Dream.exe: Can Video Generation Models Dream Executable Robot Manipulation?
Pith reviewed 2026-06-28 06:30 UTC · model grok-4.3
The pith
Video generation models can output motions that convert into executable robot manipulation trajectories in simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Generative priors from video models already encode enough physical knowledge that some generated manipulation sequences produce trajectories that succeed when executed in simulation, yet this capability is not captured by visual metrics alone.
What carries the argument
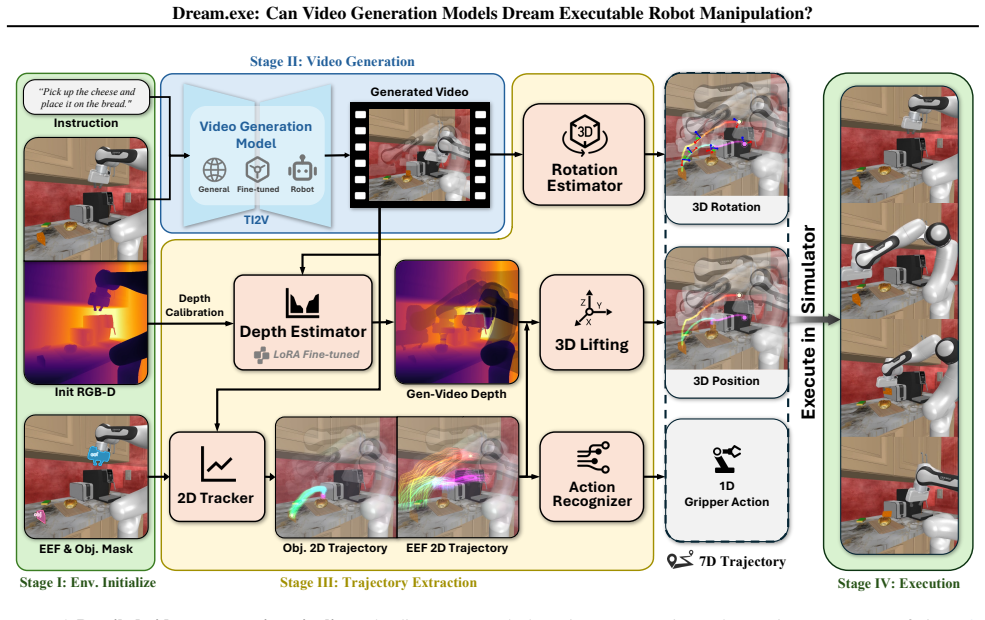
Dream.exe pipeline that converts model-generated video motion into robot trajectories and scores execution success inside a physics simulator.
If this is right
- Generative models trained on internet video capture actionable physical regularities beyond appearance.
- Execution success forms an independent axis of evaluation that visual metrics miss.
- Frontier closed-source and open-source generators can already support downstream robotic motion planning via their outputs.
- Robot-specific models do not show clear advantages over general video generators on physical executability.
Where Pith is reading between the lines
- The same pipeline could serve as a training signal to improve video models specifically for motion consistency.
- If simulator-to-reality transfer holds, video generation could become an intermediate step for zero-shot robot instruction following.
- Scaling video generation further might reduce reliance on explicit physics engines for simple manipulation tasks.
Load-bearing premise
The video-to-trajectory conversion step and the physics simulator together give a valid signal of the model's physical knowledge rather than pipeline artifacts.
What would settle it
All evaluated models producing near-zero execution success rates on the 101 tasks even when visual quality is high would show the models lack usable physical knowledge.
Figures

read the original abstract
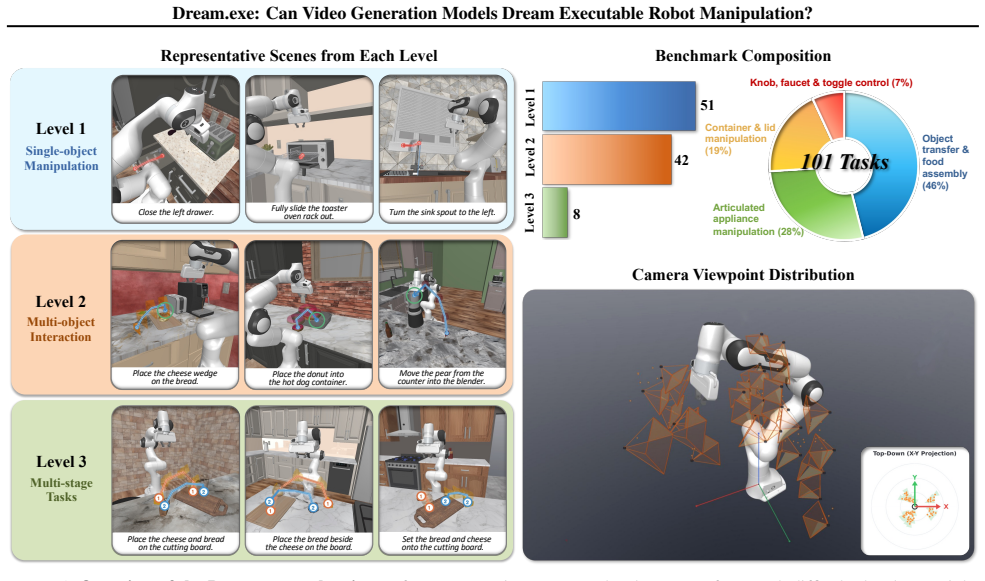
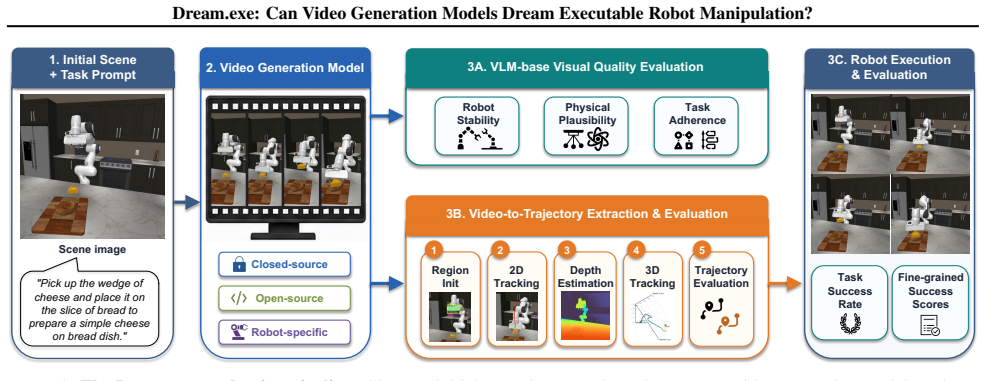
Video generation models have made impressive strides in synthesizing visually compelling content, yet their outputs remain confined to the virtual domain. A natural question follows: how well do these models reflect the physical world when their generated videos leave the screen and enter reality? We propose robotic manipulation as a concrete, measurable window onto this question: if a model has truly internalized physical laws, the motion it depicts should translate into executable robot behavior. We introduce Dream$.$exe, an evaluation framework that operationalizes this criterion through a video-to-execution pipeline. Given a scene image and a task description, Dream$.$exe synthesizes a manipulation video, converts the generated motion into robot trajectories, and executes them in a physics simulator, yielding a grounding signal that purely visual metrics cannot offer. Using this pipeline, we evaluate 8 models spanning frontier closed-source generators, open-source generators, and robot-specific models. Our benchmark covers 101 manually curated manipulation tasks at three levels of physical complexity, measured across visual quality, trajectory fidelity, and execution success. Encouragingly, several models achieve measurable execution success, suggesting that generative priors learned from internet-scale data already encode meaningful physical knowledge. Yet visual quality proves a poor predictor of executability, exposing a dimension of model capability that standard visual evaluations do not capture. Dream$.$exe will be open-sourced at https://github.com/showlab/Dream.exe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dream.exe, a framework to evaluate whether video generation models have internalized physical laws by synthesizing manipulation videos from scene images and task descriptions, converting the motion to robot trajectories via an unspecified pipeline, and executing them in a physics simulator. It benchmarks 8 models (frontier closed-source, open-source, and robot-specific) on 101 curated tasks at three complexity levels, reporting results on visual quality, trajectory fidelity, and execution success. The central claim is that measurable execution success in several models indicates meaningful physical knowledge in internet-scale generative priors, while visual quality is a poor predictor of executability.
Significance. If the pipeline is shown to provide a valid neutral grounding signal, the work supplies a concrete, executable test of physical understanding that standard visual metrics miss. The open-sourcing of the benchmark and code is a clear strength that enables reproducibility and follow-on work. The finding that visual quality decouples from executability is a useful negative result that could shift evaluation practices in video generation for robotics.
major comments (2)
- [Abstract, §3] Abstract and pipeline description (likely §3): the claim that execution success demonstrates model-internalized physical laws rests on the video-to-trajectory conversion acting as a neutral extractor. No details are supplied on keypoint detection, inverse kinematics, smoothing, collision resolution, or error handling, nor are there ablations or controls that would rule out the conversion step itself enforcing dynamics. This is load-bearing for the central claim.
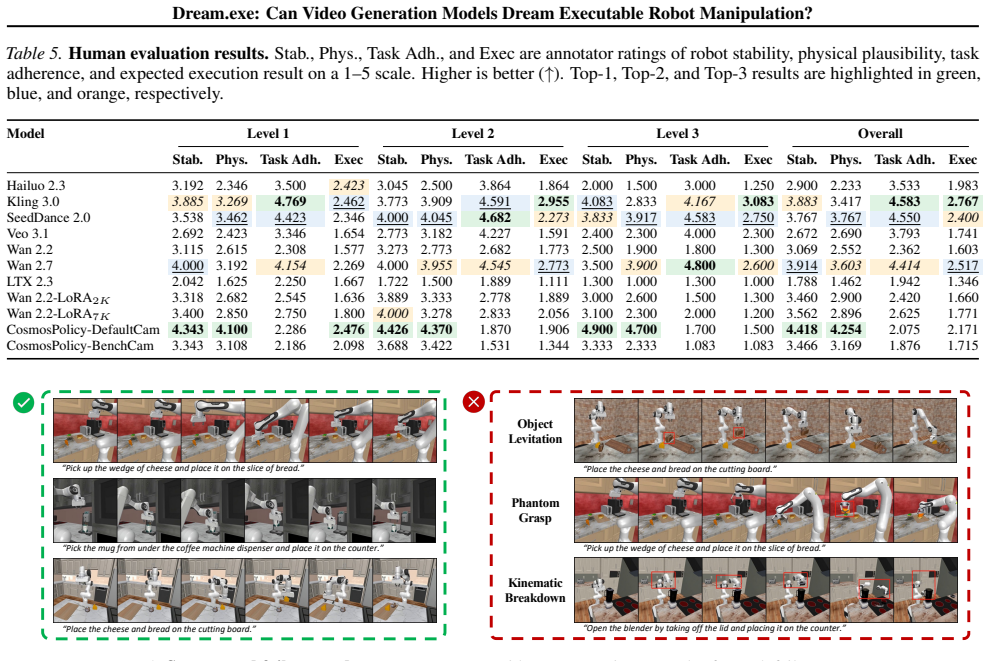
- [§4] Evaluation section (likely §4): success rates are reported without accompanying statistical tests, confidence intervals, or analysis of failure cases across the three complexity levels. Without these, it is unclear whether the measurable execution success is distinguishable from pipeline artifacts or simulator limitations.
minor comments (2)
- [Abstract] The abstract states that Dream.exe will be open-sourced but does not specify the exact release contents (e.g., whether the full conversion code and simulator configurations are included).
- [§4] Notation for the three complexity levels and the 101 tasks could be clarified with an explicit table or appendix listing task definitions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and pipeline description (likely §3): the claim that execution success demonstrates model-internalized physical laws rests on the video-to-trajectory conversion acting as a neutral extractor. No details are supplied on keypoint detection, inverse kinematics, smoothing, collision resolution, or error handling, nor are there ablations or controls that would rule out the conversion step itself enforcing dynamics. This is load-bearing for the central claim.
Authors: We agree that the pipeline must be shown to act as a neutral extractor for the central claim to hold. In the revised manuscript we will expand §3 with complete implementation details on keypoint detection, inverse kinematics, smoothing, collision resolution, and error handling. We will also add targeted ablations (e.g., feeding the pipeline physically implausible or random motion sequences) to demonstrate that the conversion step alone does not produce executable trajectories. These additions will directly address the load-bearing concern. revision: yes
-
Referee: [§4] Evaluation section (likely §4): success rates are reported without accompanying statistical tests, confidence intervals, or analysis of failure cases across the three complexity levels. Without these, it is unclear whether the measurable execution success is distinguishable from pipeline artifacts or simulator limitations.
Authors: We acknowledge that the current reporting lacks statistical rigor. In the revision we will augment §4 with appropriate statistical tests, confidence intervals on all success rates, and a systematic breakdown of failure modes by complexity level. This will allow readers to assess whether observed successes exceed what could be explained by pipeline or simulator artifacts. revision: yes
Circularity Check
No significant circularity in empirical evaluation pipeline
full rationale
The paper presents an empirical benchmark that generates videos, converts them to trajectories via an external pipeline, and measures success in an independent physics simulator. No equations, fitted parameters, or self-referential definitions are present. Execution success is not reduced to quantities defined inside the generative models; it is measured against external simulator outcomes on curated tasks. The central claim rests on this external grounding rather than any derivation that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The physics simulator serves as a valid proxy for real-world physical laws when measuring execution success on the chosen tasks.
Reference graph
Works this paper leans on
-
[1]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
2026 , url =
Alibaba Tongyi Lab , title =. 2026 , url =
2026
-
[3]
Kling-Omni Technical Report , author=. arXiv preprint arXiv:2512.16776 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
2026 , url =
Kuaishou , title =. 2026 , url =
2026
-
[5]
Seedance 2.0: Advancing Video Generation for World Complexity
Seedance 2.0: Advancing Video Generation for World Complexity , author=. arXiv preprint arXiv:2604.14148 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
LTX-Video: Realtime Video Latent Diffusion
LTX-Video: Realtime Video Latent Diffusion , author=. arXiv preprint arXiv:2501.00103 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2026 , url =
Lightricks , title =. 2026 , url =
2026
-
[8]
2025 , url=
Veo 3 Technical Report , author=. 2025 , url=
2025
-
[9]
2025 , howpublished =
Hailuo. 2025 , howpublished =
2025
-
[10]
2025 , url =
MiniMax , title =. 2025 , url =
2025
-
[11]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Cosmos policy: Fine-tuning video models for visuomotor control and planning , author=. arXiv preprint arXiv:2601.16163 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Advances in neural information processing systems , volume=
Video diffusion models , author=. Advances in neural information processing systems , volume=
-
[13]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Make-a-video: Text-to-video generation without text-video data , author=. arXiv preprint arXiv:2209.14792 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable video diffusion: Scaling latent video diffusion models to large datasets , author=. arXiv preprint arXiv:2311.15127 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The Thirteenth International Conference on Learning Representations , year =
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. The Thirteenth International Conference on Learning Representations , year =
-
[16]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Hunyuanvideo: A systematic framework for large video generative models , author=. arXiv preprint arXiv:2412.03603 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Movie Gen: A Cast of Media Foundation Models
Movie gen: A cast of media foundation models , author=. arXiv preprint arXiv:2410.13720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
OpenAI Blog , volume=
Video generation models as world simulators , author=. OpenAI Blog , volume=
-
[19]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Towards accurate generative models of video: A new metric & challenges , author=. arXiv preprint arXiv:1812.01717 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Evalcrafter: Benchmarking and evaluating large video generation models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vbench: Comprehensive benchmark suite for video generative models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
T2v-compbench: A comprehensive benchmark for compositional text-to-video generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[24]
arXiv preprint arXiv:2410.18072 , year=
Worldsimbench: Towards video generation models as world simulators , author=. arXiv preprint arXiv:2410.18072 , year=
-
[25]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Videophy: Evaluating physical commonsense for video generation , author=. arXiv preprint arXiv:2406.03520 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Towards world simulator: Crafting physical commonsense-based benchmark for video generation , author=. arXiv preprint arXiv:2410.05363 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
How Far is Video Generation from World Model: A Physical Law Perspective
How far is video generation from world model: A physical law perspective , author=. arXiv preprint arXiv:2411.02385 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Imagen Video: High Definition Video Generation with Diffusion Models
Imagen video: High definition video generation with diffusion models , author=. arXiv preprint arXiv:2210.02303 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Advances in neural information processing systems , volume=
Learning universal policies via text-guided video generation , author=. Advances in neural information processing systems , volume=
-
[30]
arXiv preprint arXiv:2602.08025 , year=
Mind: Benchmarking memory consistency and action control in world models , author=. arXiv preprint arXiv:2602.08025 , year=
-
[31]
World models , author=. arXiv preprint arXiv:1803.10122 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Zero-Shot Robotic Manipulation with Pretrained Image-Editing Diffusion Models
Zero-shot robotic manipulation with pretrained image-editing diffusion models , author=. arXiv preprint arXiv:2310.10639 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Unleashing large-scale video generative pre-training for visual robot manipulation , author=. arXiv preprint arXiv:2312.13139 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2406.16862 , year=
Dreamitate: Real-world visuomotor policy learning via video generation , author=. arXiv preprint arXiv:2406.16862 , year=
-
[35]
arXiv preprint arXiv:2512.24766 , year=
Dream2Flow: Bridging Video Generation and Open-World Manipulation with 3D Object Flow , author=. arXiv preprint arXiv:2512.24766 , year=
-
[36]
Video Generators are Robot Policies
Video generators are robot policies , author=. arXiv preprint arXiv:2508.00795 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
DreamGen: Unlocking Generalization in Robot Learning through Video World Models
Dreamgen: Unlocking generalization in robot learning through video world models , author=. arXiv preprint arXiv:2505.12705 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
World Action Models are Zero-shot Policies
World action models are zero-shot policies , author=. arXiv preprint arXiv:2602.15922 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2512.06963 , year=
Videovla: Video generators can be generalizable robot manipulators , author=. arXiv preprint arXiv:2512.06963 , year=
-
[40]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Video prediction policy: A generalist robot policy with predictive visual representations , author=. arXiv preprint arXiv:2412.14803 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
European conference on computer vision , pages=
Cotracker: It is better to track together , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[42]
European conference on computer vision , pages=
Grounding dino: Marrying dino with grounded pre-training for open-set object detection , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[43]
SAM 2: Segment Anything in Images and Videos
Sam 2: Segment anything in images and videos , author=. arXiv preprint arXiv:2408.00714 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Advances in Neural Information Processing Systems , volume=
Depth anything v2 , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Foundationpose: Unified 6d pose estimation and tracking of novel objects , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[46]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
robosuite: A modular simulation framework and benchmark for robot learning , author=. arXiv preprint arXiv:2009.12293 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[47]
arXiv preprint arXiv:2603.04356 , year=
Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots , author=. arXiv preprint arXiv:2603.04356 , year=
-
[48]
arXiv preprint arXiv:2603.12250 , year=
DVD: Deterministic Video Depth Estimation with Generative Priors , author=. arXiv preprint arXiv:2603.12250 , year=
-
[49]
arXiv preprint arXiv:2601.15282 , year=
Rethinking Video Generation Model for the Embodied World , author=. arXiv preprint arXiv:2601.15282 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.