Verilog-Evolve: Feedback-Driven and Skill-Evolving Verilog Generation
Pith reviewed 2026-06-29 18:47 UTC · model grok-4.3
The pith
Verilog-Evolve refines LLM-generated Verilog by scoring candidates on simulation, synthesis, and timing feedback then evolves modular skills across tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
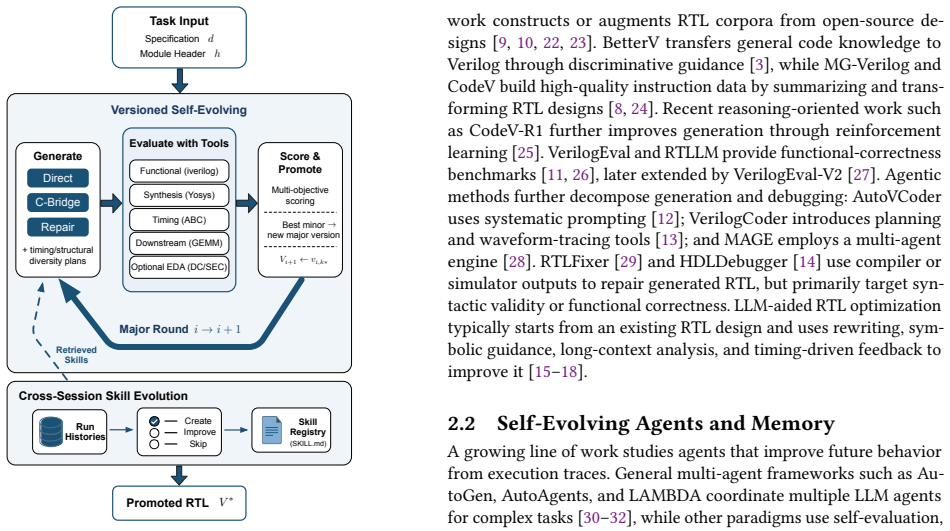
Verilog-Evolve improves final functional success and promotion stability while producing more downstream-friendly RTL under open-source synthesis, timing-proxy, and netlist-level GEMM objectives. Validation-gated skill evolution further improves GEMM downstream quality and achieves the best downstream score and GEMM held-out pass rate among the evaluated skill modes.
What carries the argument
The versioned refinement loop that scores and promotes candidates using multi-source executable feedback, combined with context-aware retrieval and history-driven evolution of modular skills.
If this is right
- Higher functional success rates and more stable major-version promotions on VerilogEval tasks.
- RTL outputs that achieve better scores under Yosys synthesis and ABC timing-proxy objectives.
- Improved netlist-level GEMM performance when the generated Verilog is synthesized and evaluated end-to-end.
- Validation-gated skill evolution delivers the highest downstream GEMM scores and held-out pass rates among tested modes.
Where Pith is reading between the lines
- The same feedback-and-promotion structure could be applied to other hardware description languages if equivalent executable metrics are available.
- Logged skill histories might be shared across organizations to bootstrap new design domains without retraining the base model.
- Adding commercial tool feedback into the scoring step would test whether open-source proxy signals remain predictive at scale.
Load-bearing premise
Feedback signals from functional simulation, Yosys synthesis, ABC timing proxy, and GEMM metrics reliably select candidates whose quality generalizes to real hardware objectives.
What would settle it
A promoted Verilog design that passes all recorded feedback metrics yet fails timing closure or functionality when run through a commercial synthesis flow or on actual silicon.
Figures
read the original abstract
Large language models (LLMs) have improved Verilog generation from natural-language specifications, but most pipelines still treat generation as isolated sampling followed by functional checking. This is insufficient for practical RTL design, where useful Verilog must be correct, synthesizable, timing-conscious, and friendly to downstream hardware objectives. We present Verilog-Evolve, a feedback-driven framework for versioned Verilog refinement and cross-session skill evolution. For each task, Verilog-Evolve generates diverse minor candidates, evaluates them with executable feedback from functional simulation, Yosys synthesis, ABC timing proxy, and optional GEMM metrics, then promotes the best candidate into a major version under configurable scoring. To improve across tasks, the system maintains modular skill guidance, retrieves skills according to task and feedback context, and evolves candidate skills from logged histories through create/improve/skip decisions and verifier reports. Experiments on VerilogEval and mixed-precision GEMM tasks show that Verilog-Evolve improves final functional success and promotion stability while producing more downstream-friendly RTL under open-source synthesis, timing-proxy, and netlist-level GEMM objectives. Validation-gated skill evolution further improves GEMM downstream quality and achieves the best downstream score and GEMM held-out pass rate among the evaluated skill modes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Verilog-Evolve, a feedback-driven framework for LLM-based Verilog generation. It generates diverse minor candidates per task, evaluates them via executable feedback from functional simulation, Yosys synthesis, ABC timing proxy, and optional GEMM metrics, promotes the best candidate to a major version under configurable scoring, and evolves modular skills across sessions by retrieving from task/feedback context and applying create/improve/skip decisions on logged histories. Experiments on VerilogEval and mixed-precision GEMM tasks claim improvements in final functional success, promotion stability, and downstream RTL quality under open-source synthesis, timing, and netlist-level objectives, with validation-gated skill evolution yielding the best GEMM downstream score and held-out pass rate.
Significance. If the empirical claims hold under rigorous controls, the work could meaningfully advance automated RTL design by showing how multi-source proxy feedback and history-derived skill evolution can produce Verilog that is not only functionally correct but also more synthesizable and aligned with downstream hardware objectives, addressing a key limitation of isolated sampling pipelines.
major comments (2)
- [Abstract / Experiments] Abstract and experimental description: the claims of benchmark improvements and 'best downstream score' rest on comparisons whose baselines, data splits, statistical significance tests, and exact scoring formulas (including how functional, synthesis, timing-proxy, and GEMM signals are combined) are not supplied; without these the reported gains cannot be verified as load-bearing evidence for the central claim.
- [Method / Experiments] The weakest assumption—that multi-source feedback (simulation, Yosys, ABC, GEMM) plus logged-history skill evolution reliably selects RTL that generalizes beyond the proxy metrics—is not accompanied by failure-case analysis, ablation on feedback reliability, or held-out hardware validation that would test generalization risk.
minor comments (1)
- [Abstract] The abstract refers to 'configurable scoring' and 'validation-gated skill evolution' without defining the configuration parameters or gating criterion, which affects reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to clarify our work. Below we respond point-by-point to the major comments, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental description: the claims of benchmark improvements and 'best downstream score' rest on comparisons whose baselines, data splits, statistical significance tests, and exact scoring formulas (including how functional, synthesis, timing-proxy, and GEMM signals are combined) are not supplied; without these the reported gains cannot be verified as load-bearing evidence for the central claim.
Authors: We agree that the abstract is highly condensed and that the experimental section would benefit from more explicit cross-references. The full manuscript already specifies the baselines (standard few-shot prompting and temperature-sampled generation from prior Verilog works), the official VerilogEval train/test splits, statistical significance via five independent seeds with reported means and standard deviations, and the composite scoring function (configurable weighted sum of functional simulation pass rate, Yosys synthesis success, ABC timing proxy, and optional GEMM metrics). To make these elements immediately verifiable from the abstract and main text, we will expand the abstract with a one-sentence evaluation protocol summary and add a dedicated “Evaluation Metrics and Statistical Protocol” subsection that reproduces the exact formula and significance tests. revision: yes
-
Referee: [Method / Experiments] The weakest assumption—that multi-source feedback (simulation, Yosys, ABC, GEMM) plus logged-history skill evolution reliably selects RTL that generalizes beyond the proxy metrics—is not accompanied by failure-case analysis, ablation on feedback reliability, or held-out hardware validation that would test generalization risk.
Authors: This concern is well-founded. The current manuscript contains component-wise ablations and reports improved held-out GEMM pass rates under validation-gated evolution, yet it lacks an explicit failure-case study and a direct discussion of when proxy signals diverge from final hardware quality. We will add a new subsection titled “Failure Modes and Generalization Analysis” that (1) presents representative cases where multi-source feedback selected functionally correct but timing-suboptimal RTL, (2) quantifies feedback reliability via an ablation that removes each signal in turn, and (3) discusses the limits of the netlist-level GEMM objective as a proxy for downstream hardware. These additions will be accompanied by the corresponding experimental tables. revision: yes
Circularity Check
No significant circularity; framework relies on external tool feedback
full rationale
The paper presents an empirical LLM-based generation framework evaluated via external tools (functional simulation, Yosys, ABC timing proxy, GEMM metrics). No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps exist in the provided material. Claims of improvement are tied to observable external benchmarks (VerilogEval, GEMM tasks) rather than reducing to internal definitions or fits by construction. This matches the default non-circular outcome for engineering papers whose core logic is externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-metric executable feedback from simulation, synthesis, and timing tools accurately ranks candidate quality for downstream hardware objectives
Reference graph
Works this paper leans on
-
[1]
Large language models for software engineering: Survey and open problems,
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, and J. M. Zhang, “Large language models for software engineering: Survey and open problems, ” in 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), 2023
2023
-
[2]
Using an llm to help with code understanding,
D. Nam, A. Macvean, V. Hellendoorn, B. Vasilescu, and B. Myers, “Using an llm to help with code understanding, ” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024
2024
-
[3]
Betterv: Controlled verilog generation with discriminative guidance,
Z. Pei, H.-L. Zhen, M. Yuan, Y. Huang, and B. Yu, “Betterv: Controlled verilog generation with discriminative guidance, ”arXiv preprint arXiv:2402.03375, 2024
-
[4]
ChipNeMo: Domain-Adapted LLMs for Chip Design,
M. Liu, T.-D. Ene, R. Kirby, C. Cheng, N. Pinckney, R. Liang, J. Alben, H. Anand, S. Banerjee, I. Bayraktarogluet al., “ChipNeMo: Domain-Adapted LLMs for Chip Design, ”arXiv preprint arXiv:2311.00176, 2023
-
[5]
ChatEDA: A large language model powered autonomous agent for EDA,
Z. He, H. Wu, X. Zhang, X. Yao, S. Zheng, H. Zheng, and B. Yu, “ChatEDA: A large language model powered autonomous agent for EDA, ” inACM/IEEE Workshop on Machine Learning CAD (MLCAD), 2023
2023
-
[6]
Customized retrieval augmented generation and benchmarking for eda tool documentation qa,
Y. Pu, Z. He, T. Qiu, H. Wu, and B. Yu, “Customized retrieval augmented generation and benchmarking for eda tool documentation qa, ”arXiv preprint arXiv:2407.15353, 2024
-
[7]
Dila: Enhancing llm tool learning with differential logic layer,
Y. Zhang, H.-L. Zhen, Z. Pei, Y. Lian, L. Yin, M. Yuan, and B. Yu, “Dila: Enhancing llm tool learning with differential logic layer, ” pp. 1952–1963, 2026
1952
-
[8]
Mg-verilog: Multi-grained dataset towards enhanced llm-assisted verilog generation,
Y. Zhang, Z. Yu, Y. Fu, C. Wanet al., “Mg-verilog: Multi-grained dataset towards enhanced llm-assisted verilog generation, ”arXiv preprint arXiv:2407.01910, 2024
-
[9]
Verigen: A large language model for verilog code generation,
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “Verigen: A large language model for verilog code generation, ”ACM Transactions on Design Automation of Electronic Systems, vol. 29, no. 3, pp. 1–31, 2024
2024
-
[10]
S. Liu, W. Fang, Y. Lu, Q. Zhang, H. Zhang, and Z. Xie, “RTLCoder: Outperforming GPT-3.5 in Design RTL Generation with Our Open-Source Dataset and Lightweight Solution, ”arXiv preprint arXiv:2312.08617, 2023
-
[11]
RTLLM: An open-source benchmark for design rtl generation with large language model,
Y. Lu, S. Liu, Q. Zhang, and Z. Xie, “RTLLM: An open-source benchmark for design rtl generation with large language model, ”arXiv preprint arXiv:2308.05345, 2023
-
[12]
Autovcoder: A systematic framework for automated verilog code generation using llms,
M. Gao, J. Zhao, Z. Lin, W. Ding, X. Hou, Y. Feng, C. Li, and M. Guo, “Autovcoder: A systematic framework for automated verilog code generation using llms, ”arXiv preprint arXiv:2407.18333, 2024
-
[13]
Verilogcoder: Autonomous verilog coding agents with graph-based planning and abstract syntax tree (ast)-based waveform tracing tool,
C.-T. Ho, H. Ren, and B. Khailany, “Verilogcoder: Autonomous verilog coding agents with graph-based planning and abstract syntax tree (ast)-based waveform tracing tool, ” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 1, 2025
2025
-
[14]
Hdlde- bugger: Streamlining hdl debugging with large language models,
X. Yao, H. Li, T. H. Chan, W. Xiao, M. Yuan, Y. Huang, L. Chen, and B. Yu, “Hdlde- bugger: Streamlining hdl debugging with large language models, ”arXiv preprint arXiv:2403.11671, 2024
-
[15]
Rtlrewriter: Methodologies for large models aided rtl code optimization,
X. Yao, Y. Wang, X. Li, Y. Lian, R. Chen, L. Chen, M. Yuan, H. Xu, and B. Yu, “Rtlrewriter: Methodologies for large models aided rtl code optimization, ” inPro- ceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024
2024
-
[16]
Symrtlo: Enhancing rtl code optimization with llms and neuron-inspired symbolic reasoning,
Y. Wang, W. Ye, P. Guo, Y. He, Z. Wang, B. Tian, S. He, G. Sun, Z. Shen, S. Chen et al., “Symrtlo: Enhancing rtl code optimization with llms and neuron-inspired symbolic reasoning, ”Advances in Neural Information Processing Systems, vol. 38, pp. 50 093–50 118, 2026
2026
-
[17]
Longrtl: Graph- similarity-guided llm-driven long context rtl optimization,
Y. Ye, C.-K. Shen, X. Hu, Y. Liu, S. Yin, X. Yao, B. Yu, and T.-Y. Ho, “Longrtl: Graph- similarity-guided llm-driven long context rtl optimization, ” 2026
2026
-
[18]
Dr. RTL: Autonomous Agentic RTL Optimization through Tool-Grounded Self-Improvement
W. Fang, Y. Lu, S. Liu, J. Wang, Z. Guo, J. He, F. Tu, and Z. Xie, “Dr. rtl: Autonomous agentic rtl optimization through tool-grounded self-improvement, ”arXiv preprint arXiv:2604.14989, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
Y. Jiet al., “Skillclaw: Let skills evolve collectively with agentic evolver, ”arXiv preprint arXiv:2604.08377, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Benchmarking Large Language Models for Automated Verilog RTL Code Generation,
S. Thakur, B. Ahmad, Z. Fan, H. Pearce, B. Tan, R. Karri, B. Dolan-Gavitt, and S. Garg, “Benchmarking Large Language Models for Automated Verilog RTL Code Generation, ” inIEEE/ACM Proceedings Design, Automation and Test in Eurpoe (DATE), 2023
2023
-
[21]
Chipgpt: How far are we from natural language hardware design,
K. Chang, Y. Wang, H. Ren, M. Wang, S. Liang, Y. Han, H. Li, and X. Li, “Chipgpt: How far are we from natural language hardware design, ”arXiv preprint arXiv:2305.14019, 2023
-
[22]
A Deep Learning Framework for Verilog Autocompletion Towards Design and Verification Automation,
E. Dehaerne, B. Dey, S. Halder, and S. De Gendt, “A Deep Learning Framework for Verilog Autocompletion Towards Design and Verification Automation, ”arXiv preprint arXiv:2304.13840, 2023
-
[23]
Origen: Enhancing rtl code generation with code-to-code augmentation and self-reflection,
F. Cui, C. Yin, K. Zhou, Y. Xiao, G. Sun, Q. Xu, Q. Guo, D. Song, D. Lin, X. Zhang et al., “Origen: Enhancing rtl code generation with code-to-code augmentation and self-reflection, ”arXiv preprint arXiv:2407.16237, 2024
-
[24]
CodeV: Empowering LLMs for Verilog Generation through Multi-Level Summarization,
Y. Zhao, D. Huang, C. Li, P. Jin, Z. Nan, T. Ma, L. Qi, Y. Pan, Z. Zhang, R. Zhang et al., “Codev: Empowering llms for verilog generation through multi-level sum- marization, ”arXiv preprint arXiv:2407.10424, 2024
-
[25]
Codev-r1: Reasoning-enhanced verilog generation,
Y. Zhu, D. Huang, H. Lyu, X. Zhang, C. Li, W. Shi, Y. Wu, J. Mu, J. Wang, Y. Zhaoet al., “Codev-r1: Reasoning-enhanced verilog generation, ”arXiv preprint arXiv:2505.24183, 2025
-
[26]
VerilogEval: Evaluating Large Lan- guage Models for Verilog Code Generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “VerilogEval: Evaluating Large Lan- guage Models for Verilog Code Generation, ” inIEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2023
2023
-
[27]
N. Pinckney, C. Batten, M. Liu, H. Ren, and B. Khailany, “Revisiting verilogeval: Newer llms, in-context learning, and specification-to-rtl tasks, ” 2024. [Online]. Available: https://arxiv.org/abs/2408.11053
-
[28]
Mage: A multi-agent engine for automated rtl code generation,
Y. Zhao, H. Zhang, H. Huang, Z. Yu, and J. Zhao, “Mage: A multi-agent engine for automated rtl code generation, ”arXiv preprint arXiv:2412.07822, 2024
-
[29]
RTLFixer: Automatically Fixing RTL Syntax Errors with Large Language Models,
Y. Tsai, M. Liu, and H. Ren, “RTLFixer: Automatically Fixing RTL Syntax Errors with Large Language Models, ”arXiv preprint arXiv:2311.16543, 2023
-
[30]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu, G. Bansal, J. Zhang, Y. Wu, S. Zhang, E. Zhu, B. Li, L. Jiang, X. Zhang, and C. Wang, “Autogen: Enabling next-gen llm applications via multi-agent conversa- tion framework, ”arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Autoagents: A framework for automatic agent generation,
G. Chen, S. Dong, Y. Shu, G. Zhang, J. Sesay, B. F. Karlsson, J. Fu, and Y. Shi, “Autoagents: A framework for automatic agent generation, ”arXiv preprint arXiv:2309.17288, 2023
-
[32]
Lambda: A large model based data agent,
M. Sun, R. Han, B. Jiang, H. Qi, D. Sun, Y. Yuan, and J. Huang, “Lambda: A large model based data agent, ”arXiv preprint arXiv:2407.17535, 2024
-
[33]
Agentcollab: A self-evaluation-driven collaboration paradigm for efficient llm agents,
W. Gao, R. Liu, X. Wang, F. Guo, S. Yang, X. Chen, H.-L. Zhen, H. Chen, W. Lin, X. Li et al., “Agentcollab: A self-evaluation-driven collaboration paradigm for efficient llm agents, ”arXiv preprint arXiv:2603.26034, 2026
-
[34]
Rethinker: Scientific reasoning by rethinking with guided reflection and confidence control,
Z. Tang, Y. Cui, S. Kai, W. Zhao, K. Ye, X. Li, A. Tian, Z. Pei, H.-L. Zhen, S. Hu et al., “Rethinker: Scientific reasoning by rethinking with guided reflection and confidence control, ”arXiv preprint arXiv:2602.04496, 2026
-
[35]
SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
Z. Pei, H.-L. Zhen, S. Kai, S. J. Pan, Y. Wang, M. Yuan, and B. Yu, “Scope: Prompt evolution for enhancing agent effectiveness, ”arXiv preprint arXiv:2512.15374, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Towards efficient agents: A co-design of inference architecture and system,
W. Lin, H.-L. Zhen, S. Yang, X. Wang, R. Liu, H. Chen, W. Zhang, C. Zhou, Y. Li, C. Chenet al., “Towards efficient agents: A co-design of inference architecture and system, ”arXiv preprint arXiv:2512.18337, 2025
-
[37]
Yosys open synthesis suite,
C. Wolf, “Yosys open synthesis suite, ” https://yosyshq.net/yosys/
-
[38]
ABC: An academic industrial-strength verification tool,
R. Brayton and A. Mishchenko, “ABC: An academic industrial-strength verification tool, ” inInternational Conference on Computer-Aided Verification (CA V), 2010. 7
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.