SparseWorld: Enhancing End-to-End Autonomous Driving via World Models with Sparse Scene Representation
Pith reviewed 2026-06-30 14:02 UTC · model grok-4.3
The pith
A world model that predicts only critical map elements and agents improves trajectory planning safety in end-to-end autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
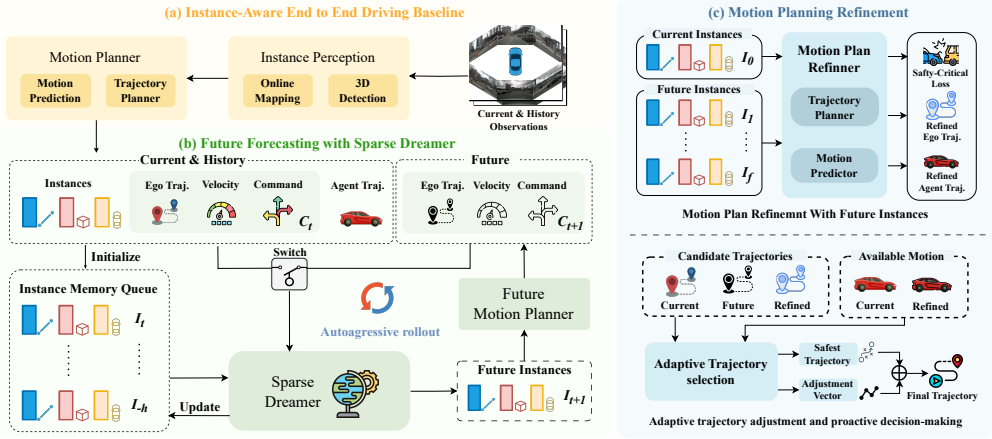
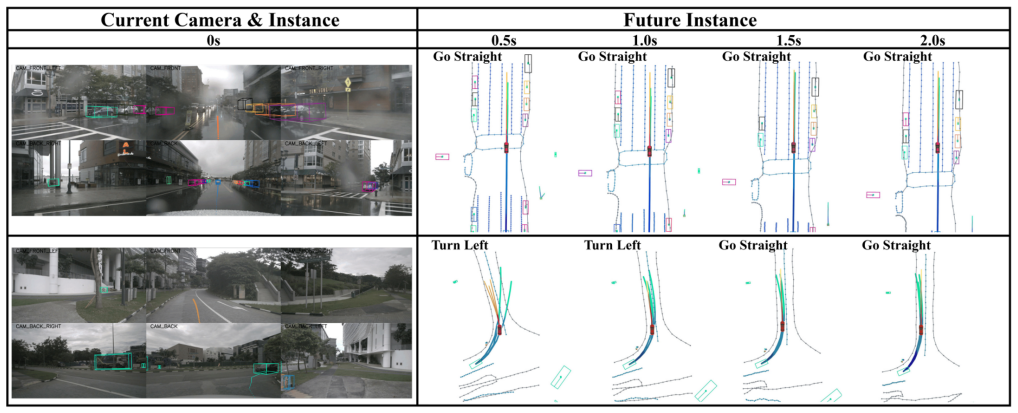
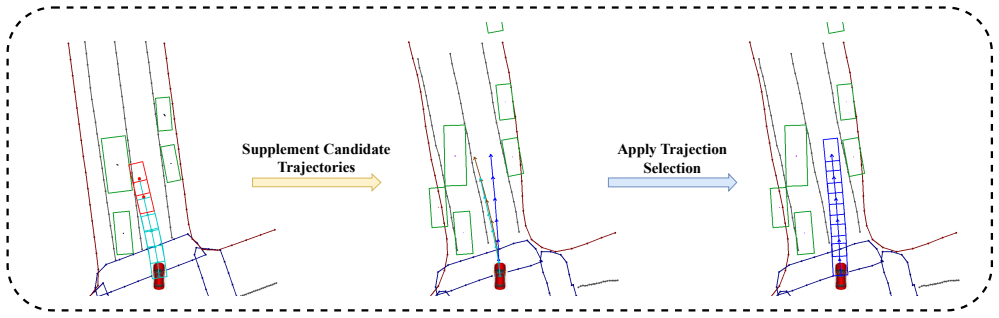
SparseWorld shows that autoregressive rollout of future instances in latent space through joint temporal and spatial attention, followed by interaction with the motion planner, produces more accurate motion patterns and safety-aware trajectories than dense representations, reaching a 0.05% collision rate on nuScenes open-loop planning and outperforming the baseline on closed-loop metrics of Bench2Drive.
What carries the argument
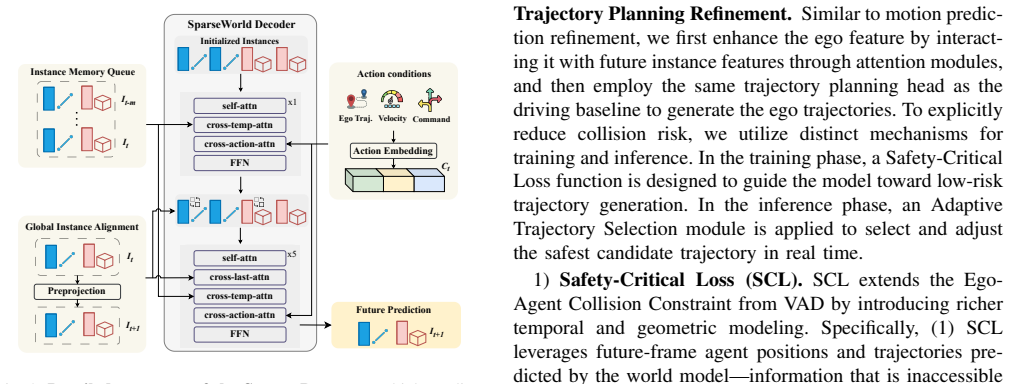
Sparse Dreamer, which anticipates future instances in latent space through joint temporal and spatial attention to enable efficient scene evolution forecasting.
If this is right
- Collision rate drops to 0.05% on nuScenes open-loop planning metrics.
- Closed-loop planning metrics improve over the baseline on Bench2Drive.
- Computational cost decreases by avoiding dense scene representations.
- Motion planner generates trajectories that better account for predicted future dynamics.
Where Pith is reading between the lines
- The sparse approach may support longer-horizon forecasts without proportional increases in compute.
- Hybrid systems could combine sparse forecasting for dynamics with dense perception for static details.
- Similar latent-space rollout might apply to other sequential decision tasks that benefit from selective scene modeling.
Load-bearing premise
That rollout of only critical layout elements and agents in latent space supplies enough information to refine motion prediction without losing essential scene details.
What would settle it
A test case in which the sparse predictions omit a road layout change or agent behavior that a dense model captures, resulting in a higher collision rate than the dense baseline on the same nuScenes or Bench2Drive evaluation.
Figures

read the original abstract
Recently, world models have made significant progress in enhancing end-to-end driving systems through both future situation forecasting and improved scene understanding. However, existing driving world models are typically built upon dense scene representations, causing high computational costs and redundant information. In this paper, we present SparseWorld, a lightweight world model that focuses on predicting only the critical layout of the scene, enabling efficient future forecasting for end-to-end driving systems. SparseWorld first performs autoregressive rollout to forecast future map elements and surrounding agents, enabling the model to learn how driving scenarios evolve over time. It then leverages these predicted futures to refine downstream motion prediction and trajectory planning. Specifically, we propose a Sparse Dreamer that anticipates future instances in the latent space through joint temporal and spatial attention. By interacting with predicted future instances, the motion planner captures more accurate motion patterns and generates more informed and safety-aware trajectories. Extensive experiments demonstrate that SparseWorld significantly reduces collision risk and achieves state-of-the-art performance on the open-loop planning metrics of the nuScenes dataset with a collision rate of 0.05\%. Moreover, it substantially outperforms the baseline method in closed-loop planning metrics on the Bench2Drive benchmark. Supplementary material is available at the project page: https://wryzju.github.io/SparseWorld/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SparseWorld, a lightweight world model for end-to-end autonomous driving that replaces dense scene representations with a sparse one. It performs autoregressive rollout of only critical map elements and surrounding agents in latent space via a Sparse Dreamer module using joint temporal and spatial attention, then feeds the predicted futures into downstream motion prediction and trajectory planning modules. The authors report state-of-the-art open-loop planning results on nuScenes (0.05% collision rate) and substantial gains over baselines on closed-loop metrics of the Bench2Drive benchmark, attributing the improvements to more efficient and safety-aware forecasting enabled by the sparse representation.
Significance. If the central claim holds, the work offers a practical route to lower computational cost in driving world models without sacrificing (and potentially improving) safety, which is relevant for real-time autonomous systems. The reported collision rate is exceptionally low and the closed-loop gains on Bench2Drive are noteworthy; successful validation of the sparse approach could influence subsequent research on efficient latent-space forecasting.
major comments (2)
- [Experiments] Experiments section: the central claim that autoregressive rollout of only critical elements via the Sparse Dreamer supplies sufficient information for downstream planning rests on an untested assumption. No ablation is reported that compares dense vs. sparse instance sets, varies the criticality threshold, or measures planning degradation when non-critical elements are omitted. Without such controls it is impossible to isolate whether the 0.05% collision rate and Bench2Drive gains are attributable to the sparse world model rather than other architectural choices.
- [Method] Method description (Sparse Dreamer paragraph): the joint temporal-spatial attention mechanism is presented as capturing future instance interactions, yet no quantitative analysis (e.g., attention maps or reconstruction error on omitted elements) is provided to show that essential scene details for trajectory safety are retained. This is load-bearing for the safety claims.
minor comments (2)
- [Abstract] The abstract states that supplementary material is available at the project page, but the manuscript does not include a direct citation or footnote to the specific supplementary sections that contain additional ablations or implementation details.
- [Method] Notation for the latent-space rollout (e.g., definitions of instance tokens and attention masks) could be made more explicit with a small diagram or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify gaps in experimental validation that would strengthen the attribution of performance gains to the sparse representation. We address each major comment below and commit to revisions that directly respond to the concerns.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that autoregressive rollout of only critical elements via the Sparse Dreamer supplies sufficient information for downstream planning rests on an untested assumption. No ablation is reported that compares dense vs. sparse instance sets, varies the criticality threshold, or measures planning degradation when non-critical elements are omitted. Without such controls it is impossible to isolate whether the 0.05% collision rate and Bench2Drive gains are attributable to the sparse world model rather than other architectural choices.
Authors: We agree that the manuscript lacks direct ablations isolating the contribution of the sparse instance set. The current experiments compare against dense baselines and report efficiency and accuracy gains, but do not systematically vary the criticality threshold or quantify degradation from omitting non-critical elements. In the revised manuscript we will add these ablations, including performance curves for different instance densities and criticality thresholds, as well as explicit measurements of planning degradation when non-critical elements are removed. These additions will allow clearer attribution of the reported collision rate and closed-loop improvements. revision: yes
-
Referee: [Method] Method description (Sparse Dreamer paragraph): the joint temporal-spatial attention mechanism is presented as capturing future instance interactions, yet no quantitative analysis (e.g., attention maps or reconstruction error on omitted elements) is provided to show that essential scene details for trajectory safety are retained. This is load-bearing for the safety claims.
Authors: We acknowledge that the paper provides no quantitative verification that the attention mechanism retains safety-critical details from omitted elements. While the overall planning results are consistent with effective retention, direct evidence such as attention visualizations or reconstruction error on non-predicted elements is absent. In revision we will include attention map examples and reconstruction metrics on omitted map elements and agents to demonstrate that essential information for safe trajectory generation is preserved. revision: yes
Circularity Check
No circularity: method claims rest on external benchmark results, not self-referential definitions or fitted inputs
full rationale
The provided abstract and method description introduce SparseWorld as a sparse latent-space autoregressive world model using joint temporal-spatial attention in the Sparse Dreamer, then apply its outputs to refine motion prediction and planning. No equations, parameter-fitting procedures, or derivation steps are shown that would reduce any 'prediction' to a fitted input or self-definition by construction. Central performance claims (0.05% collision rate on nuScenes, gains on Bench2Drive) are presented as outcomes of experiments on external datasets rather than tautological outputs of the model definition itself. No self-citation load-bearing, uniqueness theorems, or ansatz smuggling appear in the text. The derivation chain is therefore self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse scene representations suffice to model the evolution of driving scenarios over time
invented entities (1)
-
Sparse Dreamer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving
Y . Wang, J. He, L. Fan, H. Li, Y . Chen, and Z. Zhang. “Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, pp. 14749–14759
2024
-
[2]
Vista: A generalizable driving world model with high fidelity and versatile controllability
S. Gao, J. Yang, L. Chen, K. Chitta, Y . Qiu, A. Geiger, J. Zhang, and H. Li. “Vista: A generalizable driving world model with high fidelity and versatile controllability”. In:Advances in Neural Information Processing Systems37 (2024), pp. 91560–91596
2024
-
[3]
Driving in the occupancy world: Vision-centric 4d occupancy forecasting and planning via world models for autonomous driving
Y . Yang, J. Mei, Y . Ma, S. Du, W. Chen, Y . Qian, Y . Feng, and Y . Liu. “Driving in the occupancy world: Vision-centric 4d occupancy forecasting and planning via world models for autonomous driving”. In:Proceedings of the AAAI Conference on Artificial Intelligence. V ol. 39. 9. 2025, pp. 9327–9335
2025
-
[4]
End-to-End Driving with Online Trajectory Evaluation via
Y . Li, Y . Wang, Y . Liu, J. He, L. Fan, and Z. Zhang. “End-to-end driving with online trajectory evaluation via bev world model”. In: arXiv preprint arXiv:2504.01941(2025)
-
[5]
nuscenes: A multimodal dataset for autonomous driving
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom. “nuscenes: A multimodal dataset for autonomous driving”. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020, pp. 11621–11631
2020
-
[6]
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving
X. Jia, Z. Yang, Q. Li, Z. Zhang, and J. Yan. “Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving”. In:Advances in Neural Information Processing Systems 37 (2024), pp. 819–844
2024
-
[7]
Sparsedrive: End-to-end autonomous driving via sparse scene representation
W. Sun, X. Lin, Y . Shi, C. Zhang, H. Wu, and S. Zheng. “Sparsedrive: End-to-end autonomous driving via sparse scene representation”. In:arXiv preprint arXiv:2405.19620(2024)
-
[8]
Vad: Vectorized scene repre- sentation for efficient autonomous driving
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang. “Vad: Vectorized scene repre- sentation for efficient autonomous driving”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023, pp. 8340–8350
2023
-
[9]
Rad: Training an end-to-end driving policy via large-scale 3dgs-based reinforcement learning,
H. Gao, S. Chen, B. Jiang, B. Liao, Y . Shi, X. Guo, Y . Pu, H. Yin, X. Li, X. Zhang, et al. “Rad: Training an end-to-end driving policy via large-scale 3dgs-based reinforcement learning”. In:arXiv preprint arXiv:2502.13144(2025)
-
[10]
Hydra- next: Robust closed-loop driving with open-loop training
Z. Li, S. Wang, S. Lan, Z. Yu, Z. Wu, and J. M. Alvarez. “Hydra- next: Robust closed-loop driving with open-loop training”. In:arXiv preprint arXiv:2503.12030(2025)
-
[11]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, et al. “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving”. In:Proceedings of the Computer Vision and Pattern Recognition Conference. 2025, pp. 12037–12047
2025
-
[12]
Centaur: Robust end-to-end autonomous driving with test- time training
C. Sima, K. Chitta, Z. Yu, S. Lan, P. Luo, A. Geiger, H. Li, and J. M. Alvarez. “Centaur: Robust end-to-end autonomous driving with test- time training”. In:arXiv preprint arXiv:2503.11650(2025)
-
[13]
arXiv preprint arXiv:2408.03601 (2024)
C. Yuan, Z. Zhang, J. Sun, S. Sun, Z. Huang, C. D. W. Lee, D. Li, Y . Han, A. Wong, K. P. Tee, et al. “Drama: An efficient end-to-end motion planner for autonomous driving with mamba”. In:arXiv preprint arXiv:2408.03601(2024)
-
[14]
End-to-end model- free reinforcement learning for urban driving using implicit affor- dances
M. Toromanoff, E. Wirbel, and F. Moutarde. “End-to-end model- free reinforcement learning for urban driving using implicit affor- dances”. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020, pp. 7153–7162
2020
-
[15]
Trajectory- guided control prediction for end-to-end autonomous driving: A simple yet strong baseline
P. Wu, X. Jia, L. Chen, J. Yan, H. Li, and Y . Qiao. “Trajectory- guided control prediction for end-to-end autonomous driving: A simple yet strong baseline”. In:Advances in Neural Information Processing Systems35 (2022), pp. 6119–6132
2022
-
[16]
Learning by cheating
D. Chen, B. Zhou, V . Koltun, and P. Kr ¨ahenb¨uhl. “Learning by cheating”. In:Conference on robot learning. PMLR. 2020, pp. 66– 75
2020
-
[17]
Planning-oriented autonomous driving
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, et al. “Planning-oriented autonomous driving”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023, pp. 17853–17862
2023
-
[18]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
S. Chen, B. Jiang, H. Gao, B. Liao, Q. Xu, Q. Zhang, C. Huang, W. Liu, and X. Wang. “Vadv2: End-to-end vectorized autonomous driv- ing via probabilistic planning”. In:arXiv preprint arXiv:2402.13243 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
L. Liu, Z. Song, H. Pan, L. Yang, and C. Jia. “Two Tasks, One Goal: Uniting Motion and Planning for Excellent End To End Autonomous Driving Performance”. In:arXiv preprint arXiv:2504.12667(2025)
-
[20]
GAIA-1: A Generative World Model for Autonomous Driving
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado. “Gaia-1: A generative world model for autonomous driving”. In:arXiv preprint arXiv:2309.17080(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Model-based imitation learning for urban driving
A. Hu, G. Corrado, N. Griffiths, Z. Murez, C. Gurau, H. Yeo, A. Kendall, R. Cipolla, and J. Shotton. “Model-based imitation learning for urban driving”. In:Advances in Neural Information Processing Systems35 (2022), pp. 20703–20716
2022
-
[22]
arXiv preprint arXiv:2311.13549 , year=
F. Jia, W. Mao, Y . Liu, Y . Zhao, Y . Wen, C. Zhang, X. Zhang, and T. Wang. “Adriver-i: A general world model for autonomous driving”. In:arXiv preprint arXiv:2311.13549(2023)
-
[23]
DrivingDiffusion: layout-guided multi-view driving scenarios video generation with latent diffusion model
X. Li, Y . Zhang, and X. Ye. “DrivingDiffusion: layout-guided multi-view driving scenarios video generation with latent diffusion model”. In:European Conference on Computer Vision. Springer. 2024, pp. 469–485
2024
-
[24]
Drive- dreamer: Towards real-world-drive world models for autonomous driving
X. Wang, Z. Zhu, G. Huang, X. Chen, J. Zhu, and J. Lu. “Drive- dreamer: Towards real-world-drive world models for autonomous driving”. In:European conference on computer vision. Springer. 2024, pp. 55–72
2024
-
[25]
arXiv preprint arXiv:2311.01017 (2023)
L. Zhang, Y . Xiong, Z. Yang, S. Casas, R. Hu, and R. Urtasun. “Copilot4d: Learning unsupervised world models for autonomous driving via discrete diffusion”. In:arXiv preprint arXiv:2311.01017 (2023)
-
[26]
Occworld: Learning a 3d occupancy world model for autonomous driving
W. Zheng, W. Chen, Y . Huang, B. Zhang, Y . Duan, and J. Lu. “Occworld: Learning a 3d occupancy world model for autonomous driving”. In:European conference on computer vision. Springer. 2024, pp. 55–72
2024
-
[27]
Uniworld: Au- tonomous driving pre-training via world models
C. Min, D. Zhao, L. Xiao, Y . Nie, and B. Dai. “Uniworld: Au- tonomous driving pre-training via world models”. In:arXiv preprint arXiv:2308.07234(2023)
-
[28]
Occsora: 4d occupancy generation models as world simulators for autonomous driving
L. Wang, W. Zheng, Y . Ren, H. Jiang, Z. Cui, H. Yu, and J. Lu. “Occsora: 4d occupancy generation models as world simulators for autonomous driving”. In:arXiv preprint arXiv:2405.20337(2024)
-
[29]
Driveworld: 4d pre-trained scene understanding via world models for autonomous driving
C. Min, D. Zhao, L. Xiao, J. Zhao, X. Xu, Z. Zhu, L. Jin, J. Li, Y . Guo, J. Xing, et al. “Driveworld: 4d pre-trained scene understanding via world models for autonomous driving”. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024, pp. 15522–15533
2024
-
[30]
Gaussianworld: Gaussian world model for streaming 3d occupancy prediction
S. Zuo, W. Zheng, Y . Huang, J. Zhou, and J. Lu. “Gaussianworld: Gaussian world model for streaming 3d occupancy prediction”. In:Proceedings of the Computer Vision and Pattern Recognition Conference. 2025, pp. 6772–6781
2025
-
[31]
Uniscene: Unified occupancy-centric driving scene generation
B. Li, J. Guo, H. Liu, Y . Zou, Y . Ding, X. Chen, H. Zhu, F. Tan, C. Zhang, T. Wang, et al. “Uniscene: Unified occupancy-centric driving scene generation”. In:Proceedings of the Computer Vision and Pattern Recognition Conference. 2025, pp. 11971–11981
2025
-
[32]
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
J.-T. Zhai, Z. Feng, J. Du, Y . Mao, J.-J. Liu, Z. Tan, Y . Zhang, X. Ye, and J. Wang. “Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes”. In:arXiv preprint arXiv:2305.10430(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Don’t Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving
Z. Song, C. Jia, L. Liu, H. Pan, Y . Zhang, J. Wang, X. Zhang, S. Xu, L. Yang, and Y . Luo. “Don’t Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving”. In:Proceedings of the Computer Vision and Pattern Recognition Conference. 2025, pp. 22432–22441
2025
-
[34]
Is ego status all you need for open-loop end-to-end autonomous driving?
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez. “Is ego status all you need for open-loop end-to-end autonomous driving?” In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, pp. 14864–14873
2024
-
[35]
Enhancing End-to-End Autonomous Driving with Latent World Model
Y . Li, L. Fan, J. He, Y . Wang, Y . Chen, Z. Zhang, and T. Tan. “En- hancing end-to-end autonomous driving with latent world model”. In:arXiv preprint arXiv:2406.08481(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.