Artiverse: A Diverse and Physically Grounded Dataset for Articulated Objects
Pith reviewed 2026-06-30 13:41 UTC · model grok-4.3
The pith
Artiverse supplies 5.4K articulated 3D objects annotated with functional parts, multi-DoF joints, interior structures, and physical attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
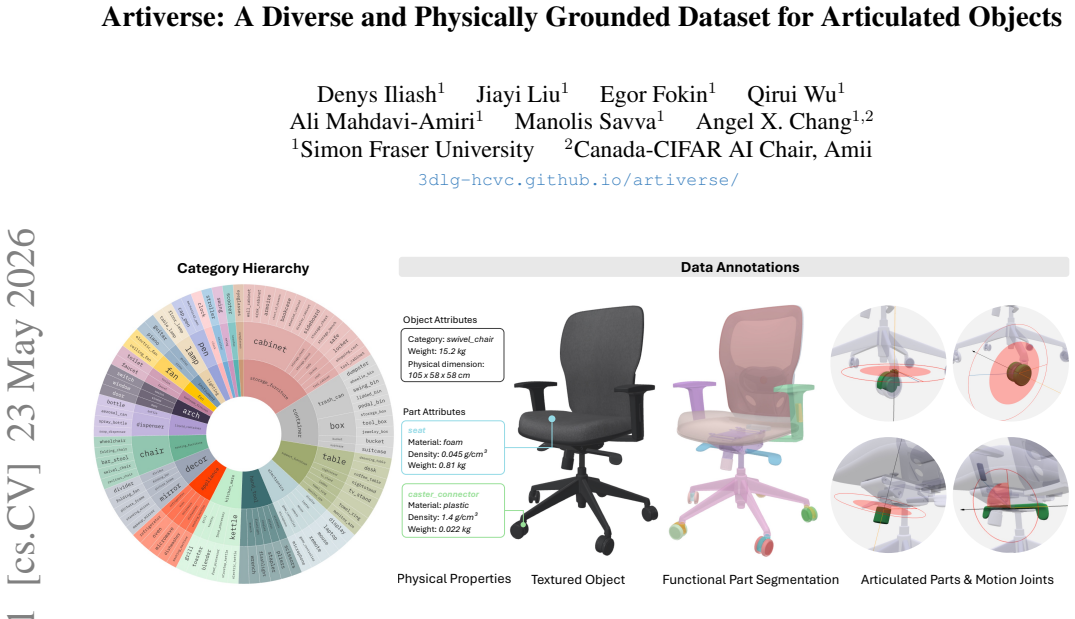
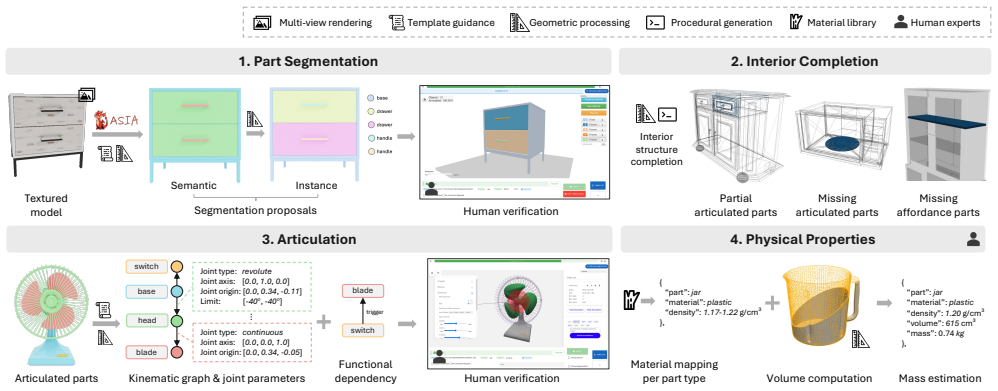
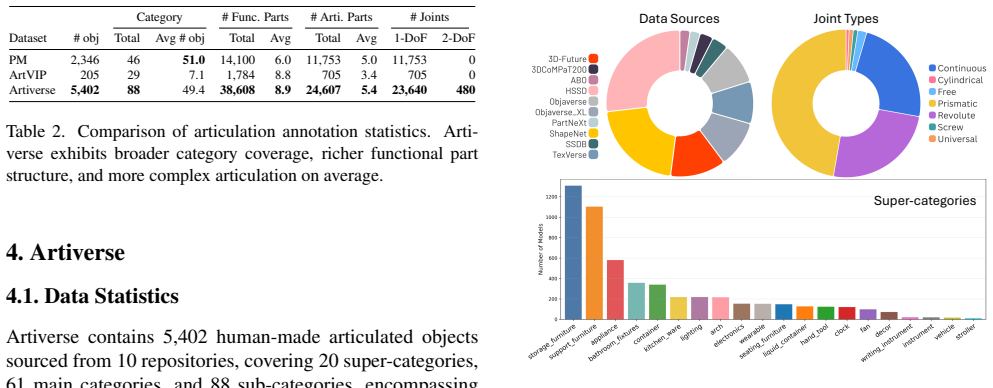
Artiverse contains 5.4K objects across 88 categories, each supplied with annotations for functional parts, interior structures, realistic kinematic relationships, articulated joints including multi-DoF joints, and physical attributes such as metric scale, material, and mass, produced through a semi-automated pipeline of few-shot segmentation, geometric reasoning, and multi-stage human verification.
What carries the argument
The semi-automated annotation pipeline combining few-shot segmentation, geometric reasoning, and multi-stage human verification to label functional parts, joints, and physical attributes at reduced manual cost.
If this is right
- Part mobility analysis can draw on the supplied kinematic relationships and multi-DoF joints.
- Articulated object generation methods gain access to objects already labeled with functional parts and interior structures.
- Physics-based interaction simulations can incorporate the provided metric scales, materials, and masses.
- Annotation time for similar future datasets can be reduced by adopting the reported pipeline.
Where Pith is reading between the lines
- The scale and category breadth may allow training of models that generalize across object types not covered in narrower prior collections.
- The inclusion of interior structures could support tasks that require reasoning about hidden components during manipulation.
- Physical attributes such as mass and material may enable direct transfer to real-world robotic control loops that rely on accurate dynamics.
Load-bearing premise
The pipeline's combination of automated steps and human verification produces annotations accurate enough to support functional modeling and physics simulation.
What would settle it
An experiment in which models trained or evaluated on Artiverse show no measurable improvement over models using prior articulated-object datasets on part mobility prediction or physics-based interaction accuracy.
Figures






read the original abstract
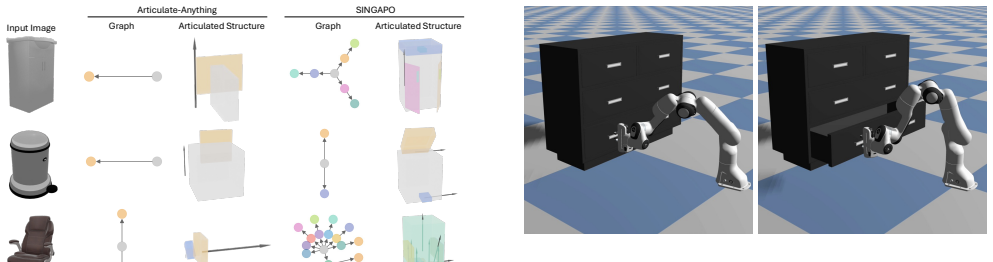
We present Artiverse, a diverse and physically grounded dataset of high-quality articulated 3D objects designed for realistic functional modeling and simulation. Artiverse contains 5.4K human-authored objects across a broad range of 88 categories, aggregated from multiple 3D static repositories. Objects are annotated with functional parts, interior structures, realistic kinematic relationships and articulated joints including multi-DoF joints, and physical attributes such as metric scale, material, and mass. We develop a semi-automated annotation pipeline that combines few-shot segmentation, geometric reasoning, and multi-stage human verification to achieve high-quality and efficient annotation, reducing manual annotation time by over 30%. We demonstrate the value of Artiverse on tasks of part mobility analysis, articulated object generation, and physics-based interaction. Artiverse provides a data resource to advance functional understanding for articulated objects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Artiverse, a dataset of 5.4K articulated 3D objects from 88 categories with annotations for functional parts, interior structures, kinematic joints (including multi-DoF), and physical attributes like scale, material, and mass. It describes a semi-automated pipeline using few-shot segmentation, geometric reasoning, and human verification that reduces annotation time by over 30%, and demonstrates utility on part mobility analysis, articulated object generation, and physics-based interaction tasks.
Significance. If the annotations prove accurate, Artiverse would be a significant contribution as a large-scale, diverse, and physically grounded dataset for articulated objects, filling a gap for functional modeling and simulation research. The inclusion of multi-DoF joints and physical attributes is particularly valuable for realistic applications in computer vision and robotics.
major comments (2)
- [Semi-automated annotation pipeline] The manuscript states that the pipeline produces high-quality annotations but reports no quantitative validation metrics, such as part segmentation IoU/Dice scores on held-out data, joint parameter errors versus expert re-annotation, material/mass consistency, or inter-annotator agreement. This absence undermines the central claim that the dataset supports functional modeling and simulation, as noted in the abstract and the pipeline description.
- [Demonstration tasks] The experiments on mobility analysis, generation, and physics-based interaction use the annotated data but do not provide metrics or ablations that measure or isolate the fidelity of the annotations (e.g., comparing performance with vs. without the new annotations or vs. expert-annotated subsets), leaving the pipeline's effectiveness untested.
minor comments (1)
- The abstract and text claim a >30% reduction in manual annotation time; providing the methodology and data behind this measurement would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on Artiverse. We address each major comment below and will incorporate revisions to strengthen the validation of the annotation pipeline.
read point-by-point responses
-
Referee: [Semi-automated annotation pipeline] The manuscript states that the pipeline produces high-quality annotations but reports no quantitative validation metrics, such as part segmentation IoU/Dice scores on held-out data, joint parameter errors versus expert re-annotation, material/mass consistency, or inter-annotator agreement. This absence undermines the central claim that the dataset supports functional modeling and simulation, as noted in the abstract and the pipeline description.
Authors: We agree that the absence of quantitative metrics such as segmentation IoU, joint parameter errors, and inter-annotator agreement limits the strength of the high-quality claim. The pipeline description emphasizes multi-stage human verification and the reported 30% time reduction, but these do not substitute for numeric validation. In the revised manuscript we will add a dedicated validation subsection reporting IoU/Dice on held-out objects, joint parameter errors against expert re-annotations, material/mass consistency checks, and inter-annotator agreement statistics. revision: yes
-
Referee: [Demonstration tasks] The experiments on mobility analysis, generation, and physics-based interaction use the annotated data but do not provide metrics or ablations that measure or isolate the fidelity of the annotations (e.g., comparing performance with vs. without the new annotations or vs. expert-annotated subsets), leaving the pipeline's effectiveness untested.
Authors: We acknowledge that the current experiments demonstrate utility of the dataset but do not isolate the contribution of annotation fidelity through ablations against expert subsets or alternative annotations. To address this, the revised manuscript will include additional ablations on the mobility analysis and physics-based interaction tasks that compare performance when using our annotations versus expert-annotated subsets, thereby providing direct evidence of annotation quality. revision: yes
Circularity Check
Dataset presentation paper contains no derivations, predictions, or self-referential chains
full rationale
This manuscript introduces the Artiverse dataset and describes its semi-automated annotation pipeline. No equations, fitted parameters, uniqueness theorems, or predictions appear anywhere in the text. The central claims are descriptive statements about object counts, category coverage, and pipeline time savings; none reduce to prior outputs of the same paper by construction. Self-citations, if present, are not load-bearing for any derivation. The paper is therefore self-contained with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SATR: Zero-shot semantic segmentation of 3D shapes
Ahmed Abdelreheem, Ivan Skorokhodov, Maks Ovsjanikov, and Peter Wonka. SATR: Zero-shot semantic segmentation of 3D shapes. InICCV, pages 15166–15179, 2023. 4
2023
-
[2]
3DCoMPaT200: Language-grounded composi- tional understanding of parts and materials of 3d shapes
Mahmoud Ahmed, Xiang Li, Arpit Prajapati, and Mohamed Elhoseiny. 3DCoMPaT200: Language-grounded composi- tional understanding of parts and materials of 3d shapes. arXiv preprint arXiv:2501.06785, 2025. 3, 1
-
[3]
Genesis: A generative and universal physics engine for robotics and beyond, 2024
Genesis Authors. Genesis: A generative and universal physics engine for robotics and beyond, 2024. 8
2024
-
[4]
PhysX- 3D: Physical-grounded 3D asset generation.arXiv preprint arXiv:2507.12465, 2025
Ziang Cao, Zhaoxi Chen, Linag Pan, and Ziwei Liu. PhysX- 3D: Physical-grounded 3D asset generation.arXiv preprint arXiv:2507.12465, 2025. 2
-
[5]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3D model repository.arXiv preprint arXiv:1512.03012, 2015. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[6]
ABO: Dataset and benchmarks for real-world 3D object un- derstanding
Jasmine Collins, Shubham Goel, Kenan Deng, Achlesh- war Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. ABO: Dataset and benchmarks for real-world 3D object un- derstanding. InCVPR, pages 21126–21136, 2022. 3
2022
-
[7]
3D highlighter: Localizing regions on 3D shapes via text descriptions
Dale Decatur, Itai Lang, and Rana Hanocka. 3D highlighter: Localizing regions on 3D shapes via text descriptions. In CVPR, pages 20930–20939, 2023. 4
2023
-
[8]
3D paintbrush: Local stylization of 3D shapes with cascaded score distillation
Dale Decatur, Itai Lang, Kfir Aberman, and Rana Hanocka. 3D paintbrush: Local stylization of 3D shapes with cascaded score distillation. InCVPR, pages 4473–4483, 2024. 4
2024
-
[9]
Objaverse: A universe of annotated 3D objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3D objects. InCVPR, pages 13142– 13153, 2023. 2, 3
2023
-
[10]
Objaverse-XL: A universe of 10M+ 3D objects.NeurIPS, 36, 2024
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-XL: A universe of 10M+ 3D objects.NeurIPS, 36, 2024. 2, 3
2024
-
[11]
PAOLI: Pose-free Articulated Object Learning from Sparse-view Images
Jianning Deng, Kartic Subr, and Hakan Bilen. PAOLI: Pose- free articulated object learning from sparse-view images. arXiv preprint arXiv:2509.04276, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Example-based synthesis of 3D object arrangements.ACM TOG, 31(6):1–11, 2012
Matthew Fisher, Daniel Ritchie, Manolis Savva, Thomas Funkhouser, and Pat Hanrahan. Example-based synthesis of 3D object arrangements.ACM TOG, 31(6):1–11, 2012. 3
2012
-
[13]
3D-Future: 3D fur- niture shape with texture.International Journal of Computer Vision, 129:3313–3337, 2021
Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3D-Future: 3D fur- niture shape with texture.International Journal of Computer Vision, 129:3313–3337, 2021. 3
2021
-
[14]
Me- shArt: Generating articulated meshes with structure-guided transformers
Daoyi Gao, Yawar Siddiqui, Lei Li, and Angela Dai. Me- shArt: Generating articulated meshes with structure-guided transformers. InCVPR, pages 618–627, 2025. 3
2025
-
[15]
GAPartNet: Cross- category domain-generalizable object perception and manip- ulation via generalizable and actionable parts
Haoran Geng, Helin Xu, Chengyang Zhao, Chao Xu, Li Yi, Siyuan Huang, and He Wang. GAPartNet: Cross- category domain-generalizable object perception and manip- ulation via generalizable and actionable parts. InCVPR, pages 7081–7091, 2023. 2, 3
2023
-
[16]
Pradyumn Goyal, Dmitry Petrov, Sheldon Andrews, Yizhak Ben-Shabat, Hsueh-Ti Derek Liu, and Evangelos Kaloger- akis. GEOPARD: Geometric pretraining for articulation pre- diction in 3D shapes.arXiv preprint arXiv:2504.02747,
-
[17]
ArticulatedGS: Self-supervised digital twin modeling of articulated objects using 3d gaussian splatting
Junfu Guo, Yu Xin, Gaoyi Liu, Kai Xu, Ligang Liu, and Ruizhen Hu. ArticulatedGS: Self-supervised digital twin modeling of articulated objects using 3d gaussian splatting. InCVPR, pages 27144–27153, 2025. 3
2025
-
[18]
Minghao Guo, Victor Zordan, Sheldon Andrews, Wojciech Matusik, Maneesh Agrawala, and Hsueh-Ti Derek Liu. Kinematic kitbashing for modeling functional articulated ob- jects.arXiv preprint arXiv:2510.13048, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
S2O: Static to openable enhancement for articulated 3D objects.arXiv preprint arXiv:2409.18896,
Denys Iliash, Hanxiao Jiang, Yiming Zhang, Manolis Savva, and Angel X Chang. S2O: Static to openable enhancement for articulated 3D objects.arXiv preprint arXiv:2409.18896,
-
[20]
OPD: Single-view 3d openable part detection
Hanxiao Jiang, Yongsen Mao, Manolis Savva, and Angel X Chang. OPD: Single-view 3d openable part detection. In ECCV, pages 410–426, 2022. 3
2022
-
[21]
Zhao Jin, Zhengping Che, Zhen Zhao, Kun Wu, Yuheng Zhang, Yinuo Zhao, Zehui Liu, Qiang Zhang, Xiaozhu Ju, Jing Tian, et al. ArtVIP: Articulated digital assets of visual realism, modular interaction, and physical fidelity for robot learning.arXiv preprint arXiv:2506.04941, 2025. 2, 3, 6
-
[22]
Abhishek Joshi, Beining Han, Jack Nugent, Yiming Zuo, Jonathan Liu, Hongyu Wen, Stamatis Alexandropoulos, Tao Sun, Alexander Raistrick, Gaowen Liu, et al. Infinigen-Sim: Procedural generation of articulated simulation assets.arXiv preprint arXiv:2505.10755, 2025. 3
-
[23]
Justin Kerr, Chung Min Kim, Mingxuan Wu, Brent Yi, Qianqian Wang, Ken Goldberg, and Angjoo Kanazawa. Robot see robot do: Imitating articulated object manipu- lation with monocular 4d reconstruction.arXiv preprint arXiv:2409.18121, 2024. 3
-
[24]
Habitat synthetic scenes dataset (HSSD-200): An analysis 9 of 3D scene scale and realism tradeoffs for objectgoal navi- gation
Mukul Khanna, Yongsen Mao, Hanxiao Jiang, Sanjay Haresh, Brennan Shacklett, Dhruv Batra, Alexander Clegg, Eric Undersander, Angel X Chang, and Manolis Savva. Habitat synthetic scenes dataset (HSSD-200): An analysis 9 of 3D scene scale and realism tradeoffs for objectgoal navi- gation. InCVPR, pages 16384–16393, 2024. 3, 1
2024
-
[25]
PartSTAD: 2D-to-3D part segmentation task adaptation
Hyunjin Kim and Minhyuk Sung. PartSTAD: 2D-to-3D part segmentation task adaptation. InECCV, pages 422–439,
-
[26]
Guiding diffusion-based articulated object generation by partial point cloud alignment and physical plausibility constraints
Jens U Kreber and Joerg Stueckler. Guiding diffusion-based articulated object generation by partial point cloud alignment and physical plausibility constraints. InICCV, pages 3206– 3214, 2025. 3
2025
-
[27]
Long Le, Jason Xie, William Liang, Hung-Ju Wang, Yue Yang, Yecheng Jason Ma, Kyle Vedder, Arjun Krishna, Di- nesh Jayaraman, and Eric Eaton. Articulate-Anything: Auto- matic modeling of articulated objects via a vision-language foundation model.arXiv preprint arXiv:2410.13882, 2024. 3, 7, 8
-
[28]
Duoduo CLIP: Efficient 3D understanding with multi-view images
Han-Hung Lee, Yiming Zhang, and Angel X Chang. Duoduo CLIP: Efficient 3D understanding with multi-view images. InICLR, 2025. 1
2025
-
[29]
Nap: Neural 3d articulation prior
Jiahui Lei, Congyue Deng, Bokui Shen, Leonidas Guibas, and Kostas Daniilidis. Nap: Neural 3d articulation prior. arXiv preprint arXiv:2305.16315, 2023. 3
-
[30]
Xinyu Lian, Zichao Yu, Ruiming Liang, Yitong Wang, Li Ray Luo, Kaixu Chen, Yuanzhen Zhou, Qihong Tang, Xudong Xu, Zhaoyang Lyu, et al. Infinite mobility: Scalable high-fidelity synthesis of articulated objects via procedural generation.arXiv preprint arXiv:2503.13424, 2025. 3
-
[31]
PARIS: Part-level reconstruction and motion analysis for articulated objects
Jiayi Liu, Ali Mahdavi-Amiri, and Manolis Savva. PARIS: Part-level reconstruction and motion analysis for articulated objects. InICCV, pages 352–363, 2023. 3
2023
-
[32]
Jiayi Liu, Denys Iliash, Angel X Chang, Manolis Savva, and Ali Mahdavi-Amiri. SINGAPO: Single image controlled generation of articulated parts in objects.arXiv preprint arXiv:2410.16499, 2024. 3, 7, 8
-
[33]
CAGE: Controllable articulation generation
Jiayi Liu, Hou In Ivan Tam, Ali Mahdavi-Amiri, and Mano- lis Savva. CAGE: Controllable articulation generation. In CVPR, pages 17880–17889, 2024. 3
2024
-
[34]
AKB-48: A real-world articu- lated object knowledge base
Liu Liu, Wenqiang Xu, Haoyuan Fu, Sucheng Qian, Qiaojun Yu, Yang Han, and Cewu Lu. AKB-48: A real-world articu- lated object knowledge base. InCVPR, pages 14809–14818,
-
[35]
Toward real-world category-level articulation pose esti- mation.IEEE Transactions on Image Processing, 31:1072– 1083, 2022
Liu Liu, Han Xue, Wenqiang Xu, Haoyuan Fu, and Cewu Lu. Toward real-world category-level articulation pose esti- mation.IEEE Transactions on Image Processing, 31:1072– 1083, 2022. 2, 3
2022
-
[36]
PartSLIP: Low-shot part segmentation for 3D point clouds via pretrained image- language models
Minghua Liu, Yinhao Zhu, Hong Cai, Shizhong Han, Zhan Ling, Fatih Porikli, and Hao Su. PartSLIP: Low-shot part segmentation for 3D point clouds via pretrained image- language models. InCVPR, pages 21736–21746, 2023. 4
2023
-
[37]
Yu Liu, Baoxiong Jia, Ruijie Lu, Junfeng Ni, Song-Chun Zhu, and Siyuan Huang. Building interactable replicas of complex articulated objects via gaussian splatting.ArXiv, abs/2502.19459, 2025. 3
-
[38]
PhysPart: Physically plausible part completion for interactable objects
Rundong Luo, Haoran Geng, Congyue Deng, Puhao Li, Zan Wang, Baoxiong Jia, Leonidas Guibas, and Siyuan Huang. PhysPart: Physically plausible part completion for interactable objects. InIEEE International Conference on Robotics and Automation (ICRA), pages 12386–12393,
-
[39]
The RBO dataset of articulated objects and interactions.The International Journal of Robotics Research, 38(9):1013– 1019, 2019
Roberto Mart ´ın-Mart´ın, Clemens Eppner, and Oliver Brock. The RBO dataset of articulated objects and interactions.The International Journal of Robotics Research, 38(9):1013– 1019, 2019. 2, 3
2019
-
[40]
PartNet: A large- scale benchmark for fine-grained and hierarchical part-level 3D object understanding
Kaichun Mo, Shilin Zhu, Angel X Chang, Li Yi, Subarna Tripathi, Leonidas J Guibas, and Hao Su. PartNet: A large- scale benchmark for fine-grained and hierarchical part-level 3D object understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 909–918, 2019. 3
2019
-
[41]
ASIA: Adaptive 3D segmentation using few image annotations.ArXiv, abs/2509.24288, 2025
Sai Raj Kishore Perla, Aditya V ora, Sauradip Nag, Ali Mahdavi-Amiri, and Hao Zhang. ASIA: Adaptive 3D segmentation using few image annotations.ArXiv, abs/2509.24288, 2025. 4, 1
-
[42]
Pengzhen Ren, Min Li, Zhen Luo, Xinshuai Song, Ziwei Chen, Weijia Liufu, Yixuan Yang, Hao Zheng, Rongtao Xu, Zitong Huang, et al. InfiniteWorld: A unified scalable sim- ulation framework for general visual-language robot interac- tion.arXiv preprint arXiv:2412.05789, 2024. 3
-
[43]
Arti-PG: A toolbox for procedurally synthesizing large-scale and diverse articulated objects with rich annotations
Jianhua Sun, Yuxuan Li, Jiude Wei, Longfei Xu, Nange Wang, Yining Zhang, and Cewu Lu. Arti-PG: A toolbox for procedurally synthesizing large-scale and diverse articulated objects with rich annotations. InICCV, pages 6396–6405,
-
[44]
OPDMulti: Openable part detection for multiple ob- jects
Xiaohao Sun, Hanxiao Jiang, Manolis Savva, and Angel Chang. OPDMulti: Openable part detection for multiple ob- jects. In2024 International Conference on 3D Vision (3DV), pages 169–178, 2024. 3
2024
-
[45]
3×2: 3D object part seg- mentation by 2D semantic correspondences
Anh Thai, Weiyao Wang, Hao Tang, Stefan Stojanov, James M Rehg, and Matt Feiszli. 3×2: 3D object part seg- mentation by 2D semantic correspondences. InEuropean Conference on Computer Vision, pages 149–166. Springer,
-
[46]
Penghao Wang, Yiyang He, Xin Lv, Yukai Zhou, Lan Xu, Jingyi Yu, and Jiayuan Gu. PartNeXt: A next-generation dataset for fine-grained and hierarchical 3D part understand- ing.arXiv preprint arXiv:2510.20155, 2025. 3
-
[47]
Shape2motion: Joint analysis of motion parts and attributes from 3d shapes
Xiaogang Wang, Bin Zhou, Yahao Shi, Xiaowu Chen, Qin- ping Zhao, and Kai Xu. Shape2motion: Joint analysis of motion parts and attributes from 3d shapes. InCVPR, pages 8876–8884, 2019. 2, 3
2019
-
[48]
Xinjie Wang, Liu Liu, Yu Cao, Ruiqi Wu, Wenkang Qin, Dehui Wang, Wei Sui, and Zhizhong Su. EmbodiedGen: Towards a generative 3d world engine for embodied intel- ligence.ArXiv, abs/2506.10600, 2025. 3
-
[49]
Neural implicit representation for building digital twins of unknown articulated objects
Yijia Weng, Bowen Wen, Jonathan Tremblay, Valts Blukis, Dieter Fox, Leonidas Guibas, and Stan Birchfield. Neural implicit representation for building digital twins of unknown articulated objects. InCVPR, pages 3141–3150, 2024. 3
2024
-
[50]
Di Wu, Liu Liu, Linli Zhou, Anran Huang, Liangtu Song, Qiaojun Yu, Qi Wu, and Cewu Lu. REArtGS: Recon- structing and generating articulated objects via 3D gaus- sian splatting with geometric and motion constraints.ArXiv, abs/2503.06677, 2025. 3
-
[51]
Ruiqi Wu, Xinjie Wang, Liu Liu, Chunle Guo, Jiaxiong Qiu, Chongyi Li, Lichao Huang, Zhizhong Su, and Ming-Ming Cheng. DIPO: Dual-state images controlled articulated ob- 10 ject generation powered by diverse data.arXiv preprint arXiv:2505.20460, 2025. 3
-
[52]
DRAWER: Digi- tal reconstruction and articulation with environment realism
Hongchi Xia, Entong Su, Marius Memmel, Arhan Jain, Ray- mond Yu, Numfor Mbiziwo-Tiapo, Ali Farhadi, Abhishek Gupta, Shenlong Wang, and Wei-Chiu Ma. DRAWER: Digi- tal reconstruction and articulation with environment realism. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 21771–21782, 2025. 3
2025
-
[53]
SAPIEN: A simulated part-based interactive environment
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, et al. SAPIEN: A simulated part-based interactive environment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097– 11107, 2020. 2, 3, 5, 6, 7, 1
2020
-
[54]
Structured 3d latents for scalable and versatile 3d gen- eration
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d gen- eration. InCVPR, 2025. 4
2025
-
[55]
X-part: high fi- delity and structure coherent shape decomposition.ArXiv, abs/2509.08643, 2025
Xinhao Yan, Jiachen Xu, Yang Li, Changfeng Ma, Yun- han Yang, Chunshi Wang, Zibo Zhao, Zeqiang Lai, Yunfei Zhao, Zhuo Chen, and Chunchao Guo. X-part: high fi- delity and structure coherent shape decomposition.ArXiv, abs/2509.08643, 2025. 4
-
[56]
RPM-Net: Recurrent prediction of motion and parts from point cloud
Zihao Yan, Ruizhen Hu, Xingguang Yan, Luanmin Chen, Oliver van Kaick, Hao Zhang, and Hui Huang. RPM-Net: Recurrent prediction of motion and parts from point cloud. ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia), 38(6):240:1–240:15, 2019. 2, 3
2019
-
[57]
PhyScene: Physically interactable 3d scene synthe- sis for embodied ai
Yandan Yang, Baoxiong Jia, Peiyuan Zhi, and Siyuan Huang. PhyScene: Physically interactable 3d scene synthe- sis for embodied ai. InCVPR, pages 16262–16272, 2024. 3
2024
-
[58]
Yibo Zhang, Li Zhang, Rui Ma, and Nan Cao. TexVerse: A universe of 3D objects with high-resolution textures.arXiv preprint arXiv:2508.10868, 2025. 3
-
[59]
main_category
Ziming Zhong, Yanyu Xu, Jing Li, Jiale Xu, Zhengxin Li, Chaohui Yu, and Shenghua Gao. Meshsegmenter: Zero-shot mesh semantic segmentation via texture synthesis. InECCV, pages 182–199, 2024. 4 11 Artiverse: A Diverse and Physically Grounded Dataset for Articulated Objects Supplementary Material A. Additional Statistics In this section, we provide additiona...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.