RoboWits: Unexpected Challenges for Robotic Creative Problem Solving
Pith reviewed 2026-06-29 07:04 UTC · model grok-4.3
The pith
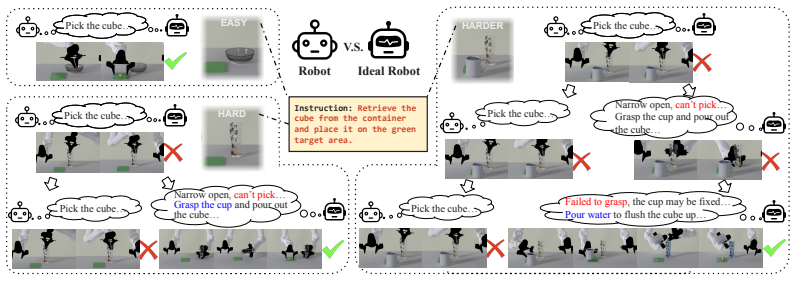
Pre-trained VLAs succeed on original robotic tasks but fail on mutated versions that require creative reasoning and adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that while pre-trained VLAs exhibit preliminary success on seed tasks after single-task fine-tuning, they struggle to perform on mutated tasks, implying their brittleness in manipulation tasks requiring reasoning, strategy adaptation, and robustness to deceptive or constrained environments.
What carries the argument
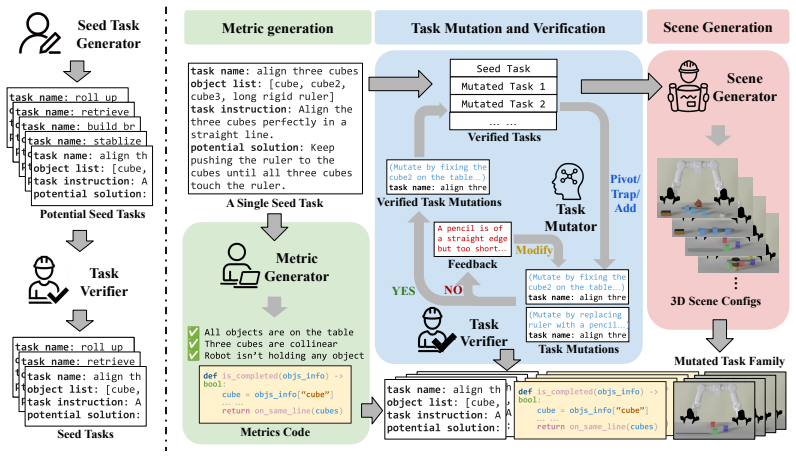
The multi-agent cooperative framework for automated task generation, with agents handling seed task generation and verification, metric generation, scene generation, and task mutation to scale the creation of reasoning-centric unexpected scenarios.
If this is right
- Current robotic benchmarks that focus on skill-level execution miss cognitive reasoning capabilities needed for real-world operation.
- Pre-trained VLAs require additional mechanisms beyond single-task fine-tuning to handle variations in geometry, materials, and assembly constraints.
- Oracle-state planners provide performance upper bounds but still reveal gaps that learned policies must close for robustness.
- Bi-manual manipulation policies must incorporate strategy adaptation to succeed in deceptive or constrained environments.
Where Pith is reading between the lines
- Future models might close the gap by training explicitly on mutated or procedurally varied task distributions rather than isolated seeds.
- The benchmark could serve as a diagnostic tool to measure progress toward open-ended robotic problem solving in unpredictable settings.
- Real-world deployment of these systems may encounter similar failure modes unless training explicitly addresses unexpected changes in object properties or constraints.
Load-bearing premise
The mutations applied to the seed tasks create scenarios that require genuine creative reasoning and adaptation not captured by performance on the original tasks.
What would settle it
Demonstrating that a single fine-tuned VLA achieves comparable success rates on both the original seed tasks and the full set of 208 mutated tasks would falsify the brittleness claim.
Figures





read the original abstract
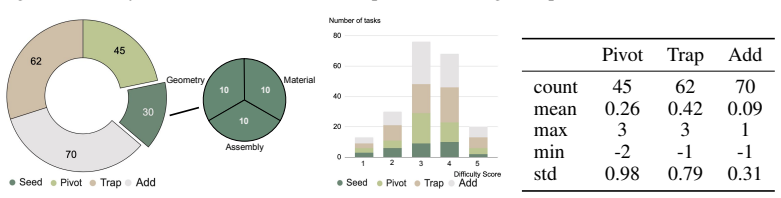
The ability to reason, adapt, and creatively solve problems under unexpected challenges is essential for robots operating in real-world environments. However, current robotic benchmarks primarily emphasize skill-level execution and provide limited insight into such cognitive reasoning capabilities. We introduce RoboWits, a bi-manual robotic benchmark designed to systematically evaluate cognitive reasoning, creative tool use, and robustness to unexpected conditions. To enable scalable construction of high-quality reasoning-centric unexpected scenarios, we propose an automated task generation pipeline formulated as a multi-agent cooperative framework, comprising agents for seed task generation and verification, metric generation, scene generation, and task mutation. Using the pipeline, we curated 30 diverse seed tasks and 208 tasks with mutations and graded difficulty across geometry, material, and assembly-based reasoning. We benchmark popular robot policies, pre-trained VLAs, and oracle-state planners. Our results reveal a significant performance gap: while pre-trained VLAs exhibit preliminary success on seed tasks after single-task fine-tuning, they struggle to perform on mutated tasks, implying their brittleness in manipulation tasks requiring reasoning, strategy adaptation, and robustness to deceptive or constrained environments. Project page is available at https://umass-embodied-agi.github.io/RoboWits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RoboWits, a bi-manual robotic benchmark for evaluating cognitive reasoning, creative tool use, and robustness under unexpected conditions. It proposes a multi-agent cooperative pipeline to generate 30 seed tasks and 208 mutated tasks across geometry, material, and assembly axes, then benchmarks pre-trained VLAs (showing preliminary success on seed tasks after single-task fine-tuning) alongside other policies and planners, concluding that the performance drop on mutated tasks reveals brittleness in reasoning, strategy adaptation, and robustness to deceptive or constrained environments.
Significance. If the mutations are shown to require qualitatively new reasoning rather than parametric generalization, the benchmark and generation pipeline would address a genuine gap in existing robotic evaluation suites that focus primarily on skill execution. The automated multi-agent construction method is a concrete strength for scalability and reproducibility.
major comments (1)
- [Abstract] Abstract: The central interpretive claim—that the observed performance gap on mutated tasks demonstrates brittleness 'in manipulation tasks requiring reasoning, strategy adaptation, and robustness to deceptive or constrained environments'—rests on the unverified assumption that the 208 mutations cannot be solved by modest extensions of seed-task policies or non-reasoning mechanisms. No human baselines, oracle success rates, or analysis distinguishing qualitative new subgoals from distribution shift are referenced, which is load-bearing for the headline conclusion.
minor comments (1)
- [Abstract] The abstract states that tasks are 'graded difficulty' but provides no detail on the grading procedure, validation, or inter-rater reliability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's central claim. We address the concern regarding verification of the mutations' requirements point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central interpretive claim—that the observed performance gap on mutated tasks demonstrates brittleness 'in manipulation tasks requiring reasoning, strategy adaptation, and robustness to deceptive or constrained environments'—rests on the unverified assumption that the 208 mutations cannot be solved by modest extensions of seed-task policies or non-reasoning mechanisms. No human baselines, oracle success rates, or analysis distinguishing qualitative new subgoals from distribution shift are referenced, which is load-bearing for the headline conclusion.
Authors: The multi-agent task generation pipeline was explicitly designed to produce mutations along geometry, material, and assembly axes that introduce qualitatively new constraints and subgoals (e.g., deceptive object placements or novel tool combinations) not addressable by direct policy extension from seeds; the 30 seed tasks were verified as solvable by the same policies before mutation. The oracle-state planners provide success rates showing that mutated tasks remain solvable with perfect information, establishing that the gap is not due to inherent task infeasibility. We agree that human baselines and explicit subgoal-shift analysis would strengthen the interpretation and will add both a discussion of expected human performance (based on task design) and a breakdown of mutation types versus distribution shift in the revised manuscript. The abstract will be updated to qualify the conclusion as suggestive of brittleness rather than definitive proof. revision: partial
Circularity Check
Empirical benchmark paper with no derivations or self-referential reductions
full rationale
The manuscript introduces RoboWits as an empirical benchmark constructed via a described multi-agent pipeline, with results consisting of performance measurements on seed and mutated tasks. No equations, fitted parameters presented as predictions, uniqueness theorems, or load-bearing self-citations appear in the provided text. The central claim is an observed performance gap on mutated tasks, which is a direct empirical observation rather than a reduction to prior inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Automated multi-agent systems can generate valid and diverse robotic tasks that test creative problem solving when mutated
Reference graph
Works this paper leans on
-
[1]
A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dha- balia, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glossop, T. Godden, I. Goryachev, L. Groom, H. Hancock, K. Hausman, G. Hussein, B. Ichter, S. Jakubczak, R. Jen, T. Jones, B. Katz, L. Ke, C. Kuchi, M. Lamb, D. LeBlanc, S. Levine, A. Li-Bell, ...
2025
-
[2]
G. Authors. Genesis: A universal and generative physics engine for robotics and beyond.URL https://github. com/Genesis-Embodied-AI/Genesis, 2024
2024
-
[3]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fu- sai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025
2025
-
[4]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision-language- action flow model for general robot control, 2026
2026
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022. 9
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [7]
-
[8]
N. Chernyadev, N. Backshall, X. Ma, Y . Lu, Y . Seo, and S. James. Bigym: A demo-driven mobile bi-manual manipulation benchmark.arXiv preprint arXiv:2407.07788, 2024
-
[9]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
- [10]
-
[11]
Deitke, E
M. Deitke, E. VanderBilt, A. Herrasti, L. Weihs, K. Ehsani, J. Salvador, W. Han, E. Kolve, A. Kembhavi, and R. Mottaghi. Procthor: Large-scale embodied ai using procedural generation. Advances in Neural Information Processing Systems, 35:5982–5994, 2022
2022
-
[12]
Z. Fu, T. Z. Zhao, and C. Finn. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation.arXiv preprint arXiv:2401.02117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
- [14]
-
[15]
J. P. Guilford. Creativity: Yesterday, today and tomorrow.The Journal of Creative Behavior, 1(1):3–14, 1967
1967
- [16]
-
[17]
Z. Hu, A. Iscen, A. Jain, T. Kipf, Y . Yue, D. A. Ross, C. Schmid, and A. Fathi. Scenecraft: An llm agent for synthesizing 3d scenes as blender code. InForty-first International Conference on Machine Learning, 2024
2024
-
[18]
Huang, F
Z. Huang, F. Chen, Y . Pu, C. Lin, H. Su, and C. Gan. Diffvl: Scaling up soft body manipulation using vision-language driven differentiable physics.Advances in Neural Information Processing Systems, 36:29875–29900, 2023
2023
-
[19]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[20]
J. C. Kaufman and R. A. Beghetto. Beyond big and little: The four c model of creativity.Review of general psychology, 13(1):1–12, 2009
2009
-
[21]
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations.arXiv preprint arXiv:2402.10885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, et al. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [26]
- [27]
-
[28]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[29]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
J. Ma, W. Liang, H.-J. Wang, Y . Zhu, L. Fan, O. Bastani, and D. Jayaraman. Dreureka: Language model guided sim-to-real transfer. RSS, 2024
2024
-
[31]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[33]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
W. Pumacay, I. Singh, J. Duan, R. Krishna, J. Thomason, and D. Fox. The colosseum: A bench- mark for evaluating generalization for robotic manipulation.arXiv preprint arXiv:2402.08191, 2024
-
[35]
J. Song, H. Ma, O. Bagoren, A. Sethuraman, Y . Zhang, and K. A. Skinner. Oceansim: A gpu- accelerated underwater robot perception simulation framework. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1526–1533. IEEE, 2025
2025
-
[36]
G. A. Team. Gen-0: Embodied foundation models that scale with physical interaction.General- ist AI Blog, 2025. https://generalistai.com/blog/preview-uqlxvb-bb.html
2025
-
[37]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Y . Tian, A. Ravichander, L. Qin, R. Le Bras, R. Marjieh, N. Peng, Y . Choi, T. L. Griffiths, and F. Brahman. Macgyver: Are large language models creative problem solvers? InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5303–5324, 2024
2024
-
[39]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[40]
C. Wang, H. Fang, H.-S. Fang, and C. Lu. Rise: 3d perception makes real-world robot imitation simple and effective. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2870–2877. IEEE, 2024. 11
2024
- [41]
-
[42]
Y . Wang, J. Duan, D. Fox, and S. Srinivasa. Newton: Are large language models capable of physical reasoning? InFindings of the association for computational linguistics: EMNLP 2023, pages 9743–9758, 2023
2023
-
[43]
Y . Wang, X. Qiu, J. Liu, Z. Chen, J. Cai, Y . Wang, T.-H. Wang, Z. Xian, and C. Gan. Architect: Generating vivid and interactive 3d scenes with hierarchical 2d inpainting.Advances in Neural Information Processing Systems, 37:67575–67603, 2024
2024
- [44]
-
[45]
Y . R. Wang, C. Ung, G. Tannert, J. Duan, J. Li, A. Le, R. Oswal, M. Grotz, W. Pumacay, Y . Deng, et al. Roboeval: Where robotic manipulation meets structured and scalable evaluation. arXiv preprint arXiv:2507.00435, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
J. Wen, Y . Zhu, J. Li, M. Zhu, Z. Tang, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[47]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, et al. Sapien: A simulated part-based interactive environment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097–11107, 2020
2020
- [48]
-
[49]
Yang, F.-Y
Y . Yang, F.-Y . Sun, L. Weihs, E. VanderBilt, A. Herrasti, W. Han, J. Wu, N. Haber, R. Krishna, L. Liu, et al. Holodeck: Language guided generation of 3d embodied ai environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16227–16237, 2024
2024
-
[50]
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, et al. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
S. Yenamandra, A. Ramachandran, K. Yadav, A. Wang, M. Khanna, T. Gervet, T.-Y . Yang, V . Jain, A. W. Clegg, J. Turner, et al. Homerobot: Open-vocabulary mobile manipulation.arXiv preprint arXiv:2306.11565, 2023
-
[52]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pages 1094–1100. PMLR, 2020
2020
-
[53]
Zhang, Z
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang, et al. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11142–11152, 2025
2025
-
[54]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Y . Zhu, J. Wong, A. Mandlekar, R. Martín-Martín, A. Joshi, S. Nasiriany, and Y . Zhu. robo- suite: A modular simulation framework and benchmark for robot learning.arXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[56]
x _min": 0,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 12 Figure 8: Ego-centric view of the 30 seed tasks inRoboWits. A Task Details The details of 30 seed tasks are as fol...
2023
-
[57]
39- No (Not Complete): There are missing obejcts mentioned but not in the ’ object_list’
Completeness: 38- Yes (Complete): All the objects mentioned in the ’initial _scene_setup’, ’task_instruction’, ’task _success_criteria’ and ’potential _solution’ are in the ’object _list’, except the table and the robot. 39- No (Not Complete): There are missing obejcts mentioned but not in the ’ object_list’
-
[58]
a narrow gap), or geometry with unintended flaws (e.g., unintended holes, scratches, wear, or micro-grooves)
Simulatability: 41- Impossible: Tasks involving aerodynamics, magnetism, thermodynamics, sticky materials, abstract objects (e.g. a narrow gap), or geometry with unintended flaws (e.g., unintended holes, scratches, wear, or micro-grooves). 42- Hard: Tasks involving contact-rich rigid-body interactions, soft bodies , liquids (including buoyancy), or compon...
-
[59]
High- complexity multi-object interactions that exceed dual-arm coordination limits are also considered not feasible
Solution Feasibility: 45- Not Feasible: Solutions requiring breaking, tearing, or creating permanent defects (e.g., drilling holes) are not feasible. High- complexity multi-object interactions that exceed dual-arm coordination limits are also considered not feasible. 46- Kind of Feasible: Solutions requiring highly precise dynamic control, such as throwin...
-
[60]
52- Yes (Efficiency): If there is no other way except ’potential _solution’ to solve the task, it’s efficient
Solution Efficiency (Bypass Check): 51- No (Not Efficient): The task is not efficient only if there is a significantly easier or more efficient solution. 52- Yes (Efficiency): If there is no other way except ’potential _solution’ to solve the task, it’s efficient. If there are other solutions, but ’potential_solution’ is easier for operation (e.g. requiri...
-
[61]
Each step involves a single robot arm to operate a single object, and the two robot arms 22 don’t need to operate together
Difficulty (a score between 1 and 5): 56- Score 1: Tasks can be solved within two steps. Each step involves a single robot arm to operate a single object, and the two robot arms 22 don’t need to operate together. The objects used in the ’ potential_solution’ are common in daily life and easy to operate by a robot arm with a parallel gripper. 57- Score 2: ...
-
[62]
8- Modify or remove the MINIMAL number of existing objects (usually the primary tool) to block the current solution
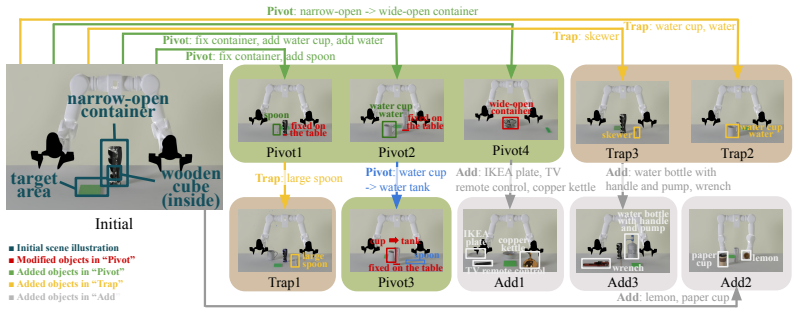
Pivot: Block the current ’potential _solution’ by modifying or removing objects in ’object _list’, then add new objects to support a new solution. 8- Modify or remove the MINIMAL number of existing objects (usually the primary tool) to block the current solution. 9- For any object mentioned in ’task _success_criteria’, it is not removable, and its ’object...
-
[63]
14- You must NOT modify or remove any original objects in the ’object _list ’
Trap (ADDITIVE ONLY): 13- Add exactly one object that looks like a potential solution but fails due to wrong attributes (e.g., a ‘‘soft’’ bridge that collapses, a ‘‘ light’’ hammer, a screwdriver ‘‘fixed on the table’’). 14- You must NOT modify or remove any original objects in the ’object _list ’
-
[64]
17- You must NOT modify or remove any original objects in the ’object _list ’
Related (ADDITIVE ONLY): 16- Add N objects that belong in the environment (e.g., a fork in a kitchen ) but are unnecessary for the solution. 17- You must NOT modify or remove any original objects in the ’object _list ’
-
[65]
x _min": 0.21,
Unrelated (ADDITIVE ONLY): 19- Add N objects as visual/spatial noise (clutter). 20- You must NOT modify or remove any original objects in the ’object _list ’. 21 22IMPORTANT: 23- Always return the full, valid JSON object. 24- Ensure ’object _list’ and ’initial _scene_setup’ are perfectly synchronized. 23 25- For ADDITIVE types, the ’object _list’ must con...
-
[66]
39- False: the task is incomplete and fails
Output Convention: 38- True: the task is completed and succeeds. 39- False: the task is incomplete and fails
-
[67]
Use scene.entities to access these objects within the code block
State Extraction: Use the provided code to identify entity names and their starting positions. Use scene.entities to access these objects within the code block
-
[68]
Stick to ‘task _success_criteria‘: Implement the natural language success criteria in Python code
-
[69]
Spatial precision: When performing spatial checks (e.g., checking if objects are on the table, checking positions, overlaps), prefer using ‘convex_hull_2d‘ over ‘bounds‘ (AABB) for rigid objects, as ‘ convex_hull_2d‘ provides more precise geometry representation
-
[70]
_is_completed
Default criteria: 44- Only check objects that are involved in the task _success_criteria. For those objects, ensure they do not fall off from the table (excluding ’table’ and ’robot’ from checks). 45 46OUTPUT FORMAT: 47‘‘‘json 48{ 49" _is_completed": "def _is_completed(objs_info) -> bool:\n \"\"\" Checks if the task is completed.\"\"\"\n ..." 50} 51‘‘‘ E....
-
[71]
29- Otherwise, always seek for suitable assets in the model library first
Create Entities 28- If object in the object list has assigned ‘use _primitive‘ or ‘asset _id‘, respect it, use ‘retrieve _asset_info_by_id‘ tool to get the information of the asset. 29- Otherwise, always seek for suitable assets in the model library first. Only use primitives when there’s no good choice. 30- Scale the asset properly based on its bounds an...
-
[72]
Place Entities 34- With a retrieved asset, the appropriate ‘position‘, ‘euler‘ should be computed based on the asset’s bbox after scaling and the desired world -space alignment. 35- For liquids/granular objects (water, sands) that should be contained in a container object, carefully interpret the volume they should occupy (which may be smaller than the co...
-
[73]
recon" vis _mode for particle materials MPM and SPH. Default vis_mode of
Verify Entities: 38- Use ‘render _current_frame‘ tool to get visual feedback of the current tabletop scene from four different views, and exmaine it carefully. 39- Use the ‘get _entity_info‘ tool to retrieve the current details of the entity. 40- Make sure no entity is in collision with other entities. Otherwise, adjust the ‘euler‘, ‘scale‘, and ‘position...
-
[74]
left" or
MOVETO _GRASP(arm, object _name, grasping _direction, offs, dlt _euler, gripper) - Move end-effector to object for grasping 10- arm: "left" or "right" 11- object _name: name of object to grasp 12- grasping _direction: gripper orientation string in format "{{ gripper_faces}}_{{fingers_align}}_{{fingers_point}}" 13Common options: 14- "down _left-right_front...
-
[75]
left" or
MOVETO _OBJECT(arm, object _name, dlt _pos, dlt _euler, steps, gripper) - Move arm to object position with offset 31- arm: "left" or "right" 32- object _name: name of object to move to 33- dlt _pos: [dx, dy, dz] position offset from object center (default [0, 0, 0]) 34- dlt _euler: [rx, ry, rz] delta euler angles in degrees (default [0, 0, 0]) 35- steps: ...
-
[76]
left" or
OPEN _GRIPPER(arm) - Open the gripper 39- arm: "left" or "right" 40
-
[77]
left" or
CLOSE _GRIPPER(arm) - Close the gripper 42- arm: "left" or "right" 43
-
[78]
" = both open,
HOLD(steps, gripper) - Hold current position 45- steps: number of steps to hold (default 10) 46- gripper: which grippers to keep closed ("" = both open, "l" = left closed, "r" = right closed, "lr" = both closed) 47
-
[79]
left" or
RETURN _HOME(arm) - Return arm to initial/home position 49- arm: "left" or "right" 50
-
[80]
x _min": 0.21,
DONE() - Call this when the task appears to be completed 52- Use this when you believe the task goal has been achieved 53 54COORDINATE SYSTEM: 55- X: forward (positive) / backward (negative) 56- Y: left (positive) / right (negative) 57- Z: up (positive) / down (negative) 58- Robot workspace is roughly: {{"x _min": 0.21, "x _max": 1.00, "y _min": -0.69, "y...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.