AdaCodec: A Predictive Visual Code for Video MLLMs
Pith reviewed 2026-06-28 15:18 UTC · model grok-4.3
The pith
A predictive visual code for video MLLMs encodes full frames only when prediction from prior context fails and uses compact P-tokens for changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
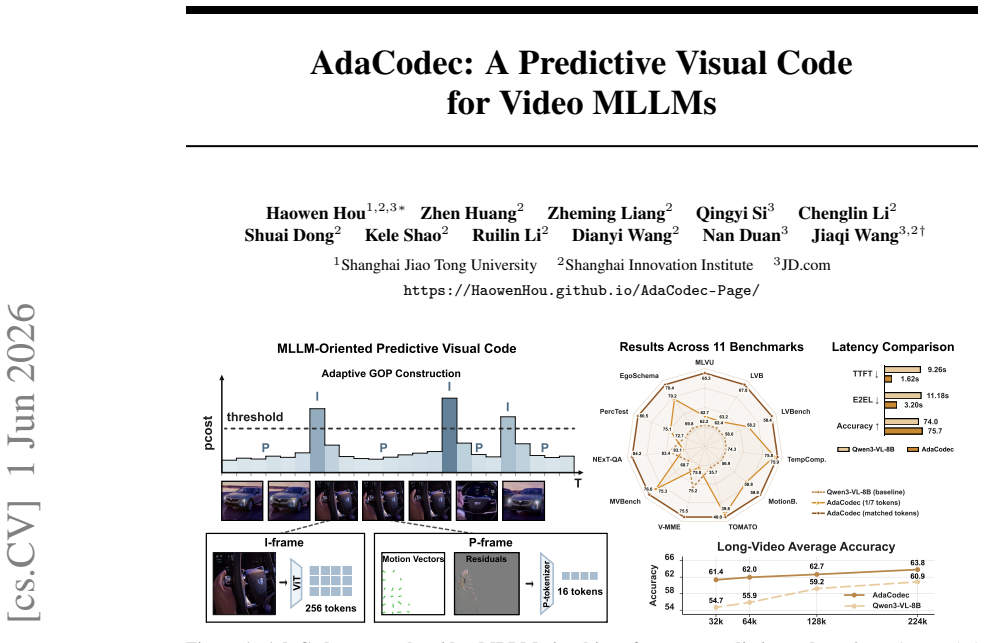
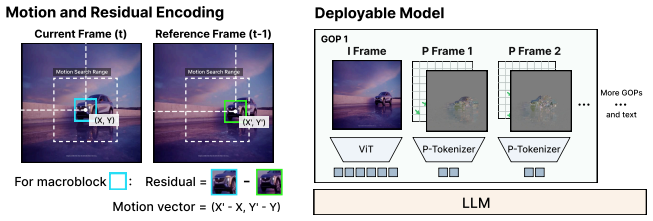
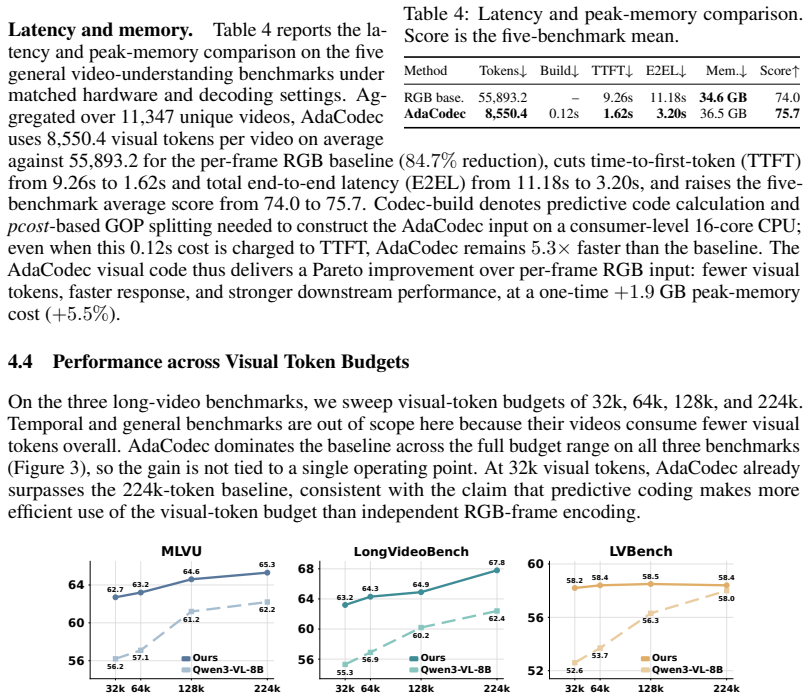
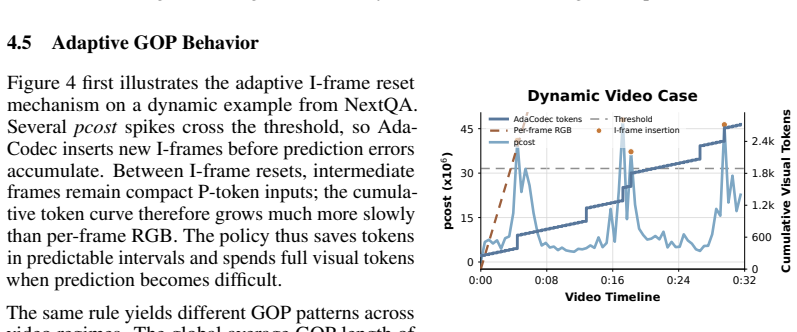
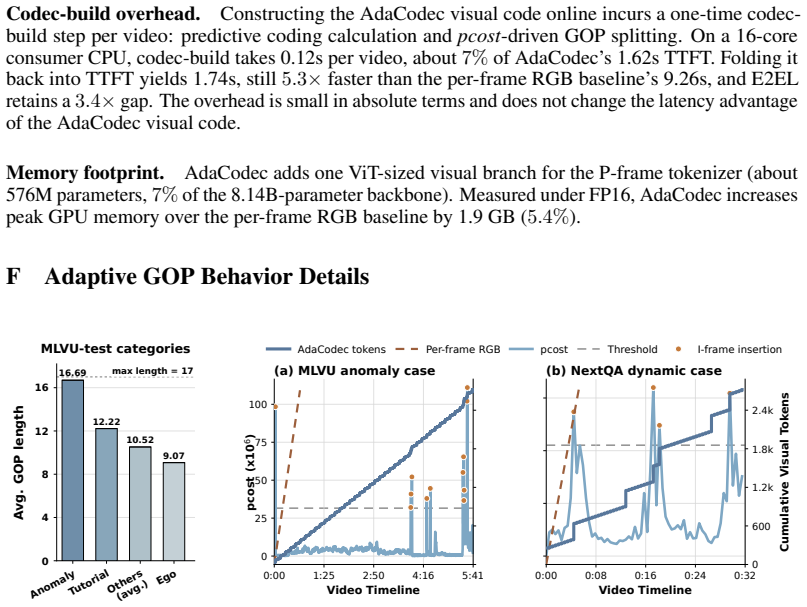
AdaCodec instantiates a predictive visual code that spends full visual tokens on a reference frame only when its conditional predictive cost is high; otherwise it encodes inter-frame changes, including motion and prediction residuals, as compact P-tokens. Across all eleven benchmarks AdaCodec improves over the Qwen3-VL-8B per-frame RGB baseline at matched visual-token budget. Even at 1/7 the budget, 32k-token AdaCodec surpasses the 224k baseline on all long-video benchmarks and on five general-video benchmarks raises average score while cutting time-to-first-token from 9.26s to 1.62s.
What carries the argument
The predictive visual code, which decides between full reference frames and compact P-tokens according to conditional predictive cost of each frame given prior context.
If this is right
- At matched token budget AdaCodec outperforms per-frame RGB encoding on all eleven benchmarks.
- At one-seventh the tokens it surpasses the full baseline on every long-video benchmark.
- On general-video tasks it simultaneously raises average score and reduces time-to-first-token from 9.26s to 1.62s.
- The method directly exploits temporal redundancy by conditioning encoding on prior-frame prediction success.
Where Pith is reading between the lines
- The same conditional decision rule could be applied to other sequential inputs such as audio streams or point-cloud sequences.
- End-to-end training of the predictive-cost estimator might further reduce reliance on a separate motion module.
- Context-dependent tokenization suggests that future visual encoders for MLLMs should accept previous-frame features as additional input rather than process frames in isolation.
Load-bearing premise
The conditional predictive cost reliably identifies frames needing full encoding and the P-tokens preserve all task-relevant information from motion and residuals.
What would settle it
Measure whether AdaCodec at 32k tokens falls below the 224k per-frame baseline accuracy on long-video benchmarks when tested on videos containing abrupt scene changes that break temporal prediction.
Figures
read the original abstract
Video is temporally redundant: adjacent frames usually share most objects, background, and layout. Yet existing video multimodal large language models (video MLLMs) usually encode each sampled frame as an independent RGB image, causing visual tokens to repeat content already present in earlier frames. This suggests a more direct video interface: send a full reference frame only when the scene cannot be predicted well from prior context, and otherwise transmit a compact description of inter-frame changes. We call this interface a \emph{predictive visual code}, and instantiate it for video MLLMs as \textbf{AdaCodec}. AdaCodec spends full visual tokens on a reference frame only when its conditional predictive cost is high; otherwise, it encodes inter-frame changes, including motion and prediction residuals, as compact P-tokens. Across all eleven benchmarks, AdaCodec improves over the Qwen3-VL-8B per-frame RGB baseline at a matched visual-token budget. Even at $1/7$ the budget, AdaCodec with 32k tokens surpasses the 224k baseline on all long-video benchmarks; on five general-video benchmarks, it raises the average score while substantially cutting time-to-first-token from 9.26s to 1.62s.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AdaCodec as a predictive visual code for video MLLMs. It encodes full visual tokens only for reference frames whose conditional predictive cost is high; otherwise it transmits compact P-tokens that encode motion and prediction residuals. The central empirical claim is that this scheme outperforms the Qwen3-VL-8B per-frame RGB baseline across all eleven benchmarks at matched token budgets, that 32 k AdaCodec tokens surpass a 224 k baseline on long-video tasks, and that it simultaneously raises average scores on five general-video benchmarks while cutting time-to-first-token from 9.26 s to 1.62 s.
Significance. If the two core assumptions hold—that conditional predictive cost reliably identifies non-predictable frames and that the resulting P-tokens retain all task-relevant information—the approach would constitute a substantial advance in token-efficient video modeling for MLLMs, directly addressing temporal redundancy that current per-frame encoders ignore.
major comments (2)
- [Abstract and §3] Abstract and §3 (method description): the headline token-budget reductions (32 k vs 224 k) rest on the unverified claim that P-tokens preserve task-relevant motion and residual information whenever predictive cost is low. No ablation, reconstruction metric, or downstream-task control is supplied to test this assumption, which is load-bearing for every reported gain.
- [Abstract] Abstract: no error bars, dataset splits, or statistical controls are reported for any of the eleven benchmarks, so it is impossible to assess whether the claimed improvements over the per-frame RGB baseline are reliable or merely within noise.
minor comments (2)
- Notation for “conditional predictive cost” and “P-tokens” is introduced without a formal definition or pseudocode, making the method non-reproducible from the text alone.
- [Abstract] The abstract states gains “across all eleven benchmarks” but does not list the benchmarks or the exact token budgets used in each comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify important gaps in validation and reporting that we will address directly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): the headline token-budget reductions (32 k vs 224 k) rest on the unverified claim that P-tokens preserve task-relevant motion and residual information whenever predictive cost is low. No ablation, reconstruction metric, or downstream-task control is supplied to test this assumption, which is load-bearing for every reported gain.
Authors: We agree that the information-preservation property of P-tokens is a load-bearing assumption. While the consistent outperformance on eleven downstream benchmarks at matched or reduced budgets supplies indirect empirical support, we recognize that direct controls are needed. In the revised manuscript we will add (i) reconstruction metrics comparing P-token decoded frames against ground-truth frames and (ii) controlled ablations that swap P-tokens for full frames on selected tasks while holding token budget fixed. revision: yes
-
Referee: [Abstract] Abstract: no error bars, dataset splits, or statistical controls are reported for any of the eleven benchmarks, so it is impossible to assess whether the claimed improvements over the per-frame RGB baseline are reliable or merely within noise.
Authors: We accept that the absence of error bars and explicit statistical controls limits interpretability. The reported numbers follow the official evaluation protocols and fixed splits of each benchmark; however, to improve transparency we will include standard-error estimates from multiple forward passes (where stochasticity exists) and will add a short section clarifying the evaluation protocol and any variance observed across runs. revision: yes
Circularity Check
No circularity: empirical method with external baseline comparison
full rationale
The paper introduces AdaCodec as a predictive visual code that allocates full tokens to reference frames based on conditional predictive cost and uses P-tokens for changes. No equations, derivations, or fitting procedures are shown in the provided text. Performance claims are made against the external Qwen3-VL-8B per-frame RGB baseline at matched or reduced token budgets. No self-citations, self-definitional steps, or fitted inputs renamed as predictions appear. The derivation chain is absent, so no reduction to inputs by construction occurs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
VideoChat: Chat-Centric Video Understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. VideoChat: Chat-Centric Video Understanding.arXiv preprint arXiv:2305.06355, 2023. doi: 10.48550/arXiv.2305.06355. URLhttps://arxiv.org/abs/2305.06355
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.06355 2023
-
[2]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, Bangkok, Thailand, 2024. Association for Computational Linguistics. doi:...
-
[3]
Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 543–553, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-demo.49. URL http...
-
[4]
Video-LLaV A: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning United Visual Representation by Alignment Before Projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5971–5984, Miami, Florida, USA, 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.e...
-
[5]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understand- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13700–13710, June 2024. doi: 10.1109/CVPR52733.2024.01300. URL https: //openacc...
-
[6]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. LLaV A-OneVision: Easy Visual Task Transfer.arXiv preprint arXiv:2408.03326, 2024. doi: 10.48550/arXiv.2408.03326. URL https://arxiv.org/abs/2408. 03326
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03326 2024
-
[7]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.arXiv preprint arXiv:2409.12191, 2024. d...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12191 2024
-
[8]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analy- sis. I...
-
[9]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. MLVU: Benchmarking Multi-task Long Video Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 13691–13701, June 2025. doi: 10.1109/CVPR52734.2025.01...
-
[10]
KeyVideoLLM: Towards Large-scale Video Keyframe Selection.arXiv preprint arXiv:2407.03104, 2024
Hao Liang, Jiapeng Li, Tianyi Bai, Xijie Huang, Linzhuang Sun, Zhengren Wang, Conghui He, Bin Cui, Chong Chen, and Wentao Zhang. KeyVideoLLM: Towards Large-scale Video Keyframe Selection.arXiv preprint arXiv:2407.03104, 2024. doi: 10.48550/arXiv.2407.03104. URL https://arxiv.org/abs/ 2407.03104
-
[11]
Frame-V oyager: Learning to Query Frames for Video Large Language Models
Sicheng Yu, Chengkai Jin, Huanyu Wang, Zhenghao Chen, Sheng Jin, Zhongrong Zuo, Xiaolei Xu, Zhenbang Sun, Bingni Zhang, Jiawei Wu, Hao Zhang, and Qianru Sun. Frame-V oyager: Learning to Query Frames for Video Large Language Models. InProceedings of the International Conference on Learning Representations (ICLR), 2025. URL https://proceedings.iclr.cc/paper...
2025
-
[12]
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. Adaptive Keyframe Sam- pling for Long Video Understanding. InProceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 29118–29128, June 2025. doi: 10.1109/CVPR52734. 2025.02711. URL https://openaccess.thecvf.com/content/CVPR2025/html/Tang_Ad...
-
[13]
MDP3: A Training-free Approach for List-wise Frame Selection in Video-LLMs
Hui Sun, Shiyin Lu, Huanyu Wang, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Ming Li. MDP3: A Training-free Approach for List-wise Frame Selection in Video-LLMs. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 24090–24101, October 2025. URL https://openaccess.thecvf.com/content/ICCV2025/html/Sun_MDP3_A_Trai...
2025
-
[14]
Q-Frame: Query-aware Frame Selection and Multi-Resolution Adaptation for Video-LLMs
Shaojie Zhang, Jiahui Yang, Jianqin Yin, Zhenbo Luo, and Jian Luan. Q-Frame: Query-aware Frame Selection and Multi-Resolution Adaptation for Video-LLMs. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22056–22065, October 2025. URL https: //openaccess.thecvf.com/content/ICCV2025/html/Zhang_Q-Frame_Query-aware_Frame_...
2025
-
[15]
LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models
Yanwei Li, Chengyao Wang, and Jiaya Jia. LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models. InComputer Vision – ECCV 2024, volume 15104 ofLecture Notes in Computer Science, pages 323–340. Springer, 2024. doi: 10.1007/978-3-031-72952-2_19. URL https://www.ecva.net/ papers/eccv_2024/papers_ECCV/html/6290_ECCV_2024_paper.php
-
[16]
Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, Zhuang Liu, Hu Xu, Hyunwoo J. Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra. LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding. InProceedings...
2025
-
[17]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18992–19001, June 2025. doi: 10.1109/CVPR52734.2025.01769. URL https://openaccess.thecvf.com/content/CVPR2025/html/Tao_DyCoke_...
-
[18]
AdaReTaKe: Adap- tive Redundancy Reduction to Perceive Longer for Video-language Understanding
Xiao Wang, Qingyi Si, Shiyu Zhu, Jianlong Wu, Li Cao, and Liqiang Nie. AdaReTaKe: Adap- tive Redundancy Reduction to Perceive Longer for Video-language Understanding. InFindings of the Association for Computational Linguistics: ACL 2025, pages 5417–5432, Vienna, Austria, July
2025
-
[19]
doi: 10.18653/v1/2025.findings-acl.283
Association for Computational Linguistics. doi: 10.18653/v1/2025.findings-acl.283. URL https://aclanthology.org/2025.findings-acl.283/
-
[20]
FrameFusion: Combining Similarity and Importance for Video Token Reduction on Large Vision Language Models
Tianyu Fu, Tengxuan Liu, Qinghao Han, Guohao Dai, Shengen Yan, Huazhong Yang, Xue- fei Ning, and Yu Wang. FrameFusion: Combining Similarity and Importance for Video Token Reduction on Large Vision Language Models. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV), pages 22654–22663, October 2025. URL https://openaccess.the...
2025
-
[21]
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 14313–14323, June 2024. doi: 10.1109/CVPR52733.2024.01357. URL https://openaccess.thecvf.com/content/CVPR2024/ ...
-
[22]
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, Yan Lu, Jenq-Neng Hwang, and Gaoang Wang. MovieChat: From Dense Token to Sparse Memory for Long Video Un- derstanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 18221–18232,...
-
[23]
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern 11 Recognition (CVPR), pages 13504–13514, June 2024. doi: 10.1109/CVPR52733.2024.01282. UR...
-
[24]
Streaming Long Video Understanding with Large Language Models
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, and Jiaqi Wang. Streaming Long Video Understanding with Large Language Models. InAdvances in Neural Information Processing Systems, volume 37, pages 119336–119360, 2024. doi: 10. 52202/079017-3792. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ d7ce06e9293c3d8e6cb3f...
2024
-
[25]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long Context Transfer from Language to Vision.arXiv preprint arXiv:2406.16852, 2024. doi: 10.48550/arXiv.2406.16852. URL https://arxiv.org/abs/ 2406.16852
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.16852 2024
-
[26]
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Hao- tian Tang, Shang Yang, Zhijian Liu, Ethan He, Hongxu Yin, Pavlo Molchanov, Jan Kautz, Jim Fan, Yuke Zhu, Yao Lu, and Song Han. LongVILA: Scaling Long-Context Visual Language Models for Long Videos. InProceedings of the International Conference on Learning Representati...
2025
-
[27]
Kwai Keye-VL 1.5 Technical Report.arXiv preprint arXiv:2509.01563, 2025
Biao Yang, Bin Wen, Boyang Ding, Changyi Liu, Chenglong Chu, Chengru Song, Chongling Rao, Chuan Yi, Da Li, Dunju Zang, Fan Yang, Guorui Zhou, Guowang Zhang, Han Shen, Hao Peng, Haojie Ding, Hao Wang, Haonan Fan, Hengrui Ju, Jiaming Huang, Jiangxia Cao, Jiankang Chen, Jingyun Hua, Kaibing Chen, Kaiyu Jiang, Kaiyu Tang, Kun Gai, Muhao Wei, Qiang Wang, Ruita...
-
[28]
Chao-Yuan Wu, Manzil Zaheer, Hexiang Hu, R. Manmatha, Alexander J. Smola, and Philipp Krähen- bühl. Compressed Video Action Recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6026–6035, June 2018. doi: 10.1109/CVPR.2018. 00631. URL https://openaccess.thecvf.com/content_cvpr_2018/html/Wu_Compressed_ V...
-
[29]
DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition
Zheng Shou, Xudong Lin, Yannis Kalantidis, Laura Sevilla-Lara, Marcus Rohrbach, Shih-Fu Chang, and Zhicheng Yan. DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 1268–1277, June 2019. doi: 10.1109/CVPR.2019.00136....
-
[30]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zijia Zhao, Yuqi Huo, Tongtian Yue, Longteng Guo, Haoyu Lu, Bingning Wang, Weipeng Chen, and Jing Liu. Efficient Motion-Aware Video MLLM. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 24159–24168, June 2025. doi: 10.1109/CVPR52734.2025.02250. URL https://openaccess.thecvf.com/content/CVPR2025/ html/Zha...
-
[31]
Sayan Deb Sarkar, Rémi Pautrat, Ondrej Miksik, Marc Pollefeys, Iro Armeni, Mahdi Rad, and Mihai Dusmanu. CoPE-VideoLM: Leveraging Codec Primitives For Efficient Video Language Modeling.arXiv preprint arXiv:2602.13191, 2026. doi: 10.48550/arXiv.2602.13191. URL https://arxiv.org/abs/ 2602.13191
-
[32]
Daichi Yashima, Shuhei Kurita, Yusuke Oda, and Komei Sugiura. ReMoRa: Multimodal Large Lan- guage Model based on Refined Motion Representation for Long-Video Understanding.arXiv preprint arXiv:2602.16412, 2026. doi: 10.48550/arXiv.2602.16412. URL https://arxiv.org/abs/2602. 16412. Accepted to CVPR 2026
-
[33]
Rajesh P. N. Rao and Dana H. Ballard. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects.Nature Neuroscience, 2(1):79–87, 1999. doi: 10.1038/4580. 12
-
[34]
Sullivan, Gisle Bjøntegaard, and Ajay Luthra
Thomas Wiegand, Gary J. Sullivan, Gisle Bjøntegaard, and Ajay Luthra. Overview of the H.264/A VC video coding standard.IEEE Transactions on Circuits and Systems for Video Technology, 13(7):560–576,
-
[35]
doi: 10.1109/TCSVT.2003.815165
-
[36]
Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand
Gary J. Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand. Overview of the High Efficiency Video Coding (HEVC) Standard.IEEE Transactions on Circuits and Systems for Video Technology, 22 (12):1649–1668, 2012. doi: 10.1109/TCSVT.2012.2221191
-
[37]
Feilong Tang, Xiang An, Yunyao Yan, Yin Xie, Bin Qin, Kaicheng Yang, Yifei Shen, Yuanhan Zhang, Chunyuan Li, Shikun Feng, Changrui Chen, Huajie Tan, Ming Hu, Manyuan Zhang, Bo Li, Ziyong Feng, Ziwei Liu, Zongyuan Ge, and Jiankang Deng. OneVision-Encoder: Codec-Aligned Sparsity as a Foundational Principle for Multimodal Intelligence.arXiv preprint arXiv:26...
-
[38]
Haotian Ye, Qiyuan He, Jiaqi Han, Puheng Li, Jiaojiao Fan, Zekun Hao, Fitsum Reda, Yogesh Balaji, Huayu Chen, Sheng Liu, Angela Yao, James Zou, Stefano Ermon, Haoxiang Wang, and Ming-Yu Liu. InfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic Compression.arXiv preprint arXiv:2512.16975, 2025. doi: 10.48550/arXiv.2512.16975. URL https://ar...
-
[39]
A Technical Overview of A V1.Proceedings of the IEEE, 109(9):1435–1462, September 2021
Jingning Han, Bohan Li, Debargha Mukherjee, Ching-Han Chiang, Adrian Grange, Cheng Chen, Hui Su, Sarah Parker, Sai Deng, Urvang Joshi, Yue Chen, Yunqing Wang, Paul Wilkins, Yaowu Xu, and James Bankoski. A Technical Overview of A V1.Proceedings of the IEEE, 109(9):1435–1462, September 2021. doi: 10.1109/JPROC.2021.3058584. URLhttps://doi.org/10.1109/JPROC....
-
[40]
Real-Time Action Recogni- tion with Enhanced Motion Vector CNNs
Bowen Zhang, Limin Wang, Zhe Wang, Yu Qiao, and Hanli Wang. Real-Time Action Recogni- tion with Enhanced Motion Vector CNNs. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2718–2726, June 2016. doi: 10.1109/CVPR.2016
-
[41]
URL https://openaccess.thecvf.com/content_cvpr_2016/html/Zhang_Real-Time_ Action_Recognition_CVPR_2016_paper.html
-
[42]
TEAM-Net: Multi-modal Learning for Video Action Recognition with Partial Decoding
Zhengwei Wang, Qi She, and Aljosa Smolic. TEAM-Net: Multi-modal Learning for Video Action Recognition with Partial Decoding. InProceedings of the British Machine Vision Conference (BMVC),
-
[43]
URL https://www.bmva-archive.org.uk/bmvc/2021/conference/ papers/paper_0483.html
doi: 10.5244/C.35.138. URL https://www.bmva-archive.org.uk/bmvc/2021/conference/ papers/paper_0483.html
-
[44]
Compressed sensing mri reconstruction with co-vegan: Complex-valued generative adversarial network
Jiawei Chen and Chiu Man Ho. MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 786–797, January 2022. doi: 10.1109/WACV51458.2022.00086. URL https: //doi.org/10.1109/WACV51458.2022.00086
-
[46]
Accelerating Video Object Segmentation with Compressed Video
Kai Xu and Angela Yao. Accelerating Video Object Segmentation with Compressed Video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1332–1341, June
-
[47]
doi: 10.1109/CVPR52688.2022.00140. URL https://doi.org/10.1109/CVPR52688.2022. 00140
-
[48]
Deepsd: Automatic deep skinning and pose space deformation for 3d garment animation
Zhipeng Fan, Jun Liu, and Yao Wang. Motion Adaptive Pose Estimation from Compressed Videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11699–11708, October 2021. doi: 10.1109/ICCV48922.2021.01151. URL https://doi.org/10.1109/ICCV48922. 2021.01151
-
[49]
Deepsd: Automatic deep skinning and pose space deformation for 3d garment animation
Nayoung Kim, Seong Jong Ha, and Je-Won Kang. Video Question Answering Using Language-Guided Deep Compressed-Domain Video Feature. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 1688–1697, October 2021. doi: 10.1109/ICCV48922.2021.00173. URL https://doi.org/10.1109/ICCV48922.2021.00173
-
[50]
Yaojie Shen, Xin Gu, Kai Xu, Heng Fan, Longyin Wen, and Libo Zhang. Accurate and Fast Compressed Video Captioning. InProceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 15558–15567, October 2023. doi: 10.1109/ICCV51070.2023.01426. URL https://openaccess.thecvf.com/content/ICCV2023/html/Shen_Accurate_and_Fast_ Compressed...
-
[51]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[52]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding , url =
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding. InAdvances in Neural Information Processing Systems, volume 37, pages 28828–28857, 2024. doi: 10.52202/079017-0907. URLhttps://papers.nips.cc/ paper_files/paper/2024/hash/329ad516cf7a6ac306f29882e9c77558-Abstract-Datasets_...
-
[53]
LVBench: An Extreme Long Video Understanding Benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, Yuxiao Dong, and Jie Tang. LVBench: An Extreme Long Video Understanding Benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22958–22967, October 2025. URL https://openaccess.thecvf.com/content/ICCV...
2025
-
[54]
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. TempCompass: Do video LLMs really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.517....
-
[55]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Wenyi Hong, Yean Cheng, Zhuoyi Yang, Weihan Wang, Lefan Wang, Xiaotao Gu, Shiyu Huang, Yuxiao Dong, and Jie Tang. MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 8450–8460, June 2025. doi: 10.1109/...
-
[56]
TOMATO: Assessing Visual Temporal Reasoning Capabilities in Multimodal Foundation Models
Ziyao Shangguan, Chuhan Li, Yuxuan Ding, Yanan Zheng, Yilun Zhao, Tesca Fitzgerald, and Arman Cohan. TOMATO: Assessing Visual Temporal Reasoning Capabilities in Multimodal Foundation Models. InProceedings of the International Conference on Learning Representa- tions (ICLR), 2025. URL https://proceedings.iclr.cc/paper_files/paper/2025/hash/ 16ba99f25a235f1...
2025
-
[57]
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. MVBench: A Comprehensive Multi-modal Video Understanding Benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22195–22206, June 2024. doi: 10.1109/CVPR52733. 2024.02095. URL ...
-
[58]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. NExT-QA: Next phase of question- answering to explaining temporal actions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9777–9786, June 2021. doi: 10.1109/CVPR46437.2021. 00965. URL https://openaccess.thecvf.com/content/CVPR2021/html/Xiao_NExT-QA_...
-
[59]
Perception Test: A diagnostic benchmark for multimodal video models
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Recasens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovi- cova, Yury Sulsky, Antoine Miech, Alexandre Fréchette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, Yusuf Aytar, Simon Osindero, Dima Damen, Andrew ...
2023
-
[60]
EgoSchema: A Diagnostic Bench- mark for Very Long-form Video Language Understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. EgoSchema: A Diagnostic Bench- mark for Very Long-form Video Language Understanding. InAdvances in Neural Information Process- ing Systems, volume 36, 2023. URL https://papers.nips.cc/paper_files/paper/2023/hash/ 90ce332aff156b910b002ce4e6880dec-Abstract-Datasets_and_Benchmarks.html. Datasets a...
2023
-
[61]
In Findings of the Association for Computational Lin- guistics: EMNLP 2025
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. LMMs-eval: Reality check on the evaluation of large multimodal models. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational Linguistics: NAACL 2025, pages 881–916...
-
[62]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, Vincent Shao, Yue Yang, Weikai Huang, Ziqi Gao, Taira Anderson, Jianrui Zhang, Jitesh Jain, George Stoica, Winson Han, Ali Farhadi, and Ranjay Krishna. Molmo2: Open Weights and Data for Vision-Language M...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.10611 2026
-
[63]
GPT-5 System Card, August 2025
OpenAI. GPT-5 System Card, August 2025. URL https://openai.com/index/ gpt-5-system-card/
2025
-
[64]
Gemini 3 Pro - Model Card, December 2025
Google DeepMind. Gemini 3 Pro - Model Card, December 2025. URL https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf . Model card update: De- cember 2025
2025
-
[65]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities, 2025
Google DeepMind. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities, 2025. URLhttps://storage.googleapis.com/ deepmind-media/gemini/gemini_v2_5_report.pdf
2025
-
[66]
Claude Sonnet 4.5 System Card, September 2025
Anthropic. Claude Sonnet 4.5 System Card, September 2025. URL https://assets.anthropic.com/ m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf
2025
-
[67]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Zhi Hou,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.18265 2025
-
[68]
GLM-V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Haochen Li, Jiale Zhu, Jiali Chen...
-
[69]
doi: 10.48550/arXiv.2507.01006. URLhttps://arxiv.org/abs/2507.01006
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.01006
-
[70]
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, Bokai Xu, Junbo Cui, Yingjing Xu, Liqing Ruan, Luoyuan Zhang, Hanyu Liu, Jingkun Tang, Hongyuan Liu, Qining Guo, Wenhao Hu, Bingxiang He, Jie Zhou, Jie Cai, Ji Qi, Zonghao Guo, Chi Chen, Guoyang Zeng, Yuxuan Li, Ganqu Cui, Ning D...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.18154 2025
-
[71]
Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Tuomas Rintamaki, Tyler Poon, Max Ehrlich, Tong Lu, Limin Wang, Bryan Catanzaro, Jan Kautz, Andrew Tao, Zhiding Yu, and Guilin Liu. Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models.arXiv preprint arXiv:2504.1527...
-
[72]
Jang Hyun Cho, Andrea Madotto, Effrosyni Mavroudi, Triantafyllos Afouras, Tushar Nagarajan, Muham- mad Maaz, Yale Song, Tengyu Ma, Shuming Hu, Suyog Jain, Miguel Martin, Huiyu Wang, Hanoona Rasheed, Peize Sun, Po-Yao Huang, Daniel Bolya, Nikhila Ravi, Shashank Jain, Tammy Stark, Shane Moon, Babak Damavandi, Vivian Lee, Andrew Westbury, Salman Khan, Philip...
-
[73]
LLaV A-Video: Video Instruction Tuning With Synthetic Data.Transactions on Machine Learning Research, 2025
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. LLaV A-Video: Video Instruction Tuning With Synthetic Data.Transactions on Machine Learning Research, 2025. URL https://openreview.net/forum?id=EElFGvt39K
2025
-
[74]
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, Yu Qiao, Yali Wang, and Limin Wang. VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling.arXiv preprint arXiv:2501.00574, 2025. doi: 10.48550/ arXiv.2501.00574. URLhttps://arxiv.org/abs/2501.00574
Pith/arXiv arXiv 2025
-
[75]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN: Efficient Context Window Extension of Large Language Models.arXiv preprint arXiv:2309.00071, 2023. doi: 10.48550/arXiv.2309. 00071. URLhttps://arxiv.org/abs/2309.00071. Revised February 2026
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309 2023
-
[76]
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. ActivityNet-QA: A Dataset for Understanding Complex Web Videos via Question Answering.Proceedings of the AAAI Conference on Artificial Intelligence, 33(01):9127–9134, 2019. doi: 10.1609/aaai.v33i01.33019127. URL https://doi.org/10.1609/aaai.v33i01.33019127
-
[77]
Weijia Wu, Yuzhong Zhao, Zhuang Li, Jiahong Li, Hong Zhou, Mike Zheng Shou, and Xiang Bai. A Large Cross-Modal Video Retrieval Dataset with Reading Comprehension.arXiv preprint arXiv:2305.03347,
-
[78]
URLhttps://arxiv.org/abs/2305.03347
doi: 10.48550/arXiv.2305.03347. URLhttps://arxiv.org/abs/2305.03347
-
[79]
Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta
Gunnar A. Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hol- lywood in Homes: Crowdsourcing Data Collection for Activity Understanding. InComputer Vision – ECCV 2016, volume 9905 ofLecture Notes in Computer Science, pages 510–526. Springer, 2016. doi: 10.1007/978-3-319-46448-0_31. URLhttps://doi.org/10.1007/978-3-319-4...
-
[80]
Anna Rohrbach, Atousa Torabi, Marcus Rohrbach, Niket Tandon, Christopher Joseph Pal, Hugo Larochelle, Aaron C. Courville, and Bernt Schiele. Movie Description.International Journal of Computer Vision, 123 (1):94–120, 2017. doi: 10.1007/s11263-016-0987-1. URL https://link.springer.com/article/ 10.1007/s11263-016-0987-1
-
[81]
TGIF-QA: Toward Spatio- Temporal Reasoning in Visual Question Answering
Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. TGIF-QA: Toward Spatio- Temporal Reasoning in Visual Question Answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1359–1367, July 2017. doi: 10.1109/CVPR.2017.149. URL https://doi.org/10.1109/CVPR.2017.149
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.