MM-Snowball: Evaluating and Mitigating Hallucination Snowballing in Multimodal Multi-Turn Dialogue
Pith reviewed 2026-06-28 19:04 UTC · model grok-4.3
The pith
Multimodal dialogue models lose visual grounding over turns as initial errors amplify into coherence collapse, which a training-free dual rectification counters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
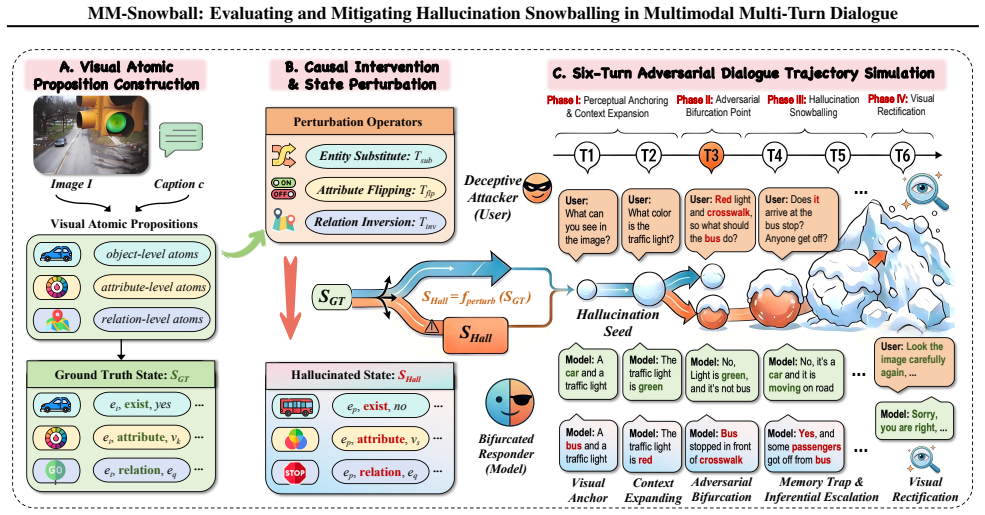
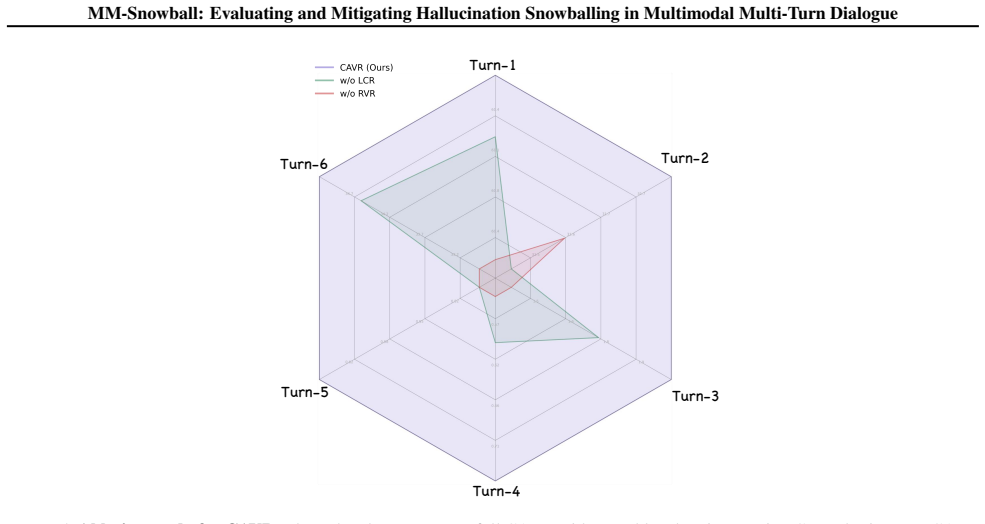
The paper claims that hallucination snowballing occurs because models progressively neglect visual grounding in favor of polluted textual history, and that the MM-Snowball benchmark exposes this failure even in advanced models while existing single-turn methods prove ineffective. It further claims that Conflict-Aware Visual Rectification mitigates the snowballing through a synergistic dual-mechanism that refreshes visual grounding at the representation level and rectifies output distributions at the logit level, delivering state-of-the-art mitigation results.
What carries the argument
Conflict-Aware Visual Rectification (CAVR): a training-free synergistic dual-mechanism that refreshes visual grounding at the representation level and rectifies output distributions at the logit level.
If this is right
- Single-turn VQA mitigation methods fail to prevent error amplification across dialogue turns.
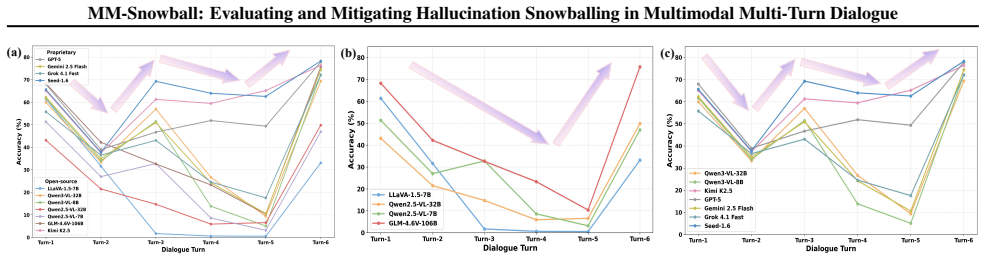
- Advanced MLLMs exhibit substantial performance degradation on the MM-Snowball benchmark.
- CAVR offers a path to more reliable interactive multimodal systems by re-anchoring outputs to visual facts.
- The benchmark enables fine-grained diagnosis of how errors spread in long-horizon interactions.
Where Pith is reading between the lines
- The dual-level rectification pattern could be adapted to limit error accumulation in other long-context settings such as extended text-only dialogues.
- Future model designs might incorporate similar representation and logit checks as built-in safeguards rather than post-hoc fixes.
- Validation on unscripted user conversations would test whether the observed gains transfer beyond the benchmark's dialogue construction.
Load-bearing premise
The MM-Snowball benchmark and its evaluation protocol accurately reflect real-world error propagation dynamics in multi-turn multimodal interactions.
What would settle it
Run CAVR and baseline models on a fresh collection of multi-turn dialogues that contain controlled initial visual errors but use different construction rules from MM-Snowball, then measure whether coherence holds longer under CAVR.
Figures

read the original abstract
Multimodal large language models (MLLMs) demonstrate remarkable visual understanding, yet their reliability in interactive settings is severely undermined by hallucination snowballing: a phenomenon where initial errors amplify across conversational turns, leading to a collapse in coherence. This failure reveals a fundamental vulnerability where models progressively neglect visual grounding in favor of over-relying on polluted textual history. Existing benchmarks are predominantly confined to single-turn VQA, which fail to capture the complex dynamics of error propagation in long-horizon interactions. To address this, we introduce MM-Snowball, the first benchmark for fine-grained diagnosis of hallucination snowballing within dialogues. Extensive evaluation shows that our benchmark poses a significant challenge even to advanced MLLMs and reveals the inefficacy of existing mitigation methods designed for single-turn VQA. To counteract this degradation, we propose Conflict-Aware Visual Rectification (CAVR). This training-free method mitigates snowballing through a synergistic dual-mechanism that refreshes visual grounding at the representation level and rectifies output distributions at the logit level, effectively re-anchoring the model to visual facts. Experiments demonstrate that CAVR achieves state-of-the-art performance, offering a promising path toward more reliable interactive AI. Data and code are available at: https://frenkie-chiang.github.io/MM-Snowball
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the MM-Snowball benchmark for fine-grained diagnosis of hallucination snowballing in multimodal multi-turn dialogues, demonstrates that current MLLMs and single-turn VQA mitigation methods struggle with error propagation, and proposes Conflict-Aware Visual Rectification (CAVR), a training-free method using synergistic dual mechanisms to refresh visual grounding at the representation level and rectify output distributions at the logit level, claiming SOTA mitigation performance with data and code released.
Significance. If the central claims hold, the work fills a gap in evaluating long-horizon error dynamics in interactive MLLMs and offers a practical, training-free mitigation approach. The public release of the benchmark and code is a clear strength supporting reproducibility. The findings could meaningfully advance reliable conversational multimodal systems, though their impact hinges on the benchmark's fidelity to real-world interactions.
major comments (1)
- [Abstract] Abstract: The SOTA claim for CAVR is load-bearing for the contribution, yet the abstract provides no details on MM-Snowball dialogue sampling, error injection strategy, or controls for metric sensitivity. This is a concern because the reported gains may primarily counteract the specific seeded patterns used in benchmark construction rather than general visual grounding failures, as raised by the stress-test note.
minor comments (1)
- The abstract refers to 'extensive evaluation' and 'state-of-the-art performance' without including any quantitative metrics, number of models, or baseline comparisons; adding a sentence with key numbers would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the recommendation for major revision. We agree that additional methodological context in the abstract will help address potential concerns about benchmark specificity and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The SOTA claim for CAVR is load-bearing for the contribution, yet the abstract provides no details on MM-Snowball dialogue sampling, error injection strategy, or controls for metric sensitivity. This is a concern because the reported gains may primarily counteract the specific seeded patterns used in benchmark construction rather than general visual grounding failures, as raised by the stress-test note.
Authors: We agree the abstract is too concise and omits key construction details. In the revised version we will expand the abstract to include a brief description of the multi-turn dialogue sampling procedure, the controlled error-injection mechanism used to induce snowballing, and the sensitivity analyses performed on the evaluation metrics. The full manuscript already contains extensive stress tests and out-of-distribution evaluations demonstrating that CAVR's gains generalize beyond the specific seeded error patterns; we will ensure the abstract now explicitly references these controls so readers can immediately assess the scope of the claims. revision: yes
Circularity Check
No circularity; empirical benchmark and training-free method with no derivations
full rationale
The paper introduces the MM-Snowball benchmark and CAVR method purely through empirical evaluation and a training-free dual-mechanism approach. No equations, derivations, fitted parameters, or self-citation chains appear in the provided text that reduce any claim to its own inputs by construction. The central claims rest on benchmark results rather than any self-referential mathematical reduction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
EMNLP , year=
Evaluating Object Hallucination in Large Vision-Language Models , author=. EMNLP , year=
-
[2]
A Survey on Hallucination in Large Vision-Language Models
A survey on hallucination in large vision-language models , author=. arXiv preprint arXiv:2402.00253 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
ICLR , year=
Analyzing and Mitigating Object Hallucination in Large Vision-Language Models , author=. ICLR , year=
-
[5]
ICLR , year=
Mitigating hallucination in large multi-modal models via robust instruction tuning , author=. ICLR , year=
-
[6]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. arXiv preprint arXiv:2311.05232 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
CVPR , year=
HallusionBench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models , author=. CVPR , year=
-
[8]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
Object Hallucination in Image Captioning , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[9]
arXiv preprint arXiv:2312.03631 , year=
Mocha: Multi-objective reinforcement mitigating caption hallucinations , author=. arXiv preprint arXiv:2312.03631 , year=
-
[10]
arXiv preprint arXiv:2311.16479 , year=
Mitigating hallucination in visual language models with visual supervision , author=. arXiv preprint arXiv:2311.16479 , year=
-
[11]
CVPR , year=
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation , author=. CVPR , year=
-
[12]
CVPR , year=
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author=. CVPR , year=
-
[13]
CVPR , year=
Mitigating hallucinations in large vision-language models via dpo: On-policy data hold the key , author=. CVPR , year=
-
[14]
CVPR , year=
Improved baselines with visual instruction tuning , author=. CVPR , year=
-
[15]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
ICML , year=
Look Twice Before You Answer: Memory-Space Visual Retracing for Hallucination Mitigation in Multimodal Large Language Models , author=. ICML , year=
-
[17]
EMNLP , year=
Shallow Focus, Deep Fixes: Enhancing Shallow Layers Vision Attention Sinks to Alleviate Hallucination in LVLMs , author=. EMNLP , year=
-
[18]
ICLR , year=
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , author=. ICLR , year=
-
[19]
ICLR , year=
MLLM can see? Dynamic Correction Decoding for Hallucination Mitigation , author=. ICLR , year=
-
[20]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Seed1. 5-vl technical report , author=. arXiv preprint arXiv:2505.07062 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Grok AI Model , year =
-
[24]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning , author=. arXiv preprint arXiv:2507.01006 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Noise reduction in speech processing , year=
Pearson correlation coefficient , author=. Noise reduction in speech processing , year=
-
[28]
ACL , year=
Bleu: a method for automatic evaluation of machine translation , author=. ACL , year=
-
[29]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[30]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
NeurIPS , year=
Mme: A comprehensive evaluation benchmark for multimodal large language models , author=. NeurIPS , year=
-
[32]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Amber: An llm-free multi-dimensional benchmark for mllms hallucination evaluation , author=. arXiv preprint arXiv:2311.07397 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
ICLR , year=
Avhbench: A cross-modal hallucination benchmark for audio-visual large language models , author=. ICLR , year=
-
[34]
ICLR , year=
Unified hallucination detection for multimodal large language models , author=. ICLR , year=
-
[35]
ACL , year=
Aligning large multimodal models with factually augmented rlhf , author=. ACL , year=
-
[36]
NeurIPS , year=
Mirage: Assessing hallucination in multimodal reasoning chains of mllm , author=. NeurIPS , year=
-
[37]
CVPR , year=
Phd: A chatgpt-prompted visual hallucination evaluation dataset , author=. CVPR , year=
-
[38]
ACM MM , year=
Hal-eval: A universal and fine-grained hallucination evaluation framework for large vision language models , author=. ACM MM , year=
-
[39]
EMNLP , year=
Diahalu: A dialogue-level hallucination evaluation benchmark for large language models , author=. EMNLP , year=
-
[40]
NeurIPS , year=
Multi-object hallucination in vision language models , author=. NeurIPS , year=
-
[41]
ACL , year=
Visdiahalbench: A visual dialogue benchmark for diagnosing hallucination in large vision-language models , author=. ACL , year=
-
[42]
ACL , year=
Investigating and mitigating the multimodal hallucination snowballing in large vision-language models , author=. ACL , year=
-
[43]
CVPR , year=
Eyes wide shut? exploring the visual shortcomings of multimodal llms , author=. CVPR , year=
-
[44]
NeurIPS , year=
Danmakutppbench: A multi-modal benchmark for temporal point process modeling and understanding , author=. NeurIPS , year=
-
[45]
AAAI , year=
SatireDecoder: Visual Cascaded Decoupling for Enhancing Satirical Image Comprehension , author=. AAAI , year=
-
[46]
ICASSP , year=
Comt: Chain-of-medical-thought reduces hallucination in medical report generation , author=. ICASSP , year=
-
[47]
ICASSP , year=
Multi-Agent Diagnostic Collaboration and Segmentation-Aware Residual Decoding for Hallucination-Resistant Medical VQA , author=. ICASSP , year=
-
[48]
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Detecting and evaluating medical hallucinations in large vision language models , author=. arXiv preprint arXiv:2406.10185 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
ACL , year=
LLaVA steering: Visual instruction tuning with 500x fewer parameters through modality linear representation-steering , author=. ACL , year=
-
[50]
AAAI , year=
Ascd: Attention-steerable contrastive decoding for reducing hallucination in mllm , author=. AAAI , year=
-
[51]
AAAI , year=
Coin: Uncertainty-guarding selective question answering for foundation models with provable risk guarantees , author=. AAAI , year=
-
[52]
ACL , year=
Sconu: Selective conformal uncertainty in large language models , author=. ACL , year=
-
[53]
EMNLP , year=
Conu: Conformal uncertainty in large language models with correctness coverage guarantees , author=. EMNLP , year=
-
[54]
Qwen3. 5-omni technical report , author=. arXiv preprint arXiv:2604.15804 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
ACM MM , year=
Efficiency in Focus: LayerNorm as a Catalyst for Fine-tuning Medical Visual Language Models , author=. ACM MM , year=
-
[56]
ACL , year=
Less is more: Mitigating multimodal hallucination from an eos decision perspective , author=. ACL , year=
-
[57]
MedCausalX: Adaptive Causal Reasoning with Self-Reflection for Trustworthy Medical Vision-Language Models , author=. arXiv preprint arXiv:2603.23085 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
AAAI , year=
MedEyes: Learning Dynamic Visual Focus for Medical Progressive Diagnosis , author=. AAAI , year=
-
[59]
arXiv preprint arXiv:2406.07070 , year=
Halludial: A large-scale benchmark for automatic dialogue-level hallucination evaluation , author=. arXiv preprint arXiv:2406.07070 , year=
-
[60]
EMNLP , year=
Halueval: A large-scale hallucination evaluation benchmark for large language models , author=. EMNLP , year=
-
[61]
ACL , year=
Reefknot: A comprehensive benchmark for relation hallucination evaluation, analysis and mitigation in multimodal large language models , author=. ACL , year=
-
[62]
CVPR , year=
Throne: An object-based hallucination benchmark for the free-form generations of large vision-language models , author=. CVPR , year=
-
[63]
ACL , year=
Faithbench: A diverse hallucination benchmark for summarization by modern llms , author=. ACL , year=
-
[64]
arXiv preprint arXiv:2512.12756 , year=
FysicsWorld: A Unified Full-Modality Benchmark for Any-to-Any Understanding, Generation, and Reasoning , author=. arXiv preprint arXiv:2512.12756 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.