DriveWAM: Video Generative Priors Enable Scalable World-Action Modeling for Autonomous Driving
Pith reviewed 2026-06-29 13:39 UTC · model grok-4.3
The pith
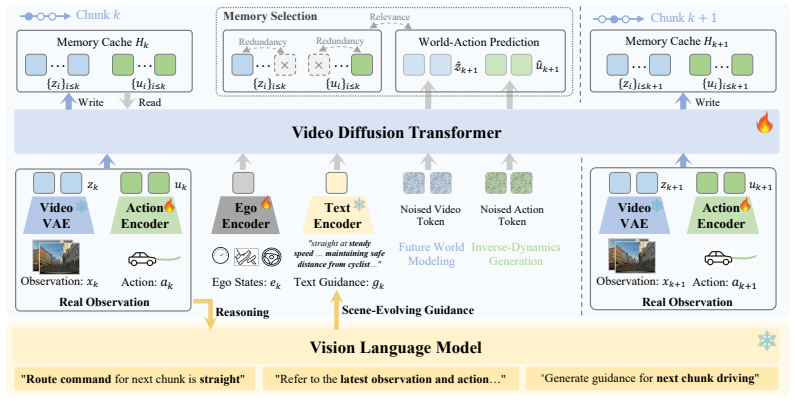
DriveWAM adapts a pretrained video diffusion transformer into an autoregressive video-action policy by unifying video frames and driving actions in a single token sequence under joint flow matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
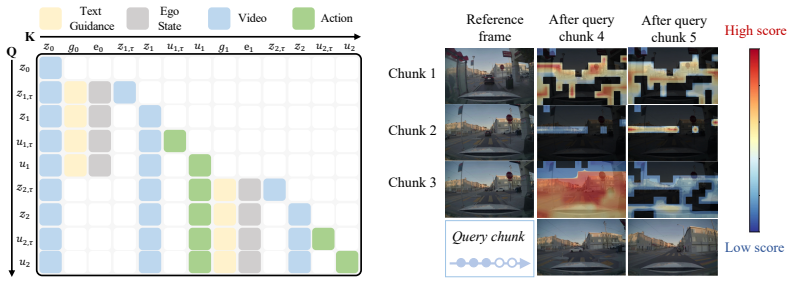
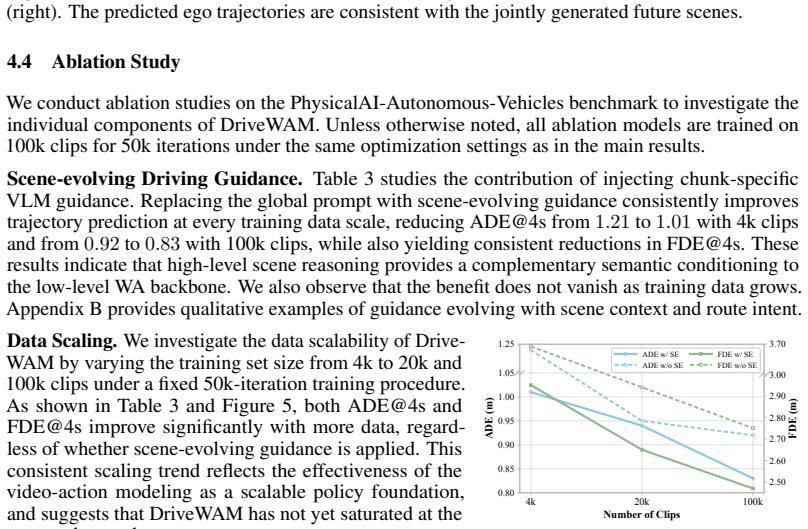
DriveWAM organizes video and action streams into a unified temporal token sequence and trains them under a joint flow-matching objective, preserving the pretrained video-generation architecture while adapting its large-scale video priors to action generation. Scene-evolving driving guidance from a frozen VLM supplies chunk-specific semantic intent, and selective KV memory maintains bounded modality-aware pools through relevance-redundancy selection at inference. Experiments on NAVSIM and the PhysicalAI-Autonomous-Vehicles benchmark show strong planning performance, and a data-scaling study from 4k to 100k driving clips confirms the scaling potential of world-action modeling for end-to-end au
What carries the argument
Unified temporal token sequence of video and actions trained with joint flow-matching on a frozen video diffusion transformer backbone.
If this is right
- Strong planning performance is achieved on NAVSIM and PhysicalAI-Autonomous-Vehicles benchmarks.
- Performance improves as training data increases from 4k to 100k driving clips.
- Scene-evolving guidance from a frozen VLM supplies high-level intent to the generation process.
- Selective KV memory keeps long-horizon video-action rollouts computationally bounded.
Where Pith is reading between the lines
- The same unified-sequence approach could be tested on other embodied control problems where video priors already exist, such as robotic navigation.
- If the scaling trend continues beyond 100k clips, the method would imply that collecting larger unlabeled driving video sets becomes the dominant lever for policy improvement.
- The selective memory mechanism suggests a general pattern for keeping autoregressive world models tractable in any long-horizon visual task.
- Combining the frozen VLM guidance with additional modalities like lidar or maps could be explored without retraining the core transformer.
Load-bearing premise
The joint flow-matching objective on the unified video-action token sequence successfully transfers the pretrained video-generation priors to action generation without requiring substantial architectural changes.
What would settle it
If planning metrics on NAVSIM or PhysicalAI-Autonomous-Vehicles show no improvement when training data scales from 4k to 100k clips, or if DriveWAM performs no better than the unmodified video model, the transfer of priors would be falsified.
Figures




read the original abstract
Pretrained foundation models have become an important basis for end-to-end autonomous driving. In contrast to vision-language models pretrained primarily on static image-text pairs, video generative models capture temporal dynamics and motion priors that are naturally suited for driving. We present DriveWAM, a driving world-action model that adapts a pretrained video diffusion transformer into an autoregressive video-action policy. DriveWAM organizes video and action streams into a unified temporal token sequence and trains them under a joint flow-matching objective, preserving the pretrained video-generation architecture while adapting its large-scale video priors to action generation. To incorporate high-level scene understanding, we introduce scene-evolving driving guidance, where a frozen VLM produces chunk-specific semantic intent to guide video-action generation. To keep long-horizon rollout bounded, we further introduce selective KV memory, which maintains bounded modality-aware video and action memory pools through relevance-redundancy cache selection at inference time. Experiments on NAVSIM and the PhysicalAI-Autonomous-Vehicles benchmark show that DriveWAM achieves strong planning performance, and a data-scaling study from 4k to 100k driving clips further confirms the scaling potential of world-action modeling for end-to-end autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DriveWAM, a driving world-action model that adapts a pretrained video diffusion transformer into an autoregressive video-action policy. The model unifies video and action streams into a temporal token sequence trained under a joint flow-matching objective to preserve video-generation priors. It adds scene-evolving driving guidance using a frozen VLM for semantic intent and selective KV memory for bounded long-horizon rollouts. Experiments on NAVSIM and PhysicalAI-Autonomous-Vehicles benchmarks are claimed to show strong planning performance, with a scaling study from 4k to 100k clips supporting the approach's potential for end-to-end autonomous driving.
Significance. If the experimental results hold, the paper would make a significant contribution by demonstrating an effective method to transfer large-scale video generative priors to action generation for driving tasks. The joint objective and memory management techniques could enable scalable world-action modeling, with the data scaling study providing evidence for the benefits of larger datasets in this domain.
major comments (1)
- Abstract: The abstract asserts 'strong planning performance' and 'scaling potential' but supplies no quantitative metrics, baseline comparisons, ablation results, or error analysis. Without these details the support for the central claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment. We agree that the abstract would benefit from greater specificity to support its claims and will revise it accordingly in the next version of the manuscript.
read point-by-point responses
-
Referee: Abstract: The abstract asserts 'strong planning performance' and 'scaling potential' but supplies no quantitative metrics, baseline comparisons, ablation results, or error analysis. Without these details the support for the central claim cannot be evaluated.
Authors: We agree with this observation. The current abstract is intentionally concise but does not include the specific numbers that would allow readers to immediately assess the strength of the reported results. In the revised manuscript we will expand the abstract to include the primary quantitative outcomes (e.g., planning metrics on NAVSIM and PhysicalAI-Autonomous-Vehicles, the performance delta relative to the strongest baselines, and the scaling trend from 4k to 100k clips) while remaining within typical abstract length limits. This change directly addresses the concern without altering the technical content of the paper. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description present DriveWAM as an empirical adaptation of an external pretrained video diffusion transformer using a joint flow-matching objective on unified video-action tokens, with scene guidance from a frozen VLM and selective KV memory. Performance is validated on external benchmarks (NAVSIM, PhysicalAI-Autonomous-Vehicles) and a scaling study from 4k to 100k clips. No equations, fitted parameters renamed as predictions, self-citations, or derivation steps that reduce claims to inputs by construction are present. The approach is self-contained against external benchmarks with no load-bearing internal reductions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 4 Pith papers
-
Kamera: Unified Position-Invariant Multimodal KV Cache for Training-Free Reuse
Kamera stores a low-rank patch with each position-free KV chunk to restore cross-chunk conditioning lost in naive reuse, enabling cheap reordering, sliding windows, and recall across attention mechanisms.
-
Diffusion Transformer World-Action Model for AV Scene Prediction
A Diffusion Transformer world model in V-JEPA2 latent space predicts action-conditioned future scenes on nuScenes, outperforming regression on KID/FID while preserving steering controllability and adding a jump model ...
-
Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
Discrete-WAM unifies world modeling and policy learning for autonomous driving by representing observations, states, decisions, and actions as tokens in one space and using hierarchical token editing for planning.
-
World Action Models: A Survey
A survey that clarifies boundaries and organizes World Action Models by generation requirements and predictive substrates, identifying a trend toward generating less of the future.
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
DriveVLA-w0: World models amplify data scaling law in autonomous driving
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, AnYasong, Chufeng Tang, Lu Hou, Lue Fan, and Zhaoxiang Zhang. DriveVLA-w0: World models amplify data scaling law in autonomous driving. InICLR, 2026
2026
-
[4]
Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. InICLR, 2026
2026
-
[5]
Simlingo: Vision-only closed-loop autonomous driving with language-action alignment
Katrin Renz, Long Chen, Elahe Arani, and Oleg Sinavski. Simlingo: Vision-only closed-loop autonomous driving with language-action alignment. InCVPR, 2025
2025
-
[6]
Drivemoe: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving
Zhenjie Yang, Yilin Chai, Xiaosong Jia, Qifeng Li, Yuqian Shao, Xuekai Zhu, Haisheng Su, and Junchi Yan. Drivemoe: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving. InCVPR, 2026
2026
-
[7]
Langcoop: Collaborative driving with language
Xiangbo Gao, Yuheng Wu, Rujia Wang, Chenxi Liu, Yang Zhou, and Zhengzhong Tu. Langcoop: Collaborative driving with language. InCVPR, 2025
2025
-
[8]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023
2023
-
[11]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. InNeurIPS, 2022
2022
-
[13]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Yang Zhou, Xiaofeng Wang, Hao Shao, Letian Wang, Guosheng Zhao, Jiangnan Shao, Jiagang Zhu, Tingdong Yu, Zheng Zhu, Guan Huang, et al. Drivedreamer-policy: A geometry-grounded world-action model for unified generation and planning.arXiv preprint arXiv:2604.01765, 2026
-
[15]
Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, and Xing Wei. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving. InNeurIPS, 2025
2025
-
[16]
Cosmos policy: Fine-tuning video models for visuomotor control and planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. InICLR, 2026. 10
2026
-
[17]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, et al. Gigaworld-policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
-
[21]
Video prediction policy: A generalist robot policy with predictive visual representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations. InICML, 2025
2025
-
[22]
Xingtai Gui, Meijie Zhang, Tianyi Yan, Wencheng Han, Jiahao Gong, Feiyang Tan, Cheng-zhong Xu, and Jianbing Shen. Bridging scene generation and planning: Driving with world model via unifying vision and motion representation.arXiv preprint arXiv:2603.14948, 2026
-
[23]
Florent Bartoccioni, Elias Ramzi, Victor Besnier, Shashanka Venkataramanan, Tuan-Hung Vu, Yihong Xu, Loick Chambon, Spyros Gidaris, Serkan Odabas, David Hurych, Renaud Marlet, Alexandre Boulch, Mickael Chen, Eloi Zablocki, Andrei Bursuc, Eduardo Valle, and Matthieu Cord. Vavim and vavam: Autonomous driving through video generative modeling.arXiv preprint ...
-
[24]
Epona: Autoregressive diffusion world model for autonomous driving
Kaiwen Zhang, Zhenyu Tang, Xiaotao Hu, Xingang Pan, Xiaoyang Guo, Yuan Liu, Jingwei Huang, Li Yuan, Qian Zhang, Xiao-Xiao Long, et al. Epona: Autoregressive diffusion world model for autonomous driving. InICCV, 2025
2025
-
[25]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[26]
Flow caching for autoregressive video generation
Yuexiao Ma, Xuzhe Zheng, Jing Xu, Xiwei Xu, Feng Ling, Xiawu Zheng, Huafeng Kuang, Huixia Li, Xing Wang, Xuefeng Xiao, et al. Flow caching for autoregressive video generation. InICLR, 2026
2026
-
[27]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. InNeurIPS, 2024
2024
-
[28]
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Diamond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters, 2024
2024
-
[30]
Drivevlm: The convergence of autonomous driving and large vision-language models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Zhiyong Zhao, Yang Wang, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. InCoRL, 2024
2024
-
[31]
Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
Bo Jiang, Shaoyu Chen, Bencheng Liao, Xingyu Zhang, Wei Yin, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Senna: Bridging large vision-language models and end-to-end autonomous driving. arXiv preprint arXiv:2410.22313, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
DriveLM: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. DriveLM: Driving with graph visual question answering. In ECCV, 2024
2024
-
[33]
Wenhai Wang, Jiangwei Xie, ChuanYang Hu, Haoming Zou, Jianan Fan, Wenwen Tong, Yang Wen, Silei Wu, Hanming Deng, Zhiqi Li, et al. Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving.arXiv preprint arXiv:2312.09245, 2023
-
[34]
A language agent for autonomous driving.arXiv preprint arXiv:2311.10813, 2023
Jiageng Mao, Junjie Ye, Yuxi Qian, Marco Pavone, and Yue Wang. A language agent for autonomous driving.arXiv preprint arXiv:2311.10813, 2023. 11
-
[35]
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M. Alvarez. OmniDrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. InCVPR, 2025
2025
-
[36]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving. arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma
Zewei Zhou, Tianhui Cai, Seth Z. Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Au- toVLA: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning. InNeurIPS, 2025
2025
-
[38]
MoVQ: Modulating quantized vectors for high-fidelity image generation
Chuanxia Zheng, Long Tung Vuong, Jianfei Cai, and Dinh Phung. MoVQ: Modulating quantized vectors for high-fidelity image generation. InNeurIPS, 2022
2022
-
[39]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[40]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan.Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer. In ICLR, 2025
2025
-
[42]
Neural discrete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. InNeurIPS, 2017
2017
-
[43]
Language models are unsupervised multitask learners.OpenAI blog, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 2019
2019
-
[44]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InNeurIPS, 2025
2025
-
[45]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InNeurIPS, 2024
2024
-
[46]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InCVPR, 2025
2025
-
[47]
Sparse video-gen: Accelerating video diffusion transformers with spatial-temporal sparsity
Haocheng Xi, Shuo Yang, Yilong Zhao, Chenfeng Xu, Muyang Li, Xiuyu Li, Yujun Lin, Han Cai, Jintao Zhang, Dacheng Li, Jianfei Chen, Ion Stoica, Kurt Keutzer, and Song Han. Sparse video-gen: Accelerating video diffusion transformers with spatial-temporal sparsity. InICML, 2025
2025
-
[48]
Sparse videogen2: Accelerate video generation with sparse attention via semantic-aware permutation
Shuo Yang, Haocheng Xi, Yilong Zhao, Muyang Li, Jintao Zhang, Han Cai, Yujun Lin, Xiuyu Li, Chenfeng Xu, Kelly Peng, Jianfei Chen, Song Han, Kurt Keutzer, and Ion Stoica. Sparse videogen2: Accelerate video generation with sparse attention via semantic-aware permutation. InNeurIPS, 2025
2025
-
[49]
Adaptive caching for faster video generation with diffusion transformers
Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S Ryoo, and Tian Xie. Adaptive caching for faster video generation with diffusion transformers. InICCV, 2025
2025
-
[50]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023
2023
-
[51]
Fifo-diffusion: Generating infinite videos from text without training.NeurIPS, 2024
Jihwan Kim, Junoh Kang, Jinyoung Choi, and Bohyung Han. Fifo-diffusion: Generating infinite videos from text without training.NeurIPS, 2024
2024
-
[52]
Chaoda Zheng, Sean Li, Jinhao Deng, Zhennan Wang, Shijia Chen, Liqiang Xiao, Ziheng Chi, Hongbin Lin, Kangjie Chen, Boyang Wang, et al. X-world: Controllable ego-centric multi-camera world models for scalable end-to-end driving.arXiv preprint arXiv:2603.19979, 2026
-
[53]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InCVPR, 2023
2023
-
[55]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.TPAMI, 2023
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.TPAMI, 2023. 12
2023
-
[56]
Para-drive: Parallelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Parallelized architecture for real-time autonomous driving. InCVPR, 2024
2024
-
[57]
Enhancing end-to-end autonomous driving with latent world model
Yingyan Li, Lue Fan, Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang, and Tieniu Tan. Enhancing end-to-end autonomous driving with latent world model. InICLR, 2025
2025
-
[58]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InCVPR, 2025
2025
-
[59]
End-to-end driving with online trajectory evaluation via bev world model
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via bev world model. InICCV, 2025
2025
-
[60]
Openscene: The largest up-to-date 3d occupancy prediction benchmark in autonomous driving.https://github.com/OpenDriveLab/OpenScene, 2023
OpenScene Contributors. Openscene: The largest up-to-date 3d occupancy prediction benchmark in autonomous driving.https://github.com/OpenDriveLab/OpenScene, 2023
2023
-
[61]
Towards learning-based planning: The nuplan benchmark for real-world autonomous driving
Napat Karnchanachari, Dimitris Geromichalos, Kok Seang Tan, Nanxiang Li, Christopher Eriksen, Shakiba Yaghoubi, Noushin Mehdipour, Gianmarco Bernasconi, Whye Kit Fong, Yiluan Guo, et al. Towards learning-based planning: The nuplan benchmark for real-world autonomous driving. InICRA, 2024
2024
-
[62]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019
2019
-
[63]
Generalized predictive model for autonomous driving
Jiazhi Yang, Shenyuan Gao, Yihang Qiu, Li Chen, Tianyu Li, Bo Dai, Kashyap Chitta, Penghao Wu, Jia Zeng, Ping Luo, et al. Generalized predictive model for autonomous driving. InCVPR, 2024. 13 A Dataset Curation The PhysicalAI-Autonomous-Vehicles benchmark contains roughly 1,700 hours of driving organized into 306,152 20-second clips. To focus evaluation a...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.