Extracting Training Data from Diffusion Language Models via Infilling
Pith reviewed 2026-06-30 15:53 UTC · model grok-4.3
The pith
Diffusion language models leak up to three times more verbatim training sequences when extraction uses infilling masks instead of prefixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
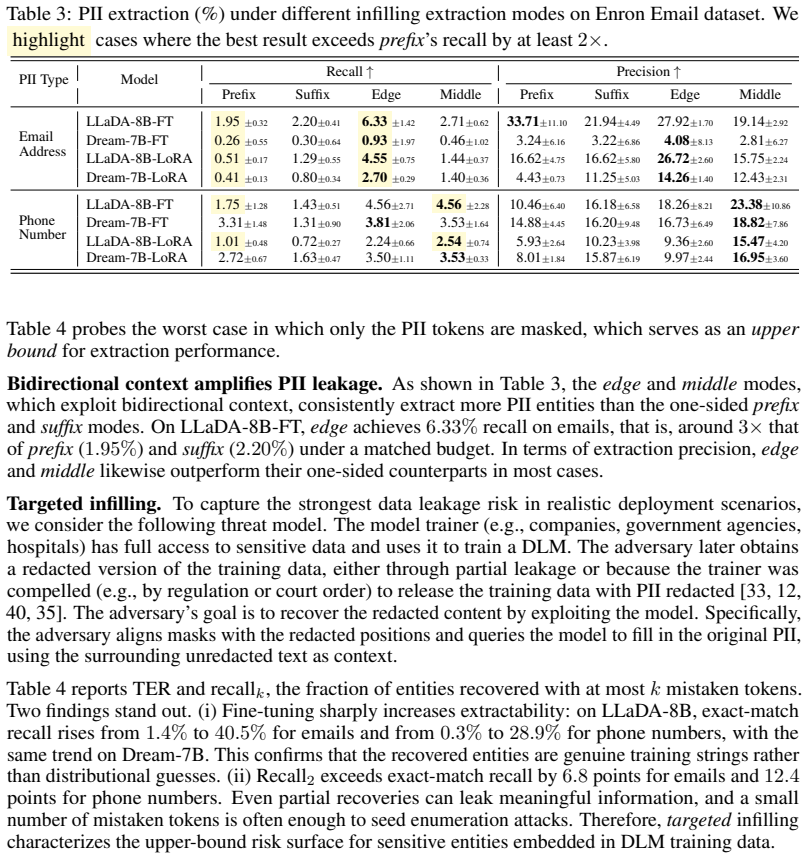
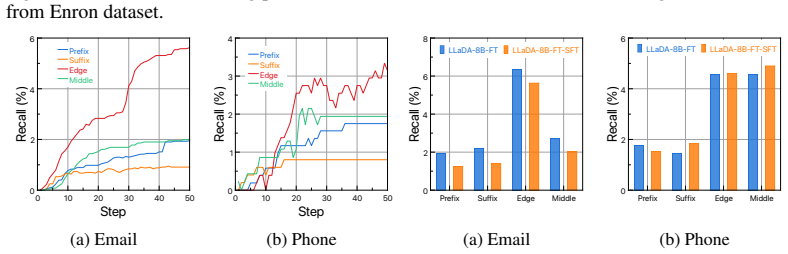
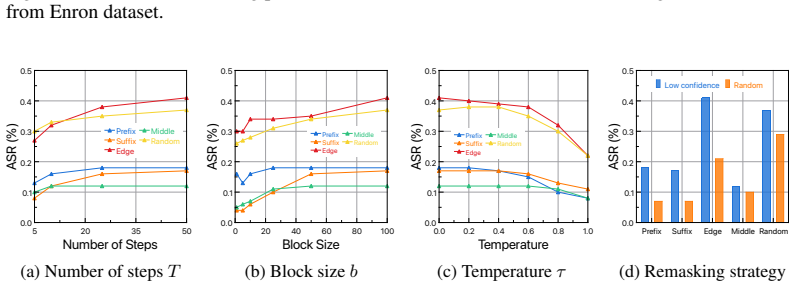
Infilling extraction, parameterized by arbitrary binary masks, shows that mask geometry governs extractability in diffusion language models: edge-conditioned masks extract up to three times more verbatim sequences than prefix-conditioned ones. Bidirectional access opens channels inaccessible in autoregressive models, enabling a realistic adversary with redacted training data to achieve higher recall on extracting email addresses from DLMs than from scale-matched autoregressive models. Tunable decoding parameters affect extraction rates while a subsequent supervised finetuning stage leaves prior memorization intact.
What carries the argument
Infilling extraction: a data-extraction protocol that applies an arbitrary binary mask to diffusion language models, allowing token recovery at any positions rather than only from a left-to-right prefix.
If this is right
- Mask geometry, not merely model scale, determines how much training data can be recovered from diffusion language models.
- Prefix-only tests systematically underestimate memorization risk in diffusion language models.
- Adversaries holding partial or redacted training data can extract more from diffusion language models than from autoregressive counterparts.
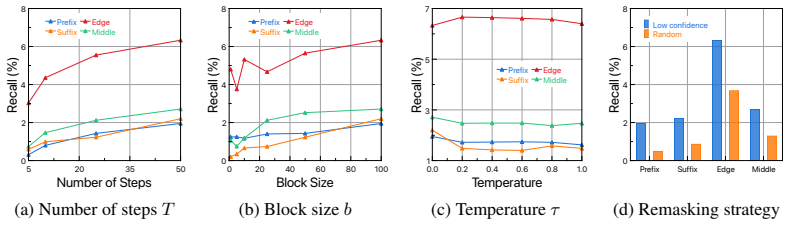
- Tuning of decoding parameters during extraction measurably changes success rates.
- A supervised finetuning stage after initial training does not remove the memorization that enables extraction.
Where Pith is reading between the lines
- Evaluation protocols for memorization in non-autoregressive models will need to test multiple mask geometries to be considered complete.
- Applications that handle sensitive data may face different privacy trade-offs when switching from autoregressive to diffusion language models.
- Defenses developed for prefix-based extraction may leave residual channels open when applied to diffusion language models.
- The same mask-based probing approach could be applied to other bidirectional or non-autoregressive architectures to check for similar extractability patterns.
Load-bearing premise
The chosen extraction modes, mask geometries, and corpora accurately reflect the access and capabilities a realistic adversary would have when targeting deployed diffusion language models.
What would settle it
Run the same set of edge-conditioned and prefix masks on a diffusion language model and a scale-matched autoregressive model trained on identical redacted data; if recall on redacted email addresses is not higher for the diffusion model, the central claim on bidirectional advantage fails.
Figures

read the original abstract
Memorization in large language models has been studied almost exclusively through prefix-conditioned extraction, a natural choice for autoregressive models. However, diffusion language models (DLMs) can denoise masked tokens at arbitrary positions. Thus, prefix-only probing reveals only one facet of memorization in DLMs and significantly underestimates the risk of training-data extraction. In order to realistically model extractability of training data in DLMs, we introduce \emph{infilling extraction}, a data-extraction protocol parameterized by an arbitrary binary mask that subsumes prefix-only probing and accounts for the bidirectional inductive bias of DLMs. Instantiating it on LLaDA-8B and Dream-7B across five extraction modes, three training pipelines, and three corpora covering verbatim and partial leakage, we find that mask geometry governs extractability: edge-conditioned masks \emph{extract up to three times more} verbatim sequences than prefix-conditioned ones, and bidirectional access opens channels inaccessible in autoregressive models. In particular, we show that a realistic adversary with access to training data where personally identifiable information has been redacted, can even achieve higher recall on extracting redacted email addresses from DLMs than from scale-matched autoregressive models. Tunable parameters for decoding measurably affect extraction performance, while a follow-up supervised finetuning stage does not eliminate the prior memorization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that diffusion language models (DLMs) allow substantially higher training-data extraction than previously measured because they support infilling at arbitrary positions. It introduces an infilling-extraction protocol parameterized by binary masks, shows on LLaDA-8B and Dream-7B that edge-conditioned masks recover up to three times more verbatim sequences than prefix-conditioned masks, and reports that a realistic adversary supplied with redacted-PII training data can extract redacted email addresses at higher recall from DLMs than from scale-matched autoregressive models. The results are obtained across five extraction modes, three training pipelines, and three corpora.
Significance. If the empirical findings hold, the work is significant because it demonstrates that standard prefix-only probing systematically underestimates memorization risk in bidirectional models and that mask geometry is a first-order determinant of extractability. The redacted-PII experiment directly addresses a practical privacy threat. The multi-model, multi-pipeline design and explicit comparison to autoregressive baselines are strengths that make the central claim falsifiable.
major comments (2)
- [Abstract] Abstract: the assertion that the five extraction modes and three corpora 'realistically model' an adversary's capabilities is load-bearing for both the 3× verbatim claim and the redacted-email recall gap, yet the manuscript provides no evidence that arbitrary mask control (as opposed to prefix/suffix or fixed-length infilling) is attainable under typical deployment constraints.
- [Abstract] Abstract: the quantitative statements ('up to three times more', 'higher recall') are presented without accompanying tables, confidence intervals, or statistical tests in the summary; because these numbers are the primary support for the claim that 'mask geometry governs extractability,' their robustness cannot be assessed from the provided information.
minor comments (1)
- [Abstract] The abstract introduces LLaDA-8B and Dream-7B only in the final sentence; moving the model names earlier would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our work. The two major comments focus on the framing of the adversary model in the abstract and the presentation of quantitative claims. We address each point below with proposed revisions to improve clarity and precision without altering the core empirical contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the five extraction modes and three corpora 'realistically model' an adversary's capabilities is load-bearing for both the 3× verbatim claim and the redacted-email recall gap, yet the manuscript provides no evidence that arbitrary mask control (as opposed to prefix/suffix or fixed-length infilling) is attainable under typical deployment constraints.
Authors: We agree that the phrasing 'realistically model' in the abstract is imprecise and that the manuscript does not demonstrate the availability of arbitrary mask control in typical closed deployments. The intent was to show that prefix-only extraction underestimates risk for bidirectional models when infilling is possible. In revision we will replace the phrase with 'model an adversary with infilling access' and add a short discussion paragraph on deployment contexts (open-weight models, fine-tuned checkpoints, or APIs exposing infilling) where such access could occur. This qualifies the claim without changing the experimental results. revision: yes
-
Referee: [Abstract] Abstract: the quantitative statements ('up to three times more', 'higher recall') are presented without accompanying tables, confidence intervals, or statistical tests in the summary; because these numbers are the primary support for the claim that 'mask geometry governs extractability,' their robustness cannot be assessed from the provided information.
Authors: The abstract is a high-level summary; the supporting tables, per-model breakdowns, and multi-run results appear in Sections 4–5. We acknowledge that the abstract alone does not convey robustness. We will revise it to add a brief qualifier directing readers to the experimental sections and will ensure the main text reports confidence intervals or statistical tests for the key comparisons if they are not already present. The multi-model, multi-corpus design already provides some robustness evidence. revision: partial
Circularity Check
No circularity: empirical extraction measurements are self-contained
full rationale
The paper defines infilling extraction as a new protocol parameterized by binary masks and reports direct empirical measurements of verbatim recovery rates across five modes, three pipelines, and three corpora on LLaDA-8B and Dream-7B. Central claims (edge masks yield up to 3× more recovery; DLMs outperform AR models on redacted emails) rest on these measurements rather than any derivation, fitted parameter renamed as prediction, or self-citation chain. No equations or uniqueness theorems are invoked that reduce to the paper's own inputs; the work is an experimental study whose validity hinges on external benchmarks and assumptions about adversary access, not internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://deepmind.google/models/gemini-diffusion/
Gemini Diffusion. https://deepmind.google/models/gemini-diffusion/
-
[2]
Block diffusion: Interpolating between autoregressive and diffusion language models
Marianne Arriola, Subham Sekhar Sahoo, Aaron Gokaslan, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Justin T Chiu, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=tyEyYT267x
2025
-
[3]
Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
2021
-
[4]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21), pages 2633–2650, 2021
2021
-
[7]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview. net/forum?id=TatRHT_1cK
2023
-
[8]
Tracedet: Hallucination detection from the decoding trace of diffusion large language models
Shenxu Chang, Junchi Yu, Weixing Wang, Yongqiang Chen, Jialin Yu, Philip Torr, and Jindong Gu. Tracedet: Hallucination detection from the decoding trace of diffusion large language models. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=4puxTouUSV
2026
-
[9]
Membership inference attacks against fine-tuned diffusion language models
Yuetian Chen, Kaiyuan Zhang, Yuntao Du, Edoardo Stoppa, Charles Fleming, Ashish Kundu, Bruno Ribeiro, and Ninghui Li. Membership inference attacks against fine-tuned diffusion language models. InThe Fourteenth International Conference on Learning Representations,
-
[10]
URLhttps://openreview.net/forum?id=oWKJursYpW
-
[11]
Partition generative modeling: Masked mod- eling without masks
Justin Deschenaux, Lan Tran, and Caglar Gulcehre. Partition generative modeling: Masked mod- eling without masks. InThe Fourteenth International Conference on Learning Representations,
-
[12]
URLhttps://openreview.net/forum?id=vEh1ceS154
-
[13]
Do membership inference attacks work on large language models? InConference on Language Modeling (COLM), 2024
Michael Duan, Anshuman Suri, Niloofar Mireshghallah, Sewon Min, Weijia Shi, Luke Zettle- moyer, Yulia Tsvetkov, Yejin Choi, David Evans, and Hannaneh Hajishirzi. Do membership inference attacks work on large language models? InConference on Language Modeling (COLM), 2024
2024
-
[14]
General data protection regulation, 2016
European Union. General data protection regulation, 2016. URL https://eur-lex.europa. eu/eli/reg/2016/679/oj. Regulation (EU) 2016/679
2016
-
[15]
Unlocking Prompt Infilling Capability for Diffusion Language Models
Yoshinari Fujinuma and Keisuke Sakaguchi. Unlocking prompt infilling capability for diffusion language models.arXiv preprint arXiv:2604.03677, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Scaling diffusion language models via adaptation from autoregressive models
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, Hao Peng, and Lingpeng Kong. Scaling diffusion language models via adaptation from autoregressive models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=j1tSLYKwg8
2025
-
[17]
Measuring memorization in language models via probabilistic extraction
Jamie Hayes, Marika Swanberg, Harsh Chaudhari, Itay Yona, Ilia Shumailov, Milad Nasr, Christopher A Choquette-Choo, Katherine Lee, and A Feder Cooper. Measuring memorization in language models via probabilistic extraction. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human La...
2025
-
[18]
Diffusionbert: Improving generative masked language models with diffusion models
Zhengfu He, Tianxiang Sun, Qiong Tang, Kuanning Wang, Xuan-Jing Huang, and Xipeng Qiu. Diffusionbert: Improving generative masked language models with diffusion models. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 4521–4534, 2023
2023
-
[19]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=nZeVKeeFYf9
2022
-
[20]
Accelerating diffusion LLMs via adaptive parallel decoding
Daniel Mingyi Israel, Guy Van den Broeck, and Aditya Grover. Accelerating diffusion LLMs via adaptive parallel decoding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=xwqTt26NJf
2026
-
[21]
Copyright violations and large language models
Antonia Karamolegkou, Jiaang Li, Li Zhou, and Anders Søgaard. Copyright violations and large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7403–7412, 2023
2023
-
[22]
The enron corpus: A new dataset for email classification research
Bryan Klimt and Yiming Yang. The enron corpus: A new dataset for email classification research. InEuropean conference on machine learning, pages 217–226. Springer, 2004
2004
-
[23]
Mercury: Ultra-Fast Language Models Based on Diffusion
Inception Labs, Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, et al. Mercury: Ultra-fast language models based on diffusion.arXiv preprint arXiv:2506.17298, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Deduplicating training data makes language mod- els better
Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. Deduplicating training data makes language mod- els better. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8424–8445, 2022
2022
-
[26]
Breaking AR’s sampling bottleneck: Provable acceleration via diffusion language models
Gen Li and Changxiao Cai. Breaking AR’s sampling bottleneck: Provable acceleration via diffusion language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=to1VYVar9W
2026
-
[27]
Diffusion language model knows the answer before it decodes
Pengxiang Li, Yefan Zhou, Dilxat Muhtar, Lu Yin, Shilin Yan, Li Shen, Yi Liang, Soroush V osoughi, and Shiwei Liu. Diffusion language model knows the answer before it decodes. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=g88nt4ieTG
2026
-
[28]
A Survey on Diffusion Language Models
Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. A survey on diffusion language models.arXiv preprint arXiv:2508.10875, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Diffusion-lm improves controllable text generation.Advances in neural information processing systems, 35:4328–4343, 2022
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. Diffusion-lm improves controllable text generation.Advances in neural information processing systems, 35:4328–4343, 2022. 11
2022
-
[30]
Analyzing leakage of personally identifiable information in language models
Nils Lukas, Ahmed Salem, Robert Sim, Shruti Tople, Lukas Wutschitz, and Santiago Zanella- Béguelin. Analyzing leakage of personally identifiable information in language models. In 2023 IEEE Symposium on Security and Privacy (SP), pages 346–363. IEEE, 2023
2023
-
[31]
Xiaoyu Luo, Wenrui Yu, Qiongxiu Li, and Johannes Bjerva. Characterizing memorization in diffusion language models: Generalized extraction and sampling effects.arXiv preprint arXiv:2603.02333, 2026
-
[32]
Microsoft Presidio: Context aware, pluggable and customizable PII anonymization service for text and images.https://microsoft.github.io/presidio, 2018
Omri Mendels, Coby Peled, Nava Vaisman Levy, Sharon Hart, Tomer Rosenthal, Limor Lahiani, et al. Microsoft Presidio: Context aware, pluggable and customizable PII anonymization service for text and images.https://microsoft.github.io/presidio, 2018
2018
-
[33]
Feder Cooper, Daphne Ippolito, Christopher A
Milad Nasr, Javier Rando, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, Florian Tramèr, and Katherine Lee. Scalable extraction of training data from aligned, production language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openrev...
2025
-
[34]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2026. URL https: //openreview.net/forum?id=KnqiC0znVF
2026
-
[35]
Guidance regarding methods for de-identification of protected health information in accordance with the health insurance portability and accountability act (hipaa) privacy rule
Office for Civil Rights. Guidance regarding methods for de-identification of protected health information in accordance with the health insurance portability and accountability act (hipaa) privacy rule. Technical report, U.S. Department of Health and Human Services, 2012. URL https://www.hhs.gov/hipaa/for-professionals/privacy/special-topics/ de-identification/
2012
-
[36]
Yanyu Qian, Yue Tan, Yixin Liu, Wang Yu, and Shirui Pan. Dynhd: Hallucination detection for diffusion large language models via denoising dynamics deviation learning.arXiv preprint arXiv:2603.16459, 2026
-
[37]
Balancing innovation and oversight: Ai in the us treasury and irs: A survey
Sohail Shaikh. Balancing innovation and oversight: Ai in the us treasury and irs: A survey. arXiv preprint arXiv:2509.16294, 2025
-
[38]
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Self- conditioned embedding diffusion for text generation.arXiv preprint arXiv:2211.04236, 2022
Robin Strudel, Corentin Tallec, Florent Altché, Yilun Du, Yaroslav Ganin, Arthur Mensch, Will Grathwohl, Nikolay Savinov, Sander Dieleman, Laurent Sifre, et al. Self-conditioned embedding diffusion for text generation.arXiv preprint arXiv:2211.04236, 2022
-
[40]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Exploring Cross-Client Memorization of Training Data in Large Language Models for Federated Learning
Tinnakit Udsa, Can Udomcharoenchaikit, Patomporn Payoungkhamdee, Sarana Nutanong, and Norrathep Rattanavipanon. Exploring cross-client memorization of training data in large language models for federated learning.arXiv preprint arXiv:2510.08750, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Department of the Treasury
U.S. Department of the Treasury. Treasury and artificial in- telligence. https://home.treasury.gov/policy-issues/ financial-markets-financial-institutions-and-fiscal-service/ treasury-and-artificial-intelligence, 2026. Accessed: 2026-05-05
2026
-
[43]
The devil behind the mask: An emergent safety vulnerability of diffusion LLMs
Zichen Wen, Jiashu Qu, Zhaorun Chen, Xiaoya Lu, Dongrui Liu, Zhiyuan Liu, Ruixi Wu, Yicun Yang, Xiangqi Jin, Haoyun Xu, Xuyang Liu, Weijia Li, Chaochao Lu, Jing Shao, Conghui He, and Linfeng Zhang. The devil behind the mask: An emergent safety vulnerability of diffusion LLMs. InThe Fourteenth International Conference on Learning Representations, 2026. URL...
2026
-
[44]
Fast-dLLM: Training-free acceleration of diffusion LLM by enabling KV cache and parallel decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dLLM: Training-free acceleration of diffusion LLM by enabling KV cache and parallel decoding. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=3Z3Is6hnOT
2026
-
[45]
Alexander Xiong, Xuandong Zhao, Aneesh Pappu, and Dawn Song. The landscape of memo- rization in llms: Mechanisms, measurement, and mitigation.arXiv preprint arXiv:2507.05578, 2025
-
[46]
Energy-based diffusion language models for text generation
Minkai Xu, Tomas Geffner, Karsten Kreis, Weili Nie, Yilun Xu, Jure Leskovec, Stefano Ermon, and Arash Vahdat. Energy-based diffusion language models for text generation. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=sL2F9YCMXf
2025
-
[47]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Bag of tricks for training data extraction from language models
Weichen Yu, Tianyu Pang, Qian Liu, Chao Du, Bingyi Kang, Yan Huang, Min Lin, and Shuicheng Yan. Bag of tricks for training data extraction from language models. InInternational Conference on Machine Learning, pages 40306–40320. PMLR, 2023
2023
-
[49]
Exploring memorization in fine-tuned language models
Shenglai Zeng, Yaxin Li, Jie Ren, Yiding Liu, Han Xu, Pengfei He, Yue Xing, Shuaiqiang Wang, Jiliang Tang, and Dawei Yin. Exploring memorization in fine-tuned language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3917–3948, 2024
2024
-
[50]
Jailbreaking large language diffusion models: Revealing hidden safety flaws in diffusion-based text generation
Yuanhe Zhang, Fangzhou Xie, Zhenhong Zhou, Zherui Li, Hao Chen, Kun Wang, and Yufei Guo. Jailbreaking large language diffusion models: Revealing hidden safety flaws in diffusion-based text generation. InSocially Responsible and Trustworthy Foundation Models at NeurIPS 2025,
2025
-
[51]
URLhttps://openreview.net/forum?id=NWvL280s2l
-
[52]
d1: Scaling reasoning in diffusion large language models via reinforcement learning
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling reasoning in diffusion large language models via reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=7ZVRlBFuEv
2026
-
[53]
dllm: Simple diffusion language modeling.arXiv preprint arXiv:2602.22661, 2026
Zhanhui Zhou, Lingjie Chen, Hanghang Tong, and Dawn Song. dllm: Simple diffusion language modeling.arXiv preprint arXiv:2602.22661, 2026. 13 A Experimental Settings A.1 Datasets Following prior work [48], we fine-tune models on thefull pilesubset of the MIMIR dataset, which contains 10K sequences. To evaluate verbatim extraction, we randomly sample 5,000 ...
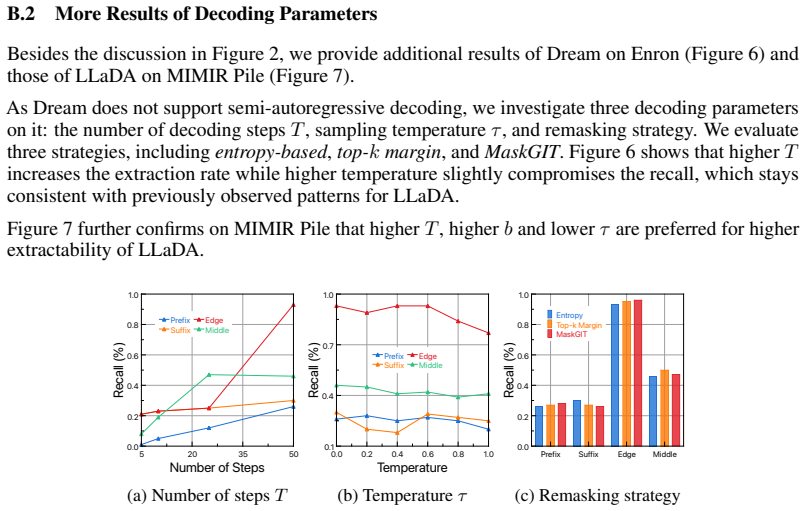
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.