World Models as Group Actions
Pith reviewed 2026-06-30 13:15 UTC · model grok-4.3
The pith
Video world models realize group actions on latent states when identity, inverse, and composition rules are enforced through regularization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that action-conditioned world modeling amounts to realizing a group action on the state space, and that enforcing the group properties of identity, inverse, and composition consistency through latent regularization with synthesized data improves structural correctness of the dynamics.
What carries the argument
Realizing group actions on the latent state space via consistency regularization on identity, inverse, and composition properties using synthesized supervision.
If this is right
- Action sequences will compose correctly in the model's predictions.
- Inverse actions will reliably return the state to its prior condition.
- Identity actions will leave the predicted state unchanged.
- Rollouts will exhibit greater stability over long horizons under the group constraints.
- These improvements occur without any loss in visual fidelity of the generated videos.
Where Pith is reading between the lines
- Applying the same regularization to other domains like robotic manipulation could enforce their respective group structures such as SE(3).
- Future work might derive the group structure automatically from data rather than assuming it a priori.
- The metrics GAC and GAR could serve as training objectives in addition to evaluation.
Load-bearing premise
The assumption that embodied action dynamics exactly follow a group structure that can be captured and enforced in the existing latent space of video world models.
What would settle it
Observing that after applying the regularization, the model's predictions for composite actions deviate significantly from the direct prediction of the composed action on real video data.
Figures


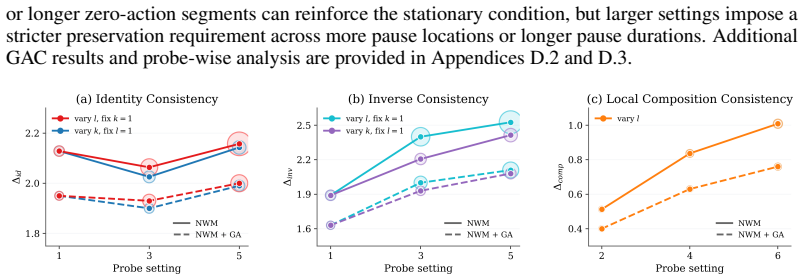





read the original abstract
Video world models have achieved strong visual realism, but this does not ensure that their dynamics are truly governed by actions. In this work, we argue that action faithfulness should be understood through the compositional structure of actions, which in many embodied settings follows a group structure (e.g., SE(2) for navigation). Based on this insight, we formalize action-conditioned world modeling as realizing a group action on the state space, providing a principled criterion for evaluating dynamics beyond visual quality. To operationalize this framework, we propose a unified approach that enforces identity, inverse, and composition consistency via latent-space regularization with synthesized supervision, avoiding additional data collection. We further introduce two metrics: Group-Action Consistency (GAC) and Group-Action Robustness (GAR), to evaluate structural correctness and rollout stability. Extensive experimental results show that our method consistently improves both GAC and GAR in state-of-the-art video world models without degrading perceptual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that action faithfulness in video world models should be understood via the compositional group structure of actions (e.g., SE(2) for navigation), formalizes action-conditioned world modeling as realizing a group action on the state space, proposes latent-space regularization with synthesized supervision to enforce identity/inverse/composition consistency, introduces GAC and GAR metrics, and reports that this yields consistent improvements in SOTA models without degrading perceptual quality.
Significance. If the improvements are shown to be independent of the regularization and the metrics provide an external criterion, the framework supplies a structured, group-theoretic basis for evaluating dynamics beyond visual fidelity; this would be relevant for embodied planning and control. The avoidance of new data collection via synthesized supervision is a practical positive if the synthesis is externally grounded.
major comments (3)
- [§3] §3 (synthesized supervision): the generation process for the supervision signals must be specified in detail; if supervision is produced from the base model's own predicted transitions or by applying assumed group operations directly in latent space without external grounding in real action trajectories, the regularization is self-referential and the claim of an independent principled criterion is undermined.
- [§4] §4 (GAC/GAR definitions): the metrics directly quantify the same identity, inverse, and composition properties that are enforced by the loss terms; this makes reported gains in GAC/GAR follow by construction from the added regularization rather than from improved alignment with embodied dynamics, weakening the central claim that the approach supplies an independent evaluation criterion.
- [§5] §5 (experiments): the manuscript must report concrete baselines, datasets, effect sizes, statistical controls, and ablation results; without these the abstract claim of 'consistent improvements' cannot be verified and may reflect post-hoc metric choices or insufficient controls.
minor comments (2)
- Notation for the group homomorphism and latent-space mappings should be introduced with explicit equations at first use to improve clarity.
- Ensure every acronym (GAC, GAR, SE(2)) is expanded on first occurrence in the body text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point by point below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: §3 (synthesized supervision): the generation process for the supervision signals must be specified in detail; if supervision is produced from the base model's own predicted transitions or by applying assumed group operations directly in latent space without external grounding in real action trajectories, the regularization is self-referential and the claim of an independent principled criterion is undermined.
Authors: We agree that the generation process for synthesized supervision must be specified with full precision. The revised manuscript will include an expanded description in §3 detailing that supervision signals are generated by applying the known group operations (identity, inverse, composition) to ground-truth action labels drawn from the original dataset trajectories, rather than from model predictions or direct latent-space manipulations. This ensures external grounding in real action data and preserves the independence of the regularization criterion. revision: yes
-
Referee: §4 (GAC/GAR definitions): the metrics directly quantify the same identity, inverse, and composition properties that are enforced by the loss terms; this makes reported gains in GAC/GAR follow by construction from the added regularization rather than from improved alignment with embodied dynamics, weakening the central claim that the approach supplies an independent evaluation criterion.
Authors: The metrics and loss terms target the same group properties by design, as both operationalize the formalization in §2. However, GAC and GAR are evaluated on held-out test trajectories and multi-step rollouts, providing a measure of generalization to unseen data, whereas the regularization is applied only during training. We will revise §4 to explicitly distinguish these roles and clarify that the metrics serve as an external diagnostic of structural correctness beyond training objectives, thereby supporting their use as an independent evaluation criterion. revision: partial
-
Referee: §5 (experiments): the manuscript must report concrete baselines, datasets, effect sizes, statistical controls, and ablation results; without these the abstract claim of 'consistent improvements' cannot be verified and may reflect post-hoc metric choices or insufficient controls.
Authors: We acknowledge that the current experimental section requires additional concrete details for full verifiability. The revised manuscript will expand §5 to report specific model baselines, exact dataset names and splits, quantitative effect sizes with standard deviations across multiple runs, statistical significance tests, and further ablation studies isolating the contribution of each consistency term. revision: yes
Circularity Check
GAC/GAR metrics improve by construction from regularization enforcing the same group consistencies they measure
specific steps
-
fitted input called prediction
[Abstract]
"we propose a unified approach that enforces identity, inverse, and composition consistency via latent-space regularization with synthesized supervision, avoiding additional data collection. We further introduce two metrics: Group-Action Consistency (GAC) and Group-Action Robustness (GAR), to evaluate structural correctness and rollout stability. Extensive experimental results show that our method consistently improves both GAC and GAR in state-of-the-art video world models without degrading perceptual quality."
GAC and GAR are defined to measure precisely the identity/inverse/composition consistencies that the regularization loss directly optimizes; therefore reported metric gains follow by construction from applying the synthesized-supervision objective rather than from external verification that the latent dynamics obey an independent group structure.
full rationale
The paper defines action faithfulness as realizing a group action (identity, inverse, composition), operationalizes it by enforcing those exact properties via latent regularization with synthesized supervision, and then reports that the method 'consistently improves both GAC and GAR'. Because GAC and GAR are introduced specifically 'to evaluate structural correctness' of those same consistencies, the claimed gains on the metrics reduce to a direct consequence of the loss terms rather than independent evidence. The perceptual-quality claim is not circular, but the central structural improvement is. No self-citation chains or other patterns appear in the given text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Actions in embodied settings follow a group structure (e.g., SE(2) for navigation)
Forward citations
Cited by 1 Pith paper
-
ATM: Action-Consistency Transfer Matrix for Diagnosing and Improving Latent World Models
ATM is a post-hoc probe-based transfer matrix that diagnoses action consistency in latent world models and serves as a training signal via AITS, enabling fast reliable ranking with claimed 100x speedup over CEM planne...
Reference graph
Works this paper leans on
-
[1]
Llm-planner: Few-shot grounded planning for embodied agents with large language models
Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2998–3009, 2023
2023
-
[2]
Grhp: Graph- fused hierarchical planning for embodied long-horizon robotic task.Engineering Applications of Artificial Intelligence, 165:113413, 2026
Xiaodong Li, Guohui Tian, Yongcheng Cui, Xuyang Shao, and Zhiwei Wang. Grhp: Graph- fused hierarchical planning for embodied long-horizon robotic task.Engineering Applications of Artificial Intelligence, 165:113413, 2026
2026
-
[3]
Embodied Task Planning via Graph-Informed Action Generation with Large Language Models
Xiang Li, Ning Yan, and Masood Mortazavi. Embodied task planning via graph-informed action generation with large language model.arXiv preprint arXiv:2601.21841, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Embodied agent interface: Benchmarking llms for embodied decision making.Advances in Neural Information Processing Systems, 37:100428–100534, 2024
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Li E Li, Ruohan Zhang, et al. Embodied agent interface: Benchmarking llms for embodied decision making.Advances in Neural Information Processing Systems, 37:100428–100534, 2024
2024
-
[5]
Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, et al. Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11142–11152, 2025
2025
-
[6]
Large model empowered embodied ai: A survey on decision-making and embodied learning
Wenlong Liang, Rui Zhou, Yang Ma, Bing Zhang, Songlin Li, Yijia Liao, and Ping Kuang. Large model empowered embodied ai: A survey on decision-making and embodied learning. arXiv preprint arXiv:2508.10399, 2025
-
[7]
Yang Liu, Xinshuai Song, Kaixuan Jiang, Weixing Chen, Jingzhou Luo, Guanbin Li, and Liang Lin. Meia: Multimodal embodied perception and interaction in unknown environments.arXiv preprint arXiv:2402.00290, 2024
-
[8]
Aligning cyber space with physical world: A comprehensive survey on embodied ai
Yang Liu, Weixing Chen, Yongjie Bai, Xiaodan Liang, Guanbin Li, Wen Gao, and Liang Lin. Aligning cyber space with physical world: A comprehensive survey on embodied ai. IEEE/ASME Transactions on Mechatronics, 2025
2025
-
[9]
Beyond the destination: A novel benchmark for exploration-aware embodied question answering
Kaixuan Jiang, Yang Liu, Weixing Chen, Jingzhou Luo, Ziliang Chen, Ling Pan, Guanbin Li, and Liang Lin. Beyond the destination: A novel benchmark for exploration-aware embodied question answering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9091–9101, 2025
2025
-
[10]
Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
2022
-
[11]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Navigation world models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801, 2025
2025
-
[14]
Dhruv Shah, Benjamin Eysenbach, Gregory Kahn, Nicholas Rhinehart, and Sergey Levine. Rapid exploration for open-world navigation with latent goal models.arXiv preprint arXiv:2104.05859, 2021
-
[15]
Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022
Haresh Karnan, Anirudh Nair, Xuesu Xiao, Garrett Warnell, Sören Pirk, Alexander Toshev, Justin Hart, Joydeep Biswas, and Peter Stone. Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022. 10
2022
-
[16]
Sacson: Scalable autonomous control for social navigation.IEEE Robotics and Automation Letters, 9(1):49–56, 2023
Noriaki Hirose, Dhruv Shah, Ajay Sridhar, and Sergey Levine. Sacson: Scalable autonomous control for social navigation.IEEE Robotics and Automation Letters, 9(1):49–56, 2023
2023
-
[17]
Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
2024
-
[18]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569, 2021
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569, 2021
2021
-
[21]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[22]
Dreamsim: Learning new dimensions of human visual similarity using synthetic data.Advances in Neural Information Processing Systems, 36:50742–50768, 2023
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data.Advances in Neural Information Processing Systems, 36:50742–50768, 2023
2023
-
[23]
Nomad: Goal masked diffusion policies for navigation and exploration
Ajay Sridhar, Dhruv Shah, Catherine Glossop, and Sergey Levine. Nomad: Goal masked diffusion policies for navigation and exploration. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 63–70. IEEE, 2024
2024
-
[24]
Goal-conditioned reinforcement learning for data-driven maritime navigation
Vaishnav Vaidheeswaran, Dilith Jayakody, Samruddhi Mulay, Anand Lo, Md Mahbub Alam, and Gabriel Spadon. Goal-conditioned reinforcement learning for data-driven maritime navigation. arXiv preprint arXiv:2509.01838, 2025
-
[25]
Wangtian Shen, Ziyang Meng, Jinming Ma, Mingliang Zhou, and Diyun Xiang. An efficient and multi-modal navigation system with one-step world model.arXiv preprint arXiv:2601.12277, 2026
-
[26]
Vision-and-language navi- gation: A survey of tasks, methods, and future directions
Jing Gu, Eliana Stefani, Qi Wu, Jesse Thomason, and Xin Wang. Vision-and-language navi- gation: A survey of tasks, methods, and future directions. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7606–7623, 2022
2022
-
[27]
Navgpt: Explicit reasoning in vision-and-language navigation with large language models
Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7641–7649, 2024
2024
-
[28]
Wei Xue, Mingcheng Li, Xuecheng Wu, Jingqun Tang, Dingkang Yang, and Lihua Zhang. Profocus: Proactive perception and focused reasoning in vision-and-language navigation.arXiv preprint arXiv:2603.05530, 2026
-
[29]
Effonav: An effective foundation- model-based visual navigation approach in challenging environment.IEEE Robotics and Automation Letters, 2025
Wangtian Shen, Pengfei Gu, Haijian Qin, and Ziyang Meng. Effonav: An effective foundation- model-based visual navigation approach in challenging environment.IEEE Robotics and Automation Letters, 2025
2025
-
[30]
Foundation-model-based action selection for behavior trees in navigation
Michele Moriconi, Stefan Laible, and Carmine Recchiuto. Foundation-model-based action selection for behavior trees in navigation. In2025 European Conference on Mobile Robots (ECMR), pages 1–7. IEEE, 2025
2025
-
[31]
Foundation model driven robotics: A compre- hensive review.arXiv preprint arXiv:2507.10087, 2025
Muhammad Tayyab Khan and Ammar Waheed. Foundation model driven robotics: A compre- hensive review.arXiv preprint arXiv:2507.10087, 2025
-
[32]
Gnm: A general navigation model to drive any robot
Dhruv Shah, Ajay Sridhar, Arjun Bhorkar, Noriaki Hirose, and Sergey Levine. Gnm: A general navigation model to drive any robot. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 7226–7233. IEEE, 2023. 11
2023
-
[33]
Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846, 2023
Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hi- rose, and Sergey Levine. Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846, 2023
-
[34]
Towards long-horizon vision-language navigation: Platform, benchmark and method
Xinshuai Song, Weixing Chen, Yang Liu, Vincent Chan, Guanbin Li, and Liang Lin. Towards long-horizon vision-language navigation: Platform, benchmark and method. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[35]
Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, et al. Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
-
[36]
Zhangyang Qi, Zhixiong Zhang, Yizhou Yu, Jiaqi Wang, and Hengshuang Zhao. Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221, 2025
-
[37]
ImagineNav++: Prompting Vision-Language Models as Embodied Navigator through Scene Imagination
Teng Wang, Xinxin Zhao, Wenzhe Cai, and Changyin Sun. Imaginenav++: Prompting vision-language models as embodied navigator through scene imagination.arXiv preprint arXiv:2512.17435, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Lazar Milikic, Manthan Patel, and Jonas Frey. Vld: Visual language goal distance for reinforce- ment learning navigation.arXiv preprint arXiv:2512.07976, 2025
-
[39]
Can Vision Foundation Models Navigate? Zero-Shot Real-World Evaluation and Lessons Learned
Maeva Guerrier, Karthik Soma, Jana Pavlasek, and Giovanni Beltrame. Can vision founda- tion models navigate? zero-shot real-world evaluation and lessons learned.arXiv preprint arXiv:2603.25937, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Fei Liu, Shichao Xie, Minghua Luo, Zedong Chu, Junjun Hu, Xiaolong Wu, and Mu Xu. Navforesee: A unified vision-language world model for hierarchical planning and dual-horizon navigation prediction.arXiv preprint arXiv:2512.01550, 2025
-
[41]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[42]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Dreaming: Model-based reinforcement learning by latent imagination without reconstruction
Masashi Okada and Tadahiro Taniguchi. Dreaming: Model-based reinforcement learning by latent imagination without reconstruction. In2021 ieee international conference on robotics and automation (icra), pages 4209–4215. IEEE, 2021
2021
-
[44]
Model-based reinforcement learning via imagination with derived memory.Advances in Neural Information Processing Systems, 34:9493–9505, 2021
Yao Mu, Yuzheng Zhuang, Bin Wang, Guangxiang Zhu, Wulong Liu, Jianyu Chen, Ping Luo, Shengbo Li, Chongjie Zhang, and Jianye Hao. Model-based reinforcement learning via imagination with derived memory.Advances in Neural Information Processing Systems, 34:9493–9505, 2021
2021
-
[45]
Pengxuan Yang, Yupeng Zheng, Deheng Qian, Zebin Xing, Qichao Zhang, Linbo Wang, Yichen Zhang, Shaoyu Guo, Zhongpu Xia, Qiang Chen, et al. Dreamerad: Efficient reinforcement learning via latent world model for autonomous driving.arXiv preprint arXiv:2603.24587, 2026
-
[46]
4d latent world model for robot planning.OpenReview preprint, 2026
Zhiyi Li, Peilin Wu, Xiaoshen Han, Ruojin Cai, and Yilun Du. 4d latent world model for robot planning.OpenReview preprint, 2026
2026
-
[47]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[48]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[49]
Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022. 12
2022
-
[50]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575, 2023
2023
-
[52]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Vid2world: Crafting video diffusion models to interactive world models,
Siqiao Huang, Jialong Wu, Qixing Zhou, Shangchen Miao, and Mingsheng Long. Vid2world: Crafting video diffusion models to interactive world models.arXiv preprint arXiv:2505.14357, 2025
-
[55]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Aether: Geometric-aware unified world modeling
Haoyi Zhu, Yifan Wang, Jianjun Zhou, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Chunhua Shen, Jiangmiao Pang, and Tong He. Aether: Geometric-aware unified world modeling. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8535– 8546, 2025
2025
-
[57]
Language-conditioned world modeling for visual navigation.arXiv preprint arXiv:2603.26741, 2026
Yifei Dong, Fengyi Wu, Yilong Dai, Lingdong Kong, Guangyu Chen, Xu Zhu, Qiyu Hu, Tianyu Wang, Johnalbert Garnica, Feng Liu, et al. Language-conditioned world modeling for visual navigation.arXiv preprint arXiv:2603.26741, 2026
-
[58]
Learning Interactive Real-World Simulators
Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 1(2):6, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Yifei Dong, Fengyi Wu, Guangyu Chen, Zhi-Qi Cheng, Qiyu Hu, Yuxuan Zhou, Jingdong Sun, Jun-Yan He, Qi Dai, and Alexander G Hauptmann. Unified world models: Memory-augmented planning and foresight for visual navigation.arXiv preprint arXiv:2510.08713, 2025
-
[60]
Yangcheng Yu, Xin Jin, Yu Shang, Xin Zhang, Haisheng Su, Wei Wu, and Yong Li. Mowm: Mixture-of-world-models for embodied planning via latent-to-pixel feature modulation.arXiv preprint arXiv:2509.21797, 2025
-
[61]
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, et al. Gigaworld-policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
-
[62]
Taiyi Su, Jian Zhu, Yaxuan Li, Chong Ma, Jianjun Zhang, Zitai Huang, Hanli Wang, and Yi Xu. Towards high-consistency embodied world model with multi-view trajectory videos.arXiv preprint arXiv:2511.12882, 2025
-
[63]
Yiran Qin, Zhelun Shi, Jiwen Yu, Xijun Wang, Enshen Zhou, Lijun Li, Zhenfei Yin, Xihui Liu, Lu Sheng, Jing Shao, et al. Worldsimbench: Towards video generation models as world simulators.arXiv preprint arXiv:2410.18072, 2024
-
[64]
Chun-Kai Fan, Xiaowei Chi, Xiaozhu Ju, Hao Li, Yong Bao, Yu-Kai Wang, Lizhang Chen, Zhiyuan Jiang, Kuangzhi Ge, Ying Li, et al. Wow, wo, val! a comprehensive embodied world model evaluation turing test.arXiv preprint arXiv:2601.04137, 2026. 13
-
[65]
Yu Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Lei Jin, Xin Zhang, Yinzhou Tang, Haisheng Su, et al. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models.arXiv preprint arXiv:2602.08971, 2026
-
[66]
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Ao Liang, Lingdong Kong, Tianyi Yan, Hongsi Liu, Wesley Yang, Ziqi Huang, Wei Yin, Jialong Zuo, Yixuan Hu, Dekai Zhu, et al. Worldlens: Full-spectrum evaluations of driving world models in real world.arXiv preprint arXiv:2512.10958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Yixuan Ye, Xuanyu Lu, Yuxin Jiang, Yuchao Gu, Rui Zhao, Qiwei Liang, Jiachun Pan, Fengda Zhang, Weijia Wu, and Alex Jinpeng Wang. Mind: Benchmarking memory consistency and action control in world models.arXiv preprint arXiv:2602.08025, 2026
-
[68]
LoopNav: Benchmarking Spatial Consistency in World Models
Kewei Lian, Shaofei Cai, Yilun Du, and Yitao Liang. Toward memory-aided world models: Benchmarking via spatial consistency.arXiv preprint arXiv:2505.22976, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Toward Consistent World Models with Multi-Token Prediction and Latent Semantic Enhancement
Qimin Zhong, Hao Liao, Haiming Qin, Mingyang Zhou, Rui Mao, Wei Chen, and Naipeng Chao. Toward consistent world models with multi-token prediction and latent semantic enhancement. arXiv preprint arXiv:2604.06155, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[70]
Zhen Li, Zian Meng, Shuwei Shi, Wenshuo Peng, Yuwei Wu, Bo Zheng, Chuanhao Li, and Kaipeng Zhang. Wildworld: A large-scale dataset for dynamic world modeling with actions and explicit state toward generative arpg.arXiv preprint arXiv:2603.23497, 2026
-
[71]
Han Yan, Zishang Xiang, Zeyu Zhang, and Hao Tang. Mwm: Mobile world models for action-conditioned consistent prediction.arXiv preprint arXiv:2603.07799, 2026
-
[72]
Generative modeling of molecular dynamics trajectories.Advances in Neural Information Processing Systems, 37:40534– 40564, 2024
Bowen Jing, Hannes Stärk, Tommi Jaakkola, and Bonnie Berger. Generative modeling of molecular dynamics trajectories.Advances in Neural Information Processing Systems, 37:40534– 40564, 2024
2024
-
[73]
Scalable emulation of protein equilibrium ensembles with generative deep learning.Science, 389(6761):eadv9817, 2025
Sarah Lewis, Tim Hempel, José Jiménez-Luna, Michael Gastegger, Yu Xie, Andrew YK Foong, Victor García Satorras, Osama Abdin, Bastiaan S Veeling, Iryna Zaporozhets, et al. Scalable emulation of protein equilibrium ensembles with generative deep learning.Science, 389(6761):eadv9817, 2025
2025
-
[74]
Aditya Sengar, Jiying Zhang, Pierre Vandergheynst, and Patrick Barth. Beyond ensembles: Simulating all-atom protein dynamics in a learned latent space.arXiv preprint arXiv:2509.02196, 2025
-
[75]
Conditional diffusion with locality-aware modal alignment for generating diverse protein conformational ensembles.Nature Machine Intelligence, pages 1–20, 2026
Baoli Wang, Chenglin Wang, Jingyang Chen, Danlin Liu, Changzhi Sun, Jie Zhang, Kai Zhang, and Honglin Li. Conditional diffusion with locality-aware modal alignment for generating diverse protein conformational ensembles.Nature Machine Intelligence, pages 1–20, 2026
2026
-
[76]
Pathdiffusion: modeling protein folding pathway using evolution-guided diffusion.bioRxiv, pages 2026–01, 2026
Kailong Zhao, Chenxiao Xiang, Bin Cheng, Yunyun Shen, Wenkai Wang, Shuyun Chen, Baoquan Su, Guijun Zhang, Zhenling Peng, and Jianyi Yang. Pathdiffusion: modeling protein folding pathway using evolution-guided diffusion.bioRxiv, pages 2026–01, 2026
2026
-
[77]
Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds
Nathaniel Thomas, Tess Smidt, Steven Kearnes, Lusann Yang, Li Li, Kai Kohlhoff, and Patrick Riley. Tensor field networks: Rotation-and translation-equivariant neural networks for 3d point clouds.arXiv preprint arXiv:1802.08219, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[78]
E (n) equivariant graph neural networks
Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E (n) equivariant graph neural networks. InInternational conference on machine learning, pages 9323–9332. PMLR, 2021
2021
-
[79]
Equivariant diffusion for molecule generation in 3d
Emiel Hoogeboom, Vıctor Garcia Satorras, Clément Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3d. InInternational conference on machine learning, pages 8867–8887. PMLR, 2022
2022
-
[80]
Minkai Xu, Lantao Yu, Yang Song, Chence Shi, Stefano Ermon, and Jian Tang. Geodiff: A geo- metric diffusion model for molecular conformation generation.arXiv preprint arXiv:2203.02923, 2022. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.