OmniGameArena: A Unified UE5 Benchmark for VLM Game Agents with Improvement Dynamics
Pith reviewed 2026-06-27 16:48 UTC · model grok-4.3
The pith
OmniGameArena supplies twelve new UE5 games and an IDC harness so VLM agents can be scored on cold-start performance plus how their skills evolve through autonomous reflection rounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
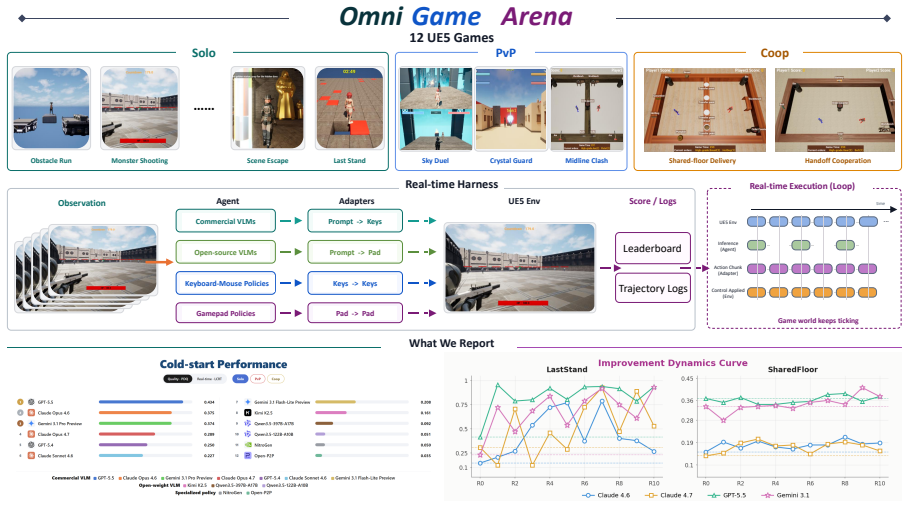
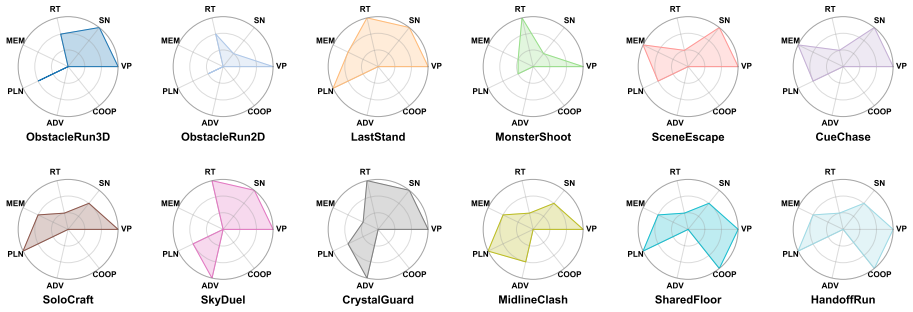
OmniGameArena consists of twelve newly built Unreal Engine 5 games covering solo, PvP, and coop play with unified action interfaces, paired with the Improvement Dynamics Curve harness in which a tool-using reflector LLM autonomously refines bounded skill prompts across multiple rounds, thereby exposing for each agent-game pair both the evolution of scores across reflection rounds and the behavior of the learned skill on held-out task variants.
What carries the argument
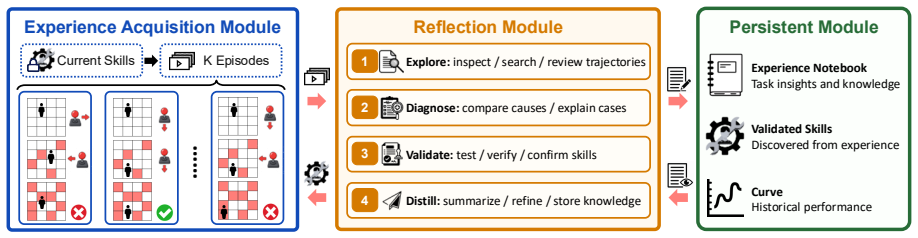
The Improvement Dynamics Curve (IDC), an agentic-reflection harness that uses a tool-using reflector LLM to autonomously refine a bounded skill prompt across successive rounds.
If this is right
- VLM agents of different types become directly comparable on the same set of games and interfaces.
- Score change across reflection rounds becomes a standard observable in addition to the initial score.
- Generalization is measured by testing the refined skill on held-out task variants.
- Evaluation extends naturally to PvP and cooperative multi-agent settings.
Where Pith is reading between the lines
- Agents might be trained explicitly to maximize improvement rate rather than single-shot peak performance.
- The IDC approach could be applied to other interactive domains such as robotic control or simulation environments.
- Observed dynamics may vary with the choice of reflector LLM, suggesting separate study of that component.
Load-bearing premise
The twelve newly constructed UE5 games together with their unified action interfaces and the reflector LLM inside the IDC form a representative testbed that fairly compares heterogeneous agent classes without introducing design artifacts or reflection biases.
What would settle it
Finding that replacement of the reflector LLM or substitution of the custom games with existing commercial titles produces substantially different improvement trajectories or leaderboard orderings would show the benchmark does not deliver stable, unbiased observables.
Figures



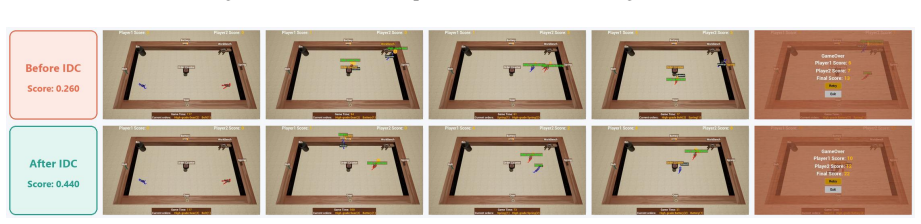
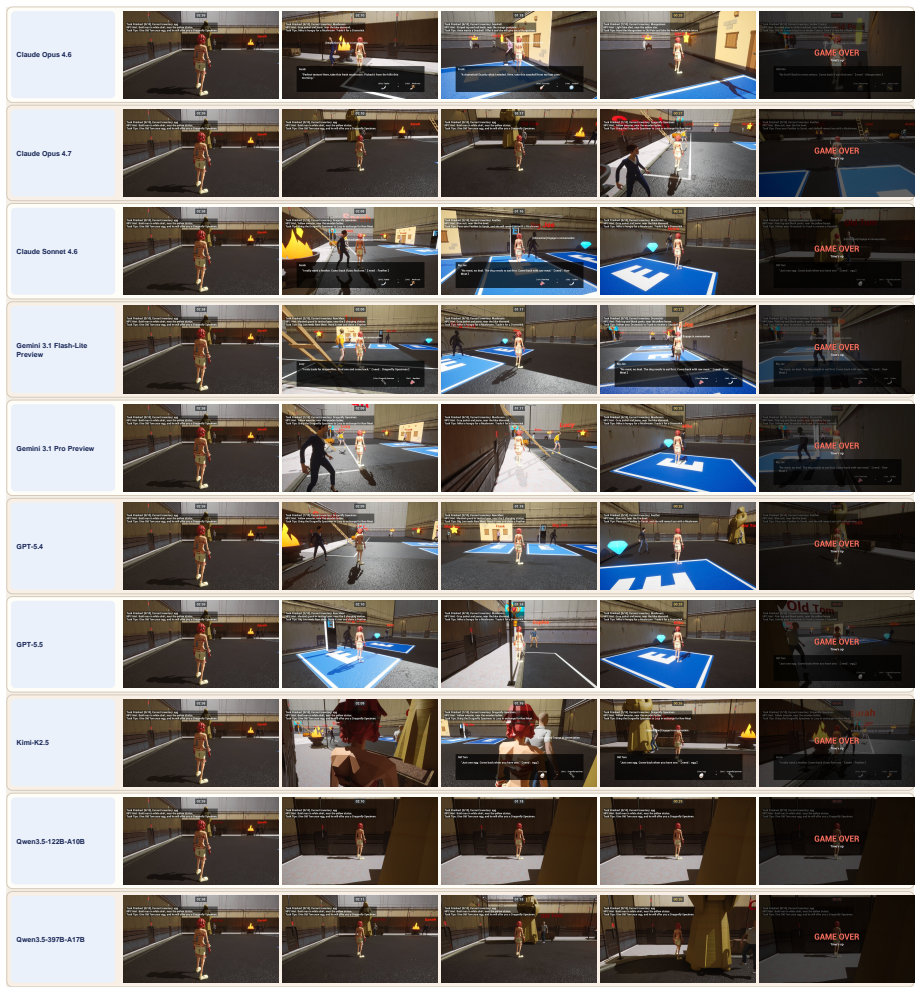



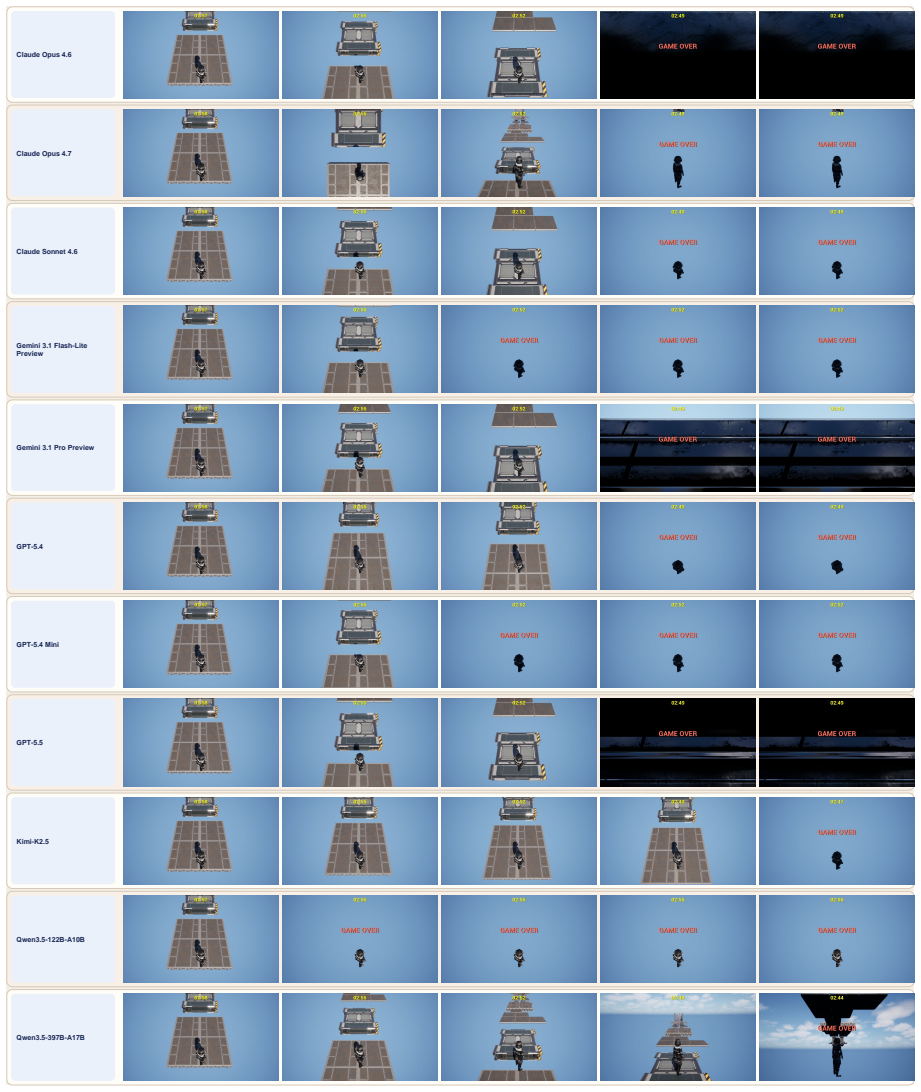
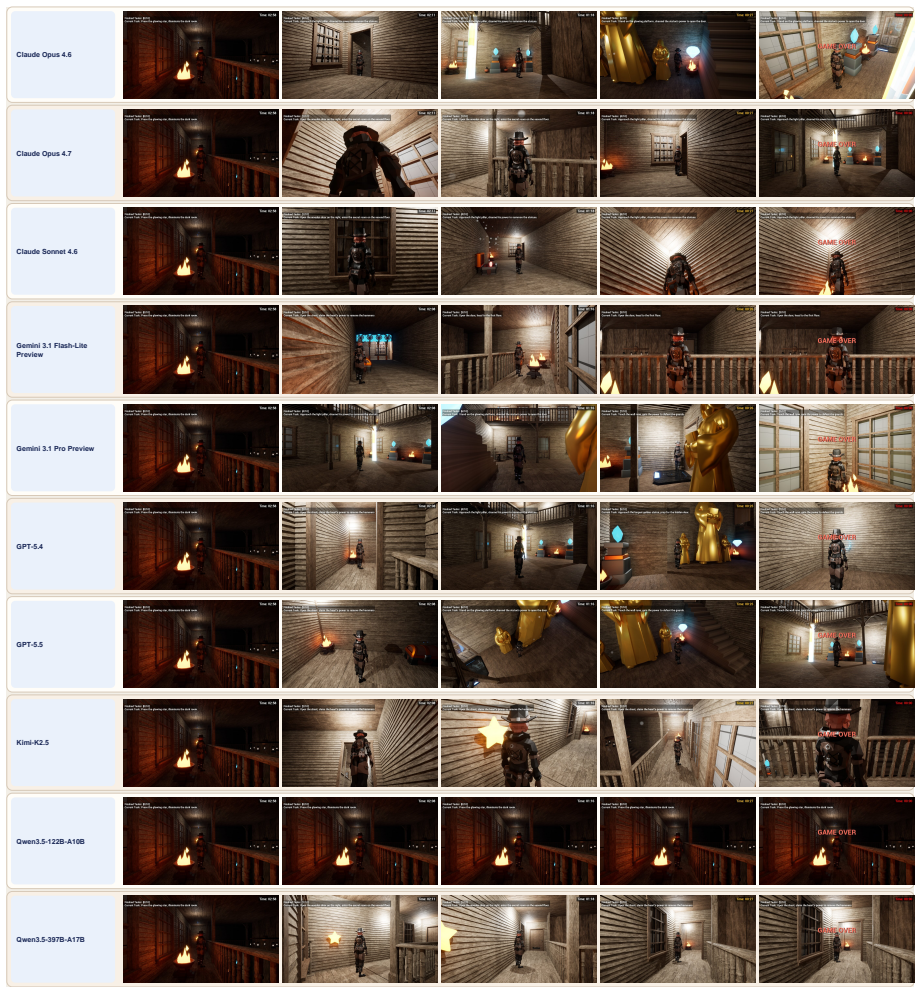

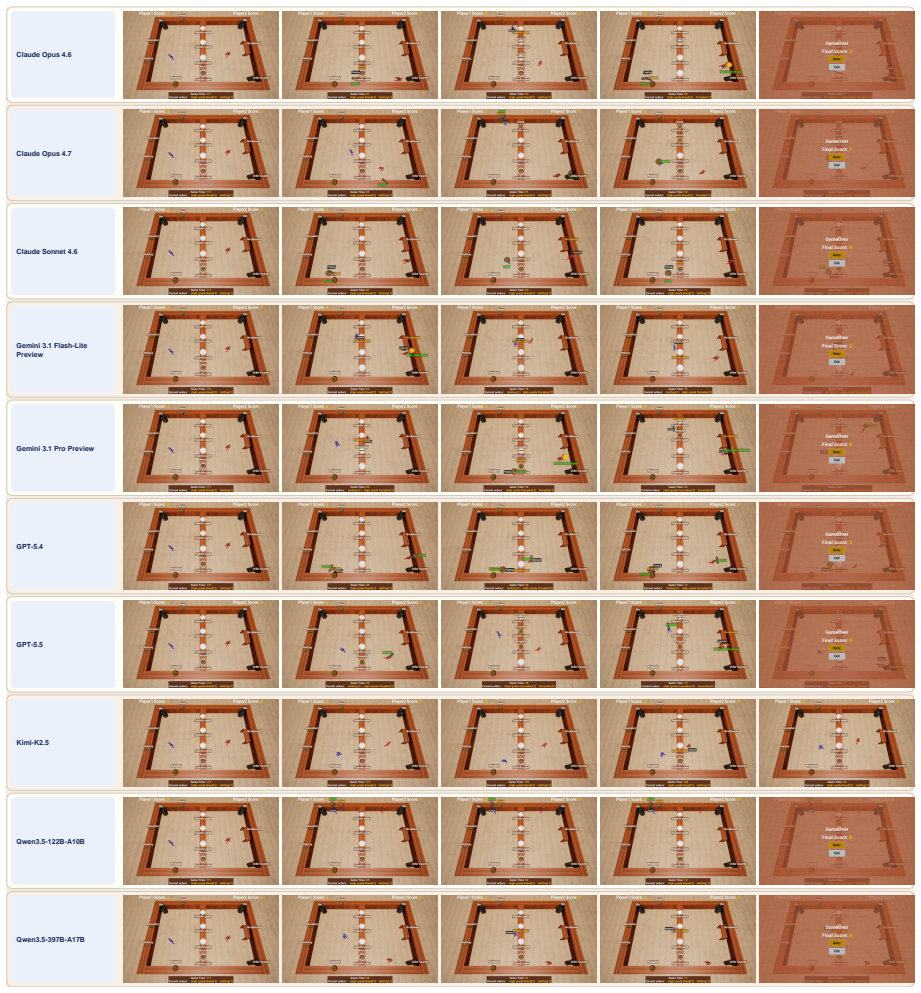


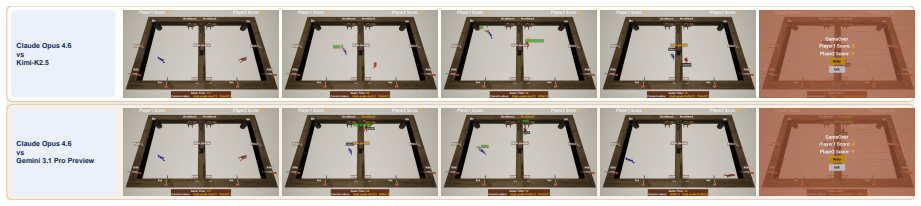

read the original abstract
Vision-language model (VLM) agents are increasingly deployed in interactive game environments. Yet game benchmarks for VLM agents typically report a single first-attempt score per (agent, game) pair, focus on single-agent Solo play, and lack unified protocols for evaluating heterogeneous agent classes (commercial VLMs, open-weight VLMs, and specialized game policies) on the same footing. We address these gaps with OmniGameArena, a real-time benchmark of twelve newly built Unreal Engine 5 games spanning Solo (7), PvP (3), and Coop (2) with unified action interfaces, and the Improvement Dynamics Curve (IDC), an agentic-reflection harness in which a tool-using reflector LLM autonomously refines a bounded skill prompt across multiple rounds. Beyond cold-start leaderboard scores, IDC exposes two additional observables for each (agent, game) pair: how the score evolves across reflection rounds, and how the learned skill behaves on held-out task variants. We report these observables for twelve VLM agents on the cold-start leaderboard and four top agents under IDC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniGameArena, a real-time benchmark consisting of twelve newly constructed Unreal Engine 5 games (7 Solo, 3 PvP, 2 Coop) equipped with unified action interfaces, together with the Improvement Dynamics Curve (IDC), an agentic-reflection harness in which a tool-using reflector LLM autonomously refines a bounded skill prompt over multiple rounds. Beyond cold-start leaderboard scores for twelve VLM agents, the work reports two additional observables per (agent, game) pair: score evolution across reflection rounds and behavior of the learned skill on held-out task variants, with IDC results shown for the four top agents.
Significance. If the new environments and IDC harness prove free of systematic bias, the benchmark could supply a needed unified protocol for comparing commercial VLMs, open-weight VLMs, and specialized policies across solo and multi-agent settings, while the IDC observables would add longitudinal and generalization information absent from single-shot game benchmarks. The explicit construction of real-time UE5 titles and the agentic-reflection mechanism are concrete contributions that could be adopted by the VLM-agent community.
major comments (2)
- [Benchmark Construction and Game Descriptions] The central claim that the twelve author-built UE5 games plus unified action interfaces constitute a neutral, representative testbed is unsupported by any validation, cross-benchmark calibration, or analysis of potential design artifacts (game mechanics, visual cues, reward structures, or action mappings). This is load-bearing for the fairness of both the cold-start leaderboard and the IDC curves.
- [IDC Harness and Experimental Protocol] No ablation or control experiment isolates whether observed IDC score evolution arises from intrinsic VLM agent improvement or from the reflector LLM's prompt-refinement policy. Without such separation, the reported improvement dynamics cannot be unambiguously attributed to the evaluated agents.
minor comments (2)
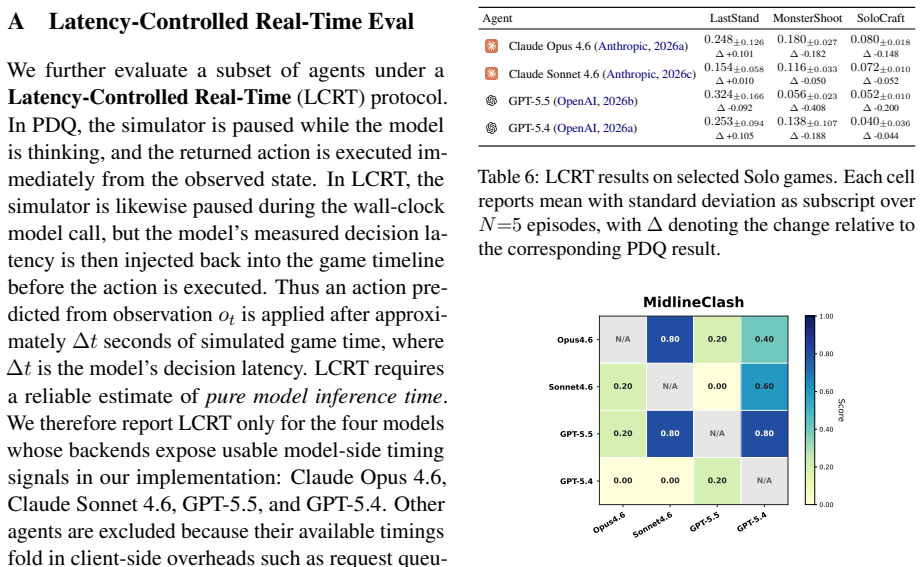
- [Results] The abstract states that observables are reported for twelve agents on the cold-start leaderboard and four under IDC, yet the manuscript should include the precise numerical values, variance estimates, and statistical tests in a dedicated results table or figure for reproducibility.
- [Related Work] References to prior VLM game benchmarks (e.g., those using established titles) are needed to situate the novelty of the twelve new UE5 environments and to allow readers to assess the claimed unification of protocols.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, proposing targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Benchmark Construction and Game Descriptions] The central claim that the twelve author-built UE5 games plus unified action interfaces constitute a neutral, representative testbed is unsupported by any validation, cross-benchmark calibration, or analysis of potential design artifacts (game mechanics, visual cues, reward structures, or action mappings). This is load-bearing for the fairness of both the cold-start leaderboard and the IDC curves.
Authors: We agree the manuscript provides no cross-benchmark calibration or systematic artifact analysis. The twelve games were newly constructed in UE5 specifically to span Solo, PvP, and Coop settings under a single action interface, enabling direct comparison of commercial VLMs, open-weight VLMs, and specialized policies. In revision we will add an appendix with per-game descriptions of mechanics, visual cues, reward structures, and action mappings, plus a limitations paragraph discussing possible design biases. Full external calibration remains outside the current scope. revision: partial
-
Referee: [IDC Harness and Experimental Protocol] No ablation or control experiment isolates whether observed IDC score evolution arises from intrinsic VLM agent improvement or from the reflector LLM's prompt-refinement policy. Without such separation, the reported improvement dynamics cannot be unambiguously attributed to the evaluated agents.
Authors: We concur that the present protocol lacks an explicit control isolating the reflector LLM's contribution. The IDC design uses a fixed reflector policy across agents to measure how each VLM agent's performance changes when given progressively refined skill prompts. In the revised version we will include a control condition in which the reflector applies a non-adaptive (fixed or random) prompt policy and report the resulting score trajectories for the four top agents, allowing direct comparison to the adaptive-reflector results. revision: yes
Circularity Check
No circularity; benchmark definition is self-contained
full rationale
The manuscript defines a new benchmark (OmniGameArena) consisting of author-built UE5 games and a new evaluation harness (IDC) without any equations, fitted parameters, predictions, or derivations. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The observables (cold-start scores, score evolution, held-out behavior) are direct measurements on the defined testbed rather than quantities derived from prior results by construction. This matches the expected non-finding for a benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , howpublished =
Kimi K2.5: Visual Agentic Intelligence , author =. 2026 , howpublished =
2026
-
[8]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Jarvis-vla: Post-training large-scale vision language models to play visual games with keyboards and mouse , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[9]
Advances in Neural Information Processing Systems , volume=
The nethack learning environment , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Chessgpt: Bridging policy learning and language modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Interactive fiction games: A colossal adventure , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Learning Physics-Based Full-Body Human Reaching and Grasping from Brief Walking References , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[20]
Advances in Neural Information Processing Systems , volume=
Minedojo: Building open-ended embodied agents with internet-scale knowledge , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
arXiv preprint arXiv:2409.12889 , year=
Can vlms play action role-playing games? take black myth wukong as a study case , author=. arXiv preprint arXiv:2409.12889 , year=
-
[28]
GameWorld: Towards Standardized and Verifiable Evaluation of Multimodal Game Agents
GameWorld: Towards standardized and verifiable evaluation of multimodal game agents , author=. arXiv preprint arXiv:2604.07429 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[30]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Expel: Llm agents are experiential learners , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
2026 , month = may, howpublished =
Learning Beyond Gradients , author =. 2026 , month = may, howpublished =
2026
-
[35]
Anthropic . 2026 a . Introducing C laude O pus 4.6. https://www.anthropic.com/news/claude-opus-4-6
2026
-
[36]
Anthropic . 2026 b . Introducing C laude O pus 4.7. https://www.anthropic.com/news/claude-opus-4-7
2026
-
[37]
Anthropic . 2026 c . Introducing C laude S onnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6
2026
-
[38]
Hao Bai, Alexey Taymanov, Tong Zhang, Aviral Kumar, and Spencer Whitehead. 2026. Webgym: Scaling training environments for visual web agents with realistic tasks. arXiv preprint arXiv:2601.02439
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. 2022. Minedojo: Building open-ended embodied agents with internet-scale knowledge. volume 35, pages 18343--18362
2022
-
[40]
Xidong Feng, Yicheng Luo, Ziyan Wang, Hongrui Tang, Mengyue Yang, Kun Shao, David Mguni, Yali Du, and Jun Wang. 2023. Chessgpt: Bridging policy learning and language modeling. Advances in Neural Information Processing Systems, 36:7216--7262
2023
-
[41]
Google . 2026 a . Introducing G emini 3.1 F lash- L ite. https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/
2026
-
[42]
Google . 2026 b . Introducing G emini 3.1 P ro. https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/
2026
-
[43]
Matthew Hausknecht, Prithviraj Ammanabrolu, Marc-Alexandre C \^o t \'e , and Xingdi Yuan. 2020. Interactive fiction games: A colossal adventure. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7903--7910
2020
- [44]
- [45]
-
[46]
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, and Michael R Lyu. 2024. How far are we on the decision-making of llms? evaluating llms' gaming ability in multi-agent environments. arXiv preprint arXiv:2403.11807
-
[47]
u ttler, Nantas Nardelli, Alexander Miller, Roberta Raileanu, Marco Selvatici, Edward Grefenstette, and Tim Rockt \
Heinrich K \"u ttler, Nantas Nardelli, Alexander Miller, Roberta Raileanu, Marco Selvatici, Edward Grefenstette, and Tim Rockt \"a schel. 2020. The nethack learning environment. Advances in Neural Information Processing Systems, 33:7671--7684
2020
-
[48]
Muyao Li, Zihao Wang, Kaichen He, Xiaojian Ma, and Yitao Liang. 2025. Jarvis-vla: Post-training large-scale vision language models to play visual games with keyboards and mouse. In Findings of the Association for Computational Linguistics: ACL 2025, pages 17878--17899
2025
- [49]
- [50]
-
[51]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, and 1 others. 2023. Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems, 36:46534--46594
2023
- [52]
-
[53]
Moonshot AI . 2026. Kimi k2.5: Visual agentic intelligence. https://www.kimi.com/blog/kimi-k2-5
2026
-
[54]
OpenAI . 2026 a . Introducing GPT -5.4. https://openai.com/index/introducing-gpt-5-4/
2026
-
[55]
OpenAI . 2026 b . Introducing GPT -5.5. https://openai.com/index/introducing-gpt-5-5/
2026
- [56]
-
[57]
Dongmin Park, Minkyu Kim, Beongjun Choi, Junhyuck Kim, Keon Lee, Jonghyun Lee, Inkyu Park, Byeong-Uk Lee, Jaeyoung Hwang, Jaewoo Ahn, and 1 others. 2025. Orak: A foundational benchmark for training and evaluating llm agents on diverse video games. arXiv preprint arXiv:2506.03610
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Qwen Team . 2026. Qwen3.5 : A N ative M ultimodal F oundation M odel for E fficiency. https://qwen.ai/blog?id=qwen3.5
2026
-
[59]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems, 36:8634--8652
2023
-
[60]
Weihao Tan, Ziluo Ding, Wentao Zhang, Boyu Li, Bohan Zhou, Junpeng Yue, Haochong Xia, Jiechuan Jiang, Longtao Zheng, Xinrun Xu, and 1 others. 2024. Towards general computer control: A multimodal agent for red dead redemption ii as a case study. arXiv preprint arXiv:2403.03186, 1(2)
- [61]
- [62]
-
[63]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models, 2023. URL https://arxiv. org/abs/2305.16291, 2(11)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [64]
- [65]
-
[66]
Jiayi Weng. 2026. Learning beyond gradients. https://trinkle23897.github.io/learning-beyond-gradients/. Blog post
2026
- [67]
- [68]
-
[69]
Alex L Zhang, Thomas L Griffiths, Karthik R Narasimhan, and Ofir Press. 2025. Videogamebench: Can vision-language models complete popular video games? arXiv preprint arXiv:2505.18134
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [70]
-
[71]
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632--19642
2024
-
[72]
Xiangxi Zheng, Linjie Li, Zhengyuan Yang, Ping Yu, Alex Jinpeng Wang, Rui Yan, Yuan Yao, and Lijuan Wang. 2025. V-mage: A game evaluation framework for assessing vision-centric capabilities in multimodal large language models. arXiv preprint arXiv:2504.06148
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [73]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.