Turning Video Models into Generalist Robot Policies
Pith reviewed 2026-06-29 12:32 UTC · model grok-4.3
The pith
Decoupled video planning paired with Jacobian-based inverse dynamics models produces cross-embodiment robot policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an action-free video world model combined with an embodiment-specific inverse dynamics model based on the robot Jacobian forms a closed-loop video-to-action policy that achieves strong performance across simulated and real-world benchmarks, including zero-shot Panda arm manipulation and 16-DoF Allegro-hand dexterous cube re-orientation, and that the same video planner works across embodiments when paired with different IDMs.
What carries the argument
The embodiment-specific inverse dynamics model (IDM) based on the robot Jacobian, which converts predicted future video frames into executable joint actions without any retraining of the video planner.
If this is right
- The video planner remains embodiment-agnostic and can be swapped for other video models without retraining the IDM.
- The IDM trains independently on readily available self-play data and scales to high-dimensional action spaces such as 16-DoF hands.
- The same video planner produces viable policies on both a Panda arm and an Allegro hand when paired with the matching IDM.
- Closed-loop execution of the combined system yields strong performance on manipulation benchmarks without embodiment-specific finetuning of the planner.
Where Pith is reading between the lines
- If the Jacobian IDM remains accurate under contact-rich dynamics, the method could extend to tasks involving tool use or deformable objects with minimal extra data.
- Replacing the Jacobian IDM with a learned model trained on the same self-play data might further improve fidelity when analytic Jacobians are unavailable or noisy.
- Applying the decoupling to mobile bases or legged robots would test whether the video planner's predictions transfer when the action space changes more dramatically.
Load-bearing premise
An embodiment-specific IDM based on the robot Jacobian can accurately translate predictions from an action-free video model into executable actions without any joint training of the video planner on that embodiment's data.
What would settle it
Demonstrating that the Jacobian-based IDM produces joint commands whose resulting video trajectories deviate substantially from the video model's predictions on a new embodiment, causing task success rates to fall below those of jointly trained baselines.
Figures

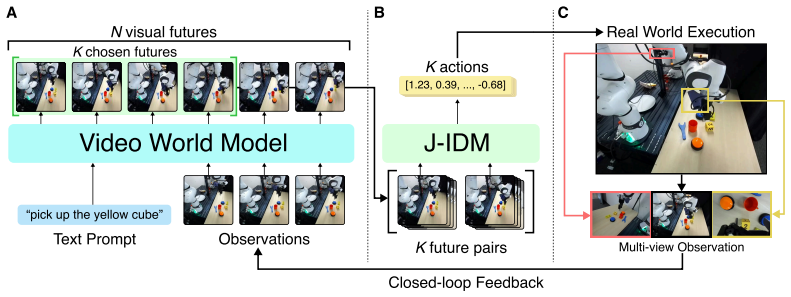


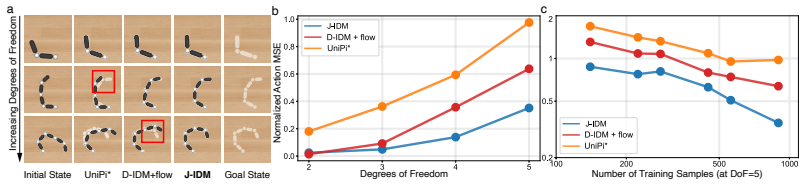


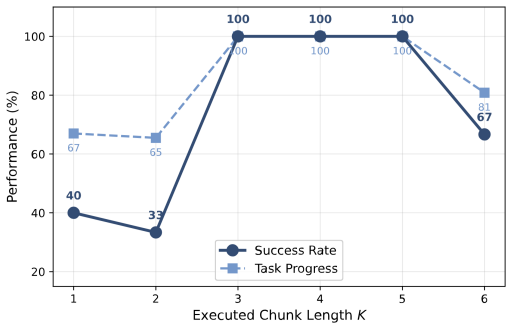
read the original abstract
Video generative models have emerged as a promising robotics backbone, capable of generating videos that depict the completion of complex tasks across embodiments and environments. Recent work proposes robot foundation models that jointly predict future observations and actions by finetuning video models with action-labeled data. In this paper, we test the limits of an alternative approach: leave the video planner as-is while training an embodiment-specific inverse dynamics model (IDM). This decoupling offers several natural benefits: the video planner remains embodiment-agnostic, different video models can be interchanged easily without re-training the IDM, and the IDM can be independently trained with readily available self-play data. We present a closed-loop, video-to-action policy that combines an action-free video world model with a carefully-designed IDM based on the robot embodiment Jacobian. We demonstrate that our IDM design is both data-efficient and scalable to high-dimensional action spaces. Our policy, which we coin the Video-to-Embodied Robot Action Model (VERA), achieves strong performance across simulated and real-world benchmarks, including zero-shot Panda arm manipulation and 16-DoF Allegro-hand dexterous cube re-orientation. The same video planner can be used across multiple embodiments by pairing it with different embodiment-specific IDMs. Our results show that decoupled video planning plus faithful video-to-action translation is a viable alternative route towards zero-shot, cross-embodiment, and generalizable robot control. More results are available on our project website: https://vera.csail.mit.edu.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VERA, a closed-loop video-to-action policy that decouples an action-free video world model (kept embodiment-agnostic) from an embodiment-specific inverse dynamics model (IDM) based on the robot Jacobian. It claims this separation enables easy interchange of video models, independent IDM training on self-play data, data-efficiency, and scalability to high-DoF actions, with strong performance on simulated and real-world benchmarks including zero-shot Panda arm manipulation and 16-DoF Allegro-hand dexterous cube re-orientation, positioning the approach as a viable route to zero-shot, cross-embodiment robot control.
Significance. If the empirical results hold, the decoupling strategy offers a practical alternative to joint video-action finetuning by preserving the video planner's generality and allowing embodiment-specific components to be trained separately. The claimed data-efficiency of the Jacobian IDM and its extension to 16-DoF actions represent concrete engineering contributions that could lower barriers to generalist policies. Explicit credit is due for the emphasis on interchangeability and the provision of a project website for additional results, which aids reproducibility in an empirical robotics setting.
major comments (2)
- [Abstract and IDM section] Abstract and Methods (IDM design): the central claim that a Jacobian-based IDM can faithfully translate action-free video predictions into executable actions without joint training on the target embodiment is load-bearing, yet the manuscript provides no quantitative evidence (metrics, baselines, ablations, or error analysis) on how video frames are mapped to the exact state representation required by the IDM; this is especially critical for the 16-DoF Allegro hand where small prediction discrepancies can produce large kinematic errors.
- [Results (Allegro hand experiments)] Results on 16-DoF Allegro hand: the zero-shot dexterous re-orientation result relies on closed-loop execution not accumulating errors from distribution shift between self-play IDM data and video-model rollouts, but no analysis of state-estimation accuracy or uncertainty handling is supplied to support that the differential kinematics inversion remains stable.
minor comments (2)
- [Abstract] The abstract states 'strong performance' and 'achieves strong performance across simulated and real-world benchmarks' without any numbers; moving quantitative results, baselines, and ablations into the abstract or a prominent table would improve readability.
- [Methods] Notation for the Jacobian IDM and video-to-state conversion should be defined more explicitly with equations to allow readers to verify the claimed parameter-free or data-efficient properties.
Simulated Author's Rebuttal
We thank the referee for the detailed review and positive assessment of the decoupling strategy. We address each major comment below and will revise the manuscript accordingly where additional evidence or discussion is warranted.
read point-by-point responses
-
Referee: [Abstract and IDM section] Abstract and Methods (IDM design): the central claim that a Jacobian-based IDM can faithfully translate action-free video predictions into executable actions without joint training on the target embodiment is load-bearing, yet the manuscript provides no quantitative evidence (metrics, baselines, ablations, or error analysis) on how video frames are mapped to the exact state representation required by the IDM; this is especially critical for the 16-DoF Allegro hand where small prediction discrepancies can produce large kinematic errors.
Authors: We agree that explicit quantitative characterization of the video-to-state mapping is important for the central claim. The Methods section details the Jacobian-based differential kinematics inversion used to convert predicted video frames into actions, and the overall policy results (including the 16-DoF Allegro experiments) serve as indirect validation. However, we acknowledge the absence of dedicated IDM-specific ablations, error metrics, or baselines on state estimation accuracy. We will add these analyses (including per-DoF error statistics on the Allegro hand) to the revised manuscript. revision: yes
-
Referee: [Results (Allegro hand experiments)] Results on 16-DoF Allegro hand: the zero-shot dexterous re-orientation result relies on closed-loop execution not accumulating errors from distribution shift between self-play IDM data and video-model rollouts, but no analysis of state-estimation accuracy or uncertainty handling is supplied to support that the differential kinematics inversion remains stable.
Authors: The closed-loop results on the Allegro hand demonstrate that the policy completes the re-orientation task without catastrophic failure, which we attribute to the data-efficient self-play training of the IDM and the embodiment-specific Jacobian design. We do not currently provide separate state-estimation accuracy curves or uncertainty quantification. We will expand the Results and Discussion sections with available state-tracking diagnostics from the experiments and a brief analysis of closed-loop stability to address this point. revision: partial
Circularity Check
No circularity: empirical decoupling of video planner and Jacobian IDM stands on independent components
full rationale
The paper's core claim rests on an empirical separation: an action-free video model is left unchanged while an embodiment-specific IDM (Jacobian-based) is trained separately on self-play data. No equations or results are shown to reduce by construction to fitted quantities defined by the target outcome; the video-to-action translation is presented as a testable engineering choice whose success is measured on external benchmarks (Panda, Allegro hand) rather than derived from the result itself. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text, and the derivation chain does not rename known patterns or smuggle assumptions via citation. The approach is therefore self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The robot embodiment Jacobian provides a sufficient mapping from video-predicted observations to executable actions.
Forward citations
Cited by 1 Pith paper
-
World Action Models: A Survey
A survey that clarifies boundaries and organizes World Action Models by generation requirements and predictive substrates, identifying a trend toward generating less of the future.
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InProceedings of the 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 2165–2183. PMLR,
-
[2]
URLhttps://proceedings.mlr.press/v229/zitkovich23a.html
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, G. Lam, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on R...
2025
-
[4]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . L. Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024. URL https://octo-models. github.io/
2024
-
[5]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision-language- action flow model for general robot control. InProceedings of Robotics: ...
-
[6]
URL https://www.roboticsproceedings.org/ rss21/p010.html
doi:10.15607/RSS.2025.XXI.010. URL https://www.roboticsproceedings.org/ rss21/p010.html
-
[7]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, b. ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
2025
-
[8]
J. Wang, M. Leonard, K. Daniilidis, D. Jayaraman, and E. Hu. Evaluating pi0 in the wild: Strengths, problems, and the future of generalist robot policies, 2025
2025
-
[9]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, H. Zhang, and M. Zhu. GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024. URL https: //arxiv.org/abs/2410.06158
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations. In Proceedings of the 42nd International Conference on Machine Learning, 2025. URL https: //proceedings.mlr.press/v267/hu25g.html. Spotlight. 9
2025
-
[11]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y . Shen, and Y . Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026. URL https://arxiv.org/abs/2601.21998. Introduces LingBot-V A, a video–action co- prediction framework
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y . Du, Y . Chebotar, S. Reed, J. Kautz, Y . Zhu, L. J. Fan, and J. Jang. World action mod...
-
[13]
URLhttps://arxiv.org/abs/2602.15922
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
S. Yang, Y . Du, S. K. S. Ghasemipour, J. Tompson, L. P. Kaelbling, D. Schuurmans, and P. Abbeel. Learning interactive real-world simulators. InInternational Conference on Learning Representations (ICLR), 2024. URLhttps://openreview.net/forum?id=sFyTZEqmUY
2024
-
[15]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. DINO-WM: World models on pre-trained visual features enable zero-shot planning. InProceedings of the 42nd International Conference on Machine Learning, 2025. URLhttps://proceedings.mlr.press/v267/zhou25t.html
2025
-
[16]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Y . Du, M. Yang, B. Dai, H. Dai, O. Nachum, J. B. Tenenbaum, D. Schuur- mans, and P. Abbeel. Learning universal policies via text-guided video gener- ation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1d5b9233ad716a43be5c0d3023cb82d0-Abstract-Conference.html
2023
-
[18]
P.-C. Ko, J. Mao, Y . Du, S.-H. Sun, and J. B. Tenenbaum. Learning to act from actionless videos through dense correspondences. InInternational Conference on Learning Representations (ICLR), 2024. URLhttps://openreview.net/forum?id=Mhb5fpA1T0
2024
-
[19]
Causal video models are data-efficient robot policy learners
Rhoda AI Research. Causal video models are data-efficient robot policy learners. Rhoda AI Research blog, 2026. URLhttps://www.rhoda.ai/research/direct-video-action
2026
-
[20]
B. Chen, T. Zhang, H. Geng, K. Song, C. Zhang, P. Li, W. T. Freeman, J. Malik, P. Abbeel, R. Tedrake, V . Sitzmann, and Y . Du. Large video planner enables generalizable robot control. arXiv preprint arXiv:2512.15840, 2025. URLhttps://arxiv.org/abs/2512.15840
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Allegro hand
Wonik Robotics. Allegro hand. https://www.allegrohand.com/sub/product/p.php? idx=1, 2024. Accessed: 2026-05-07
2024
-
[22]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. InProceedings of the 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Research, pages 1678–1690. PMLR, 2022. URL https://p...
2022
-
[23]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. BC- Z: Zero-shot task generalization with robotic imitation learning. InProceedings of the 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Research, pages 991–1002. PMLR, 2022. URL https://proceedings.mlr.press/v164/jang22a. html
2022
-
[24]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. In K. Liu, D. Kulic, and J. Ichnowski, editors,Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 785–799. PMLR, 14–18 Dec 2023. URL https://proceedings.mlr.press/v205/shridhar23a. html. 10
2023
-
[25]
Jiang, A
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. VIMA: Robot manipulation with multimodal prompts. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learnin...
2023
-
[26]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InProceedings of Robotics: Science and Systems, 2023. doi:10.15607/ RSS.2023.XIX.016. URL https://www.roboticsproceedings.org/rss19/p016.html. Action Chunking with Transformers (ACT)
2023
-
[27]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10–11):1684–1704, 2025. doi:10.1177/02783649241273668. URL https: //journals.sagepub.com/doi/10.1177/02783649241273668
-
[28]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, J....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. Palm-e: An embodied multimodal language model. InarXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
arXiv preprint arXiv:2306.11706 , year=
K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauza, T. Davchev, Y . Zhou, A. Gupta, A. Raju, A. Laurens, C. Fantacci, V . Dalibard, M. Zambelli, M. Martins, R. Pevce- viciute, M. Blokzijl, M. Denil, N. Batchelor, T. Lampe, E. Parisotto, K. ˙Zołna, S. Reed, S. G. Colmenarejo, J. Scholz, A. Abdolmaleki, O. Groth, J.-B. Regli, O. Sushkov, T. Rot...
-
[31]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakrishna, A. Wahid...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Brooks, B
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y . Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman, C. Ng, R. Wang, and A. Ramesh. Video generation models as world simulators. OpenAI Technical Report, 2024. URL https://openai.com/index/ video-generation-models-as-world-simulators/
2024
-
[33]
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng, D. Yin, Y . Zhang, W. Wang, Y . Cheng, B. Xu, X. Gu, Y . Dong, and J. Tang. CogVideoX: Text- to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://openreview.net/forum?id=LQzN6TRFg9
2025
-
[34]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. URLhttps://arxiv.org/abs/2503.20314
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
B. Chen, D. Martí Monsó, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitz- mann. Diffusion forcing: Next-token prediction meets full-sequence diffu- sion. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 2aee1c4159e48407d68fe16ae8e6e49e-Abstract-Conference.html
2024
-
[36]
K. Song, B. Chen, M. Simchowitz, Y . Du, R. Tedrake, and V . Sitzmann. History-guided video diffusion. InProceedings of the 42nd International Conference on Machine Learning, 2025. URLhttps://proceedings.mlr.press/v267/song25b.html
2025
-
[37]
Bruce, M
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, Y . Aytar, S. M. E. Bechtle, F. Behbahani, S. C. Y . Chan, N. Heess, L. Gonzalez, S. Osindero, S. Ozair, S. Reed, J. Zhang, K. Zolna, J. Clune, N. de Freitas, S. Singh, and T. Rocktäschel. Genie: Generative interactive environments. In...
2024
-
[38]
Y . Tian, S. Yang, J. Zeng, P. Wang, D. Lin, H. Dong, and J. Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation.arXiv preprint arXiv:2412.15109, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video- action models for generalizable robot control beyond vlas.arXiv preprint 2512.15692, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
S. L. Li, A. Zhang, B. Chen, H. Matusik, C. Liu, D. Rus, and V . Sitzmann. Control- ling diverse robots by inferring jacobian fields with deep networks.Nature, 643:89–95,
-
[41]
URL https://www.nature.com/articles/ s41586-025-09170-0
doi:10.1038/s41586-025-09170-0. URL https://www.nature.com/articles/ s41586-025-09170-0. 12
-
[42]
Z. Teed and J. Deng. Raft: Recurrent all-pairs field transforms for optical flow, 2020. URL https://arxiv.org/abs/2003.12039
-
[43]
C. Doersch, Y . Yang, M. Vecerik, D. Gokay, A. Gupta, Y . Aytar, J. Carreira, and A. Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement, 2023. URL https://arxiv.org/abs/2306.08637
-
[44]
A. W. Harley, Y . You, X. Sun, Y . Zheng, N. Raghuraman, Y . Gu, S. Liang, W.-H. Chu, A. Dave, P. Tokmakov, S. You, R. Ambrus, K. Fragkiadaki, and L. J. Guibas. AllTracker: Efficient dense point tracking at high resolution. InICCV, 2025
2025
- [45]
-
[46]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
- [47]
-
[48]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[49]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. In7th Annual Conference on Robot Learning, 2023
2023
-
[50]
H. J. T. Suh, T. Pang, T. Zhao, and R. Tedrake. Dexterous contact-rich manipulation via the contact trust region.The International Journal of Robotics Research, 2026. doi: 10.1177/02783649251398875. URL https://journals.sagepub.com/doi/10.1177/ 02783649251398875
-
[51]
T. Chen, J. Xu, and P. Agrawal. A system for general in-hand object re-orientation. In Conference on robot learning, pages 297–307. PMLR, 2022
2022
- [52]
-
[53]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without super...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.