How VLAs Fail Differently: Black-Box Action Monitoring Reveals Architecture-Specific Failure Signatures
Pith reviewed 2026-06-29 11:37 UTC · model grok-4.3
The pith
Direction reversal rate predicts failures across all tested VLA architectures while jerk and velocity monitoring do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
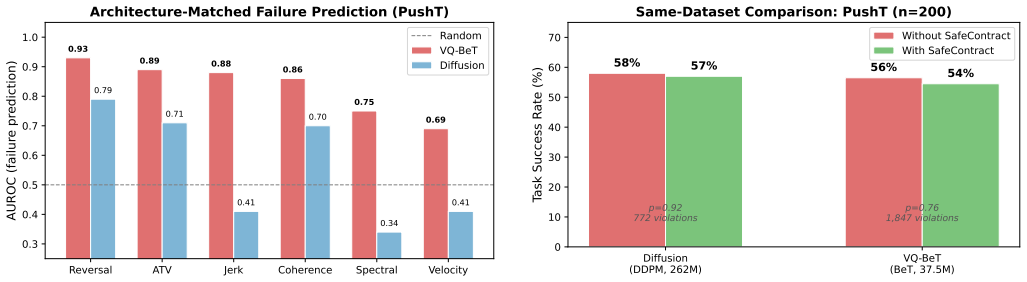
When VQ-BeT, Diffusion Policy, and ACT are run on the same 450-episode protocols in PushT and ALOHA, direction reversal rate yields AUROC values of 0.93, 0.79, and 0.91 for failure prediction; jerk monitoring shows a discrete-to-continuous gradient (0.88, 0.69, 0.41); velocity violations remain non-predictive (0.41–0.69) everywhere; and continuous-family models receive essentially zero signal from velocity (0.52 on ACT, 0.41 on Diffusion). These signatures demonstrate that the discrete/continuous distinction produces qualitatively different failure modes that require different black-box monitors.
What carries the argument
SafeContract, a training-free black-box action monitoring toolkit that applies conformal calibration to motor-command metrics (direction reversal rate, jerk, velocity violations) across discrete-token and continuous VLA families.
If this is right
- No single monitor works for every VLA architecture.
- Velocity checking, the most common safety mechanism in deployment code, supplies effectively zero predictive signal for continuous-family VLAs.
- Jerk monitoring is useful only for discrete-token architectures and loses value along the discrete-to-continuous gradient.
- Architecture-matched monitor selection is required for reliable VLA deployment.
Where Pith is reading between the lines
- Continuous VLAs may produce smoother trajectories that evade reversal- and jerk-based detection, suggesting a need for smoothness-derived metrics tailored to them.
- The black-box approach could be applied at training time to penalize architecture-specific failure signatures before deployment.
- Similar monitoring differences may appear in other continuous versus discrete control policies outside the VLA setting.
Load-bearing premise
The evaluation protocols are identical across architectures and the three chosen metrics capture the relevant failure modes without task-specific artifacts or labeling biases in PushT and ALOHA.
What would settle it
A new evaluation on additional VLA architectures or tasks in which direction reversal rate yields AUROC below 0.7 for failure prediction while the paper's reported values remain above 0.79 would falsify the universality claim.
Figures
read the original abstract
We discover that VLA architectures fail in fundamentally different, predictable ways at the motor-command level. Running VQ-BeT, Diffusion Policy, and ACT on identical evaluation protocols (n=450 episodes across PushT and ALOHA 14-DOF bimanual manipulation), we find: (1) direction reversal rate is a universal failure predictor across all three architectures (AUROC=0.93, 0.79, 0.91; p<0.001); (2) jerk monitoring is predictive only for discrete-token architectures, following a discrete-to-continuous gradient (0.88, 0.69, 0.41); (3) velocity violations alone are non-predictive everywhere (AUROC 0.41-0.69), yet velocity checking is the most common safety mechanism in VLA deployment code; and (4) for continuous-family VLAs, velocity monitoring provides effectively zero predictive signal (AUROC=0.52 on ACT, 0.41 on Diffusion), proving that architecture-matched monitor selection is essential. These results quantify a monitoring consequence of the well-known discrete/continuous VLA distinction: the two families produce qualitatively different failure signatures that require different monitors. No single monitor works universally; architecture-matched selection is required. This finding was enabled by SafeContract, a training-free, black-box action monitoring toolkit with conformal calibration. Code: https://github.com/krishnam94/vla-edge
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLA architectures (VQ-BeT, Diffusion Policy, ACT) produce distinct failure signatures at the motor-command level. Using identical protocols on 450 episodes across PushT and ALOHA tasks and the black-box SafeContract toolkit, it reports that direction reversal rate universally predicts failures (AUROCs 0.93/0.79/0.91, p<0.001), jerk monitoring follows a discrete-to-continuous gradient (0.88/0.69/0.41), and velocity monitoring is non-predictive (AUROCs 0.41-0.69), implying that architecture-matched monitors are required rather than universal ones.
Significance. If the empirical distinctions hold, the work quantifies a practical consequence of the discrete/continuous VLA distinction for safety monitoring and shows that common velocity-based checks provide little signal. The open-source SafeContract code and conformal calibration are strengths that support reproducibility and potential adoption in deployment pipelines.
major comments (2)
- [Experimental setup and metric definitions] The operational definition of direction reversal rate is not specified for each architecture. Because VQ-BeT uses discrete tokens while Diffusion Policy and ACT use continuous trajectories, any sign-change or delta-based computation is likely non-identical; without explicit per-architecture formulas or an invariant definition, the AUROCs cannot be compared to support the universality claim.
- [Evaluation protocol] Details on failure labeling, exact episode success criteria, and potential confounds in the black-box action monitoring for the 450 episodes (PushT and ALOHA) are absent. This directly affects the reliability of the reported AUROCs and p-values that underpin all four main findings.
minor comments (1)
- [Introduction] The abstract introduces SafeContract but the main text would benefit from a short dedicated subsection describing its conformal calibration procedure and black-box interface.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback on the experimental details. Below we respond point-by-point to the major comments. We will revise the manuscript to incorporate additional clarifications where needed.
read point-by-point responses
-
Referee: [Experimental setup and metric definitions] The operational definition of direction reversal rate is not specified for each architecture. Because VQ-BeT uses discrete tokens while Diffusion Policy and ACT use continuous trajectories, any sign-change or delta-based computation is likely non-identical; without explicit per-architecture formulas or an invariant definition, the AUROCs cannot be compared to support the universality claim.
Authors: We agree that the manuscript should provide explicit, comparable definitions to substantiate the universality claim. In the revised version we will add a dedicated Methods subsection with the invariant definition used: direction reversal rate is the fraction of consecutive action steps in which the sign of the first difference (delta) changes. For VQ-BeT the discrete tokens are decoded to continuous joint values before delta computation; for Diffusion Policy and ACT the deltas are taken directly on the continuous trajectories. Pseudocode and per-architecture implementation notes will be included to allow direct replication of the reported AUROCs. revision: yes
-
Referee: [Evaluation protocol] Details on failure labeling, exact episode success criteria, and potential confounds in the black-box action monitoring for the 450 episodes (PushT and ALOHA) are absent. This directly affects the reliability of the reported AUROCs and p-values that underpin all four main findings.
Authors: We acknowledge that the current text references the benchmark protocols without sufficient expansion. In revision we will add an explicit Evaluation Protocol subsection stating: episodes are labeled failures if the task-specific success metric is not met within the allotted horizon (PushT: puck-to-target distance > 0.05 m at termination; ALOHA: sequence not completed or collision detected). The 450 episodes comprise 150 per architecture across the two tasks. SafeContract performs black-box monitoring solely on the published action stream; we will discuss potential confounds such as action quantization effects and how conformal calibration is applied to control false-positive rates. These additions will directly support the reported statistical results. revision: yes
Circularity Check
No circularity; results are direct empirical measurements under stated protocols.
full rationale
The paper reports AUROC values computed from running three architectures on identical evaluation protocols (n=450 episodes) and measuring action-level statistics such as direction reversal rate. No equations, fitted parameters, or derivations are presented that reduce to their own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on observable experimental outcomes that can be replicated or falsified externally; the metric definitions and protocols are described as fixed and shared across architectures rather than tuned per model. This is the normal case of an empirical study whose findings are not equivalent to its inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math AUROC and p-value calculations are statistically valid for the reported sample size
Reference graph
Works this paper leans on
-
[1]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brohan, A. et al., “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control,” CoRL 2023, arXiv:2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J. et al., “OpenVLA: An Open-Source Vision-Language-Action Model,” CoRL 2024, arXiv:2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Shukor, M. et al., “SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics,” arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
LeRobot: State-of-the-art Machine Learning for Real-World Robotics in PyTorch,
Cadene, R. et al., “LeRobot: State-of-the-art Machine Learning for Real-World Robotics in PyTorch,” 2024, https://github.com/huggingface/ lerobot
2024
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K. et al., “π 0: A Vision-Language-Action Flow Model for General Robot Control,” arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning
Zhang, B. et al., “SafeVLA: Towards Safety Alignment of Vision- Language-Action Model via Constrained Learning,” NeurIPS 2025, arXiv:2503.03480
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
VLSA: Vision-Language-Action Models with Plug-and- Play Safety Constraint Layer,
Hu, S. et al., “VLSA: Vision-Language-Action Models with Plug-and- Play Safety Constraint Layer,” arXiv:2512.11891, 2025
-
[8]
Constrained Decoding for Safe Robot Navigation Foundation Models
Kapoor, P. et al., “Constrained Decoding for Robotics Foundation Models,” arXiv:2509.01728, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
On Robustness of Vision-Language-Action Model against Multi-Modal Perturbations,
Guo, J. et al., “On Robustness of Vision-Language-Action Model against Multi-Modal Perturbations,” ICLR 2026, arXiv:2510.00037
-
[10]
SafeDiffuser: Safe Planning with Diffusion Probabilistic Models,
Xiao, W. et al., “SafeDiffuser: Safe Planning with Diffusion Probabilistic Models,” ICLR 2025, arXiv:2306.00148
-
[11]
CoDiG: Constraint-Aware Diffusion Guidance for Robotics: Real-Time Obstacle Avoidance,
Ma, H. et al., “CoDiG: Constraint-Aware Diffusion Guidance for Robotics: Real-Time Obstacle Avoidance,” CoRL 2025, arXiv:2505.13131
-
[12]
Towards Safe Robot Foundation Models Using Induc- tive Biases,
T ¨olle, M. et al., “Towards Safe Robot Foundation Models Using Induc- tive Biases,” arXiv:2505.10219, 2025
-
[13]
Unpacking Failure Modes of Generative Poli- cies: Runtime Monitoring of Consistency and Progress,
Agia, C. et al., “Unpacking Failure Modes of Generative Poli- cies: Runtime Monitoring of Consistency and Progress,” CoRL 2024, arXiv:2410.04640
-
[14]
Algorithmic Learning in a Random World,
V ovk, V . et al., “Algorithmic Learning in a Random World,” Springer, 2005
2005
-
[15]
Continuous Inspection Schemes,
Page, E.S., “Continuous Inspection Schemes,” Biometrika 41(1/2):100– 115, 1954
1954
-
[16]
SAFE: Multitask Failure Detection for Vision-Language- Action Models,
Gu, Q. et al., “SAFE: Multitask Failure Detection for Vision-Language- Action Models,” NeurIPS 2025, arXiv:2506.09937
-
[17]
Failure Prediction at Runtime for Generative Robot Policies,
R ¨omer, R. et al., “Failure Prediction at Runtime for Generative Robot Policies,” NeurIPS 2025, arXiv:2510.09459
-
[18]
Conformal Safety Monitoring for Flight Testing: A Case Study in Data-Driven Safety Learning,
Feldman, A.O. et al., “Conformal Safety Monitoring for Flight Testing: A Case Study in Data-Driven Safety Learning,” arXiv:2511.20811, 2025
-
[19]
Adaptive Conformal Inference Under Distri- bution Shift,
Gibbs, I. and Cand `es, E., “Adaptive Conformal Inference Under Distri- bution Shift,” NeurIPS 2021, arXiv:2106.00170
-
[20]
Modular Safety Guardrails Are Necessary for Foundation-Model-Enabled Robots in the Real World,
Kim, J. et al., “Modular Safety Guardrails Are Necessary for Foundation-Model-Enabled Robots in the Real World,” arXiv:2602.04056, 2026
-
[21]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Chi, C. et al., “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,” RSS 2023, arXiv:2303.04137
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Behavior Generation with Latent Actions,
Lee, S. et al., “Behavior Generation with Latent Actions,” ICML 2024, arXiv:2403.03181
-
[23]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, T.Z. et al., “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,” RSS 2023, arXiv:2304.13705
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.