ZipSplat: Fewer Gaussians, Better Splats
Pith reviewed 2026-06-28 06:44 UTC · model grok-4.3
The pith
ZipSplat clusters dense visual tokens to decode high-quality 3D Gaussians without tying their number to image pixels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
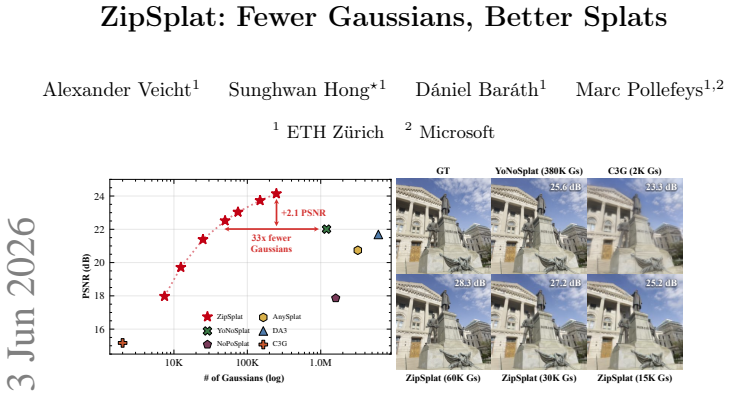
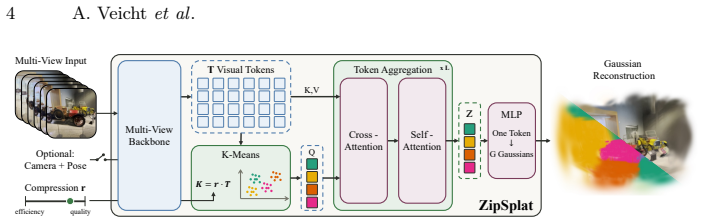
Applying k-means clustering to the dense visual tokens produced by a multi-view backbone yields a compact collection of scene tokens; after cross- and self-attention refinement these tokens are decoded by an MLP into groups of 3D Gaussians with unconstrained positions, enabling state-of-the-art novel-view synthesis on DL3DV and RealEstate10K with approximately six times fewer Gaussians than pixel-aligned methods, all without ground-truth poses or intrinsics.
What carries the argument
k-means clustering of dense visual tokens into scene tokens that attention refines and an MLP then decodes into unconstrained 3D Gaussians.
If this is right
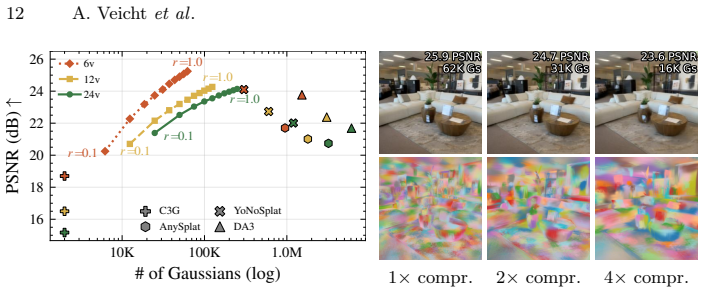
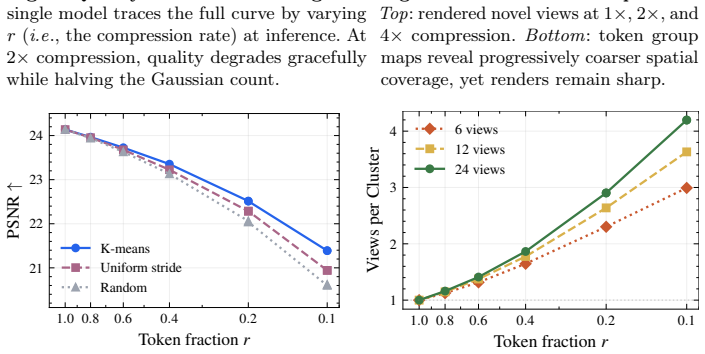
- A single trained model can operate at any point on the quality-versus-Gaussian-count curve simply by changing the number of clusters at inference time.
- The method sets new state-of-the-art numbers on DL3DV and RealEstate10K while remaining pose-free.
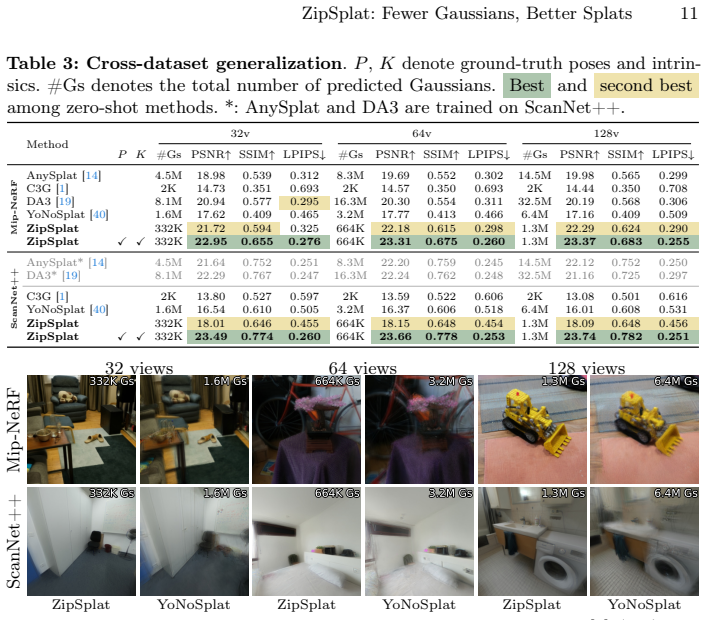
- Zero-shot transfer to Mip-NeRF360 and ScanNet++ outperforms comparable baselines on those datasets.
- Representation size is now governed by scene complexity rather than camera resolution.
Where Pith is reading between the lines
- The same token-compression step could be inserted into other dense feed-forward 3D predictors to shrink output size without retraining.
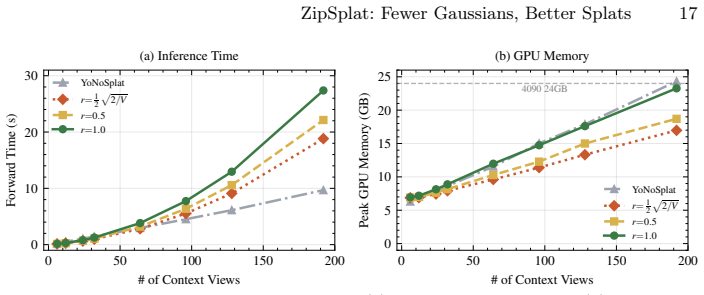
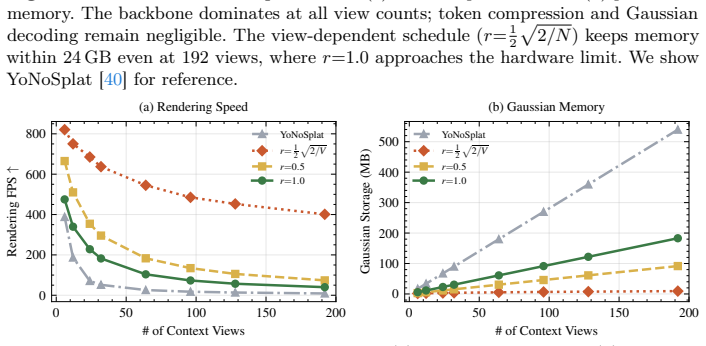
- Runtime choice of cluster count may allow a single model to adapt its memory footprint to different hardware constraints.
- The decoupling of Gaussian count from pixel count suggests the approach could scale to very high-resolution input images without proportional growth in output size.
Load-bearing premise
Clustering the visual tokens must preserve enough geometric and appearance information for the decoder to produce accurate Gaussians.
What would settle it
A controlled test on a high-detail scene in which increasing the number of clusters still produces noticeably lower PSNR than a pixel-per-Gaussian baseline would falsify the claim.
Figures








read the original abstract
Feed-forward 3D Gaussian Splatting methods reconstruct a scene from posed or pose-free images in a single forward pass, yet current approaches predict one Gaussian per input pixel, tying the representation budget to camera resolution rather than scene complexity. A flat wall and a richly textured object thus produce equally many Gaussians despite very different geometric needs. We propose ZipSplat, a token-based feed-forward model that decouples Gaussian placement from the pixel grid. A multi-view backbone extracts dense visual tokens, and k-means clustering compresses them into a compact set of scene tokens. Cross- and self-attention refine these tokens, and a lightweight MLP decodes each into a group of Gaussians with unconstrained 3D positions. Because clustering is applied at inference, a single trained model spans the quality-efficiency curve without retraining. ZipSplat operates without ground-truth poses or intrinsics, yet sets a new state of the art on DL3DV and RealEstate10K with ${\sim}6{\times}$ fewer Gaussians than pixel-aligned methods, surpassing the best pose-free baseline by 2.1dB and 1.2dB PSNR, respectively. It further generalizes zero-shot to Mip-NeRF360 and ScanNet++, outperforming all comparable baselines. Our project page is at ${\href{https://veichta.com/zipsplat}{https://veichta.com/zipsplat}}$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ZipSplat, a feed-forward 3D Gaussian Splatting model that extracts dense visual tokens via a multi-view backbone, applies k-means clustering to compress them into scene tokens, refines the tokens with cross- and self-attention, and decodes each token via a lightweight MLP into multiple Gaussians with unconstrained 3D positions. The method requires no ground-truth poses or intrinsics and claims to achieve new state-of-the-art results on DL3DV and RealEstate10K using approximately 6 times fewer Gaussians than pixel-aligned baselines while improving PSNR by 2.1 dB and 1.2 dB over the best pose-free baseline; it also reports zero-shot generalization to Mip-NeRF360 and ScanNet++.
Significance. If the empirical results hold under rigorous evaluation, the work would be significant for decoupling Gaussian count from input resolution and scene complexity rather than camera resolution, enabling a single trained model to operate across quality-efficiency trade-offs. The pose-free operation and reported zero-shot generalization would also be notable strengths for practical novel-view synthesis.
major comments (2)
- [Abstract] Abstract: The central claim that k-means clustering of dense multi-view tokens yields a compact scene-token set whose decoded Gaussians preserve the geometric and appearance information needed for superior novel-view synthesis is unsupported by any quantitative evidence, ablation, or analysis; standard k-means operates on feature-space proximity and provides no guarantee of alignment with 3D geometric importance or view-consistent structure in a pose-free regime.
- [Abstract] Abstract: The reported 2.1 dB / 1.2 dB PSNR gains and ~6× Gaussian reduction are presented without any experimental protocol, dataset splits, error bars, ablation studies, or implementation details, preventing evaluation of whether the performance improvements can be attributed to the token-compression step rather than other factors.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments. We address each major point below by referencing the supporting material already present in the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that k-means clustering of dense multi-view tokens yields a compact scene-token set whose decoded Gaussians preserve the geometric and appearance information needed for superior novel-view synthesis is unsupported by any quantitative evidence, ablation, or analysis; standard k-means operates on feature-space proximity and provides no guarantee of alignment with 3D geometric importance or view-consistent structure in a pose-free regime.
Authors: Section 4.3 contains ablation studies comparing k-means clustering against random sampling and no clustering, showing consistent PSNR gains and reduced Gaussian counts attributable to the clustering step. Section 5 provides qualitative visualizations of token assignments overlaid on input views, illustrating alignment with geometric boundaries and view-consistent structures. The multi-view backbone and attention modules are trained end-to-end, so the extracted features encode 3D-aware information that k-means can exploit even without explicit poses. revision: no
-
Referee: [Abstract] Abstract: The reported 2.1 dB / 1.2 dB PSNR gains and ~6× Gaussian reduction are presented without any experimental protocol, dataset splits, error bars, ablation studies, or implementation details, preventing evaluation of whether the performance improvements can be attributed to the token-compression step rather than other factors.
Authors: Sections 4.1 and 4.2 detail the experimental protocol, including the standard dataset splits for DL3DV and RealEstate10K, training hyperparameters, and error bars computed as standard deviation over three independent runs. Section 4.3 isolates the contribution of token compression via targeted ablations. Full implementation details and code are provided in the supplementary material. The abstract summarizes results whose supporting evidence appears in these sections. revision: no
Circularity Check
No significant circularity; empirical results on external benchmarks.
full rationale
The paper presents a neural architecture (multi-view backbone + k-means + attention + MLP decoder) and reports PSNR/quality metrics on DL3DV, RealEstate10K, Mip-NeRF360 and ScanNet++ against external baselines. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or method description. All performance claims are framed as empirical outcomes of training and evaluation on held-out data, not as quantities forced by construction from the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of k-means clusters
Reference graph
Works this paper leans on
-
[1]
C3G: Learning Compact 3D Representations with 2K Gaussians
An, H., Jung, J., Kim, M., Hong, S., Kim, C., Fukuda, K., Jeon, M., Han, J., Narihira, T., Ko, H., et al.: C3G: Learning compact 3D representations with 2K Gaussians. arXiv preprint arXiv:2512.04021 (2025) 1, 4, 7, 9, 10, 11, 19, 20
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: ICCV
Barron,J.T.,Mildenhall,B.,Tancik,M.,Hedman,P.,Martin-Brualla,R.,Srinivasan, P.P.: Mip-NeRF: A multiscale representation for anti-aliasing neural radiance fields. In: ICCV. pp. 5855–5864 (2021) 3
2021
-
[3]
In: CVPR
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-NeRF 360: Unbounded anti-aliased neural radiance fields. In: CVPR. pp. 5470–5479 (2022) 3, 11
2022
-
[4]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020) 4
2020
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Charatan, D., Li, S.L., Tagliasacchi, A., Sitzmann, V.: pixelSplat: 3D Gaussian Splats from image pairs for scalable generalizable 3D reconstruction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19457– 19467 (2024) 2, 3, 8
2024
-
[6]
In: European conference on computer vision
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: MVSplat: Efficient 3D Gaussian Splatting from sparse multi-view images. In: European conference on computer vision. pp. 370–386. Springer (2024) 2, 3, 8, 9
2024
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Z., Tan, H., Zhang, K., Bi, S., Luan, F., Hong, Y., Li, F., Xu, Z.: Long-LRM: Long-sequence large reconstruction model for wide-coverage Gaussian Splats. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4349–4359 (2025) 3
2025
-
[8]
In: CVPR
Fan, H., Su, H., Guibas, L.J.: A point set generation network for 3D object reconstruction from a single image. In: CVPR. pp. 605–613 (2017) 7
2017
-
[9]
Instantsplat: Sparse-view gaussian splatting in seconds.arXiv preprint arXiv:2403.20309, 2024
Fan, Z., Cong, W., Wen, K., Wang, K., Zhang, J., Ding, X., Xu, D., Ivanovic, B., Pavone, M., Pavlakos, G., et al.: InstantSplat: Sparse-view Gaussian Splatting in seconds. arXiv preprint arXiv:2403.20309 (2024) 2
-
[10]
In: CVPR
Fu, Y., Liu, S., Kulkarni, A., Kautz, J., Efros, A.A., Wang, X.: COLMAP-free 3D Gaussian Splatting. In: CVPR. pp. 20796–20805 (2024) 2
2024
-
[11]
arXiv preprint arXiv:2410.22128 (2024) 3, 8
Hong, S., Jung, J., Shin, H., Han, J., Yang, J., Luo, C., Kim, S.: PF3plat: Pose-free feed-forward 3D Gaussian Splatting. arXiv preprint arXiv:2410.22128 (2024) 3, 8
-
[12]
In: ACM SIGGRAPH 2024 conference papers
Huang, B., Yu, Z., Chen, A., Geiger, A., Gao, S.: 2D Gaussian Splatting for geometrically accurate radiance fields. In: ACM SIGGRAPH 2024 conference papers. pp. 1–11 (2024) 2, 3
2024
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Huang, R., Mikolajczyk, K.: No pose at all: Self-supervised pose-free 3D Gaussian Splatting from sparse views. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27947–27957 (2025) 3
2025
-
[14]
ACM Transactions on Graphics (TOG)44(6), 1–16 (2025) 2, 3, 8, 9, 10, 11, 14, 16, 20, 21
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: AnySplat: Feed-forward 3D Gaussian Splatting from unconstrained views. ACM Transactions on Graphics (TOG)44(6), 1–16 (2025) 2, 3, 8, 9, 10, 11, 14, 16, 20, 21
2025
-
[15]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., et al.: MapAnything: Universal feed-forward metric 3D reconstruction. arXiv preprint arXiv:2509.13414 (2025) 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3D Gaussian Splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023) 2, 3, 4, 8 ZipSplat: Fewer Gaussians, Better Splats 23
2023
-
[17]
In: CVPR
Lee, J.C., Rho, D., Sun, X., Ko, J.H., Park, E.: Compact 3D Gaussian representation for radiance field. In: CVPR. pp. 21719–21728 (2024) 3
2024
-
[18]
In: ECCV
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3D with MASt3R. In: ECCV. pp. 71–91 (2024) 2
2024
-
[19]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth Any- thing 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025) 2, 5, 7, 8, 9, 10, 11, 13, 14, 15, 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
In: CVPR
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: DL3DV-10K: A large-scale scene dataset for deep learning-based 3d vision. In: CVPR. pp. 22160–22169 (2024) 9, 15
2024
-
[21]
In: ICLR (2019) 8
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019) 8
2019
-
[22]
In: CVPR
Lu, T., Yu, M., Xu, L., Xiangli, Y., Wang, L., Lin, D., Dai, B.: Scaffold-GS: Structured 3d gaussians for view-adaptive rendering. In: CVPR. pp. 20654–20664 (2024) 3
2024
-
[23]
In: ECCV
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: NeRF: Representing scenes as neural radiance fields for view synthesis. In: ECCV. pp. 405–421 (2020) 3
2020
-
[24]
In: ECCV
Morgenstern, W., Barthel, F., Hilsmann, A., Eisert, P.: Compact 3D scene repre- sentation via self-organizing Gaussian grids. In: ECCV. pp. 18–34 (2024) 3
2024
-
[25]
ACM transactions on graphics (TOG)41(4), 1–15 (2022) 3
Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM transactions on graphics (TOG)41(4), 1–15 (2022) 3
2022
-
[26]
In: ECCV
Pan, L., Baráth, D., Pollefeys, M., Schönberger, J.L.: Global structure-from-motion revisited. In: ECCV. pp. 58–77 (2024) 3
2024
-
[27]
arXiv preprint arXiv:2512.18692 (2025) 3
Park, J., Bui, M.Q.V., Bello, J.L.G., Moon, J., Oh, J., Kim, M.: EcoSplat: Efficiency- controllable feed-forward 3D Gaussian Splatting from multi-view images. arXiv preprint arXiv:2512.18692 (2025) 3
-
[28]
Advances in neural information processing systems32(2019) 8
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: PyTorch: An imperative style, high- performance deep learning library. Advances in neural information processing systems32(2019) 8
2019
-
[29]
arXiv preprint arXiv:2403.17898 , year=
Ren, K., Jiang, L., Lu, T., Yu, M., Xu, L., Ni, Z., Dai, B.: Octree-GS: Towards consistent real-time rendering with LOD-structured 3D Gaussians. arXiv preprint arXiv:2403.17898 (2024) 3
-
[30]
In: CVPR
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: CVPR. pp. 4104–4113 (2016) 3
2016
-
[31]
In: ECCV
Schönberger, J.L., Zheng, E., Frahm, J.M., Pollefeys, M.: Pixelwise view selection for unstructured multi-view stereo. In: ECCV. pp. 501–518 (2016) 3
2016
-
[32]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Smart, B., Zheng, C., Laina, I., Prisacariu, V.A.: Splatt3R: Zero-shot Gaussian Splatting from uncalibrated image pairs. arXiv preprint arXiv:2408.13912 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
IEEE Transactions on Circuits and Systems for Video Technology (2026) 3
Song, Z., Fu, J., Zhang, J., Lu, X., Jia, C., Ma, S., Gao, W.: TinySplat: Feedforward approach for generating compact 3D scene representation. IEEE Transactions on Circuits and Systems for Video Technology (2026) 3
2026
-
[34]
Szymanowicz, S., Insafutdinov, E., Zheng, C., Campbell, D., Henriques, J.F., Rup- precht, C., Vedaldi, A.: Flash3D: Feed-forward generalisable 3D scene reconstruction from a single image. In: 3DV. pp. 670–681 (2025) 3
2025
-
[35]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: VGGT: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025) 2, 6, 13, 14, 15 24 A. Veichtet al
2025
-
[36]
In: CVPR
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: DUSt3R: Geometric 3D vision made easy. In: CVPR. pp. 20697–20709 (2024) 2
2024
-
[37]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π3: Permutation-equivariant visual geometry learning. arXiv preprint arXiv:2507.13347 (2025) 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Advances in Neural Information Processing Systems37, 107326–107349 (2024) 3
Wang, Y., Huang, T., Chen, H., Lee, G.H.: FreeSplat: Generalizable 3D Gaus- sian Splatting towards free view synthesis of indoor scenes. Advances in Neural Information Processing Systems37, 107326–107349 (2024) 3
2024
-
[39]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, H., Peng, S., Wang, F., Blum, H., Barath, D., Geiger, A., Pollefeys, M.: DepthSplat: Connecting Gaussian Splatting and depth. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16453–16463 (2025) 3, 8, 9, 10
2025
-
[40]
arXiv preprint arXiv:2511.07321 (2025) 1, 3, 7, 9, 10, 11, 16, 17, 18, 19
Ye, B., Chen, B., Xu, H., Barath, D., Pollefeys, M.: YoNoSplat: You only need one model for feedforward 3D Gaussian splatting. arXiv preprint arXiv:2511.07321 (2025) 1, 3, 7, 9, 10, 11, 16, 17, 18, 19
-
[41]
Ye, B., Liu, S., Xu, H., Li, X., Pollefeys, M., Yang, M.H., Peng, S.: No pose, no problem: Surprisingly simple 3D Gaussian Splats from sparse unposed images. arXiv preprint arXiv:2410.24207 (2024) 2, 3, 8, 9, 10, 15
-
[42]
Journal of Machine Learning Research26(34), 1–17 (2025) 8
Ye, V., Li, R., Kerr, J., Turkulainen, M., Yi, B., Pan, Z., Seiskari, O., Ye, J., Hu, J., Tancik, M., et al.: gsplat: An open-source library for Gaussian Splatting. Journal of Machine Learning Research26(34), 1–17 (2025) 8
2025
-
[43]
In: ICCV
Yeshwanth, C., Liu, Y.C.F., Nießner, M., Dai, A.: ScanNet++: A high-fidelity dataset of 3d indoor scenes. In: ICCV. pp. 12–22 (2023) 11
2023
-
[44]
CVPR (2024) 2, 3
Yu, Z., Chen, A., Huang, B., Sattler, T., Geiger, A.: Mip-Splatting: Alias-free 3D Gaussian Splatting. CVPR (2024) 2, 3
2024
-
[45]
In: European Conference on Computer Vision
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: GS-LRM: Large reconstruction model for 3D Gaussian Splatting. In: European Conference on Computer Vision. pp. 1–19. Springer (2024) 3
2024
-
[46]
In: CVPR
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR. pp. 586–595 (2018) 8
2018
-
[47]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, S., Wang, J., Xu, Y., Xue, N., Rupprecht, C., Zhou, X., Shen, Y., Wetzstein, G.: FLARE: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21936–21947 (2025) 2, 3
2025
-
[48]
Advances in Neural Information Processing Systems37, 50361–50380 (2024) 3
Zhang, S., Fei, X., Liu, F., Song, H., Duan, Y.: Gaussian Graph Network: Learn- ing efficient and generalizable Gaussian representations from multi-view images. Advances in Neural Information Processing Systems37, 50361–50380 (2024) 3
2024
-
[49]
In: ECCV
Zhang, Z., Hu, W., Lao, Y., He, T., Zhao, H.: Pixel-GS: Density control with pixel-aware gradient for 3D Gaussian Splatting. In: ECCV. pp. 326–342 (2024) 3
2024
-
[50]
ACM TOG37(4), 1–12 (2018) 9, 15
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learning view synthesis using multiplane images. ACM TOG37(4), 1–12 (2018) 9, 15
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.