UniLab: A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
Pith reviewed 2026-06-29 07:06 UTC · model grok-4.3
The pith
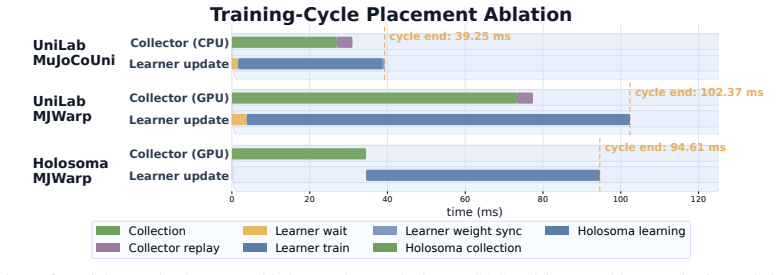
A CPU-simulation and GPU-learning split for robot RL achieves 3-10 times higher end-to-end training speed than GPU-only designs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
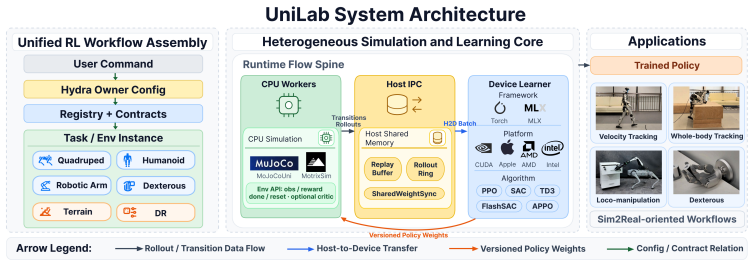
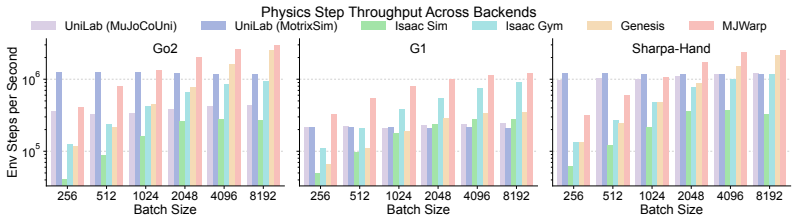
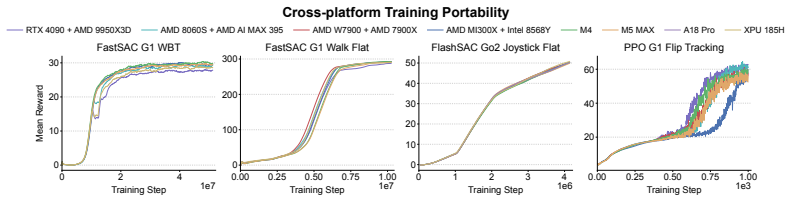
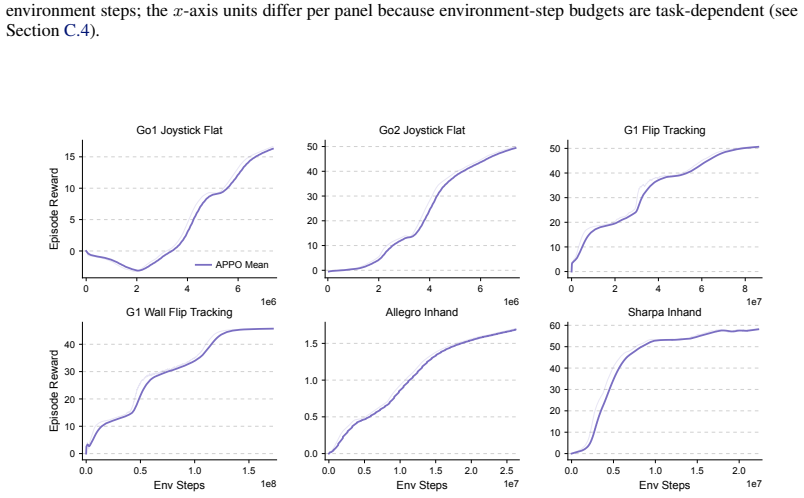
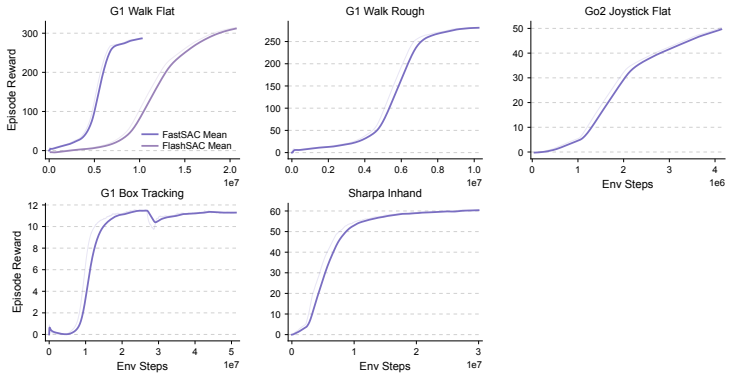
UniLab is a heterogeneous architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. It is implemented using MuJoCoUni and MotrixSim CPU-batched physics backends and supports PPO, FastSAC, FlashSAC, and APPO. On representative simulation-based robot control tasks the architecture improves end-to-end training efficiency by 3-10 times under identical hardware while reducing dependence on the NVIDIA CUDA stack and enabling execution on Apple macOS, AMD ROCm, and Intel XPU backends.
What carries the argument
Unified runtime for data movement, buffering, and synchronization between CPU simulation and GPU learning.
If this is right
- End-to-end training efficiency rises by 3-10 times on the same hardware configuration.
- Training no longer requires the NVIDIA CUDA software stack.
- The same training code runs on Apple macOS, AMD ROCm, and Intel XPU accelerator backends.
- GPU-resident simulation is effective for robot RL but is not required for high training speed.
Where Pith is reading between the lines
- Robot RL training could move to consumer laptops or edge devices that lack high-end GPUs.
- Similar CPU-GPU splits might apply to other simulation-heavy domains such as game environments or physics-based animation.
- Real-robot deployment pipelines could keep simulation on local CPU resources while using cloud GPUs only for policy updates.
Load-bearing premise
CPU-batched physics backends supply enough simulation speed and fidelity that the end-to-end gains from the split outweigh any synchronization or accuracy costs.
What would settle it
A side-by-side run of the same tasks with a GPU physics engine that shows training time no longer than the UniLab CPU version or that produces policies with lower task performance.
Figures





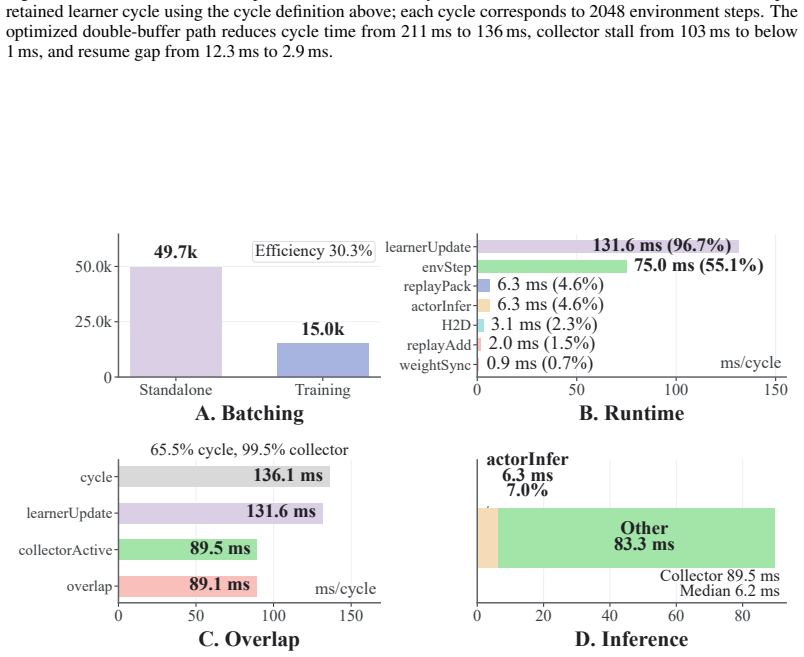
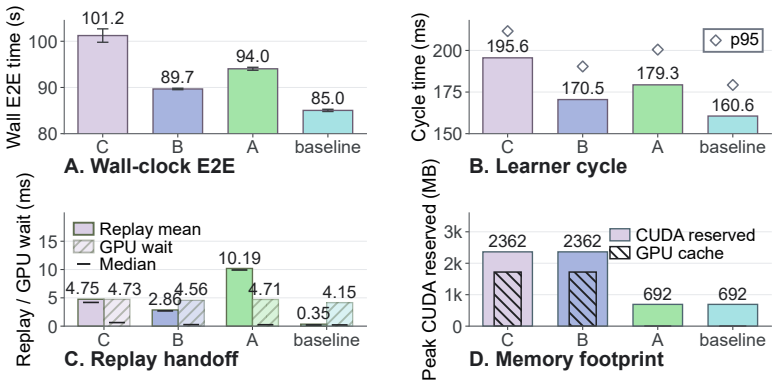
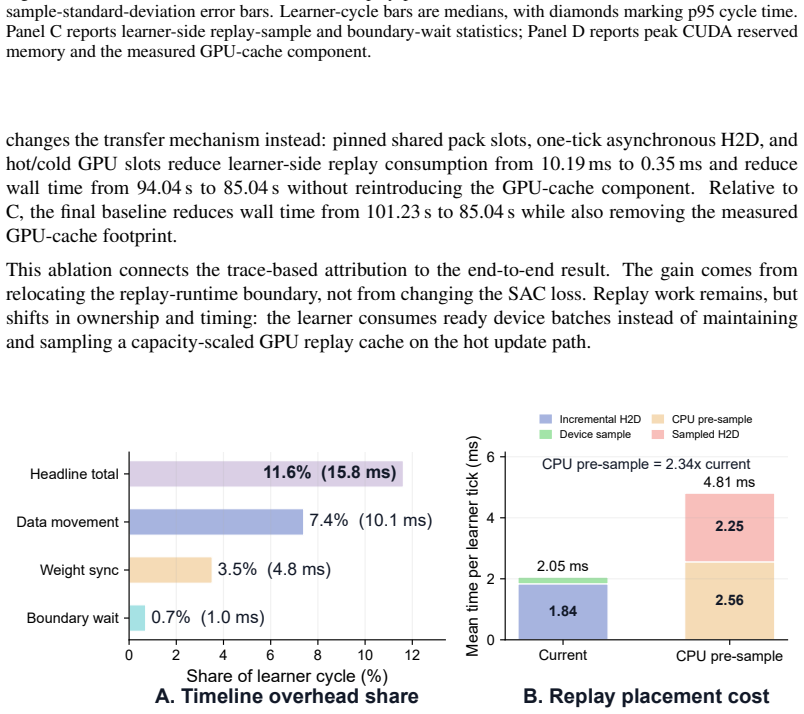
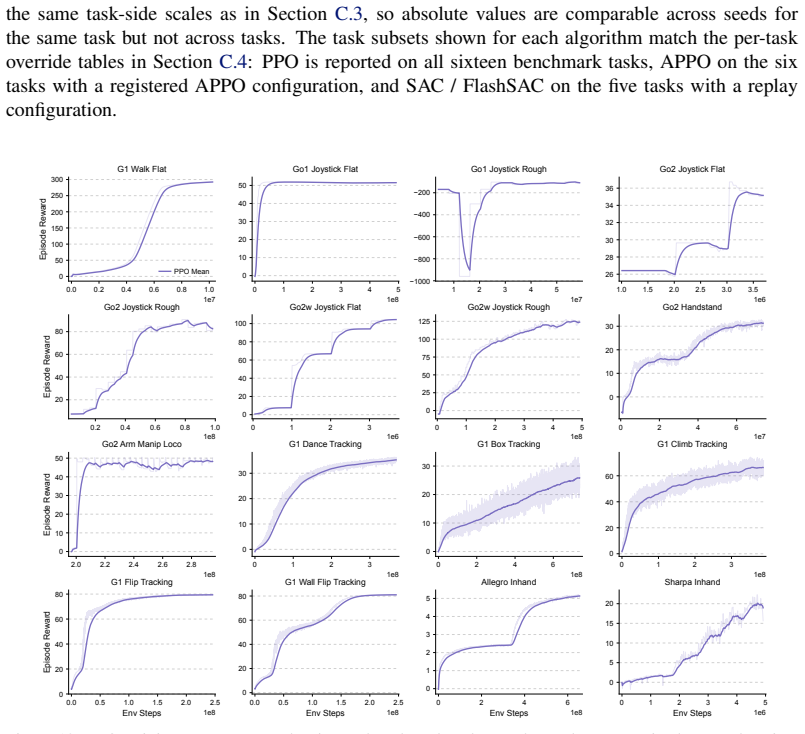
read the original abstract
Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop. We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, FastSAC, FlashSAC, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by 3--10$\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends. These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://unilabsim.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents UniLab, a heterogeneous CPU-simulation / GPU-learning architecture for robot RL that decouples CPU-parallel simulation (via MuJoCoUni and MotrixSim backends) from GPU policy updates through a unified runtime for data movement and synchronization. It supports PPO, FastSAC, FlashSAC, and APPO, and claims 3--10× end-to-end training efficiency gains on representative simulation-based robot control tasks under the same hardware, while reducing NVIDIA CUDA dependence and enabling cross-platform execution on macOS, AMD ROCm, and Intel XPU.
Significance. If the empirical claims are substantiated with detailed measurements, the work would show that GPU-resident physics is not required for efficient robot RL training, thereby expanding practical system design choices beyond the current GPU-dominant paradigm and supporting more diverse hardware backends.
major comments (2)
- [Abstract] Abstract: the performance claims of 3--10× gains are stated without any experimental details, baselines, error bars, task specifications, or measurement methodology, making it impossible to assess whether the data supports the claim.
- [Implementation description] Implementation description: the CPU-batched physics backends are asserted to deliver the claimed throughput and fidelity, but no numbers are supplied for batched simulation steps/sec on the evaluated tasks, measured CPU-to-GPU transfer latency per rollout batch, or any ablation isolating synchronization overhead; these quantities are load-bearing for the end-to-end 3--10× claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and implementation details. We address each major comment below and will revise the manuscript accordingly to improve clarity and substantiation of the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims of 3--10× gains are stated without any experimental details, baselines, error bars, task specifications, or measurement methodology, making it impossible to assess whether the data supports the claim.
Authors: We agree that the abstract presents the 3--10× claims at a high level without sufficient context. In the revised manuscript, we will update the abstract to include brief experimental details: the tasks are standard MuJoCo-based robot control benchmarks, baselines include standard GPU-centric implementations, measurements use end-to-end wall-clock training time to convergence on identical hardware, and results include error bars from multiple seeds. The full methodology, tables, and figures remain in Section 4 (Experiments). This change will allow readers to assess the claims directly from the abstract. revision: yes
-
Referee: [Implementation description] Implementation description: the CPU-batched physics backends are asserted to deliver the claimed throughput and fidelity, but no numbers are supplied for batched simulation steps/sec on the evaluated tasks, measured CPU-to-GPU transfer latency per rollout batch, or any ablation isolating synchronization overhead; these quantities are load-bearing for the end-to-end 3--10× claim.
Authors: The referee correctly identifies that the current manuscript describes the MuJoCoUni and MotrixSim backends at an architectural level but does not report the requested quantitative metrics. These measurements (batched steps/sec, per-batch transfer latency, and synchronization overhead ablation) are indeed essential to support the end-to-end efficiency claims. We will add a dedicated subsection with these numbers, derived from our evaluations on the representative tasks, along with the ablation study, in the revised version. revision: yes
Circularity Check
No circularity: empirical system architecture with observed speedups, no derivations or fitted predictions
full rationale
The paper describes a heterogeneous CPU/GPU architecture (UniLab) implemented with specific backends (MuJoCoUni, MotrixSim) and reports measured end-to-end training speedups of 3-10× on robot control tasks. No equations, parameter fits, uniqueness theorems, or predictions are presented that could reduce to the inputs by construction. The central claims are framed as empirical results from running the new system, not as mathematical reductions or self-referential fits. Self-citations, if present, are not load-bearing for any derivation. This matches the default case of a non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
- [4]
-
[5]
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.Robotics: Science and Systems, 2025
2025
-
[6]
G. Authors. Genesis: A generative and universal physics engine for robotics and beyond, December 2024. URLhttps://github.com/Genesis-Embodied-AI/Genesis
2024
-
[7]
J. Weng, M. Lin, S. Huang, B. Liu, D. Makoviichuk, V . Makoviychuk, Z. Liu, Y . Song, T. Luo, Y . Jiang, et al. Envpool: A highly parallel reinforcement learning environment execution engine.Advances in Neural Information Processing Systems, 35:22409–22421, 2022
2022
-
[8]
Z. Wu, E. Liang, M. Luo, S. Mika, J. E. Gonzalez, and I. Stoica. RLlib flow: Distributed reinforcement learning is a dataflow problem. InConference on Neural Information Processing Systems (NeurIPS), 2021. URLhttps://proceedings.neurips.cc/paper/2021/file/ 2bce32ed409f5ebcee2a7b417ad9beed-Paper.pdf. 9
2021
-
[9]
J. Weng, H. Chen, D. Yan, K. You, A. Duburcq, M. Zhang, Y . Su, H. Su, and J. Zhu. Tianshou: A highly modularized deep reinforcement learning library.Journal of Machine Learning Research, 23(267):1–6, 2022. URLhttp://jmlr.org/papers/v23/21-1127.html
2022
-
[10]
J. Suarez. PufferLib 2.0: Reinforcement learning at 1m steps/s.Reinforcement Learning Journal, 6:1378–1388, 2025
2025
-
[11]
Solving Rubik's Cube with a Robot Hand
I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, et al. Solving rubik’s cube with a robot hand.arXiv preprint arXiv:1910.07113, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[12]
Y . Kim, H. Oh, J. Lee, J. Choi, G. Ji, M. Jung, D. Youm, and J. Hwangbo. Not only rewards but also constraints: Applications on legged robot locomotion.IEEE Transactions on Robotics, 40:2984–3003, 2024
2024
-
[13]
O. Pearce. Exploring utilization options of heterogeneous architectures for multi-physics simulations.Parallel Computing, 87:35–45, 2019
2019
-
[14]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[16]
MuJoCoUni:Persistent Batched Runtime Primitives for MuJoCo
Y . Jia and J. Wu. Mujocouni: Persistent batched runtime primitives for mujoco.arXiv preprint arXiv:2605.24922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Motrixsim: A physics simulation engine for robotics and embodied ai, 2026
Motphys Team. Motrixsim: A physics simulation engine for robotics and embodied ai, 2026. URLhttps://motrixsim.readthedocs.io/. Python binary package
2026
- [18]
-
[19]
Liang, V
J. Liang, V . Makoviychuk, A. Handa, N. Chentanez, M. Macklin, and D. Fox. Gpu-accelerated robotic simulation for distributed reinforcement learning. InConference on Robot Learning, pages 270–282. PMLR, 2018
2018
-
[20]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[21]
Hwangbo, J
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter. Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
2019
-
[22]
G. B. Margolis and P. Agrawal. Walk these ways: Tuning robot control for generalization with multiplicity of behavior. InConference on Robot Learning, pages 22–31. PMLR, 2023
2023
-
[23]
G. B. Margolis, G. Yang, K. Paigwar, T. Chen, and P. Agrawal. Rapid locomotion via reinforcement learning.The International Journal of Robotics Research, 43(4):572–587, 2024
2024
-
[24]
Z. Wang, Y . Jia, L. Shi, H. Wang, H. Zhao, X. Li, J. Zhou, J. Ma, and G. Zhou. Arm-constrained curriculum learning for loco-manipulation of a wheel-legged robot. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10770–10776. IEEE, 2024. 10
2024
- [25]
- [26]
-
[27]
Bharthulwar, S
S. Bharthulwar, S. Tao, and H. Su. Staggered environment resets improve massively parallel on-policy reinforcement learning.Advances in Neural Information Processing Systems, 38: 133342–133375, 2026
2026
-
[28]
A. A. Shahid, Y . Narang, V . Petrone, E. Ferrentino, A. Handa, D. Fox, M. Pavone, and L. Roveda. Scaling population-based reinforcement learning with gpu accelerated simulation. arXiv preprint arXiv, 2404, 2024
2024
-
[29]
Fujimoto, H
S. Fujimoto, H. Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018
2018
- [30]
- [31]
-
[32]
D. Kim, Y . Lee, M. Park, K. Kim, I. Nahendra, T. Seno, S. Min, D. Palenicek, F. V ogt, D. Kragic, et al. Flashsac: Fast and stable off-policy reinforcement learning for high-dimensional robot control.arXiv preprint arXiv:2604.04539, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [33]
-
[34]
Mujoco warp (mjwarp), 2026
Google DeepMind. Mujoco warp (mjwarp), 2026. URLhttps://mujoco.readthedocs. io/en/3.3.7/mjwarp/. Software documentation. 11 Appendix Table of Contents A Off-Policy Replay Path Case Study 12 A.1 Baseline GPU-Cache SAC Path . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 A.2 Sample-Before-Transfer Replay Pipeline . . . . . . . . . . . . . . . . ....
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.