Large Depth Completion Model from Sparse Observations
Pith reviewed 2026-06-29 08:16 UTC · model grok-4.3
The pith
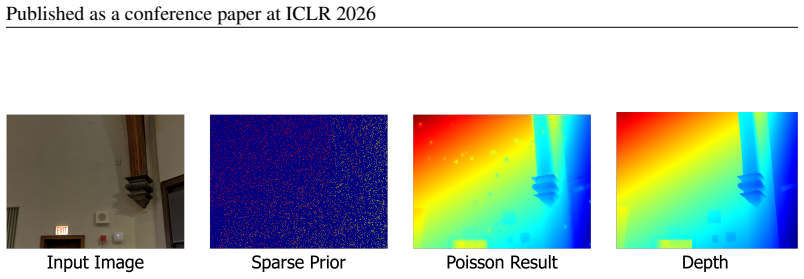
LDCM uses a point map head and Poisson initialization to output metric-scaled 3D points from sparse single-view observations without camera intrinsics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
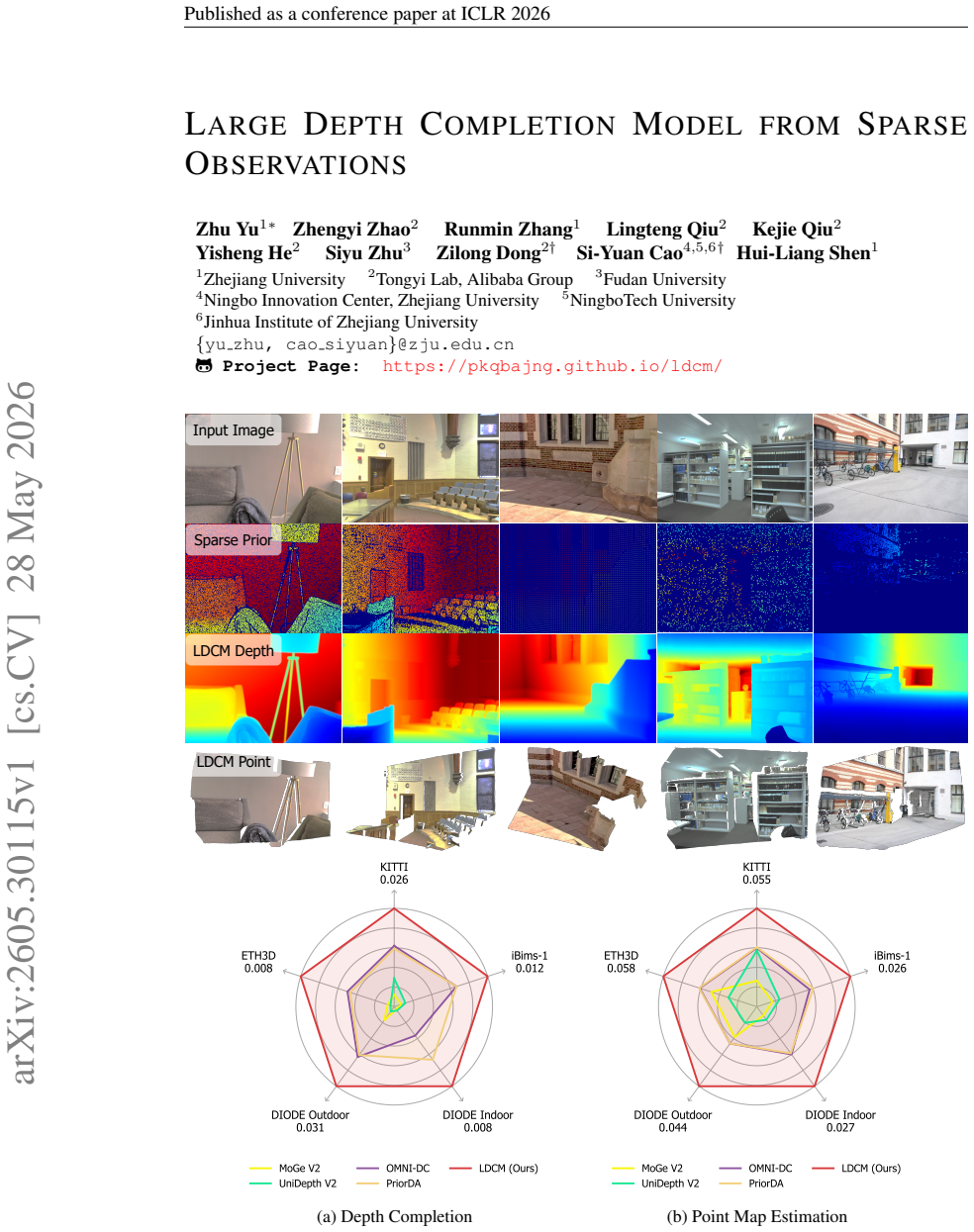
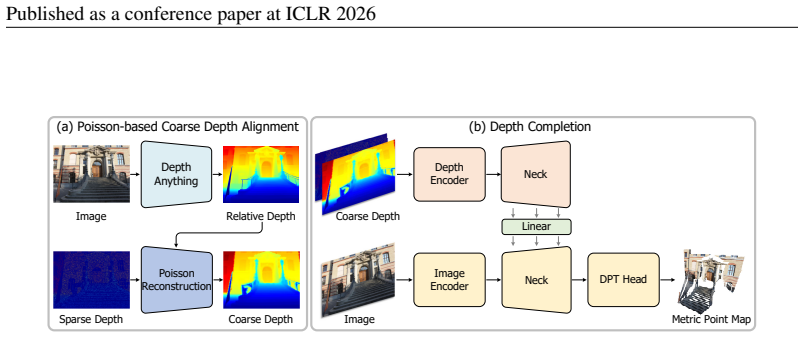
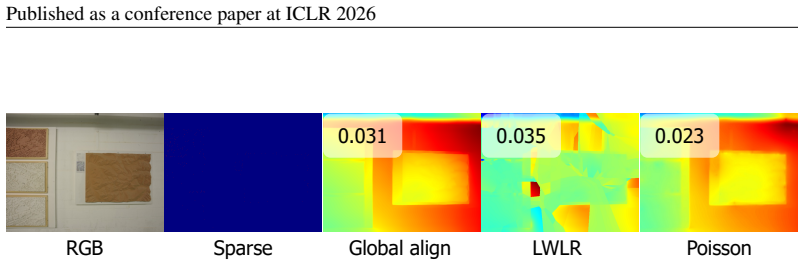
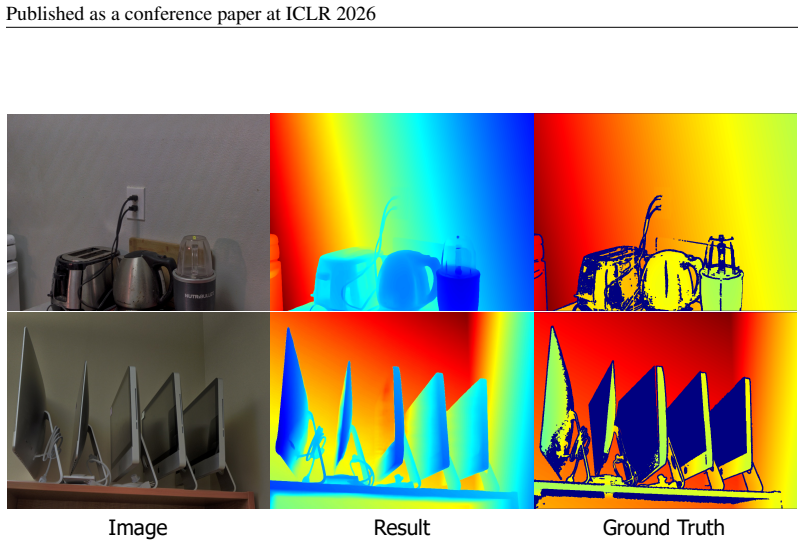
LDCM generates metric-accurate dense depth maps from sparse observations by first using monocular foundation models to refine inputs and then applying a Poisson-based strategy to produce a uniform coarse dense depth map as structural prior. Replacing the depth head with a point map head that regresses per-pixel 3D coordinates allows the network to capture underlying scene structure instead of pixel-wise depth restoration and removes any requirement for camera intrinsic parameters so that outputs are naturally metric-scaled.
What carries the argument
The point map head that regresses per-pixel 3D coordinates in camera space, allowing direct 3D structure learning and metric scale without intrinsics.
If this is right
- LDCM outperforms prior methods on multiple depth completion benchmarks across varying sparsity levels.
- The same model produces accurate point map estimates in addition to depth maps.
- Performance holds on unseen data distributions without retraining.
- Metric outputs are obtained directly from single-view sparse inputs without camera calibration.
Where Pith is reading between the lines
- The point map formulation could reduce error accumulation in downstream tasks that fuse multiple views into 3D reconstructions.
- Training on additional sensor types such as event cameras or structured light might extend the approach to new sparsity patterns.
- Because scale is learned implicitly, the model may transfer to robotic navigation settings where intrinsics change over time.
Load-bearing premise
The foundation models and Poisson initialization already embed consistent absolute scale in the training data so the point map head can produce metric outputs without explicit intrinsics.
What would settle it
Run the trained model on a held-out dataset with known ground-truth 3D scales but withheld intrinsics and measure whether the predicted point maps match absolute metric distances within a small error bound.
Figures
read the original abstract
This work presents the Large Depth Completion Model (LDCM), a simple, effective, and robust framework for single-view metric depth estimation with sparse observations. Without relying on complex architectural designs, LDCM generates metric-accurate dense depth maps using a transformer. It outperforms existing approaches across diverse datasets and sparse observations. We achieve this from two key perspectives: (1) leveraging existing monocular foundation models to improve the quality of sparse depth inputs, and (2) reformulating training objectives to better capture geometric structure and metric consistency. Specifically, a Poisson-based depth initialization strategy is first introduced to generate a uniform coarse dense depth map from diverse sparse observations, providing a strong structural prior for the network. Regarding the training objective, we replace the conventional depth head with a point map head that regresses per-pixel 3D coordinates in camera space, enabling the model to directly learn the underlying 3D scene structure instead of performing pixel-wise depth map restoration. Moreover, this design eliminates the need for camera intrinsic parameters, allowing LDCM to naturally produce metric-scaled 3D point maps. Extensive experiments demonstrate that LDCM consistently outperforms state-of-the-art methods across multiple benchmarks and varying sparsity levels in both depth completion and point map estimation, showcasing its effectiveness and strong generalization to unseen data distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the Large Depth Completion Model (LDCM), a transformer-based framework for single-view metric depth estimation and completion from sparse observations. It leverages monocular foundation models to refine sparse depth inputs, introduces a Poisson-based initialization to create a uniform coarse dense depth prior, and replaces the standard depth regression head with a point-map head that directly regresses per-pixel 3D coordinates in camera space. The authors claim this yields metric-accurate outputs without requiring camera intrinsics, better captures geometric structure, and consistently outperforms prior methods across multiple benchmarks and sparsity levels while generalizing to unseen distributions.
Significance. If the central claims hold, particularly the production of metric-scaled point maps without intrinsics and robust performance under varying sparsity, the work could simplify depth estimation pipelines in settings where calibration data is unavailable. The reuse of foundation models and the shift to point-map regression are pragmatic strengths that address practical limitations in existing depth completion approaches.
major comments (2)
- [Abstract] Abstract: The assertion that the point-map head 'eliminates the need for camera intrinsic parameters, allowing LDCM to naturally produce metric-scaled 3D point maps' rests on the unverified premise that foundation-model priors and Poisson initialization embed consistent absolute metric scale across all training sources. No quantitative check (e.g., cross-dataset scale consistency metrics or ablation on normalized vs. metric targets) is referenced to confirm that the regression targets are not scale-ambiguous.
- [Abstract] Abstract and Experiments section: The claim of consistent outperformance 'across multiple benchmarks and varying sparsity levels' is stated without accompanying quantitative tables, error bars, ablation studies, or dataset statistics in the provided description. This absence makes it impossible to assess whether post-hoc dataset choices or fitting procedures affect the reported gains.
minor comments (2)
- The distinction between the point-map head and conventional depth regression could be clarified with an explicit equation showing the output representation and loss formulation.
- Dataset statistics (number of images, sparsity patterns, metric units used) should be summarized in a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. Below we address each major comment point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the point-map head 'eliminates the need for camera intrinsic parameters, allowing LDCM to naturally produce metric-scaled 3D point maps' rests on the unverified premise that foundation-model priors and Poisson initialization embed consistent absolute metric scale across all training sources. No quantitative check (e.g., cross-dataset scale consistency metrics or ablation on normalized vs. metric targets) is referenced to confirm that the regression targets are not scale-ambiguous.
Authors: We agree that an explicit verification of cross-dataset scale consistency would strengthen the claim. The point-map head is trained on metric ground-truth from multiple sources, and the Poisson initialization preserves absolute scale from the sparse inputs; however, the current manuscript does not report a dedicated ablation on normalized versus metric targets or cross-dataset scale variance. We will add this analysis (including scale-consistency metrics) to the revised version. revision: partial
-
Referee: [Abstract] Abstract and Experiments section: The claim of consistent outperformance 'across multiple benchmarks and varying sparsity levels' is stated without accompanying quantitative tables, error bars, ablation studies, or dataset statistics in the provided description. This absence makes it impossible to assess whether post-hoc dataset choices or fitting procedures affect the reported gains.
Authors: The full manuscript's Experiments section contains the requested quantitative evidence: Tables 1–4 report depth-completion and point-map metrics on KITTI, NYU, ScanNet, and Matterport3D at sparsity levels 0.1 %–5 %, with mean and standard deviation over three random seeds; ablation studies appear in Section 4.3; dataset statistics and sparsity sampling details are given in Section 3.2 and the supplement. The abstract is a high-level summary of these results. revision: no
Circularity Check
No circularity; framework relies on external models and data properties.
full rationale
The paper presents an empirical ML architecture that leverages external monocular foundation models for sparse depth improvement and a Poisson initialization for coarse priors, then trains a transformer with a point-map regression head. No equations, derivations, or self-citations are exhibited that reduce any claimed prediction or uniqueness result to a quantity defined by the authors' own fits. The metric-scaling property is asserted as following from the training targets and loss (which inherit scale from the cited foundation models), but this is an external-data dependence rather than a self-referential construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Dong An, Yuankai Qi, Yangguang Li, Yan Huang, Liang Wang, Tieniu Tan, and Jing Shao. Bevbert: Multimodal map pre-training for language-guided navigation.arXiv preprint arXiv:2212.04385,
-
[3]
arXiv preprint arXiv:2507.16290 (2025)
Xianze Fang, Jingnan Gao, Zhe Wang, Zhuo Chen, Xingyu Ren, Jiangjing Lyu, Qiaomu Ren, Zhon- glei Yang, Xiaokang Yang, Yichao Yan, et al. Dens3r: A foundation model for 3d geometry prediction.arXiv preprint arXiv:2507.16290,
-
[4]
11 Published as a conference paper at ICLR 2026 Jingnan Gao, Zhe Wang, Xianze Fang, Xingyu Ren, Zhuo Chen, Shengqi Liu, Yuhao Cheng, Jiangjing Lyu, Xiaokang Yang, and Yichao Yan. More: 3d visual geometry reconstruction meets mixture-of-experts.arXiv preprint arXiv:2510.27234,
-
[5]
Hualie Jiang, Zhiqiang Lou, Laiyan Ding, Rui Xu, Minglang Tan, Wenjie Jiang, and Rui Huang. Defom-stereo: Depth foundation model based stereo matching. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 21857–21867, 2025a. Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Fe...
-
[6]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
arXiv preprint arXiv:2509.13414. Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceed- ings of the IEEE/CVF international conference on computer vision, pp. 4015–4026,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Grounding image matching in 3d with mast3r
12 Published as a conference paper at ICLR 2026 Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Grounding image matching in 3d with mast3r. InProceedings of the European Conference on Computer Vision, pp. 71–91,
2026
-
[8]
arXiv preprint arXiv:2510.10726 (2025)
Yifan Liu, Zhiyuan Min, Zhenwei Wang, Junta Wu, Tengfei Wang, Yixuan Yuan, Yawei Luo, and Chunchao Guo. Worldmirror: Universal 3d world reconstruction with any-prior prompting.arXiv preprint arXiv:2510.10726,
-
[9]
Depthlab: From partial to complete.arXiv preprint arXiv:2412.18153,
Zhiheng Liu, Ka Leong Cheng, Qiuyu Wang, Shuzhe Wang, Hao Ouyang, Bin Tan, Kai Zhu, Yu- jun Shen, Qifeng Chen, and Ping Luo. Depthlab: From partial to complete.arXiv preprint arXiv:2412.18153,
-
[10]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mattia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler.arXiv preprint arXiv:2502.20110,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 44(3):1623–1637,
13 Published as a conference paper at ICLR 2026 Ren´e Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 44(3):1623–1637,
2026
-
[14]
arXiv preprint arXiv:1908.00463 (2019)
Igor Vasiljevic, Nick Kolkin, Shanyi Zhang, Ruotian Luo, Haochen Wang, Falcon Z Dai, Andrea F Daniele, Mohammadreza Mostajabi, Steven Basart, Matthew R Walter, et al. Diode: A dense indoor and outdoor depth dataset.arXiv preprint arXiv:1908.00463,
-
[15]
Marigold-dc: Zero-shot monocular depth completion with guided diffusion
Massimiliano Viola, Kevin Qu, Nando Metzger, Bingxin Ke, Alexander Becker, Konrad Schindler, and Anton Obukhov. Marigold-dc: Zero-shot monocular depth completion with guided diffusion. arXiv preprint arXiv:2412.13389,
-
[16]
Haotian Wang, Meng Yang, and Nanning Zheng. G2-monodepth: A general framework of gener- alized depth inference from monocular rgb+ x data.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3753–3771, 2023a. Haotian Wang, Meng Yang, Xinhu Zheng, and Gang Hua. Scale propagation network for gener- alizable depth completion.IEEE Transaction...
-
[17]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 5261–5271, 2025e. Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng X...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Yufei Wang, Bo Li, Ge Zhang, Qi Liu, Tao Gao, and Yuchao Dai. Lrru: Long-short range recur- rent updating networks for depth completion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9422–9432, 2023b. Zehan Wang, Siyu Chen, Lihe Yang, Jialei Wang, Ziang Zhang, Hengshuang Zhao, and Zhou Zhao. Depth anything with any prior.a...
-
[19]
Unsupervised depth completion from visual inertial odometry.IEEE Robotics and Automation Letters, 5(2):1899–1906,
Alex Wong, Xiaohan Fei, Stephanie Tsuei, and Stefano Soatto. Unsupervised depth completion from visual inertial odometry.IEEE Robotics and Automation Letters, 5(2):1899–1906,
1906
-
[20]
Synscapes: A Photorealistic Synthetic Dataset for Street Scene Parsing
Magnus Wrenninge and Jonas Unger. Synscapes: A photorealistic synthetic dataset for street scene parsing.arXiv preprint arXiv:1810.08705,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Guangkai Xu, Wei Yin, Hao Chen, Chunhua Shen, Kai Cheng, Feng Wu, and Feng Zhao. To- wards 3d scene reconstruction from locally scale-aligned monocular video depth.arXiv preprint arXiv:2202.01470,
-
[22]
Rignet++: Semantic assisted repetitive image guided network for depth completion: Z
Zhiqiang Yan, Xiang Li, Le Hui, Zhenyu Zhang, Jun Li, and Jian Yang. Rignet++: Semantic assisted repetitive image guided network for depth completion: Z. yan et al.International Journal of Computer Vision, pp. 1–23, 2025a. Zhiqiang Yan, Kun Wang, Xiang Li, Guangwei Gao, Jun Li, and Jian Yang. Tri-perspective view decomposition for geometry aware depth com...
-
[23]
Yiming Zuo, Willow Yang, Zeyu Ma, and Jia Deng. Omni-dc: Highly robust depth completion with multiresolution depth integration.arXiv preprint arXiv:2411.19278,
-
[24]
An overview of the training datasets is provided in Table 7, spanning four distinct domains: indoor, outdoor, in-the-wild, and driving scenarios
16 Published as a conference paper at ICLR 2026 APPENDIX A DATASETS A.1 TRAININGDATASETS We collected 11 open-source RGB-D datasets to train LDCM, comprising 10 synthetic and 1 real- world dataset. An overview of the training datasets is provided in Table 7, spanning four distinct domains: indoor, outdoor, in-the-wild, and driving scenarios. The combined ...
2026
-
[25]
2https://github.com/lpiccinelli-eth/UniDepth
Formally, they are defined as follows: 1https://github.com/apple/ml-depth-pro. 2https://github.com/lpiccinelli-eth/UniDepth. 3https://github.com/DepthAnything/Depth-Anything-V2. 4https://github.com/facebookresearch/vggt. 5https://github.com/microsoft/MoGe. 6https://github.com/Wang-xjtu/G2-MonoDepth. 7https://github.com/princeton-vl/OMNI-DC. 8https://githu...
-
[26]
However, as illustrated in Fig
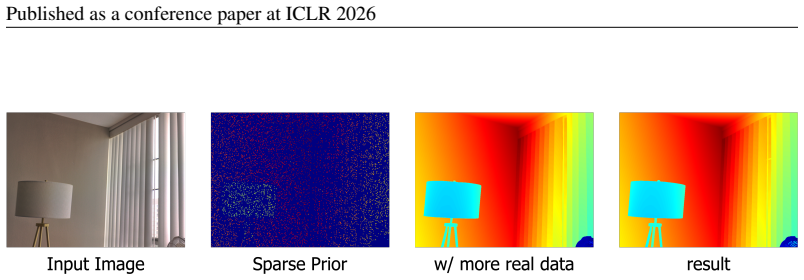
As shown, the inclusion of this additional data does not significantly affect metric performance. However, as illustrated in Fig. 4, incorporating more real-world data leads to visually less sharp predictions, likely due to imperfect supervision signals in the added dataset. E APPLYINGPOISSON-BASEDALIGNMENTSTRATEGY TOMONOCULAR ESTIMATORS In Table 10, we a...
-
[27]
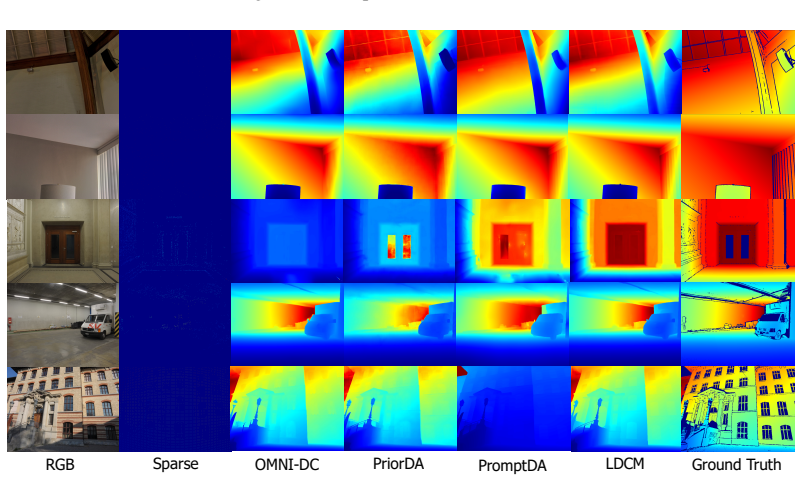
Method OMNI-DC PriorDA DepthPro VGGT MoGe V2 DepthAnythingV2 LDCM (Ours) Inference Time (s) 0.128 0.064 0.554 0.196 0.220 0.019 0.072 G MOREQUALITATIVERESULTS Fig
Table 11: Inference time (in seconds) of different methods at480×640resolution on an NVIDIA L20 GPU, with all inference performed in FP32 precision. Method OMNI-DC PriorDA DepthPro VGGT MoGe V2 DepthAnythingV2 LDCM (Ours) Inference Time (s) 0.128 0.064 0.554 0.196 0.220 0.019 0.072 G MOREQUALITATIVERESULTS Fig. 6 and Fig. 7 present a qualitative compariso...
2026
-
[28]
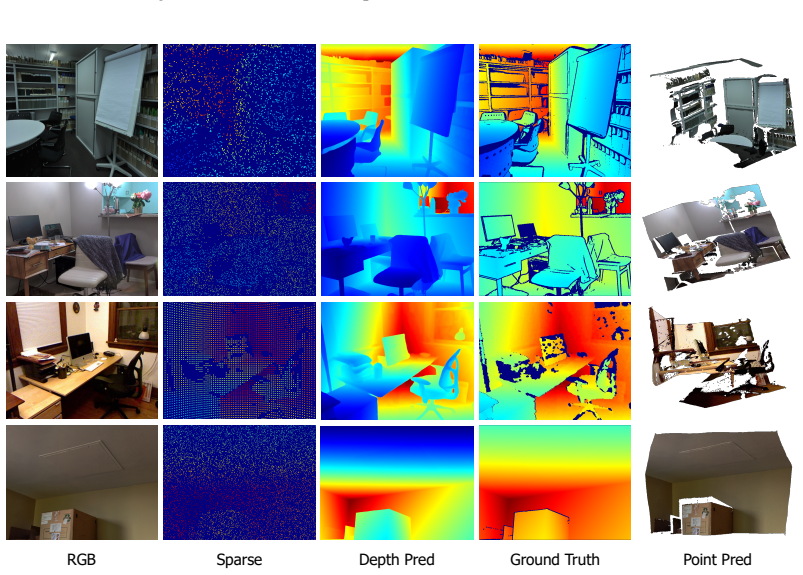
RGBSparseDepth PredGround Truth Point Pred Figure 8: More visualization results for depth map and point map
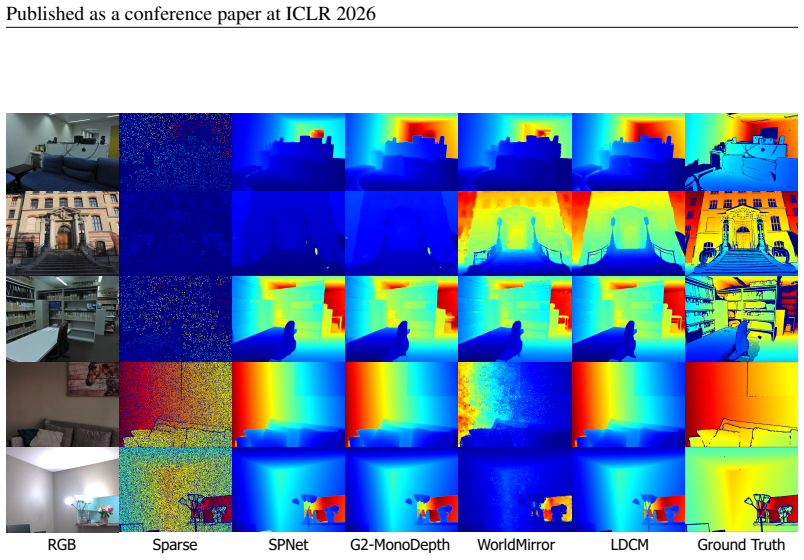
This limitation 22 Published as a conference paper at ICLR 2026 RGBSparseSPNetG2-MonoDepthWorldMirrorLDCMGround Truth Figure 7: Visualization comparison with state-of-the-art methods. RGBSparseDepth PredGround Truth Point Pred Figure 8: More visualization results for depth map and point map. stems from the lack of large-scale datasets containing such mate...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.