Bridging the 2D-3D Gap: A Hierarchical Semantic-Geometric Map for Vision Language Navigation
Pith reviewed 2026-06-29 22:30 UTC · model grok-4.3
The pith
A three-level top-down map lets VLMs select waypoints for zero-shot 3D navigation while classical planning handles movement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
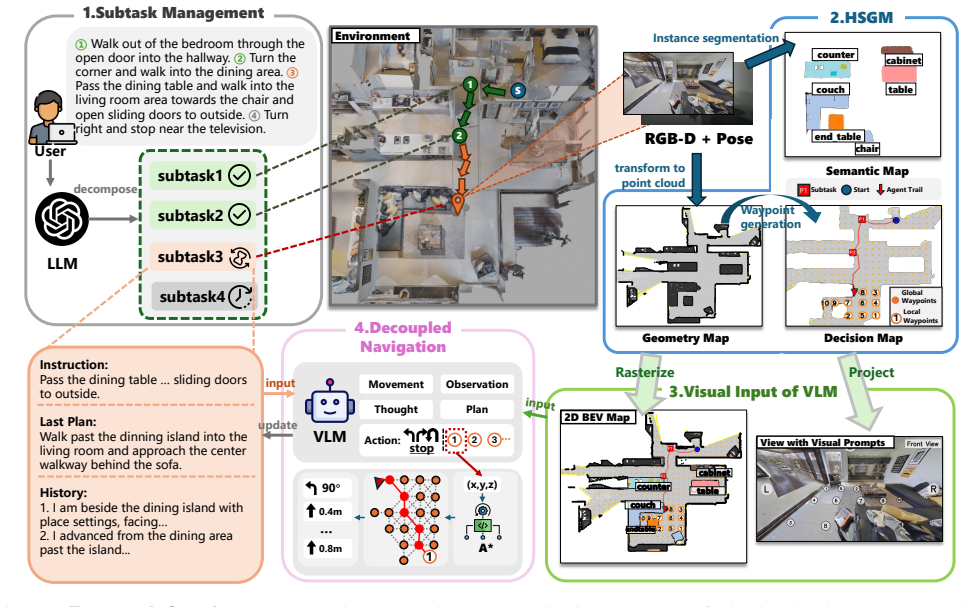
HSGM is a multi-channel top-down map with a geometric level for regions and obstacles, a semantic level for objects and relations, and a decision level for task reasoning. The VLM interprets this map to choose geometrically valid waypoints as a high-level planner, while low-level path planning executes collision-free moves between waypoints. Complex instructions are decomposed into subtasks to prevent progress forgetting or hallucination during long-horizon navigation.
What carries the argument
The Hierarchical Semantic-Geometric Map (HSGM), a multi-channel top-down representation organized into geometric, semantic, and decision levels that encodes 3D spatial layout for VLM-based waypoint selection.
If this is right
- The VLM acts only as a semantic planner selecting waypoints from the map layout.
- Subtask decomposition limits hallucination and forgetting in long-horizon navigation.
- Low-level movement is fully decoupled and handled by classical collision-free planning.
- The zero-shot framework reaches state-of-the-art on R2R-CE and RxR-CE, exceeding some supervised methods.
Where Pith is reading between the lines
- The same map structure could support other embodied tasks that require combining language instructions with physical layout.
- If map construction from sensors proves robust, the method could reduce reliance on large-scale end-to-end navigation training.
- Replacing the classical planner with a learned controller while keeping the high-level separation would test whether the core decoupling generalizes.
Load-bearing premise
The VLM can reliably read the spatial layout in the HSGM to pick valid waypoints without hallucinating or losing track of progress.
What would settle it
Provide an accurately constructed HSGM to the VLM on a benchmark task and observe whether it selects geometrically invalid waypoints at a rate higher than classical planners.
Figures


read the original abstract
Vision-Language Navigation (VLN) enables embodied agents to reach target locations in unseen environments by following language instructions. Despite recent progress with vision-language models (VLMs), a critical semantic-geometric gap remains: while VLMs excel at language and 2D visual understanding, they struggle with 3D spatial reasoning and fail to capture the causal dynamics between actions and spatial transitions, resulting in unreliable navigation, particularly in zero-shot settings. To bridge this gap, we propose a Hierarchical Semantic-Geometric Map (HSGM) that transforms 3D geometric information into a structured representation compatible with VLMs, effectively linking them to the physical world. Specifically, HSGM is represented as a multi-channel top-down map organized into three levels: (1) geometric level that records navigable regions and obstacles, (2) semantic level that represents objects and their relations, and (3) decision level that supports high-level task reasoning and goal selection. During navigation, the VLM acts as a high-level semantic planner, interpreting the spatial layout encoded in the HSGM to select geometrically valid waypoints, while low-level, collision-free movements between waypoints are executed by a classical path-planning algorithm, fully decoupling semantic reasoning from action execution. Additionally, complex instructions are decomposed into subtasks to alleviate the problem of progress forgetting or hallucinating in long-horizon navigation. Extensive experiments on R2R-CE and RxR-CE benchmarks demonstrate that our zero-shot framework achieves state-of-the-art performance and even outperforms several supervised methods. Code is available at https://github.com/Teacher-Tom/HSGM_public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to bridge the semantic-geometric gap in zero-shot Vision-Language Navigation by introducing the Hierarchical Semantic-Geometric Map (HSGM), a multi-channel top-down map with geometric, semantic, and decision levels. The VLM uses this map for high-level waypoint selection, decoupled from low-level classical planning, with subtask decomposition for long-horizon tasks. Extensive experiments on R2R-CE and RxR-CE benchmarks are reported to achieve state-of-the-art zero-shot performance, outperforming several supervised methods.
Significance. Should the zero-shot SOTA results hold under scrutiny, this approach would represent a meaningful step toward reliable VLN by structuring 3D information for VLMs without requiring task-specific training. The public release of code at the provided GitHub link supports reproducibility and is a notable strength.
major comments (3)
- §3: The precise mechanism by which the three-level HSGM is encoded and presented to the VLM (e.g., as image channels or textual description) is not specified in sufficient detail. This is load-bearing for the central claim, as the VLM's ability to select geometrically valid waypoints without hallucination depends on this interface.
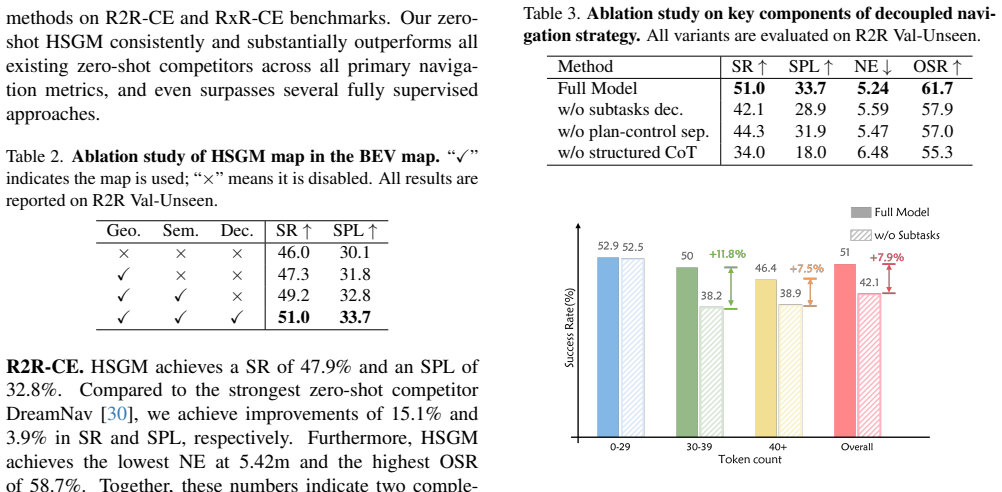
- §4: The experimental results on R2R-CE and RxR-CE are presented without error bars, standard deviations across runs, or explicit confirmation of the data splits used. This undermines verification of the claim that the method outperforms several supervised approaches.
- §3.3: While subtask decomposition is proposed to address progress forgetting, no quantitative ablation study is provided to demonstrate its necessity or impact on the reported benchmark scores.
minor comments (2)
- Abstract: The zero-shot claim could benefit from explicit comparison to the number of parameters or training data in competing supervised methods.
- Figure 1: The caption for the HSGM visualization could more clearly label the three levels and their channels for reader clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address each major comment below and commit to incorporating clarifications and additional experiments in the revised manuscript.
read point-by-point responses
-
Referee: §3: The precise mechanism by which the three-level HSGM is encoded and presented to the VLM (e.g., as image channels or textual description) is not specified in sufficient detail. This is load-bearing for the central claim, as the VLM's ability to select geometrically valid waypoints without hallucination depends on this interface.
Authors: We agree that further detail on the interface is warranted. HSGM is explicitly constructed as a multi-channel top-down map (geometric, semantic, and decision channels) and is rendered directly as a multi-channel image input to the VLM for visual reasoning. In the revision we will expand §3 with a precise description of the channel encoding, an illustrative figure of the input format, and confirmation that no textual conversion is used, thereby grounding waypoint selection in the explicit spatial data. revision: yes
-
Referee: §4: The experimental results on R2R-CE and RxR-CE are presented without error bars, standard deviations across runs, or explicit confirmation of the data splits used. This undermines verification of the claim that the method outperforms several supervised approaches.
Authors: This observation is correct and we will strengthen the experimental reporting. The revised manuscript will include standard deviations and error bars computed over multiple runs, together with explicit confirmation that the standard R2R-CE and RxR-CE data splits were employed. revision: yes
-
Referee: §3.3: While subtask decomposition is proposed to address progress forgetting, no quantitative ablation study is provided to demonstrate its necessity or impact on the reported benchmark scores.
Authors: We will add a quantitative ablation study in the revised version that directly measures the effect of subtask decomposition on navigation success rate and SPL on both R2R-CE and RxR-CE, thereby demonstrating its contribution to mitigating progress forgetting. revision: yes
Circularity Check
No significant circularity in HSGM architectural proposal
full rationale
The paper proposes an HSGM framework consisting of a three-level top-down map (geometric, semantic, decision) that decouples VLM-based high-level waypoint selection from classical low-level path planning, with subtask decomposition for long-horizon tasks. No equations, fitted parameters, or predictions appear in the provided text that reduce by construction to inputs; performance claims rest on empirical benchmark results rather than derived quantities. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The derivation chain is therefore self-contained as an engineering architecture whose validity is tested externally on R2R-CE and RxR-CE.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLMs can interpret spatial layout in a multi-channel top-down map to select geometrically valid waypoints
- domain assumption Decomposing complex instructions into subtasks alleviates progress forgetting or hallucinating
invented entities (1)
-
Hierarchical Semantic-Geometric Map (HSGM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Etpnav: Evolving topo- logical planning for vision-language navigation in continu- ous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Dong An, Hanqing Wang, Wenguan Wang, Zun Wang, Yan Huang, Keji He, and Liang Wang. Etpnav: Evolving topo- logical planning for vision-language navigation in continu- ous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 3, 6
2024
-
[2]
Vision-and-language navigation: In- terpreting visually-grounded navigation instructions in real environments
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko S ¨underhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. Vision-and-language navigation: In- terpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683,
-
[3]
Sim- to-real transfer for vision-and-language navigation
Peter Anderson, Ayush Shrivastava, Joanne Truong, Arjun Majumdar, Devi Parikh, Dhruv Batra, and Stefan Lee. Sim- to-real transfer for vision-and-language navigation. InCon- ference on Robot Learning, pages 671–681. PMLR, 2021. 2
2021
-
[4]
Matterport3d: Learning from rgb-d data in indoor environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Hal- ber, Matthias Niebner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. In2017 International Confer- ence on 3D Vision (3DV), pages 667–676. IEEE Computer Society, 2017. 6
2017
-
[5]
Mapgpt: Map-guided prompt- ing with adaptive path planning for vision-and-language nav- igation
Jiaqi Chen, Bingqian Lin, Ran Xu, Zhenhua Chai, Xiaodan Liang, and Kwan-Yee Wong. Mapgpt: Map-guided prompt- ing with adaptive path planning for vision-and-language nav- igation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9796–9810, 2024. 2
2024
-
[6]
Affordances-oriented planning using foundation models for continuous vision- language navigation
Jiaqi Chen, Bingqian Lin, Xinmin Liu, Lin Ma, Xiao- dan Liang, and Kwan-Yee K Wong. Affordances-oriented planning using foundation models for continuous vision- language navigation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 23568–23576, 2025. 2, 3, 6, 7
2025
-
[7]
Constraint-aware zero-shot vision-language navigation in continuous environ- ments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Kehan Chen, Dong An, Yan Huang, Rongtao Xu, Yifei Su, Yonggen Ling, Ian Reid, and Liang Wang. Constraint-aware zero-shot vision-language navigation in continuous environ- ments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 3, 5, 6
2025
-
[8]
Peihao Chen, Xinyu Sun, Hongyan Zhi, Runhao Zeng, Thomas H Li, Gaowen Liu, Mingkui Tan, and Chuang Gan. a2 nav: Action-aware zero-shot robot navigation by exploit- ing vision-and-language ability of foundation models.arXiv preprint arXiv:2308.07997, 2023. 6
-
[9]
Think global, act lo- cal: Dual-scale graph transformer for vision-and-language navigation
Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Think global, act lo- cal: Dual-scale graph transformer for vision-and-language navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16537– 16547, 2022. 2
2022
-
[10]
Objectrelator: Enabling cross-view object rela- tion understanding across ego-centric and exo-centric per- spectives
Yuqian Fu, Runze Wang, Bin Ren, Guolei Sun, Biao Gong, Yanwei Fu, Danda Pani Paudel, Xuanjing Huang, and Luc Van Gool. Objectrelator: Enabling cross-view object rela- tion understanding across ego-centric and exo-centric per- spectives. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 1
2025
-
[11]
Bridg- ing the gap between learning in discrete and continuous en- vironments for vision-and-language navigation
Yicong Hong, Zun Wang, Qi Wu, and Stephen Gould. Bridg- ing the gap between learning in discrete and continuous en- vironments for vision-and-language navigation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15439–15449, 2022. 2, 3, 6
2022
-
[12]
Learning navigational visual representations with semantic map su- pervision
Yicong Hong, Yang Zhou, Ruiyi Zhang, Franck Dernon- court, Trung Bui, Stephen Gould, and Hao Tan. Learning navigational visual representations with semantic map su- pervision. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3055–3067, 2023. 2
2023
-
[13]
Semantically-aware spatio-temporal rea- soning agent for vision-and-language navigation in continu- ous environments
Muhammad Zubair Irshad, Niluthpol Chowdhury Mithun, Zachary Seymour, Han-Pang Chiu, Supun Samarasekera, and Rakesh Kumar. Semantically-aware spatio-temporal rea- soning agent for vision-and-language navigation in continu- ous environments. In2022 26th International conference on pattern recognition (ICPR), pages 4065–4071. IEEE, 2022. 6
2022
-
[14]
Beyond the nav-graph: Vision-and-language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language navigation in continuous environments. InEuropean Confer- ence on Computer Vision, pages 104–120. Springer, 2020. 2, 6
2020
-
[15]
Waypoint models for instruction- guided navigation in continuous environments
Jacob Krantz, Aaron Gokaslan, Dhruv Batra, Stefan Lee, and Oleksandr Maksymets. Waypoint models for instruction- guided navigation in continuous environments. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 15162–15171, 2021. 3
2021
-
[16]
Room-across-room: Multilingual vision- and-language navigation with dense spatiotemporal ground- ing
Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. Room-across-room: Multilingual vision- and-language navigation with dense spatiotemporal ground- ing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4392–4412, 2020. 6
2020
-
[17]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 1
2023
-
[18]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[19]
Instructnav: Zero-shot system for generic 9 instruction navigation in unexplored environment
Yuxing Long, Wenzhe Cai, Hongcheng Wang, Guanqi Zhan, and Hao Dong. Instructnav: Zero-shot system for generic 9 instruction navigation in unexplored environment. InCon- ference on Robot Learning, pages 2049–2060. PMLR, 2025. 2, 3, 4, 6, 1
2049
-
[20]
Pivot: iterative visual prompting elicits actionable knowledge for vlms
Soroush Nasiriany, Fei Xia, Wenhao Yu, Ted Xiao, Jacky Liang, Ishita Dasgupta, Annie Xie, Danny Driess, Ayzaan Wahid, Zhuo Xu, et al. Pivot: iterative visual prompting elicits actionable knowledge for vlms. InProceedings of the 41st International Conference on Machine Learning, pages 37321–37341, 2024. 1
2024
-
[21]
Gpt4scene: Understand 3d scenes from videos with vision-language models,
Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, and Hengshuang Zhao. Gpt4scene: Understand 3d scenes from videos with vision-language models.arXiv preprint arXiv:2501.01428, 2025. 2
-
[22]
Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221,
Zhangyang Qi, Zhixiong Zhang, Yizhou Yu, Jiaqi Wang, and Hengshuang Zhao. Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221,
-
[23]
Open-nav: Explor- ing zero-shot vision-and-language navigation in continuous environment with open-source llms
Yanyuan Qiao, Wenqi Lyu, Hui Wang, Zixu Wang, Zerui Li, Yuan Zhang, Mingkui Tan, and Qi Wu. Open-nav: Explor- ing zero-shot vision-and-language navigation in continuous environment with open-source llms. In2025 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 6710–6717. IEEE, 2025. 6
2025
-
[24]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019. 2, 6
2019
-
[25]
Smartway: Enhanced waypoint prediction and backtracking for zero-shot vision- and-language navigation
Xiangyu Shi, Zerui Li, Wenqi Lyu, Jiatong Xia, Feras Day- oub, Yanyuan Qiao, and Qi Wu. Smartway: Enhanced waypoint prediction and backtracking for zero-shot vision- and-language navigation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 16923–16930. IEEE, 2025. 3, 6, 7
2025
-
[26]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Towards long-horizon vision- language navigation: Platform, benchmark and method
Xinshuai Song, Weixing Chen, Yang Liu, Weikai Chen, Guanbin Li, and Liang Lin. Towards long-horizon vision- language navigation: Platform, benchmark and method. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 12078–12088, 2025. 5
2025
-
[28]
Yoloe: Real-time seeing anything
Ao Wang, Lihao Liu, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Yoloe: Real-time seeing anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 24591–24602, 2025. 4
2025
-
[29]
Jiawei Wang, Teng Wang, Lele Xu, Zichen He, and Changyin Sun. Discovering intrinsic subgoals for vision- and-language navigation via hierarchical reinforcement learning.IEEE Transactions on Neural Networks and Learn- ing Systems, 36(4):6516–6528, 2024. 2
2024
-
[30]
Yunheng Wang, Yuetong Fang, Taowen Wang, Yixiao Feng, Yawen Tan, Shuning Zhang, Peiran Liu, Yiding Ji, and Ren- jing Xu. Dreamnav: A trajectory-based imaginative frame- work for zero-shot vision-and-language navigation.arXiv preprint arXiv:2509.11197, 2025. 3, 6, 7
-
[31]
Scaling data generation in vision-and-language navigation
Zun Wang, Jialu Li, Yicong Hong, Yi Wang, Qi Wu, Mohit Bansal, Stephen Gould, Hao Tan, and Yu Qiao. Scaling data generation in vision-and-language navigation. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 12009–12020, 2023. 2
2023
-
[32]
Gridmm: Grid memory map for vision- and-language navigation
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. Gridmm: Grid memory map for vision- and-language navigation. InProceedings of the IEEE/CVF International conference on computer vision, pages 15625– 15636, 2023. 2
2023
-
[33]
Zihan Wang, Seungjun Lee, and Gim Hee Lee. Dynam3d: Dynamic layered 3d tokens empower vlm for vision-and- language navigation.arXiv preprint arXiv:2505.11383,
-
[34]
Vlfm: Vision-language frontier maps for zero-shot semantic navigation
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In2024 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 42–48. IEEE, 2024. 3, 1
2024
-
[35]
Songsong Yu, Yuxin Chen, Hao Ju, Lianjie Jia, Fuxi Zhang, Shaofei Huang, Yuhan Wu, Rundi Cui, Binghao Ran, Za- ibin Zhang, et al. How far are vlms from visual spatial in- telligence? a benchmark-driven perspective.arXiv preprint arXiv:2509.18905, 2025. 2
-
[36]
Zhaohuan Zhan, Lisha Yu, Sijie Yu, and Guang Tan. Mc-gpt: Empowering vision-and-language navigation with memory map and reasoning chains.arXiv preprint arXiv:2405.10620,
-
[37]
Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence,
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence,
-
[38]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision- language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation.arXiv preprint arXiv:2402.15852, 2024. 2, 3, 6, 7, 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
MapNav: A novel memory representation via annotated semantic maps for VLM-based vision-and-language navigation
Lingfeng Zhang, Xiaoshuai Hao, Qinwen Xu, Qiang Zhang, Xinyao Zhang, Pengwei Wang, Jing Zhang, Zhongyuan Wang, Shanghang Zhang, and Renjing Xu. MapNav: A novel memory representation via annotated semantic maps for VLM-based vision-and-language navigation. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1...
2025
-
[41]
Apexnav: An adap- tive exploration strategy for zero-shot object navigation with target-centric semantic fusion.IEEE Robotics and Automa- tion Letters, 2025
Mingjie Zhang, Yuheng Du, Chengkai Wu, Jinni Zhou, Zhenchao Qi, Jun Ma, and Boyu Zhou. Apexnav: An adap- tive exploration strategy for zero-shot object navigation with target-centric semantic fusion.IEEE Robotics and Automa- tion Letters, 2025. 1
2025
-
[42]
Multimodal spatial reasoning in the large model era: A survey and benchmarks
Xu Zheng, Zihao Dongfang, Lutao Jiang, Boyuan Zheng, Yulong Guo, Zhenquan Zhang, Giuliano Albanese, Runyi 10 Yang, Mengjiao Ma, Zixin Zhang, et al. Multimodal spatial reasoning in the large model era: A survey and benchmarks. arXiv preprint arXiv:2510.25760, 2025. 1
-
[43]
Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models
Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7641–7649, 2024. 2 11 Bridging the 2D-3D Gap: A Hierarchical Semantic-Geometric Map for Vision Language Navigation Supplementary Material In this supplementar...
2024
-
[44]
More Implementation Details 6.1. Implementation of Multi-Floor Navigation To enable robust navigation in complex, multi-stair envi- ronments, we extend the HSGM framework to manage in- dependent map representations for each floor. LetF= {f0, . . . , fn}denote the set of floors. For each floorf i, the system maintains a dedicated map instanceM(i) containin...
-
[45]
Navigate to the target object [object] and get as close to it as possible
Supplementary Results 7.1. Performance on Object Goal Navigation To further assess the versatility and generalization capa- bility of our framework beyond instruction-following, we evaluated HSGM on the Object Goal Navigation (Object- Nav) task using the challenging Habitat-Matterport 3D (HM3D) [?] dataset. In this setting, the complex narra- tive instruc...
-
[46]
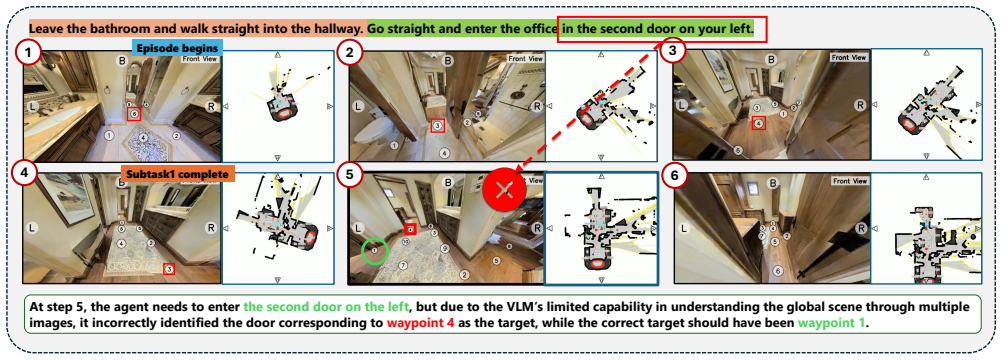
second door on the left
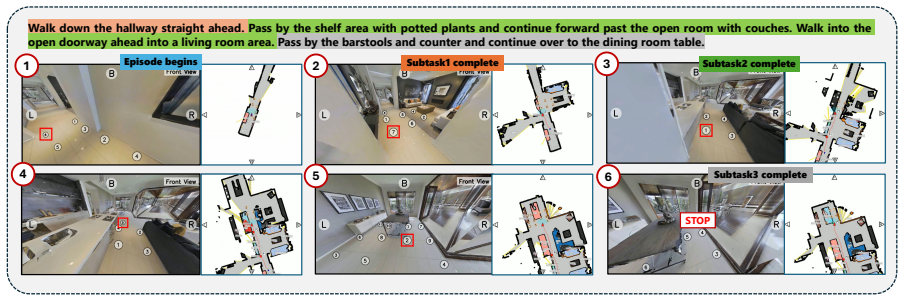
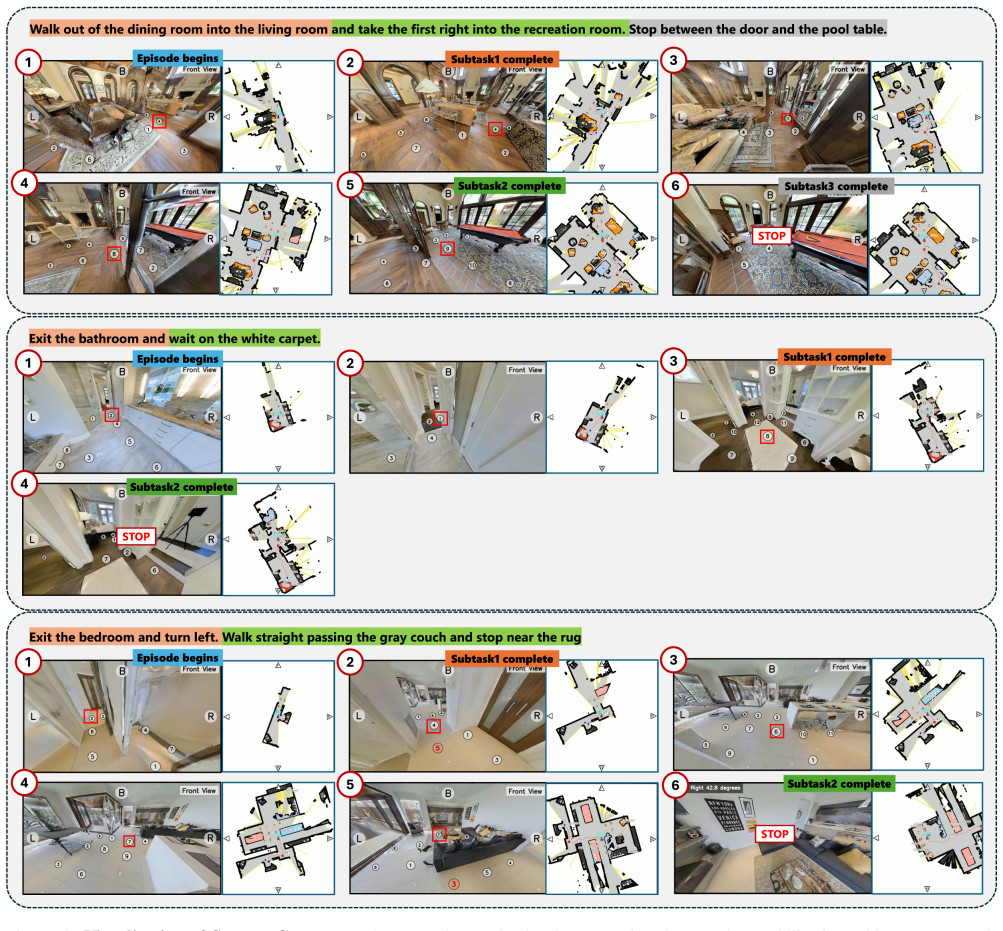
More Visualization Results 8.1. Success Cases As illustrated in Figure 5, our framework demonstrates ro- bust performance across diverse and complex indoor en- vironments. The visualization underscores the system’s ability to decompose complex natural language instructions into manageable sequential subtasks, providing a clear and structured roadmap for l...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.