Follow-Your-Preference++: Rethinking Preference Alignment for Image Inpainting
Pith reviewed 2026-06-28 10:49 UTC · model grok-4.3
The pith
An ensemble of nine public reward models lets direct preference optimization improve inpainting models without architecture changes or new data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
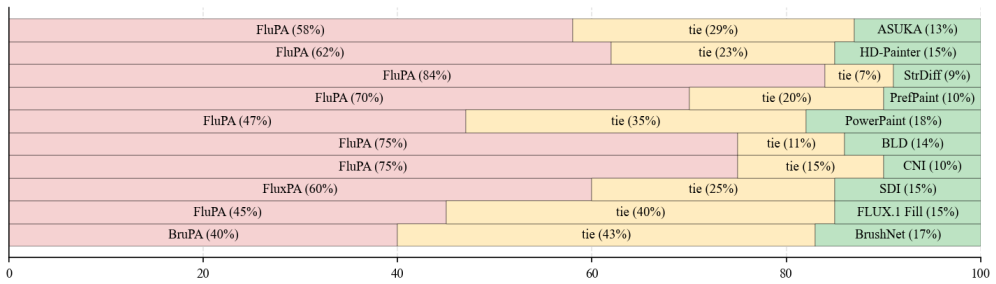
Preference data constructed from an ensemble of reward models, when used inside direct preference optimization, yields inpainting models that outperform prior state-of-the-art approaches on standard metrics, large vision-language model evaluations, and human assessments, while the same models transfer successfully to object removal; the gains arise without any architectural modification or additional training datasets.
What carries the argument
An ensemble of reward models that constructs preference pairs for direct preference optimization training.
If this is right
- Preference alignment improves inpainting quality across different model architectures and generative mechanisms.
- An ensemble of reward models produces more robust and generalizable performance than any single reward model.
- The aligned models transfer to object removal, shifting the task from open-ended generation to coherent background completion.
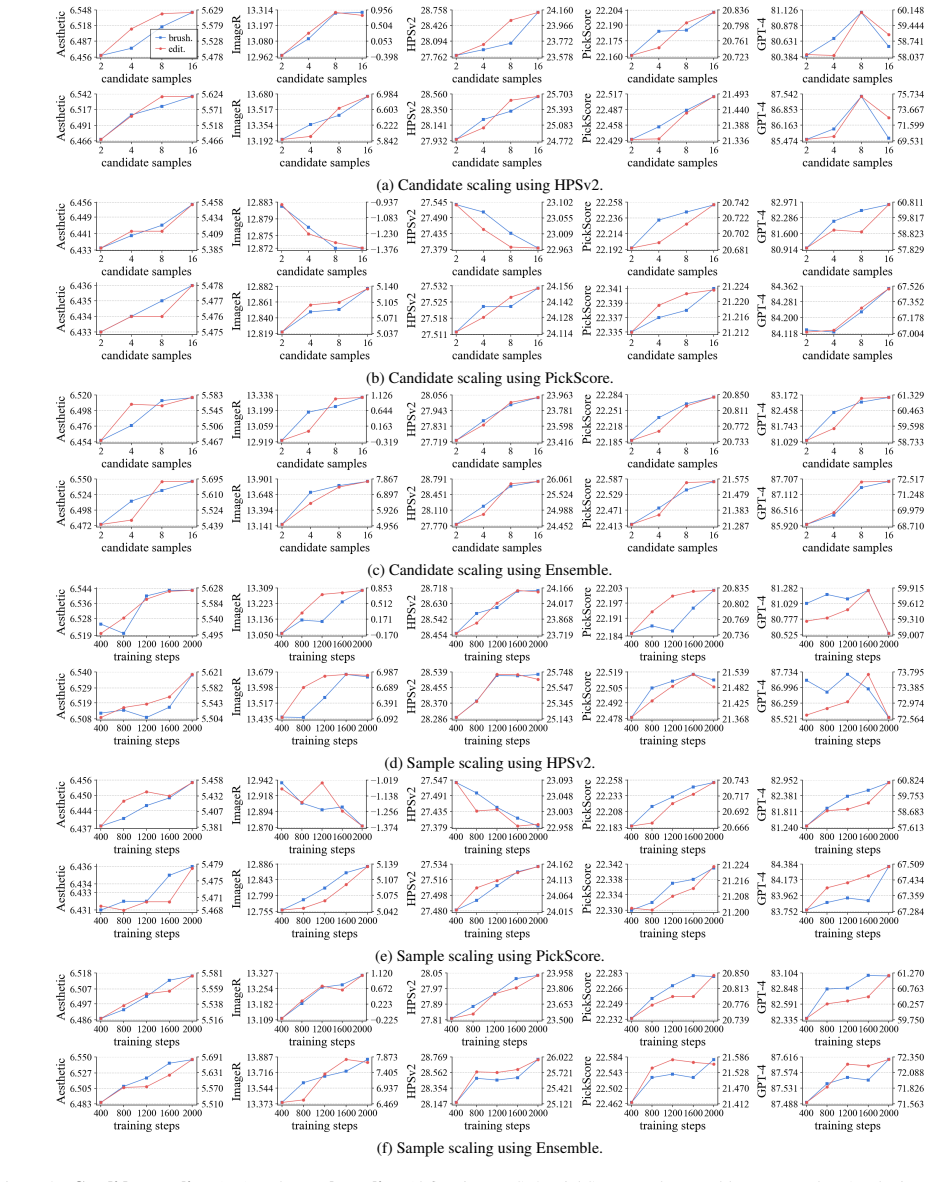
- Consistent scaling trends appear when the number of candidate pairs or samples is increased.
- A calibrated ensemble variant further reduces reward hacking and increases robustness.
Where Pith is reading between the lines
- Reward-model biases observed here may appear in other generative tasks that rely on the same public reward models.
- The transfer result suggests the alignment procedure could be tested on additional image-editing operations such as outpainting or style transfer.
- Future work could replace the public reward models with ones trained specifically on inpainting human preferences to test whether further gains are possible.
- The finding that most reward models remain useful as data sources even when unreliable as evaluators may apply to preference tuning in other domains.
Load-bearing premise
The preference pairs built from the nine reward models reflect genuine human preferences for inpainting quality rather than the reward models' own biases toward brightness, composition, and color.
What would settle it
A controlled human study in which raters consistently prefer the outputs of the original unaligned inpainting models over the preference-aligned versions in side-by-side blind comparisons would falsify the performance claim.
Figures










read the original abstract
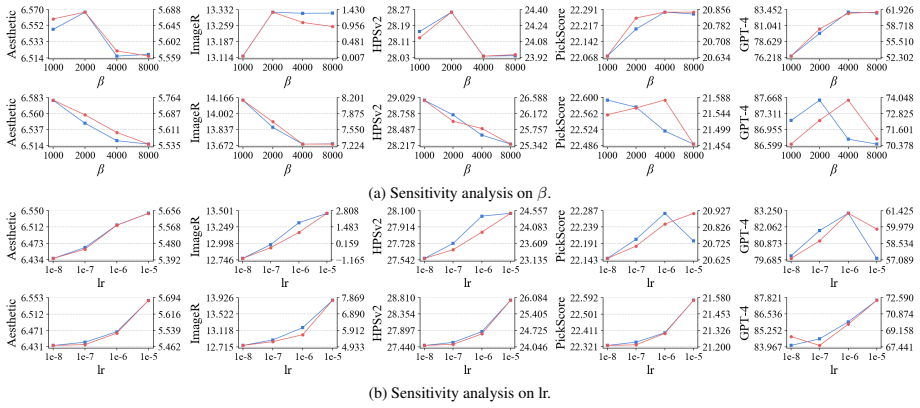
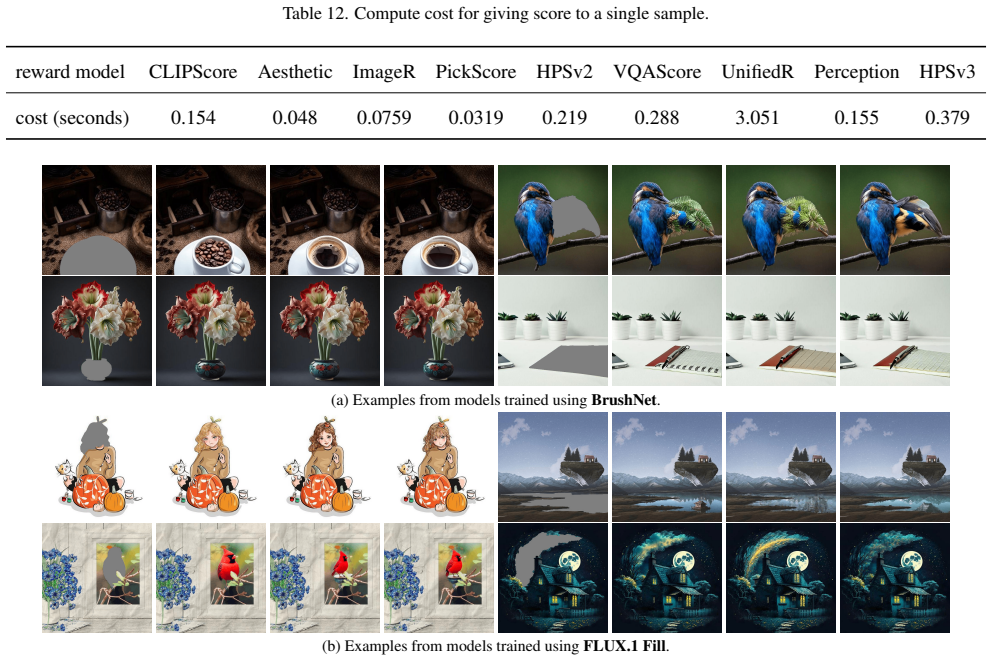
We study preference alignment for image inpainting. Rather than proposing yet another method, we revisit the problem from first principles and reassess its core challenges. We adopt the widely used direct preference optimization framework and construct preference training data with publicly available reward models. Our empirical study spans nine reward models, two benchmarks, and two baseline inpainting models that differ in architecture and generative mechanism. Our main findings are: (1) Most reward models provide valid signals for preference data construction, although some are unreliable as evaluators. (2) Across models and benchmarks, preference data exhibits consistent trends under both candidate and sample scaling. (3) Reward models display pronounced biases--particularly in brightness, composition, and color scheme--that make them prone to inducing reward hacking. (4) A simple ensemble of reward models mitigates such biases and yields robust, generalizable performance. {\color{rebuttal_blue}(5) Preference alignment is transferable to the object removal task, where the goal shifts from open-ended creative generation to coherent background completion. (6) Further analysis reveals that a calibrated ensemble method further mitigates hacking and improves robustness.} Without modifying model architectures or introducing additional datasets, our models substantially outperform prior state-of-the-art models on standard metrics, large vision-language model evaluations, and human assessments. Our code is available at: https://github.com/shenytzzz/Follow-Your-Preference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical study on preference alignment for image inpainting via Direct Preference Optimization (DPO). It constructs preference pairs using nine public reward models (plus an ensemble and calibrated variant) applied to outputs from two inpainting architectures on two benchmarks. The central claims are that most reward models provide usable signals, scaling trends are consistent, individual models exhibit biases in brightness/composition/color that risk reward hacking, the ensemble mitigates these issues, alignment transfers to object removal, and the resulting models substantially outperform prior SOTA on standard metrics, VLM evaluations, and human assessments without architectural modifications or new datasets. Code is released.
Significance. If the central claims hold, the work offers a practical, architecture-agnostic route to preference alignment for inpainting that leverages only existing reward models and benchmarks. The broad sweep across nine reward models, documentation of their biases, and demonstration of ensemble mitigation provide reusable insights for the community. Reproducibility is strengthened by the public code release. The transfer result to object removal further broadens applicability.
major comments (1)
- [Findings (3)–(4) and human evaluation results] The central claim of outperformance on human assessments (abstract and finding (4)) rests on the ensemble serving as a valid proxy for desirable inpainting quality. The manuscript documents pronounced biases in individual reward models and presents the ensemble as mitigation, yet provides no quantitative verification—such as rank correlation (Kendall’s τ or Spearman’s ρ), agreement rates, or pairwise comparison on a held-out set of inpainted images—between the ensemble’s preference rankings and independent human preference rankings. This verification is load-bearing for interpreting the human-assessment gains as generalizable improvements rather than optimization toward shared visual biases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The point raised about validating the ensemble against human preferences is well-taken, and we address it directly below with a commitment to strengthen the manuscript.
read point-by-point responses
-
Referee: [Findings (3)–(4) and human evaluation results] The central claim of outperformance on human assessments (abstract and finding (4)) rests on the ensemble serving as a valid proxy for desirable inpainting quality. The manuscript documents pronounced biases in individual reward models and presents the ensemble as mitigation, yet provides no quantitative verification—such as rank correlation (Kendall’s τ or Spearman’s ρ), agreement rates, or pairwise comparison on a held-out set of inpainted images—between the ensemble’s preference rankings and independent human preference rankings. This verification is load-bearing for interpreting the human-assessment gains as generalizable improvements rather than optimization toward shared visual biases.
Authors: We agree that explicit quantitative validation of the ensemble's alignment with human judgments would strengthen the claims. The human assessments reported in the paper are direct evaluations of the final model outputs (not mediated by the ensemble), providing independent evidence of improvement on standard metrics, VLM judgments, and human ratings. However, to address the concern about potential shared biases and to confirm the ensemble as a reliable proxy, we will add a new subsection in the revised manuscript. This will report Kendall’s τ and Spearman’s ρ, along with agreement rates, computed between the ensemble preference rankings and independent human preference rankings on a held-out set of inpainted images. We will also include pairwise comparison results. This analysis will be performed on data from the existing benchmarks and human study protocol. We believe this addition directly mitigates the load-bearing concern while preserving the architecture-agnostic nature of the study. revision: yes
Circularity Check
No circularity: empirical study with external reward models and benchmarks
full rationale
The paper is an empirical investigation that constructs preference pairs from nine publicly available reward models, applies DPO to two baseline inpainting models, and reports gains on standard metrics, VLM evaluations, and human assessments. No mathematical derivations, equations, or first-principles results are presented that reduce by construction to fitted parameters or self-defined quantities within the paper. Claims rest on experimental outcomes across models and benchmarks rather than any self-referential prediction or ansatz. Self-citations, if present, are not load-bearing for the central empirical findings, which remain independently falsifiable against external human judgments and public benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward models provide valid signals for preference data construction in image inpainting
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Blended latent diffusion.ACM transactions on graphics, 2023
Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion.ACM transactions on graphics, 2023. 2, 10
2023
-
[3]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. InInternational Confer- ence on Artificial Intelligence and Statistics, 2024. 2
2024
-
[4]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Image inpainting
Marcelo Bertalmio, Guillermo Sapiro, Vincent Caselles, and Coloma Ballester. Image inpainting. InProceedings of the 27th annual conference on Computer graphics and interactive techniques, 2000. 1, 2
2000
-
[6]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Flux.1-dev.https://huggingface
BlackForestLabs. Flux.1-dev.https://huggingface. co/black- forest- labs/FLUX.1- dev, 2024. Ac- cessed: 2025-07-12. 2
2024
-
[8]
Flux.1-fill-dev.https : / / huggingface.co/black- forest- labs/FLUX.1- Fill-dev, 2024
BlackForestLabs. Flux.1-fill-dev.https : / / huggingface.co/black- forest- labs/FLUX.1- Fill-dev, 2024. Accessed: 2025-07-12. 1, 3, 10 16
2024
-
[9]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, An- drea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Ra- jasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the network. arXiv preprint arXiv:2504.13181, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. 3
2023
-
[11]
Qihua Chen, Yue Ma, Hongfa Wang, Junkun Yuan, Wenzhe Zhao, Qi Tian, Hongmei Wang, Shaobo Min, Qifeng Chen, and Wei Liu. Follow-your-canvas: Higher-resolution video outpainting with extensive content generation.arXiv preprint arXiv:2409.01055, 2024. 2
-
[12]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim En- tezari, Jonas M¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InInternational conference on machine learning, 2024. 2, 3
2024
-
[13]
Dpok: Reinforcement learning for fine-tuning text-to-image diffu- sion models.Advances in Neural Information Processing Systems, 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffu- sion models.Advances in Neural Information Processing Systems, 2023. 1, 3
2023
-
[14]
I dream my painting: Connecting mllms and diffusion models via prompt generation for text-guided multi-mask inpainting
Nicola Fanelli, Gennaro Vessio, and Giovanna Castellano. I dream my painting: Connecting mllms and diffusion models via prompt generation for text-guided multi-mask inpainting. InIEEE/CVF Winter Conference on Applications of Computer Vision, 2025. 9
2025
-
[15]
Dit4edit: Diffusion transformer for image editing
Kunyu Feng, Yue Ma, Bingyuan Wang, Chenyang Qi, Haozhe Chen, Qifeng Chen, and Zeyu Wang. Dit4edit: Diffusion transformer for image editing. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2969–2977, 2025. 2
2025
-
[16]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiao- jie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning ca- pability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning.arXiv preprint arXiv:2104.08718, 2021. 5, 15
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 2020. 1, 2, 3
2020
-
[22]
Reinforcement learning in generative multimodal ai: A survey.Authorea Preprints, 2026
Zijing Hu, Junkun Yuan, Kairong Han, Yunze Tong, Shengyu Zhang, Fei Wu, and Kun Kuang. Reinforcement learning in generative multimodal ai: A survey.Authorea Preprints, 2026. 3
2026
-
[23]
Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion
Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, and Qiang Xu. Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion. InEuropean Conference on Computer Vision, 2024. 1, 2, 3, 5, 9, 10
2024
-
[24]
Rad: Region-aware diffusion models for image inpainting
Sora Kim, Sungho Suh, and Minsik Lee. Rad: Region-aware diffusion models for image inpainting. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2025. 3
2025
-
[25]
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Ma- tiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 2023. 1, 5, 10
2023
-
[26]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Calibrated multi-preference optimization for aligning diffusion models
Kyungmin Lee, Xiahong Li, Qifei Wang, Junfeng He, Junjie Ke, Ming-Hsuan Yang, Irfan Essa, Jinwoo Shin, Feng Yang, and Yinxiao Li. Calibrated multi-preference optimization for aligning diffusion models. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2025. 3, 4, 14
2025
-
[28]
Blip: Bootstrapping language-image pre-training for unified vision- language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision- language understanding and generation. InInternational con- ference on machine learning, 2022. 5
2022
-
[29]
Rorem: Training a robust object remover with human-in-the-loop
Ruibin Li, Tao Yang, Song Guo, and Lei Zhang. Rorem: Training a robust object remover with human-in-the-loop. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 3, 15
2025
-
[30]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021. 1
2021
-
[31]
Eval- uating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Eval- uating text-to-visual generation with image-to-text generation. InEuropean Conference on Computer Vision, 2024. 5
2024
-
[32]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Structure matters: Tackling the semantic discrepancy in diffusion models for image inpainting
Haipeng Liu, Yang Wang, Biao Qian, Meng Wang, and Yong Rui. Structure matters: Tackling the semantic discrepancy in diffusion models for image inpainting. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2024. 10
2024
-
[34]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Wenyu Qin, Meng- han Xia, et al. Improving video generation with human feed- back.arXiv preprint arXiv:2501.13918, 2025. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Prefpaint: Aligning image inpainting diffusion model with human preference.Advances in Neural Information Processing Systems, 2024
Kendong Liu, Zhiyu Zhu, Chuanhao Li, Hui Liu, Huanqiang Zeng, and Junhui Hou. Prefpaint: Aligning image inpainting diffusion model with human preference.Advances in Neural Information Processing Systems, 2024. 3, 10 17
2024
-
[36]
Repaint: Inpainting us- ing denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting us- ing denoising diffusion probabilistic models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[37]
Sit: Exploring flow and diffusion-based generative models with scalable in- terpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable in- terpolant transformers. InEuropean Conference on Computer Vision, 2024. 3
2024
-
[38]
Scaling inference time compute for diffusion models
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu- Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, et al. Scaling inference time compute for diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 5
2025
-
[39]
Follow your pose: Pose- guided text-to-video generation using pose-free videos
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Siran Chen, Xiu Li, and Qifeng Chen. Follow your pose: Pose- guided text-to-video generation using pose-free videos. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 4117–4125, 2024. 2
2024
-
[40]
Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation
Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, et al. Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation. InSIGGRAPH Asia 2024 Conference Papers, 2024
2024
-
[41]
Controllable video generation: A survey.arXiv preprint arXiv:2507.16869, 2025
Yue Ma, Kunyu Feng, Zhongyuan Hu, Xinyu Wang, Yucheng Wang, Mingzhe Zheng, Xuanhua He, Chenyang Zhu, Hongyu Liu, Yingqing He, et al. Controllable video generation: A survey.arXiv preprint arXiv:2507.16869, 2025
-
[42]
Yue Ma, Kunyu Feng, Xinhua Zhang, Hongyu Liu, David Jun- hao Zhang, Jinbo Xing, Yinhan Zhang, Ayden Yang, Zeyu Wang, and Qifeng Chen. Follow-your-creation: Empow- ering 4d creation through video inpainting.arXiv preprint arXiv:2506.04590, 2025
-
[43]
Yue Ma, Yulong Liu, Qiyuan Zhu, Ayden Yang, Kunyu Feng, Xinhua Zhang, Zhifeng Li, Sirui Han, Chenyang Qi, and Qifeng Chen. Follow-your-motion: Video motion transfer via efficient spatial-temporal decoupled finetuning.arXiv preprint arXiv:2506.05207, 2025. 2
-
[44]
Hpsv3: Towards wide-spectrum human preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum human preference score. arXiv preprint arXiv:2508.03789, 2025. 5
-
[45]
Group editing: Edit multiple images in one go.arXiv preprint arXiv:2603.22883, 2026
Yue Ma, Xinyu Wang, Qianli Ma, Qinghe Wang, Mingzhe Zheng, Xiangpeng Yang, Hao Li, Chongbo Zhao, Jixuan Ying, Harry Yang, et al. Group editing: Edit multiple images in one go.arXiv preprint arXiv:2603.22883, 2026. 2
-
[46]
Fastvmt: Eliminating redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026
Yue Ma, Zhikai Wang, Tianhao Ren, Mingzhe Zheng, Hongyu Liu, Jiayi Guo, Mark Fong, Yuxuan Xue, Zixiang Zhao, Kon- rad Schindler, et al. Fastvmt: Eliminating redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026. 2
-
[47]
Hd-painter: high-resolution and prompt-faithful text-guided image inpainting with diffusion models
Hayk Manukyan, Andranik Sargsyan, Barsegh Atanyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Hd-painter: high-resolution and prompt-faithful text-guided image inpainting with diffusion models. InInternational Con- ference on Learning Representations, 2023. 1, 2, 10
2023
-
[48]
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The ef- fects of reward misspecification: Mapping and mitigating mis- aligned models.arXiv preprint arXiv:2201.03544, 2022. 1, 7
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
Qwen3-vl.https://qwen.ai/blog?id= qwen3-vl, 2025
QwenTeam. Qwen3-vl.https://qwen.ai/blog?id= qwen3-vl, 2025. Accessed: 2025-11-20. 11
2025
-
[50]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, 2021. 5
2021
-
[51]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 2023. 1, 3
2023
-
[52]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022. 2, 10
2022
-
[53]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, 2015. 1, 3
2015
-
[54]
Laion-5b: An open large-scale dataset for training next gen- eration image-text models.Advances in neural information processing systems, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next gen- eration image-text models.Advances in neural information processing systems, 2022. 5
2022
-
[55]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[56]
Yutao Shen, Junkun Yuan, Toru Aonishi, Hideki Nakayama, and Yue Ma. Follow-your-preference: Towards preference- aligned image inpainting.arXiv preprint arXiv:2509.23082,
-
[57]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, 2015. 3
2015
-
[58]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[59]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learn- ing: An introduction. MIT press Cambridge, 1998. 3
1998
-
[60]
Attention is all you need.Advances in neural information processing systems, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 2017. 1, 3
2017
-
[61]
Diffusion model align- ment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model align- ment using direct preference optimization. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024. 1, 3, 12
2024
-
[62]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 3 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Mod- eling and predicting single-cell multi-gene perturbation responses with scLAMBDA.bioRxiv, 2024a
Jiangshan Wang, Junfu Pu, Zhongang Qi, Jiayi Guo, Yue Ma, Nisha Huang, Yuxin Chen, Xiu Li, and Ying Shan. Tam- ing rectified flow for inversion and editing.arXiv preprint arXiv:2411.04746, 2024. 2
-
[64]
Junke Wang, Zhi Tian, Xun Wang, Xinyu Zhang, Weilin Huang, Zuxuan Wu, and Yu-Gang Jiang. Simplear: Pushing the frontier of autoregressive visual generation through pre- training, sft, and rl.arXiv preprint arXiv:2504.11455, 2025. 4
-
[65]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Imagen editor and editbench: Advancing and evaluating text-guided image in- painting
Su Wang, Chitwan Saharia, Ceslee Montgomery, Jordi Pont- Tuset, Shai Noy, Stefano Pellegrini, Yasumasa Onoe, Sarah Laszlo, David J Fleet, Radu Soricut, et al. Imagen editor and editbench: Advancing and evaluating text-guided image in- painting. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. 1, 5
2023
-
[67]
Towards enhanced image inpainting: Mit- igating unwanted object insertion and preserving color con- sistency
Yikai Wang, Chenjie Cao, Junqiu Yu, Ke Fan, Xiangyang Xue, and Yanwei Fu. Towards enhanced image inpainting: Mit- igating unwanted object insertion and preserving color con- sistency. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 2, 10
2025
-
[68]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025. 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Sihao Wu, Xiaonan Si, Chi Xing, Jianhong Wang, Gaojie Jin, Guangliang Cheng, Lijun Zhang, and Xiaowei Huang. Preference alignment on diffusion model: A comprehensive survey for image generation and editing.arXiv preprint arXiv:2502.07829, 2025. 1
-
[70]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Imagereward: Learn- ing and evaluating human preferences for text-to-image gen- eration.Advances in Neural Information Processing Systems,
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learn- ing and evaluating human preferences for text-to-image gen- eration.Advances in Neural Information Processing Systems,
-
[72]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual genera- tion.arXiv preprint arXiv:2505.07818, 2025. 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Label-efficient domain generalization via col- laborative exploration and generalization
Junkun Yuan, Xu Ma, Defang Chen, Kun Kuang, Fei Wu, and Lanfen Lin. Label-efficient domain generalization via col- laborative exploration and generalization. InProceedings of the 30th ACM international conference on multimedia, pages 2361–2370, 2022. 3
2022
-
[74]
Domain-specific bias filtering for single labeled domain generalization.International Journal of Computer Vi- sion, 131(2):552–571, 2023
Junkun Yuan, Xu Ma, Defang Chen, Kun Kuang, Fei Wu, and Lanfen Lin. Domain-specific bias filtering for single labeled domain generalization.International Journal of Computer Vi- sion, 131(2):552–571, 2023. 2
2023
-
[75]
Collaborative semantic aggregation and calibra- tion for federated domain generalization.IEEE Transactions on Knowledge and Data Engineering, 35(12):12528–12541,
Junkun Yuan, Xu Ma, Defang Chen, Fei Wu, Lanfen Lin, and Kun Kuang. Collaborative semantic aggregation and calibra- tion for federated domain generalization.IEEE Transactions on Knowledge and Data Engineering, 35(12):12528–12541,
-
[76]
Hap: Structure-aware masked image modeling for human-centric perception.Advances in Neural Informa- tion Processing Systems, 2023
Junkun Yuan, Xinyu Zhang, Hao Zhou, Jian Wang, Zhongwei Qiu, Zhiyin Shao, Shaofeng Zhang, Sifan Long, Kun Kuang, Kun Yao, et al. Hap: Structure-aware masked image modeling for human-centric perception.Advances in Neural Informa- tion Processing Systems, 2023. 2
2023
-
[77]
Magicbrush: A manually annotated dataset for instruction- guided image editing.Advances in Neural Information Pro- cessing Systems, 2023
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction- guided image editing.Advances in Neural Information Pro- cessing Systems, 2023. 1
2023
-
[78]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. 2, 10
2023
-
[79]
The unreasonable effectiveness of deep fea- tures as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep fea- tures as a perceptual metric. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018. 15
2018
-
[80]
A task is worth one word: Learning with task prompts for high-quality versatile image inpainting
Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, and Kai Chen. A task is worth one word: Learning with task prompts for high-quality versatile image inpainting. InEu- ropean Conference on Computer Vision, 2024. 1, 2, 10 19 Appendix A. More Results on Reward Model Bias Studies (a) A cartoon drawing of a kitchen. (b) A pink lotus flower blooming with gre...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.