token, and OSK-RA decoder elicit 4D dynamic reasoning rests on observed improvements over baselines. However, the manuscript provides no component-wise ablations, no matched training protocols for baselines (e.g., identical schedule, data filtering, or prompt engineering), and no quantitative tables with metrics, error bars, or statistical significance. Without these, gains cannot be isolated from confounding implementation choices, weakening support for the dynamic-state hypothesis.
Authors: We agree that the current experimental presentation would benefit from greater rigor to isolate the contributions of our proposed components. In the revised manuscript, we will add component-wise ablation studies that systematically remove or modify RTGE, the TRK streaming token, and the OSK-RA decoder while keeping all other factors fixed. We will also retrain the baselines under fully matched protocols (identical optimizer schedule, data filtering criteria, and prompt templates) and report full quantitative tables including per-metric scores, error bars or standard deviations across multiple runs, and statistical significance tests (e.g., paired t-tests or Wilcoxon tests). These additions will provide clearer causal evidence for the value of explicit dynamic state modeling. revision: yes
-
Referee: [§3] §3 (Model) and Results: The description of the OSK-RA decoder for 'stable 4-step 3D state estimation' lacks explicit equations or pseudocode showing how residual anchoring interacts with the TRK token under occlusion; this makes it difficult to verify the claimed stability mechanism or reproduce the 4-step estimation process.
Authors: We acknowledge that the current textual description of the OSK-RA decoder can be made more precise and reproducible. In the revision, we will insert explicit mathematical equations defining the residual anchoring operation, its fusion with the TRK state token, and the update rules across the four estimation steps. We will also provide pseudocode that illustrates the handling of occlusion and viewpoint variation, showing how the anchor residuals are computed and propagated to maintain stability. These additions will directly address the request for verifiable details on the stability mechanism. revision: yes
Circularity Check
No circularity: empirical engineering contribution with independent benchmark evaluation
full rationale
The paper formulates a new task (trajectory-grounded multi-turn spatiotemporal dialogue), releases Track4D-Bench (526 samples, 23.5k frames), and proposes LMM-Track4D with three components (RTGE encoding, streaming TRK token, OSK-RA decoder). The central claim of improved 4D reasoning is supported by reported performance gains over baselines on the new benchmark. No equations, fitted parameters renamed as predictions, self-definitional reductions, or load-bearing self-citations appear in the abstract or described derivation. The work is self-contained as an empirical model proposal whose validity rests on external benchmark results rather than internal redefinition of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions about the availability and quality of 3D object annotations in video clips for training multimodal models.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Meteor: An automatic metric for mt evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005
work page 2005
-
[4]
Federico Castanedo, Jesus Garcia, Miguel A Patricio, and José M Molina. A multi-agent architecture based on the bdi model for data fusion in visual sensor networks.Journal of Intelligent & Robotic Systems, 62(3):299–328, 2011
work page 2011
-
[5]
Wildtrack: A multi-camera hd dataset for dense unscripted pedestrian detection
Tatjana Chavdarova, Pierre Baqué, Stéphane Bouquet, Andrii Maksai, Cijo Jose, Timur Bagaut- dinov, Louis Lettry, Pascal Fua, Luc Van Gool, and François Fleuret. Wildtrack: A multi-camera hd dataset for dense unscripted pedestrian detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5030–5039, 2018
work page 2018
-
[6]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. SpatialVLM: Endowing vision-language models with spatial reasoning capabilities. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14455–14465. IEEE. ISBN 979-8-3503-5300-6. doi: 10.1109/CVPR52733.2024.01370
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Jiajun Deng, Tianyu He, Li Jiang, Tianyu Wang, Feras Dayoub, and Ian Reid. 3D-LLaV A: Towards generalist 3D LMMs with omni superpoint transformer. pages 1–11. doi: 10.1109/ CVPR52734.2025.00357
-
[9]
Henghui Ding, Chang Liu, Shuting He, Xudong Jiang, and Chen Change Loy. MeViS: A large-scale benchmark for video segmentation with motion expressions. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2694–2703. IEEE. ISBN 979-8- 3503-0718-4. doi: 10.1109/ICCV51070.2023.00254
-
[10]
Jiayu Ding, Xinpeng Liu, Zhiyi Pan, Shiqiang Long, and Ge Li. Extrinsplat: Decoupling geometry and semantics for open-vocabulary understanding in 3d gaussian splatting.arXiv preprint arXiv:2509.22225, 2026
-
[11]
3D Instruction Ambiguity Detection
Jiayu Ding, Haoran Tang, Hongbo Jin, Wei Gao, and Ge Li. 3d instruction ambiguity detection. arXiv preprint arXiv:2601.05991, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The international journal of robotics research, 32(11):1231–1237, 2013
work page 2013
-
[13]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[14]
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al. Chat-scene: Bridging 3d scene and large language models with object identifiers.Advances in Neural Information Processing Systems, 37:113991–114017, 2024. 10
work page 2024
-
[15]
Under- standing dynamic scenes in ego centric 4d point clouds
Junsheng Huang, Shengyu Hao, Bo-Cheng Hu, Hongwei Wang, and Gaoang Wang. Under- standing dynamic scenes in ego centric 4d point clouds. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 5031–5039, 2026
work page 2026
-
[16]
Ting Huang, Zeyu Zhang, and Hao Tang. 3d-r1: Enhancing reasoning in 3d vlms for unified scene understanding.arXiv preprint arXiv:2507.23478, 2025
-
[17]
Yuzhi Huang, Kairun Wen, Rongxin Gao, Dongxuan Liu, Yibin Lou, Jie Wu, Jing Xu, Jian Zhang, Zheng Yang, Yunlong Lin, et al. Thinking in dynamics: How multimodal large language models perceive, track, and reason dynamics in physical 4d world.arXiv preprint arXiv:2603.12746, 2026
-
[18]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models.arXiv preprint arXiv:2506.03135, 2025
-
[20]
Hongbo Jin, Qingyuan Wang, Wenhao Zhang, Yang Liu, and Sijie Cheng. Videomem: En- hancing ultra-long video understanding via adaptive memory management.arXiv preprint arXiv:2512.04540, 2025
-
[21]
Hongbo Jin, Jiayu Ding, Siyi Xie, Guibo Luo, and Ge Li. Vista: Mitigating semantic inertia in video-llms via training-free dynamic chain-of-thought routing.arXiv preprint arXiv:2505.11830, 2026
-
[22]
Tir-flow: Active video search and reasoning with frozen vlms.arXiv preprint arXiv:2601.06176, 2026
Hongbo Jin, Siyi Xie, Jiayu Ding, Kuanwei Lin, and Ge Li. Tir-flow: Active video search and reasoning with frozen vlms.arXiv preprint arXiv:2601.06176, 2026
-
[23]
HiMAC: Hierarchical Macro-Micro Learning for Long-Horizon LLM Agents
Hongbo Jin, Rongpeng Zhu, Jiayu Ding, Wenhao Zhang, and Ge Li. Himac: Hierarchical macro-micro learning for long-horizon llm agents.arXiv preprint arXiv:2603.00977, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
Hongbo Jin, Rongpeng Zhu, Zhongjing Du, Xu Jiang, Jingqi Tian, Qiaoman Zhang, and Jiayu Ding. Dgpo: Distribution guided policy optimization for fine grained credit assignment.arXiv preprint arXiv:2605.03327, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Linyi Jin, Richard Tucker, Zhengqi Li, David Fouhey, Noah Snavely, and Aleksander Hołynski. Stereo4D: Learning how things move in 3D from internet stereo videos. pages 1–18. doi: 10.1109/CVPR52734.2025.00982
-
[26]
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. DynamicStereo: Consistent dynamic depth from stereo videos. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13229– 13239. IEEE. ISBN 979-8-3503-0129-8. doi: 10.1109/CVPR52729.2023.01271
-
[27]
Junlong Ke, Zichen Wen, Boxue Yang, Yantai Yang, Xuyang Liu, Chenfei Liao, Zhaorun Chen, Shaobo Wang, and Linfeng Zhang. Flash-unified: A training-free and task-aware acceleration framework for native unified models.arXiv preprint arXiv:2603.15271, 2026
-
[28]
Llava-st: A multimodal large language model for fine-grained spatial-temporal understanding
Hongyu Li, Jinyu Chen, Ziyu Wei, Shaofei Huang, Tianrui Hui, Jialin Gao, Xiaoming Wei, and Si Liu. Llava-st: A multimodal large language model for fine-grained spatial-temporal understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8592–8603, 2025
work page 2025
-
[29]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[30]
VideoChat : Chat-centric video understanding
Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. VideoChat : Chat-centric video understanding. pages 1–16. doi: 10.1007/ s11432-024-4321-9. 11
-
[31]
doi: 10.18653/v1/2024.emnlp-main.342
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning united visual representation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5971–5984. Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.342
-
[32]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
work page 2002
-
[33]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
work page 2026
-
[34]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Cider: Consensus-based image description evaluation
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015
work page 2015
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Com- positional 4d dynamic scenes understanding with physics priors for video question answering
Xingrui Wang, Wufei Ma, Angtian Wang, Shuo Chen, Adam Kortylewski, and Alan Yuille. Com- positional 4d dynamic scenes understanding with physics priors for video question answering. InInternational Conference on Learning Representations, volume 2025, pages 93688–93700, 2025
work page 2025
-
[38]
Yiyu Wang, Xuyang Liu, Xiyan Gui, Xinying Lin, Boxue Yang, Chenfei Liao, Tailai Chen, and Linfeng Zhang. Accelerating streaming video large language models via hierarchical token compression.arXiv preprint arXiv:2512.00891, 2025
-
[39]
Ai for service: Proactive assistance with ai glasses.arXiv preprint arXiv:2510.14359, 2025
Zichen Wen, Yiyu Wang, Chenfei Liao, Boxue Yang, Junxian Li, Weifeng Liu, Haocong He, Bolong Feng, Xuyang Liu, Yuanhuiyi Lyu, et al. Ai for service: Proactive assistance with ai glasses.arXiv preprint arXiv:2510.14359, 2025
-
[40]
Zichen Wen, Boxue Yang, Shuang Chen, Yaojie Zhang, Yuhang Han, Junlong Ke, Cong Wang, Yicheng Fu, Jiawang Zhao, Jiangchao Yao, et al. Innovator-vl: A multimodal large language model for scientific discovery.arXiv preprint arXiv:2601.19325, 2026
-
[41]
EvoStreaming: Your Offline Video Model Is a Natively Streaming Assistant
Zichen Wen, Boxue Yang, Junlong Ke, Jiajie Huang, Chenfei Liao, Junxi Wang, Xuyang Liu, and Linfeng Zhang. Evostreaming: Your offline video model is a natively streaming assistant. arXiv preprint arXiv:2605.10343, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.Advances in neural information processing systems, 38:13569–13597, 2026
work page 2026
-
[43]
VISA: Reasoning video object segmentation via large language models
Cilin Yan, Haochen Wang, Shilin Yan, Xiaolong Jiang, Yao Hu, Guoliang Kang, Weidi Xie, and Efstratios Gavves. VISA: Reasoning video object segmentation via large language models. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision – ECCV 2024, volume 15073, pages 98–115. Springer Nature Sw...
-
[44]
Mllm-4d: Towards visual-based spatial-temporal intelligence.arXiv preprint arXiv:2603.00515, 2026
Xingyilang Yin, Chengzhengxu Li, Jiahao Chang, Chi-Man Pun, and Xiaodong Cun. Mllm-4d: Towards visual-based spatial-temporal intelligence.arXiv preprint arXiv:2603.00515, 2026
-
[45]
Jiahui Zhang, Yurui Chen, Yueming Xu, Ze Huang, Jilin Mei, Chunhui Chen, Yanpeng Zhou, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, et al. From flatland to space: Teaching vision- language models to perceive and reason in 3d.Advances in Neural Information Processing Systems, 38, 2026. 12
work page 2026
-
[46]
Llava-next: A strong zero-shot video understanding model, April 2024
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model, April 2024. URL https://llava-vl.github.io/blog/2024-04-30-llava-next-video/
work page 2024
-
[47]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava- video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3D LLM: Learning position-aware video representation for 3D scene understanding. pages 1–14, . doi: 10.1109/CVPR52734.2025.00841
-
[49]
Duo Zheng, Yanyang Li, Liwei Wang, et al. Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors.Advances in neural information processing systems, 38: 20560–20586, 2026
work page 2026
-
[50]
Yang Zheng, Adam W. Harley, Bokui Shen, Gordon Wetzstein, and Leonidas J. Guibas. PointOdyssey: A large-scale synthetic dataset for long-term point tracking. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 19798–19808. IEEE, . ISBN 979-8-3503-0718-4. doi: 10.1109/ICCV51070.2023.01818
-
[51]
Llava-4d: Embedding spatiotemporal prompt into lmms for 4d scene understanding
Hanyu Zhou and Gim Hee Lee. Llava-4d: Embedding spatiotemporal prompt into lmms for 4d scene understanding. InThe Fourteenth International Conference on Learning Representations, 2025
work page 2025
-
[52]
Hanyu Zhou and Gim Hee Lee. Uni4d-llm: A unified spatiotemporal-aware vlm for 4d understanding and generation.arXiv preprint arXiv:2509.23828, 2025
-
[53]
Motion4D: Learning 3D-consistent motion and semantics for 4D scene understanding
Haoran Zhou and Gim Hee Lee. Motion4D: Learning 3D-consistent motion and semantics for 4D scene understanding. pages 1–20
-
[54]
Vlm4d: Towards spatiotem- poral awareness in vision language models
Shijie Zhou, Alexander Vilesov, Xuehai He, Ziyu Wan, Shuwang Zhang, Aditya Nagachandra, Di Chang, Dongdong Chen, Xin Eric Wang, and Achuta Kadambi. Vlm4d: Towards spatiotem- poral awareness in vision language models. InProceedings of the IEEE/CVF international conference on computer vision, pages 8600–8612, 2025
work page 2025
-
[55]
LLaV A-3D: A simple yet effective pathway to empowering LMMs with 3D capabilities
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. LLaV A-3D: A simple yet effective pathway to empowering LMMs with 3D capabilities. pages 1–18. doi: 10.1109/ICCV51701.2025.00409. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.