RhinoVLA Technical Report
Pith reviewed 2026-07-01 07:11 UTC · model grok-4.3
The pith
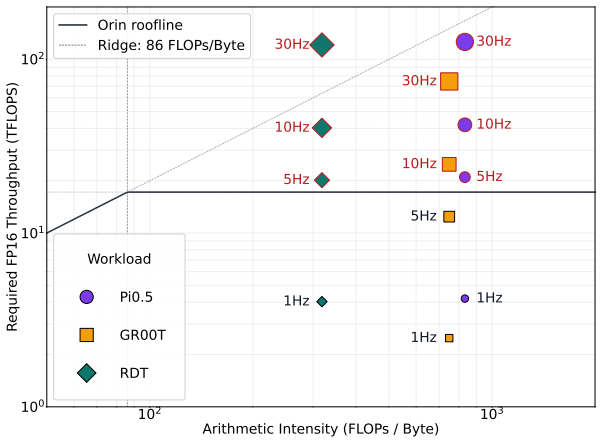
RhinoVLA achieves 11.69 Hz end-to-end inference on edge hardware while matching prior model performance at similar scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
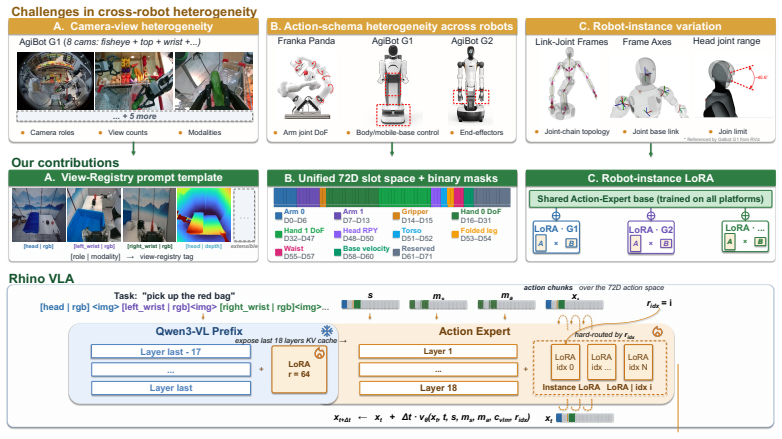
The model adopts a token-efficient vision-language backbone and a continuous action expert to reduce the vision-language-model-side token and computation burden while preserving pretrained multimodal capability. It further introduces a unified interface that combines view registry, a 72-dimensional physical state-action slot space, and robot-instance adapters, allowing heterogeneous robot observations and action schemas to be aligned under a shared policy. On the target edge system-on-chip, hardware-aware compilation, mixed-precision execution, and parallel visual encoding produce 11.69 Hz end-to-end inference and downstream performance comparable to a prior model at similar parameter scale.
What carries the argument
Token-efficient vision-language backbone paired with continuous action expert, which together cut input-token volume and associated GEMM computation while retaining pretrained multimodal capability.
If this is right
- Real-time closed-loop robotic control at or above 10 Hz becomes possible on edge hardware.
- A single policy can be trained across multiple robots with different sensors and action spaces.
- Multimodal pretraining value is retained without extra fine-tuning steps.
- Hardware-specific optimizations such as mixed precision and parallel encoding are sufficient to reach the required speed.
Where Pith is reading between the lines
- Token-reduction techniques may transfer to other multimodal models that currently face similar latency walls on edge devices.
- The 72-dimensional state-action slot space could serve as a starting point for standardizing interfaces across additional robot embodiments.
- Meeting the 10 Hz threshold on one edge platform suggests similar compilation and precision choices could be tested on other low-power chips.
Load-bearing premise
The token-efficient vision-language backbone and continuous action expert preserve enough of the pretrained multimodal capability that downstream robotic task performance remains comparable without additional fine-tuning or capability loss.
What would settle it
Task success rates on standard robotic manipulation benchmarks falling substantially below those of the prior model, or measured end-to-end inference on the target edge hardware dropping below 10 Hz, would falsify the central claim.
Figures



read the original abstract
Vision-Language-Action (VLA) models have shown strong potential for robotic manipulation, but real-time deployment on edge hardware remains challenging. In this work, we identify VLM visual and context tokens as a major source of deployment latency: for GEMM-dominated projection operators, computation grows linearly with the number of input tokens when model dimensions are fixed. Motivated by this observation, we propose RhinoVLA, a deployment-oriented VLA model co-designed with the Huixi R1 edge SoC. RhinoVLA adopts a token-efficient Qwen3-VL backbone and a continuous Action Expert, reducing the VLM-side token and computation burden while preserving pretrained multimodal capability. To support cross-robot learning, RhinoVLA further introduces a unified interface that combines View Registry, 72D physical state-action slot space, and robotinstance LoRA, allowing heterogeneous robot observations and action schemas to be aligned under a shared policy. On the deployment side, RhinoVLA is optimized through hardware-aware compilation, mixed-precision execution, and parallel visual encoding. Experiments show that RhinoVLA achieves downstream performance comparable to {\pi}0.5 at a similar parameter scale, while reaching 11.69 Hz end-to-end inference on Huixi R1, meeting the 10 Hz real-time closedloop control target. The project will be open-sourced at https://github.com/HuixiAI/RhinoVLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RhinoVLA, a deployment-oriented vision-language-action model co-designed with the Huixi R1 edge SoC. It adopts a token-efficient Qwen3-VL backbone and continuous Action Expert to reduce VLM token and computation burden while preserving pretrained multimodal capability. A unified interface combining View Registry, 72D physical state-action slot space, and robot-instance LoRA enables cross-robot learning from heterogeneous observations and action schemas. Hardware optimizations include hardware-aware compilation, mixed-precision execution, and parallel visual encoding. Experiments claim downstream performance comparable to π0.5 at similar parameter scale and 11.69 Hz end-to-end inference on Huixi R1, meeting the 10 Hz real-time closed-loop control target. The project is planned for open-sourcing.
Significance. If the empirical claims hold, the work makes a practical engineering contribution to real-time VLA deployment on edge hardware and cross-robot policy unification, addressing key bottlenecks for robotic applications. The hardware co-design, token reduction strategy, and open-source commitment are strengths that could aid reproducibility and adoption in the robotics community.
major comments (1)
- [Abstract] Abstract: The central claim that RhinoVLA achieves 'downstream performance comparable to π0.5 at a similar parameter scale' is presented without benchmark details, task descriptions, success metrics, additional baselines beyond π0.5, error bars, or dataset information. This omission renders the key empirical assertion unverifiable and load-bearing for the paper's contribution.
minor comments (2)
- The abstract contains a LaTeX rendering artifact '{\pi}0.5' that should be corrected to π0.5.
- The abstract uses 'closedloop' which should be 'closed-loop' for standard terminology.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comment on the abstract is well-taken and points to a genuine presentation issue. We address it directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that RhinoVLA achieves 'downstream performance comparable to π0.5 at a similar parameter scale' is presented without benchmark details, task descriptions, success metrics, additional baselines beyond π0.5, error bars, or dataset information. This omission renders the key empirical assertion unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the abstract presents the performance claim in a summary form that lacks the supporting details needed for immediate verification. The Experiments section of the full manuscript provides the benchmark details, task descriptions, success metrics, dataset information, and the direct comparison to π0.5 at comparable parameter scale. To resolve the issue, we will revise the abstract to include concise references to the evaluation setup (e.g., the manipulation tasks, primary success-rate metric, and parameter-scale context) while directing readers to the Experiments section for full information. We will also confirm that error bars are reported and consider whether an additional baseline can be added without altering the core claims. These changes will appear in the revised version. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a technical report on an engineering deployment of a VLA model. All central claims (inference speed of 11.69 Hz, performance comparable to π0.5) are presented as direct empirical measurements from experiments on Huixi R1 hardware. No mathematical derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear. The token reduction, continuous Action Expert, and LoRA interface are described as design choices whose validity rests on measured outcomes, not on any self-referential reduction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, Andre Susano Pinto, Alexander Kolesnikov, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castaneda, Nikita Cherniadev, Xingye Da, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xu Huang, Shu Jiang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Junhao Cai, Zetao Cai, Jiafei Cao, Yilun Chen, Zeyu He, Lei Jiang, Hang Li, Hengjie Li, Yang Li, Yufei Liu, et al. Internvla-a1: Unifying understanding, generation and action for robotic manipulation.arXiv preprint arXiv:2601.02456, 2026
-
[8]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, Deli Zhao, and Hao Chen. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
PaLI-X: On Scaling up a Multilingual Vision and Language Model
Xi Chen, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, Sebastian Goodman, Xiao Wang, Yi Tay, et al. Pali-x: On scaling up a multilingual vision and language model.arXiv preprint arXiv:2305.18565, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10–11), 2025
2025
-
[11]
Agibot world colosseum
AgiBot World Colosseum contributors. Agibot world colosseum. https://github.com/ OpenDriveLab/AgiBot-World, 2024
2024
-
[12]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
2022
-
[13]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, et al
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, et al. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022
2022
-
[15]
NORA: A Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks
Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U-Xuan Tan, Navonil Majumder, and Soujanya Poria. Nora: A small open-sourced generalist vision language action model for embodied tasks.arXiv preprint arXiv:2504.19854, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Bc-z: Zero-shot task generalization with robotic imitation learning
Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, et al. Bc-z: Zero-shot task generalization with robotic imitation learning. InProceedings of the 5th Conference on Robot Learning, volume 164 ofProceedings of Machine Learning Research, pages 991–1002. PMLR, 2022
2022
-
[17]
Openvla: An open-source vision- language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, et al. Openvla: An open-source vision- language-action model. InProceedings of The 8th Conference on Robot Learning, Proceedings of Machine Learning Research, 2025
2025
-
[18]
arXiv preprint arXiv:2501.14818 , year=
Zhiqi Li, Guo Chen, Shilong Liu, Shihao Wang, Vibashan VS, Yishen Ji, Shiyi Lan, Hao Zhang, Yilin Zhao, Subhashree Radhakrishnan, et al. Eagle 2: Building post-training data strategies from scratch for frontier vision-language models.arXiv preprint arXiv:2501.14818, 2025
-
[19]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.arXiv preprint arXiv:2304.08485, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, et al. Rdt-1b: A diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Jianlan Luo et al. Precise and dexterous robotic manipulation via human-in-the-loop reinforce- ment learning.arXiv preprint arXiv:2410.21845, 2024. 20
-
[22]
GeForce RTX 4090: Graphics cards for gaming
NVIDIA. GeForce RTX 4090: Graphics cards for gaming. Official product specification page,
-
[23]
Accessed: 2026-06-02
2026
-
[24]
Nvidia jetson agx orin series technical brief
NVIDIA. Nvidia jetson agx orin series technical brief. Technical brief, 2022
2022
-
[25]
GeForce RTX 5090: Graphics cards for gamers and creators
NVIDIA. GeForce RTX 5090: Graphics cards for gamers and creators. Official product specification page, 2025. Accessed: 2026-06-02
2025
-
[26]
Nvidia jetson thor series modules data sheet
NVIDIA Corporation. Nvidia jetson thor series modules data sheet. Official Datasheet, 2025. Accessed: 2026-06-02
2025
-
[27]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yun- liang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InRobotics: Science and Systems, 2024
2024
-
[28]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Abby O’Neill, Abdul Rehman, Abhishek Gupta, Abhiram Maddukuri, et al. Open x- embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[31]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
π0.5: A vision-language-action model with open-world generalization
Physical Intelligence. π0.5: A vision-language-action model with open-world generalization. Technical report, 2025
2025
-
[33]
Spatialvla: Exploring spatial representations for visual-language-action model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, Jiayuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. Spatialvla: Exploring spatial representations for visual-language-action model. InRobotics: Science and Systems, 2025
2025
-
[34]
Qwen Team. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, et al. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 8748–8763. PMLR, 2021
2021
-
[36]
Multimodal diffusion transformer: Learning versatile behavior from multimodal goals
Moritz Reuss, Ömer Erdinç Ya ˘gmurlu, Fabian Wenzel, and Rudolf Lioutikov. Multimodal diffusion transformer: Learning versatile behavior from multimodal goals. InRobotics: Science and Systems, 2024
2024
-
[37]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Cadene. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Agibot world 2026
AgiBot World Team. Agibot world 2026. https://huggingface.co/datasets/ agibot-world/AgiBotWorld2026, 2026
2026
-
[39]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 21
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
A Pragmatic VLA Foundation Model
Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Qian Zhu, He Sun, Yong Wang, Shuailei Ma, et al. A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[44]
Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
Biao Zhang and Rico Sennrich. Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
2019
-
[45]
Cot-vla: Visual chain-of-thought reasoning for vision-language- action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Ming-Yu Liu, Donglai Xiang, Gordon Wetzstein, and Tsung-Yi Lin. Cot-vla: Visual chain-of-thought reasoning for vision-language- action models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogn...
2025
-
[46]
Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InInternational Conference on Learning Representa- tions, 2025
2025
-
[47]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 2165–2183. PMLR, 2023. 22
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.