Rethinking VLM Representation for VLA Initialization
Pith reviewed 2026-06-29 22:19 UTC · model grok-4.3
The pith
The original pretrained VLM representation is the main driver of action performance in VLA models, and targeted adaptations must preserve it rather than reshape it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
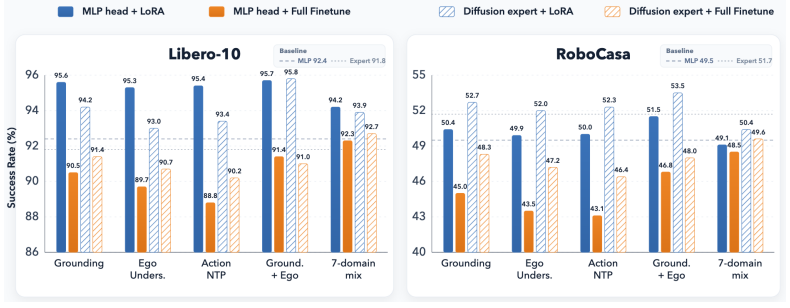
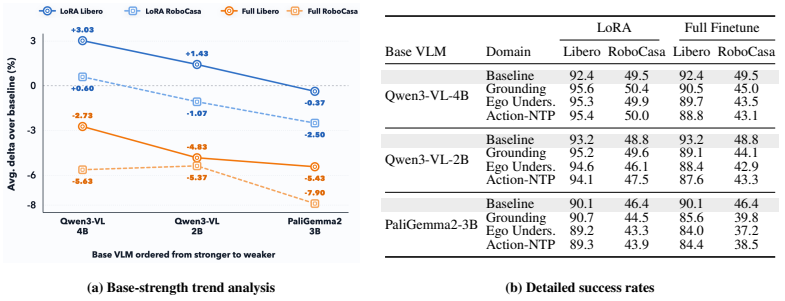
Experiments demonstrate that the original pretrained VLM representation supplies a key source of action performance. Embodied VQA adaptation produces uneven benefits that hinge on existing bottlenecks in the task and do not add across domains. Low-rank adaptation yields more reliable initialization than full finetuning because aggressive reshaping weakens the representation. Adding robot-data pretraining improves results further, with the strongest initialization obtained through staged low-rank training that injects action-relevant signals while leaving the pretrained features largely unchanged.
What carries the argument
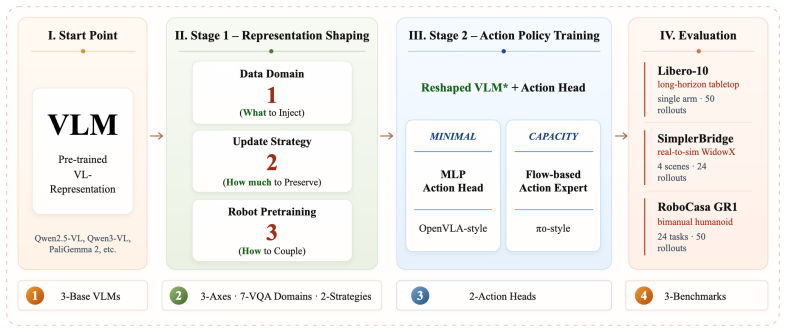
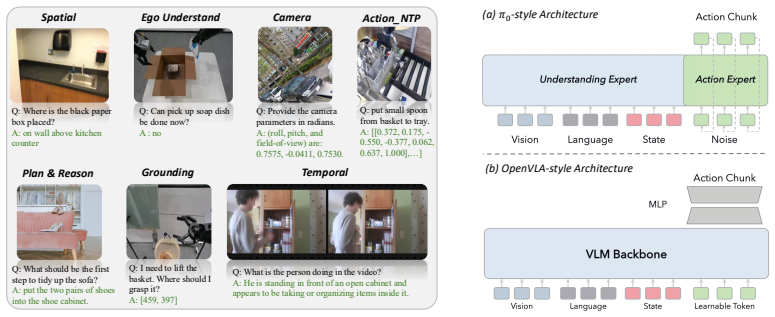
The VLM representation used as VLA initialization, tested through controlled variation along three axes of capability-level embodied VQA supervision, parameter-update strategy, and robot-data pretraining.
If this is right
- VLA training should prioritize methods that keep most of the original VLM weights fixed.
- Full parameter updates risk erasing action-relevant structure already present in the pretrained model.
- Robot trajectory data added via staged low-rank updates produces stronger initialization than either source alone.
- Gains from different embodied supervision domains must be checked against the specific bottlenecks of the target task.
Where Pith is reading between the lines
- Similar representation-preservation principles may apply when adapting other multimodal models to new output modalities.
- Future work could test whether the same staged low-rank pattern holds when the downstream task involves longer-horizon planning or multi-robot coordination.
- The finding suggests that VLA designers should measure how much the representation changes during adaptation rather than only tracking task reward.
Load-bearing premise
That varying only embodied VQA supervision, update strategy, and robot-data pretraining is enough to uncover general rules for choosing a VLM representation as VLA starting point.
What would settle it
A replication in which full finetuning on embodied VQA data consistently outperforms staged LoRA on the same downstream action tasks, or in which removing the original pretrained VLM weights improves rather than hurts policy success.
Figures
read the original abstract
Vision-Language-Action (VLA) models widely adopt pretrained Vision-Language Models (VLMs) as policy backbones, yet it remains unclear what kind of pretrained VLM representation is useful as a VLA initialization. In this paper, we study VLA initialization as a controlled representation-design problem along three axes: capability-level embodied VQA supervision, parameter-update strategy, and robot-data pretraining. Our experiments show that the original pretrained VLM representation is a key source of action performance. However, embodied VQA adaptation does not yield uniform gains: its benefit depends on downstream bottlenecks, and gains from different capability domains are not simply additive. For update strategy, LoRA provides a more reliable initialization than Full Finetune, indicating that overly reshaping the pretrained representation can weaken VLA initialization. Robot-data pretraining further improves VLA initialization, with the strongest variant obtained by staged LoRA-based training. Together, these findings suggest that effective VLM-to-VLA adaptation should inject action-relevant embodied and robot-trajectory signals while preserving the pretrained VLM representation that remains useful for action learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames VLA initialization as a controlled representation-design problem and studies it along three axes: capability-level embodied VQA supervision, parameter-update strategy (LoRA vs. full finetune), and robot-data pretraining. Experiments indicate that the original pretrained VLM representation remains a key source of action performance; embodied VQA adaptation yields non-uniform gains that depend on downstream bottlenecks and are not additive across domains; LoRA provides more reliable initialization than full finetuning; and the strongest results come from staged LoRA-based robot-data pretraining.
Significance. If the reported trends hold under the tested conditions, the work supplies concrete empirical guidance on VLM-to-VLA transfer that prioritizes preservation of pretrained representations while selectively injecting embodied and trajectory signals. The three-axis experimental design offers a reusable template for future ablation studies in this area.
minor comments (2)
- [Abstract] Abstract: the summary of experimental findings supplies no information on datasets, model sizes, number of runs, or statistical controls, making it difficult for readers to gauge the scope and reliability of the stated trends without immediately consulting the main text.
- [Introduction] The weakest-assumption paragraph in the introduction (or equivalent) should explicitly note that the three chosen axes are not claimed to be exhaustive and that interactions with other factors (e.g., action-head architecture, data scale) remain untested.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. The report accurately reflects our experimental findings on the three axes of VLA initialization.
Circularity Check
No significant circularity
full rationale
This is a purely empirical study that reports outcomes from controlled experiments along three explicitly defined axes (embodied VQA supervision, parameter-update strategy, and robot-data pretraining). No equations, fitted parameters, predictions, or derivation chains are present that could reduce any claim to a self-referential construction or self-citation load-bearing step. The central findings are direct summaries of experimental results and remain independent of any internal redefinition or imported uniqueness theorem.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URLhttps://arxiv.org/abs/2511.07403. Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi_0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498. IEEE, 2025a. Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhit...
-
[8]
URL https://arxiv.org/abs/ 2505.15517. Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330, 2024b. An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wan...
-
[9]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing
StarVLA Community. Starvla: A lego-like codebase for vision-language-action model developing. arXiv preprint arXiv:2604.05014,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
doi:10.48550/arXiv.2505.03912 , abstract =
URLhttps://github.com/starVLA/starVLA. 10 Can Cui, Pengxiang Ding, Wenxuan Song, Shuanghao Bai, Xinyang Tong, Zirui Ge, Runze Suo, Wanqi Zhou, Yang Liu, Bofang Jia, et al. Openhelix: A short survey, empirical analysis, and open-source dual-system vla model for robotic manipulation.arXiv preprint arXiv:2505.03912,
-
[11]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al. Knowledge insulating vision-language- action models: Train fast, run fast, generalize better.arXiv preprint arXiv:2505.23705,
-
[13]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, et al. Vlm-3r: Vision-language models augmented with instruction- aligned 3d reconstruction.arXiv preprint arXiv:2505.20279,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Qi Feng. Towards visuospatial cognition via hierarchical fusion of visual experts.arXiv preprint arXiv:2505.12363, 2025a. Qi Feng. Towards visuospatial cognition via hierarchical fusion of visual experts, 2025b. Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of ...
-
[16]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Evaluating Real-World Robot Manipulation Policies in Simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
11 Kang Liao, Size Wu, Zhonghua Wu, Linyi Jin, Chao Wang, Yikai Wang, Fei Wang, Wei Li, and Chen Change Loy. Thinking with camera: A unified multimodal model for camera-centric understanding and generation.arXiv preprint arXiv:2510.08673,
-
[22]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Yuhong Liu, Beichen Zhang, Yuhang Zang, Yuhang Cao, Long Xing, Xiaoyi Dong, Haodong Duan, Dahua Lin, and Jiaqi Wang. Spatial-ssrl: Enhancing spatial understanding via self-supervised reinforcement learning.arXiv preprint arXiv:2510.27606,
-
[24]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
URL https://arxiv.org/abs/2503.15558. Abby O’Neill, Abdul Rehman, Abhinav Gupta, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, et al. Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Baoqi Pei, Yifei Huang, Jilan Xu, Yuping He, Guo Chen, Fei Wu, Yu Qiao, and Jiangmiao Pang. Ego- thinker: Unveiling egocentric reasoning with spatio-temporal cot.arXiv preprint arXiv:2510.23569,
-
[28]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Delin Qu, Haoming Song, Qizhi Chen, Zhaoqing Chen, Xianqiang Gao, Xinyi Ye, Qi Lv, Modi Shi, Guanghui Ren, Cheng Ruan, et al. Eo-1: Interleaved vision-text-action pretraining for general robot control.arXiv preprint arXiv:2508.21112,
-
[30]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
PaliGemma 2: A Family of Versatile VLMs for Transfer
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bit- ton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, et al. Paligemma 2: A family of versatile vlms for transfer.arXiv preprint arXiv:2412.03555,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Robobrain 2.0 technical report.arXiv preprint arXiv:2507.02029,
BAAI RoboBrain Team. Robobrain 2.0 technical report.arXiv preprint arXiv:2507.02029,
-
[33]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montser- rat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Ganlin Yang, Tianyi Zhang, Haoran Hao, Weiyun Wang, Yibin Liu, Dehui Wang, Guanzhou Chen, Zijian Cai, Junting Chen, Weijie Su, et al. Vlaser: Vision-language-action model with synergistic embodied reasoning.arXiv preprint arXiv:2510.11027, 2025a. Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wenqia...
-
[36]
VLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jianke Zhang, Xiaoyu Chen, Qiuyue Wang, Mingsheng Li, Yanjiang Guo, Yucheng Hu, Jiajun Zhang, Shuai Bai, Junyang Lin, and Jianyu Chen. Vlm4vla: Revisiting vision-language-models in vision-language-action models.arXiv preprint arXiv:2601.03309,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross- embodiment vision-language-action model.arXiv preprint arXiv:2510.10274,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Enshen Zhou, Jingkun An, Cheng Chi, Yi Han, Shanyu Rong, Chi Zhang, Pengwei Wang, Zhongyuan Wang, Tiejun Huang, Lu Sheng, et al. Roborefer: Towards spatial referring with reasoning in vision-language models for robotics.arXiv preprint arXiv:2506.04308,
-
[39]
The reported counts denote the available candidate pool after preprocessing. In Sec. 4.1.1, each single-domain model is trained with 800K samples, sampled uniformly across the source datasets within that domain. For multi-domain composition in Sec. 4.1.2, we keep a fixed total budget and sample evenly across the selected domains. Table 4: Stage-1 embodied...
2024
-
[40]
We use learning rate2×10 −5 for the VLM backbone 14 Table 5: Stage-2 training and evaluation settings for downstream VLA learning. Item Libero-10 SimplerBridge RoboCasa GR1 Tabletop Train Image resolution224×224 224×224 224×224 Optimizer AdamW AdamW AdamW AdamW betas [0.9, 0.999] [0.9, 0.999] [0.9, 0.999] LR 1e-5 5e-5 5e-5 LR schedule cosine with min_lr =...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.