SIMPLE: Simulation-Based Policy Learning and Evaluation for Humanoid Loco-manipulation
Pith reviewed 2026-06-27 19:27 UTC · model grok-4.3
The pith
A new simulation testbed couples accurate physics with photorealistic rendering to let humanoid loco-manipulation policies transfer zero-shot to physical robots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
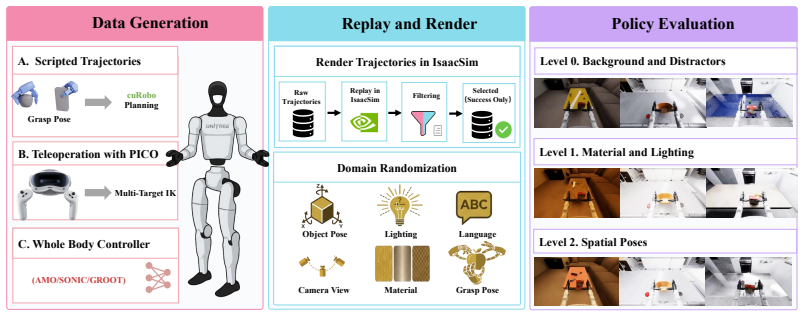
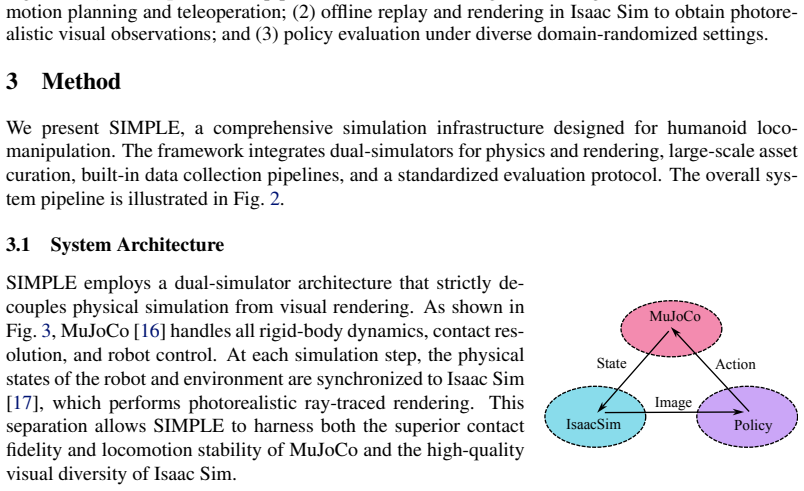
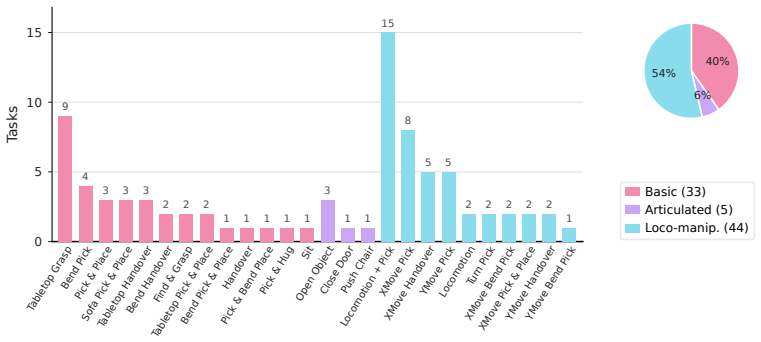
SIMPLE couples accurate contact-rich dynamics with photorealistic rendering to create a large-scale testbed of 60 diverse whole-body tasks across 50 indoor scenes and more than 1,000 object assets. Data generation via motion planning and low-latency VR teleoperation supports scalable collection, and experiments with imitation networks, vision-language-action models, and world action models establish a strong correlation between policy performance in simulation and the real world. Policies trained on data collected in SIMPLE transfer zero-shot to physical humanoid robots under similar settings.
What carries the argument
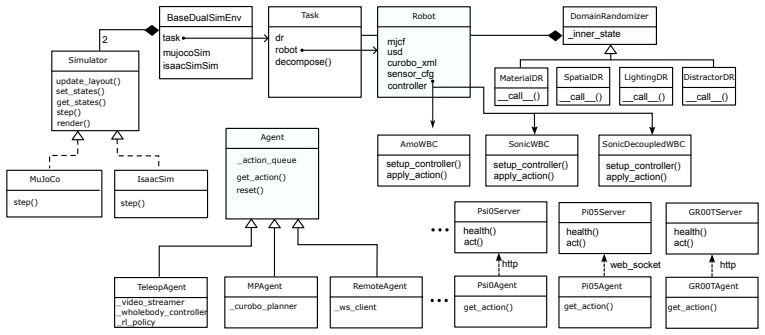
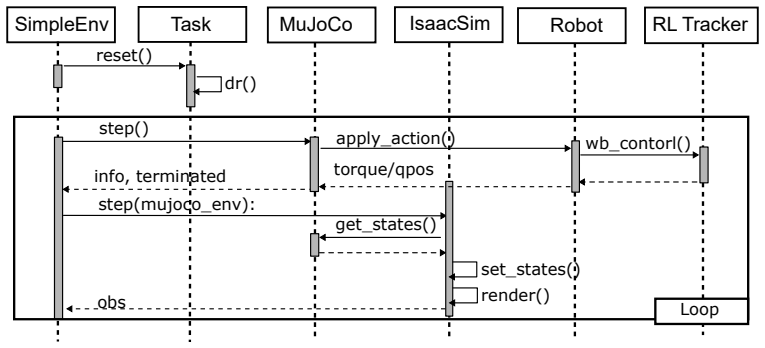
The SIMPLE testbed that unifies contact-rich physics simulation with photorealistic rendering and supplies automated trajectory generation plus VR teleoperation for policy data collection and evaluation.
If this is right
- Humanoid policy development can scale through simulation data collection without constant physical robot access.
- Performance in the testbed predicts real-world behavior, allowing filtered evaluation before hardware deployment.
- Reproducible benchmarks become available for comparing lightweight imitation networks against large vision-language-action and world action models.
- Zero-shot transfer reduces the volume of real-world data needed to reach functional loco-manipulation capabilities.
- A shared foundation supports community-wide progress on humanoid foundation models.
Where Pith is reading between the lines
- If the correlation holds across wider task distributions, the testbed could serve as a proxy for regulatory or safety validation of humanoid behaviors.
- Extending the same coupling of dynamics and rendering to additional robot morphologies might accelerate sim-to-real work outside humanoids.
- Incorporating more varied lighting, sensor noise, or deformable objects into the testbed would test the robustness of the observed transfer.
- Longer-horizon tasks or multi-robot coordination could be added to probe whether the current correlation persists at greater complexity.
Load-bearing premise
The simulation environment captures contact-rich dynamics, visual conditions, and task distributions of the physical world closely enough that performance correlations and zero-shot transfers observed in tested settings will hold more generally.
What would settle it
Policies trained to high performance in SIMPLE that then exhibit substantially lower success rates when run zero-shot on physical humanoid robots executing the same loco-manipulation tasks under matched conditions.
Figures




read the original abstract
Humanoid foundation models are advancing faster than we can evaluate them. While real-world testing is expensive and difficult to reproduce, existing simulation benchmarks focus primarily on table-top or wheeled robots. A scalable and reproducible benchmark for whole-body humanoid loco-manipulation remains an open problem. To this end, we present SIMPLE, a unified simulation testbed for humanoid policy learning and evaluation. SIMPLE couples the accurate contact-rich dynamics of MuJoCo with the photorealistic rendering of IsaacSim. It provides a large-scale environment comprising 60 diverse whole-body tasks, 50 indoor scenes, and over 1,000 object assets. To facilitate scalable data collection, the framework integrates two data generation pipelines: automated trajectory generation via motion planning and a low-latency VR teleoperation interface. We further integrate and benchmark mainstream humanoid policies at scale in SIMPLE, including lightweight imitation networks, large vision-language-action (VLA) models, and recent world action models (WAMs). Our experiments reveal a strong correlation between policy performance in simulation and the real world. Furthermore, we demonstrate that policies trained on data collected in SIMPLE can be transferred zero-shot to physical humanoid robots under similar settings, providing a robust and reproducible foundation for humanoid robotics research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SIMPLE, a hybrid simulation testbed for humanoid loco-manipulation that couples MuJoCo contact dynamics with IsaacSim photorealistic rendering. It comprises 60 whole-body tasks across 50 indoor scenes and >1000 object assets, with data pipelines using motion planning and VR teleoperation. The work benchmarks imitation networks, VLAs, and world action models, claiming a strong correlation between simulated and real-world policy performance plus successful zero-shot transfer of policies trained in SIMPLE to physical humanoid robots.
Significance. If the reported correlation and zero-shot transfers are substantiated with quantitative controls, this benchmark would address a clear gap in scalable, reproducible evaluation for whole-body humanoid policies, where real-world testing is costly. The scale (tasks, scenes, assets) and dual data-generation pipelines are strengths that could accelerate research if the sim fidelity supports the transfer claims.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the central claim of 'strong correlation' between simulation and real-world performance plus zero-shot transfer is asserted without any reported quantitative metrics (success rates, correlation coefficients, error bars), task definitions, or experimental controls, preventing assessment of whether the results support the modeling assumptions.
- [Experiments] Experiments section: the zero-shot transfer claim rests on the unquantified fidelity of MuJoCo+IsaacSim for contact-rich loco-manipulation dynamics; no contact force matching metrics, friction identification procedure, or domain randomization details are supplied to validate that small contact errors do not prevent transfer in whole-body tasks.
minor comments (2)
- [Related Work] Related Work: the discussion of prior simulation benchmarks for table-top or wheeled robots would benefit from explicit citations and a table comparing task coverage and fidelity features.
- [Figures] Figure captions: several figures showing policy rollouts lack labels for success/failure criteria or quantitative performance overlays.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where quantitative support for our claims can be strengthened. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim of 'strong correlation' between simulation and real-world performance plus zero-shot transfer is asserted without any reported quantitative metrics (success rates, correlation coefficients, error bars), task definitions, or experimental controls, preventing assessment of whether the results support the modeling assumptions.
Authors: We agree that the abstract and Experiments section would benefit from explicit quantitative metrics to allow full assessment of the claims. In the revised manuscript, we will update the abstract to reference key results and expand the Experiments section with tables reporting success rates (with error bars) for simulation and real-world evaluations across tasks, correlation coefficients between sim and real performance, precise task definitions, and descriptions of experimental controls. revision: yes
-
Referee: [Experiments] Experiments section: the zero-shot transfer claim rests on the unquantified fidelity of MuJoCo+IsaacSim for contact-rich loco-manipulation dynamics; no contact force matching metrics, friction identification procedure, or domain randomization details are supplied to validate that small contact errors do not prevent transfer in whole-body tasks.
Authors: We acknowledge that additional validation details are needed to substantiate the simulation fidelity for contact-rich tasks. In the revised Experiments section, we will add available contact force matching metrics, describe the friction identification procedure used, and provide specifics on domain randomization to better support the zero-shot transfer results. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or fitted predictions
full rationale
The paper introduces a simulation testbed (SIMPLE) coupling MuJoCo and IsaacSim, provides task/scene assets, data pipelines (motion planning and VR teleoperation), and reports empirical benchmarking of policies with observed sim-to-real correlation and zero-shot transfers. No equations, parameter fits, or derivation chains are present. The central claims rest on experimental results rather than any self-definitional, fitted-input, or self-citation reduction. This is a standard empirical benchmark paper whose content is independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: A vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[8]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, M. Lingelbach, J. Sun, et al. Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. InConference on Robot Learning, pages 80–93. PMLR, 2023
2023
-
[9]
Atreya, K
P. Atreya, K. Pertsch, T. Lee, M. J. Kim, A. Jain, A. Kuramshin, C. Eppner, C. Neary, E. Hu, F. Ramos, et al. Roboarena: Distributed real-world evaluation of generalist robot policies. In Proceedings of the Conference on Robot Learning (CoRL 2025), 2025
2025
- [10]
-
[11]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
C. L. Lab. Humanoidverse: A multi-simulator framework for humanoid robot sim-to-real learning.https://github.com/LeCAR-Lab/HumanoidVerse, 2025. 9
2025
-
[13]
Sferrazza, D.-M
C. Sferrazza, D.-M. Huang, X. Lin, Y . Lee, and P. Abbeel. Humanoidbench: Simulated hu- manoid benchmark for whole-body locomotion and manipulation, 2024
2024
-
[14]
Khanna, Y
M. Khanna, Y . Mao, H. Jiang, S. Haresh, B. Shacklett, D. Batra, A. Clegg, E. Undersander, A. X. Chang, and M. Savva. Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeoffs for objectgoal navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16384–16393, 2024
2024
-
[15]
Deitke, D
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. VanderBilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023
2023
-
[16]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[17]
Isaac Sim
NVIDIA. Isaac Sim. URLhttps://github.com/isaac-sim/IsaacSim
-
[18]
Sundaralingam, A
B. Sundaralingam, A. Murali, and S. Birchfield. curobov2: Dynamics-aware motion generation with depth-fused distance fields for high-dof robots, 2026
2026
- [19]
-
[20]
J. Li, X. Cheng, T. Huang, S. Yang, R. Qiu, and X. Wang. Amo: Adaptive motion optimization for hyper-dexterous humanoid whole-body control.Robotics: Science and Systems 2025, 2025
2025
-
[21]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Castaneda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, X. Cheng, R.-Z. Qiu, et al. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
H. Bi, L. Wu, T. Lin, H. Tan, Z. Su, H. Su, and J. Zhu. H-rdt: Human manipulation en- hanced bimanual robotic manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18135–18143, 2026
2026
-
[24]
S. Deng, M. Yan, S. Wei, H. Ma, Y . Yang, J. Chen, Z. Zhang, T. Yang, X. Zhang, W. Zhang, et al. Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data. arXiv preprint arXiv:2505.03233, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang. Uni- navid: A video-based vision-language-action model for unifying embodied navigation tasks. arXiv preprint arXiv:2412.06224, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
H.-S. Fang, C. Wang, M. Gou, and C. Lu. Graspnet-1billion: A large-scale benchmark for general object grasping. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11444–11453, 2020
2020
-
[27]
S. Wei, H. Geng, J. Chen, C. Deng, C. Wenbo, C. Zhao, X. Fang, L. Guibas, and H. Wang. D3roma: Disparity diffusion-based depth sensing for material-agnostic robotic manipulation. InECCV 2024 Workshop on Wild 3D: 3D Modeling, Reconstruction, and Generation in the Wild, 2024
2024
-
[28]
Robochallenge: Large-scale real-robot evaluation of embodied policies
A. Yakefu, B. Xie, C. Xu, E. Zhang, E. Zhou, F. Jia, H. Yang, H. Fan, H. Zhang, H. Peng, et al. Robochallenge: Large-scale real-robot evaluation of embodied policies.arXiv preprint arXiv:2510.17950, 2025. 10
-
[29]
DROID: A large-scale in-the-wild robot manipulation dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, and S. D. et al. DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset. InProceedings of Robotics: Science and Systems (RSS), 2024. doi:10.15607/RSS.2024.XX.120
-
[30]
Y . R. Wang, C. Ung, G. Tannert, J. Duan, J. Li, A. Le, R. Oswal, M. Grotz, W. Pumacay, Y . Deng, et al. Roboeval: Where robotic manipulation meets structured and scalable evaluation. arXiv preprint arXiv:2507.00435, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[32]
Nasiriany, S
S. Nasiriany, S. Nasiriany, A. Maddukuri, and Y . Zhu. Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[33]
Y . Kim, W. Pumacay, O. Rayyan, M. Argus, W. Han, E. VanderBilt, J. Salvador, A. Deshpande, R. Hendrix, S. Jauhri, S. Liu, N. M. M. Shafiullah, M. Guru, A. Guru, A. Eftekhar, K. Farley, D. Clay, J. Duan, P. Wolters, A. Herrasti, Y .-C. Lee, G. Chalvatzaki, Y . Cui, A. Farhadi, D. Fox, and R. Krishna. Molmospaces: A large-scale open ecosystem for robot nav...
2026
- [34]
-
[35]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi- modal robot learning.arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Y . Chen, S. Wei, B. Xiao, J. Lyu, J. Chen, F. Zhu, and H. Wang. Robohanger: Learning generalizable robotic hanger insertion for diverse garments.IEEE Robotics and Automation Letters, 2025
2025
-
[37]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba. Openai gym.arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[39]
X. Wei, M. Liu, Z. Ling, and H. Su. Approximate convex decomposition for 3d meshes with collision-aware concavity and tree search.ACM Transactions on Graphics (TOG), 41(4):1–18, 2022
2022
- [40]
-
[41]
vmaterials.https://developer.nvidia.com/vmaterials, 2026
NVIDIA. vmaterials.https://developer.nvidia.com/vmaterials, 2026. Accessed: 2026-05-24
2026
-
[42]
X. Chen, Y . Chen, Y . Fu, N. Gao, J. Jia, W. Jin, H. Li, Y . Mu, J. Pang, Y . Qiao, et al. Internvla- m1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[44]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023. 11 Contents 1 Introduction 2 2 Related Work 3 2.1 Robot Policy Evaluation in the Real World . . . . . . . . . . . . . . . . . . . . . . 3 2.2 Simulation-Based Benchmarks for Manipulation . . . . . . . . ....
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.