Late-Layer Fusion is Enough: Dual-Path Vision Token Routing for Multimodal Large Language Models under Visual Saturation
Pith reviewed 2026-06-27 16:30 UTC · model grok-4.3
The pith
Vision tokens saturate early, so routing them to a late single-layer fusion branch preserves MLLM performance with 3 percent trainable parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
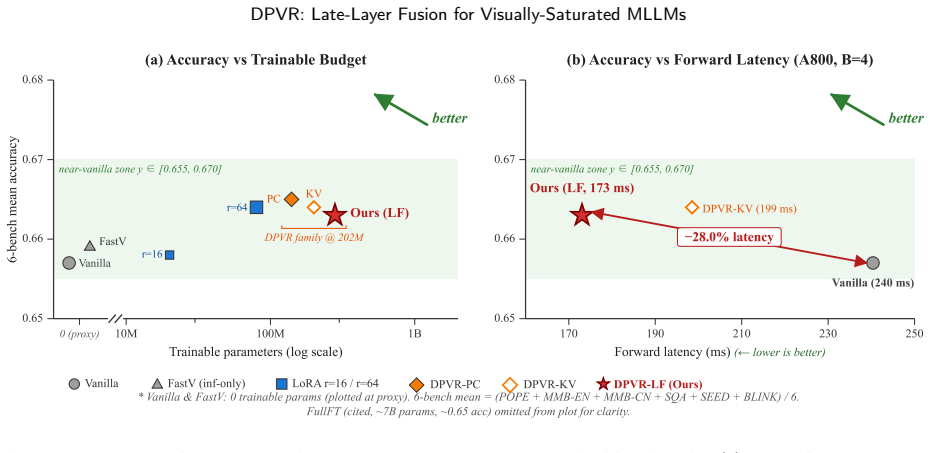
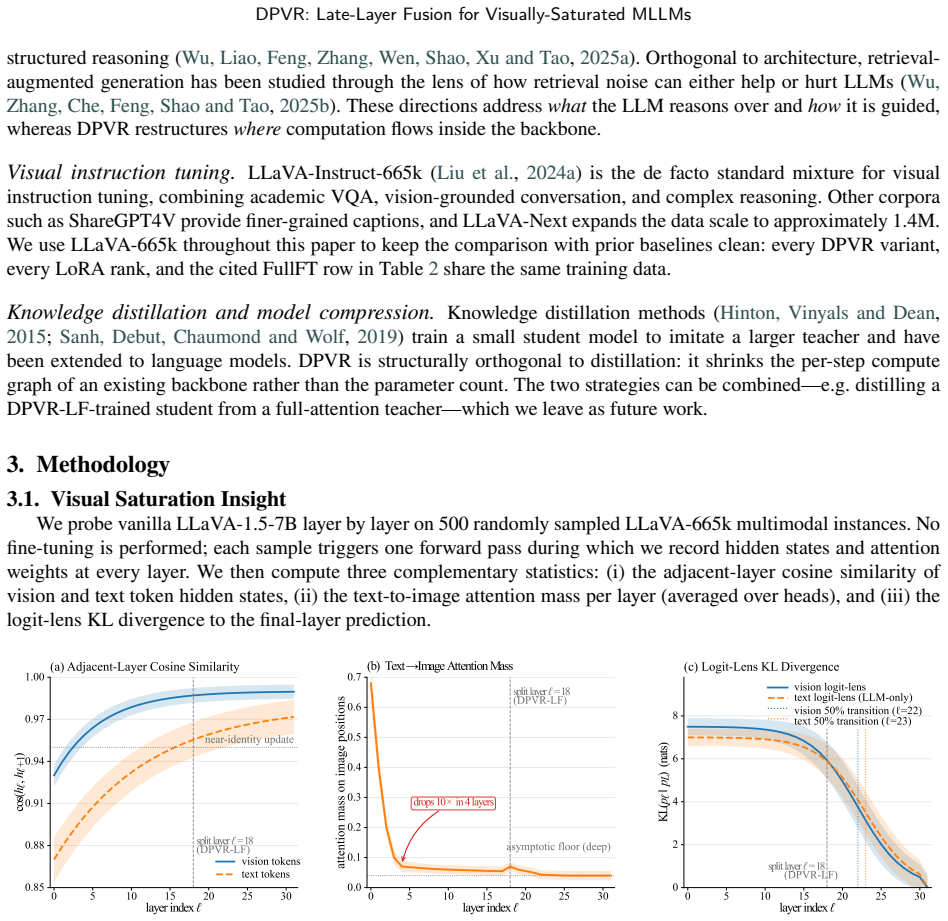
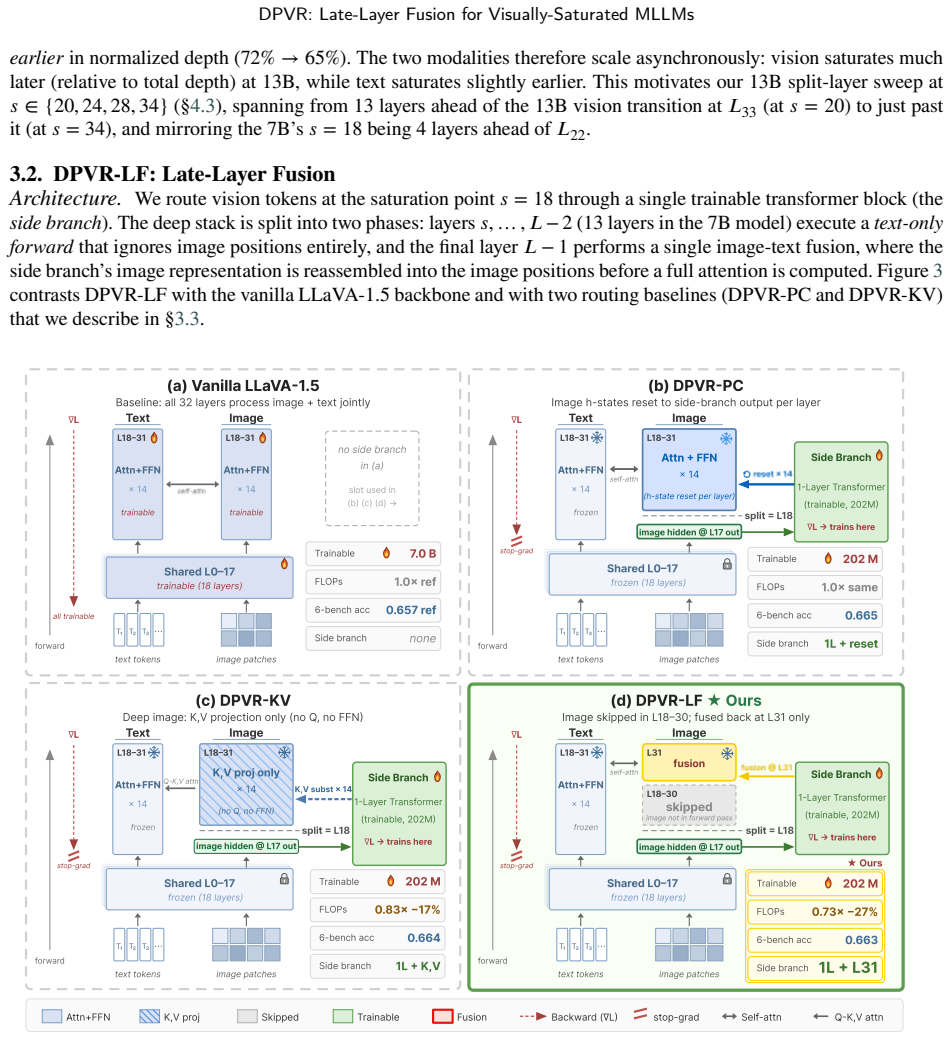
Layer-wise attention analysis on LLaVA-1.5 reveals text-to-image attention falling from 0.68 at layer 0 to 0.07 by layer 4 and stabilizing near 0.04 after layer 18, indicating visual saturation, while text tokens keep benefiting from deep layers. DPVR-LF therefore routes vision tokens at the saturation point into a one-layer trainable side branch, performs a thirteen-layer text-only forward pass that skips image positions, and re-fuses the two streams only at the final layer, achieving the reported performance with roughly 3 percent trainable parameters.
What carries the argument
Dual-Path Vision Token Routing (DPVR) with its Late-Layer Fusion (DPVR-LF) instantiation: a one-layer side branch that carries saturated vision tokens until final-layer re-fusion with the text stream.
If this is right
- Vision tokens do not require traversal of every deep language-model layer once saturation is reached.
- A single late fusion layer suffices to maintain perceptual competence without full symmetric depth.
- Visual computation inside the deep Transformer stack can be reduced while keeping multimodal benchmark scores competitive.
- Modality-asymmetric routing offers a route to lower parameter counts during task-specific adaptation.
Where Pith is reading between the lines
- The same saturation measurement could be repeated on other MLLM families to test whether the 3 percent parameter regime generalizes.
- If early vision saturation is common, future designs might allocate separate depth budgets per modality rather than sharing one backbone.
- The side-branch approach might extend to additional modalities such as audio if their cross-attention patterns also plateau early.
Load-bearing premise
The early saturation pattern measured in LLaVA-1.5 attention maps will hold for other models and tasks, so that skipping middle and late layers for vision tokens does not degrade final accuracy.
What would settle it
An ablation that removes the late fusion step and measures whether visual-question-answering accuracy on standard benchmarks falls below the full-model baseline by more than a few percentage points.
Figures

read the original abstract
Multimodal large language models (MLLMs) commonly inherit the deep, symmetric Transformer backbone designed for unimodal text modeling, and apply the same computation uniformly to image and language tokens. This design overlooks a key modality asymmetry: image and text tokens differ substantially in information density, redundancy, and required reasoning depth. Through a layer-wise analysis of LLaVA-1.5, we observe that vision tokens tend to saturate in the middle layers. Specifically, text-to-image attention decreases from 0.68 at layer 0 to 0.07 by layer 4, and stabilizes near 0.04 after layer 18, whereas text tokens continue to benefit from deep semantic processing. These findings suggest a mismatch between architectural symmetry and depth-asynchronous modality evolution, resulting in redundant visual computation and possible drift in perceptual representations during deep task-specific adaptation. Motivated by this, we propose Dual-Path Vision Token Routing (DPVR), a modality-asymmetric routing framework for efficient MLLMs. Its core instantiation, DPVR-LF (Late-Layer Fusion), routes vision tokens at the saturation point into a one-layer trainable side branch, runs a thirteen-layer text-only forward that skips image positions in the deep stack, and re-fuses the visual and textual streams only at the final layer. With approximately 3% trainable parameters, DPVR-LF preserves competitive multimodal performance on standard benchmarks while reducing visual computation in the deep Transformer stack. The results challenge the conventional assumption that vision tokens must traverse all deep language-model layers, and indicate that a single late fusion layer can be sufficient for maintaining strong perceptual competence in LLaVA-style MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vision tokens in LLaVA-style MLLMs saturate early (text-to-image attention drops from 0.68 at layer 0 to ~0.04 after layer 18), so Dual-Path Vision Token Routing with Late Fusion (DPVR-LF) can route them after the saturation point into a 1-layer side branch, run a 13-layer text-only stack, and perform a single late fusion; this uses ~3% trainable parameters while preserving competitive benchmark performance and challenges the need for symmetric deep processing of vision tokens.
Significance. If the result holds, the work would provide evidence that modality-asymmetric depth is viable for efficient MLLMs, reducing redundant visual computation in deep layers without loss of perceptual competence. The layer-wise attention analysis supplies a concrete, falsifiable observation motivating the design.
major comments (2)
- [Abstract and layer-wise analysis section] The saturation point and resulting claim that late fusion suffices both rest on attention statistics collected from the original symmetric LLaVA-1.5 model. Removing vision tokens from the middle and late layers changes the residual streams and cross-attention dynamics, so the original layer-wise pattern may not persist; the manuscript provides no direct re-measurement of text-to-image attention in the DPVR-LF computation graph to confirm the routing point remains valid.
- [Experiments / Results section] The central performance claim (preserved multimodal competence on standard benchmarks) is stated without visible quantitative results, ablation tables, or error bars in the abstract; if the full manuscript contains these, they must be cross-referenced to the routing and fusion design choices, as the absence of such evidence in the summary leaves the sufficiency of a single late fusion layer unverified.
Simulated Author's Rebuttal
Thank you for the thorough review and valuable feedback on our manuscript. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract and layer-wise analysis section] The saturation point and resulting claim that late fusion suffices both rest on attention statistics collected from the original symmetric LLaVA-1.5 model. Removing vision tokens from the middle and late layers changes the residual streams and cross-attention dynamics, so the original layer-wise pattern may not persist; the manuscript provides no direct re-measurement of text-to-image attention in the DPVR-LF computation graph to confirm the routing point remains valid.
Authors: We agree that the layer-wise attention analysis was performed on the original LLaVA-1.5 model. The early saturation observation provides the motivation for choosing the routing point after layer 4. In DPVR-LF, vision tokens are routed into the side branch, so the main path processes only text tokens in layers 5-17, altering the dynamics by design. To strengthen the claim and confirm that the saturation point remains appropriate, we will add a direct re-measurement of text-to-image attention within the DPVR-LF model in the revised version. revision: yes
-
Referee: [Experiments / Results section] The central performance claim (preserved multimodal competence on standard benchmarks) is stated without visible quantitative results, ablation tables, or error bars in the abstract; if the full manuscript contains these, they must be cross-referenced to the routing and fusion design choices, as the absence of such evidence in the summary leaves the sufficiency of a single late fusion layer unverified.
Authors: The manuscript contains detailed quantitative results, ablation tables, and error bars in the Experiments section, which are linked to the specific design choices of the routing point and late fusion. We will update the abstract to reference these results explicitly and add cross-references in the layer-wise analysis section to the corresponding experimental tables. revision: yes
Circularity Check
No significant circularity
full rationale
The paper motivates DPVR-LF via an empirical layer-wise attention analysis performed on the unmodified LLaVA-1.5 model (text-to-image attention drop from 0.68 at layer 0 to ~0.04 after layer 18). It then trains and evaluates the proposed asymmetric routing architecture on downstream benchmarks. No equations, fitted parameters, or self-citations reduce the performance claim to its inputs by construction; the saturation observation is external to the new model and the result is measured directly rather than derived tautologically.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A versatile vision–language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 doi:10.48550/arXiv.2308.12966. Liu and Wu:Preprint submitted to ElsevierPage 14 of 18 DPVR: Late-Layer Fusion for Visually-Saturated MLLMs Belrose, N., Furman, Z., Smith, L., Halawi, D., Ostrovsky, I., McKinney, L., Biderma...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.12966
-
[3]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112 doi:10.48550/arXiv.2303.08112. Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08112
-
[4]
Token Merging: Your ViT But Faster
Token merging: Your ViT but faster, in: International Conference on Learning Representations. doi:10.48550/arXiv.2210.09461,arXiv:2210.09461. Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.09461
-
[5]
An image is worth1∕2tokens after layer2: Plug-and-play inference acceleration for large vision–language models, in: European Conference on Computer Vision. doi:10.48550/arXiv.2403.06764, arXiv:2403.06764. Chiang,W.L.,Li,Z.,Lin,Z.,Sheng,Y.,Wu,Z.,Zhang,H.,Zheng,L.,Zhuang,S.,Zhuang,Y.,Gonzalez,J.E.,Stoica,I.,Xing,E.P.,2023. Vicuna: An open-source chatbot imp...
-
[6]
doi:10.48550/arXiv.1909.11556,arXiv:1909.11556
Reducing transformer depth on demand with structured dropout, in: International Conference on Learning Representations. doi:10.48550/arXiv.1909.11556,arXiv:1909.11556. Fedus, W., Zoph, B., Shazeer, N.,
-
[7]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research 23, 1–39. doi:10.48550/arXiv.2101.03961,arXiv:2101.03961. Feng,M.,Wu,J.,Liu,S.,Zhang,S.,Jin,R.,Che,F.,Shao,P.,Wen,Z.,Tao,J.,2025a. Two-stageregularization-basedstructuredpruningforLLMs. arXiv preprint arXiv:2505.18232 doi:10.4...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2101.03961 2023
-
[9]
Exploring Knowledge Purification in Multi-Teacher Knowledge Distillation for LLMs
Exploring knowledge purification in multi-teacher knowledge distillation for LLMs. arXiv preprint arXiv:2602.01064 doi:10.48550/arXiv.2602.01064,arXiv:2602.01064. Jin,R.,Shao,P.,Wen,Z.,Wu,J.,Feng,M.,Zhang,S.,Tao,J.,2025. RadialRouter:Structuredrepresentationforefficientandrobustlargelanguage models routing. arXiv preprint arXiv:2506.03880 doi:10.48550/arX...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.01064 2025
-
[10]
arXiv preprint arXiv:2405.05803 doi:10.48550/arXiv.2405.05803
VTW: Visual token withdrawal for efficient multimodal large language models. arXiv preprint arXiv:2405.05803 doi:10.48550/arXiv.2405.05803. Liu,H.,Li,C.,Li,Y.,Lee,Y.J.,2024a. Improvedbaselineswithvisualinstructiontuning,in:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition, pp. 26296–26306. doi:10.48550/arXiv.2310.03744,arXiv:2310...
-
[11]
Better, stronger, faster: Tackling the trilemma in MLLM-based segmentation with simultaneous textual mask prediction. arXiv preprint arXiv:2512.00395 doi:10.48550/arXiv.2512.00395,arXiv:2512.00395. Liu,Y.,Duan,H.,Zhang,Y.,Li,B.,Zhang,S.,Zhao,W.,Yuan,Y.,Wang,J.,He,C.,Liu,Z.,Chen,K.,Lin,D.,2024b.MMBench:Isyourmulti-modal model an all-around player?, in: Eur...
-
[12]
Learn to explain: Multimodal reasoning via thoughtchainsforsciencequestionanswering,in:AdvancesinNeuralInformationProcessingSystems,pp.2507–2521. doi:10.48550/arXiv. 2209.09513,arXiv:2209.09513. nostalgebraist,
work page internal anchor Pith review doi:10.48550/arxiv
-
[13]
LessWrong post
Interpreting GPT: The logit lens. LessWrong post. URL:https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/ interpreting-gpt-the-logit-lens. accessed: 2026-05-14. Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.,
2026
-
[14]
Learning transferable visual models from natural language supervision, in: Proceedings of the 38th International Conference on Machine Learning, PMLR. pp. 8748–8763. doi:10.48550/arXiv.2103.00020,arXiv:2103.00020. Sanh, V., Debut, L., Chaumond, J., Wolf, T.,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.00020
-
[15]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108 doi:10.48550/arXiv.1910.01108. neurIPS EMC2 Workshop. Shang, Y., Cai, M., Xu, B., Lee, Y.J., Yan, Y.,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1910.01108 1910
-
[16]
arXiv preprint arXiv:2403.15388 , year=
LLaVA-PruMerge: Adaptive token reduction for efficient large multimodal models. arXiv preprint arXiv:2403.15388 doi:10.48550/arXiv.2403.15388. Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.,
-
[17]
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 doi:10.48550/arXiv.2302.13971. Wu,J.,Feng,M.,Zhai,G.,Zhang,S.,Lian,Z.,Lv,F.,Shao,P.,Jin,R.,Wen,Z.,Tao,J.,2026. AStar:Boostingmultimodalreasoningwithautomated structured thinking, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 33926–33934. Wu, J., ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2026
-
[18]
arXiv preprint arXiv:2411.18478 doi:10.48550/arXiv.2411.18478,arXiv:2411.18478
Beyond examples: High-level automated reasoning paradigm in in-context learning via MCTS. arXiv preprint arXiv:2411.18478 doi:10.48550/arXiv.2411.18478,arXiv:2411.18478. Wu,J.,Liao,C.,Feng,M.,Zhang,S.,Wen,Z.,Shao,P.,Xu,H.,Tao,J.,2025a. Thought-augmentedpolicyoptimization:Bridgingexternalguidance and internal capabilities. arXiv preprint arXiv:2505.15692 1,
-
[19]
TemplateRL: Structured Template-Guided Reinforcement Learning for LLM Reasoning
doi:10.48550/arXiv.2505.15692,arXiv:2505.15692. Wu,J.,Zhang,S.,Che,F.,Feng,M.,Shao,P.,Tao,J.,2025b. Pandora’sboxoraladdin’slamp:AcomprehensiveanalysisrevealingtheroleofRAG noise in large language models, in: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 5019–5039. Zhu, D., Chen, J., Sh...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.15692
-
[20]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
MiniGPT-4: Enhancing vision–language understanding with advanced large language models, in: International Conference on Learning Representations. doi:10.48550/arXiv.2304.10592,arXiv:2304.10592. A. DPVR-LF Training: Gradient-Sparsity Analysis This appendix gives the formal argument behind the claim in §3.2 that the fully text-only deep stack (DPVR- LF-idea...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.10592
-
[21]
Code.The full source and training scripts will be released upon paper acceptance. The key implementation files are: •src/dpvr/models/token_diversion.py— DPVR-PC baseline •src/dpvr/models/token_diversion_substitution.py— DPVR-KV baseline •src/dpvr/models/token_diversion_x3_fusion.py—DPVR-LF (Ours) Liu and Wu:Preprint submitted to ElsevierPage 17 of 18 DPVR...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.