World Model Self-Distillation: Training World Models to Solve General Tasks
Pith reviewed 2026-06-27 10:14 UTC · model grok-4.3
The pith
Self-distillation from a VLM lets a video world model solve tasks from an image and short prompt alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
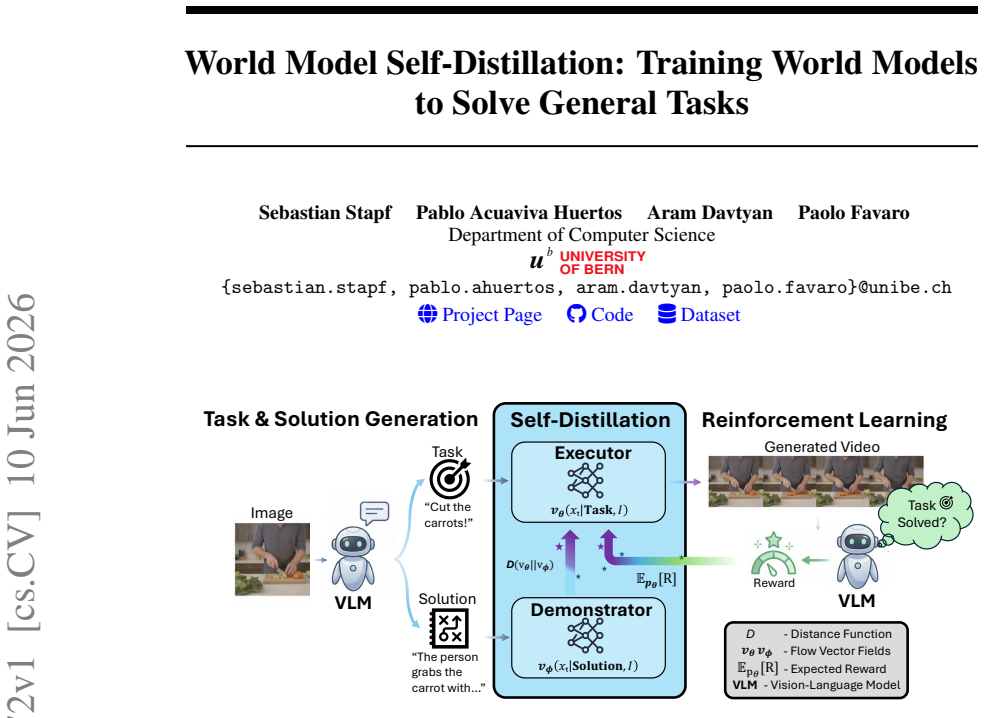
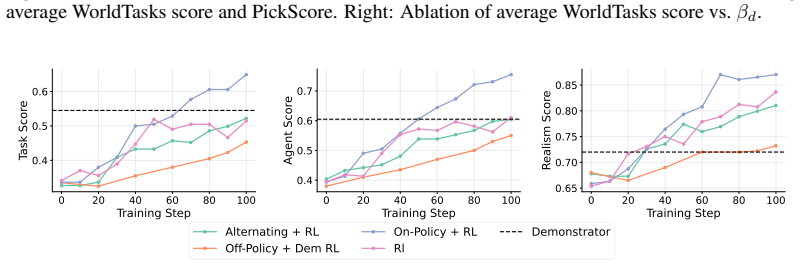
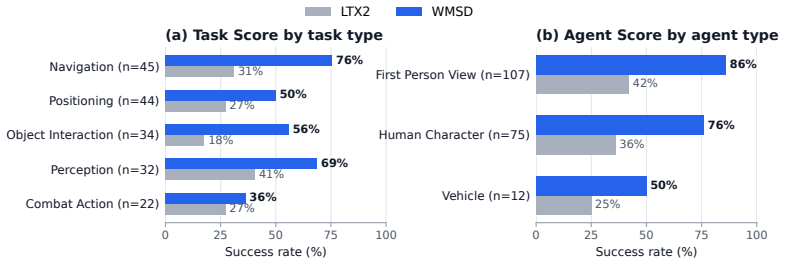
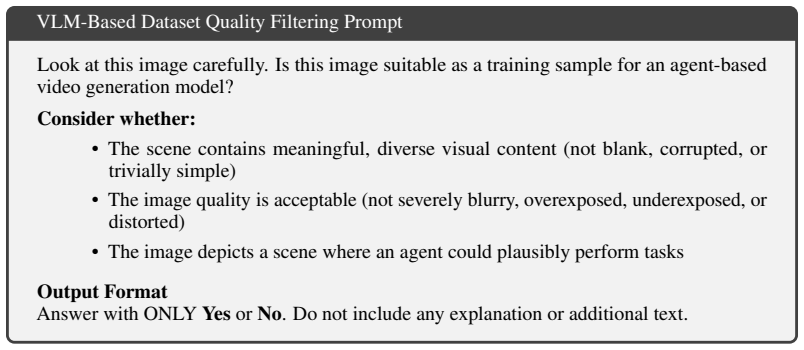
The central claim is that combining self-distillation with reinforcement learning elicits task-solving ability in pretrained video diffusion models: the Demonstrator generates videos from VLM-provided detailed solutions, its behavior is transferred to an Executor conditioned only on the scene image and short task prompt, and RL from VLM feedback on whether sampled videos satisfy the task produces an Executor that surpasses the Demonstrator on the WorldTasks-Benchmark while transferring competitively to the DreamGen robotics benchmark.
What carries the argument
The self-distillation pipeline that transfers execution knowledge from the caption-conditioned Demonstrator to the image-and-short-prompt Executor, combined with reinforcement learning that exploits the VLM's greater reliability at judging success than at generating solutions.
If this is right
- Task-solving training becomes possible from unlabeled scene images without collecting paired task-execution videos.
- The Executor can perform planning and decision-making directly from visual input and a short prompt without detailed textual descriptions.
- Reinforcement learning improves performance by leveraging the asymmetry between the VLM's judging and generating abilities.
- The resulting model transfers to robotic control tasks without additional robotics-specific supervision.
Where Pith is reading between the lines
- The approach could reduce dependence on separate language models for high-level reasoning in embodied agents.
- Similar distillation might unlock decision-making capabilities in other classes of generative models.
- Iterative self-improvement loops could be run online in deployed systems using only scene images as input.
- The method points toward world models that learn general skills from passive visual data at scale.
Load-bearing premise
The vision-language model can generate accurate step-by-step solutions from images and give reliable feedback for reinforcement learning that improves the Executor without introducing systematic errors or bias in task judgment.
What would settle it
An experiment in which videos rated successful by the VLM actually fail to complete the stated task when measured by human raters or physical robot execution, or where RL training guided by VLM feedback lowers performance on a held-out set of tasks.
Figures









read the original abstract
Pretrained video generators are promising visual world models that exhibit emergent task-solving abilities; however, their reliance on detailed textual descriptions limits their direct use for planning and decision-making. Existing approaches either outsource this reasoning to language or vision-language models, or rely on supervised fine-tuning with paired task-execution videos, which are costly to collect and difficult to scale. We propose a scalable framework that elicits task-solving ability in such models by combining self-distillation with reinforcement learning. Given an unlabeled scene image, a vision-language model generates a candidate task and a detailed step-by-step solution. The solution conditions a pretrained video diffusion model, the Demonstrator; we distill its behavior into an Executor conditioned only on the image and a short task prompt. This transfers execution knowledge from caption-guided generation to instruction-conditioned task solving without curated task-video supervision. We further improve the Executor with reinforcement learning from VLM feedback, exploiting the asymmetry between judging whether a sampled video satisfies a task and generating the solution. Experiments on our proposed WorldTasks-Benchmark and the DreamGen robotics benchmark show that the Executor surpasses the Demonstrator under our VLM-based evaluation protocol and transfers competitively to robotic tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes World Model Self-Distillation: a VLM generates candidate tasks and step-by-step solutions from unlabeled scene images; these condition a pretrained video diffusion model (Demonstrator). Behavior is distilled into an Executor conditioned only on the image plus a short task prompt. The Executor is then refined via reinforcement learning that uses VLM feedback on whether sampled videos satisfy the task. Experiments on the introduced WorldTasks-Benchmark and the DreamGen robotics benchmark report that the Executor surpasses the Demonstrator under the VLM evaluation protocol and transfers competitively to robotic tasks.
Significance. If the reported gains can be shown to reflect genuine task execution rather than VLM preference alignment, the framework would supply a scalable route to task-solving capabilities in video world models without requiring curated task-video pairs, with direct relevance to generalist planning and robotics applications.
major comments (3)
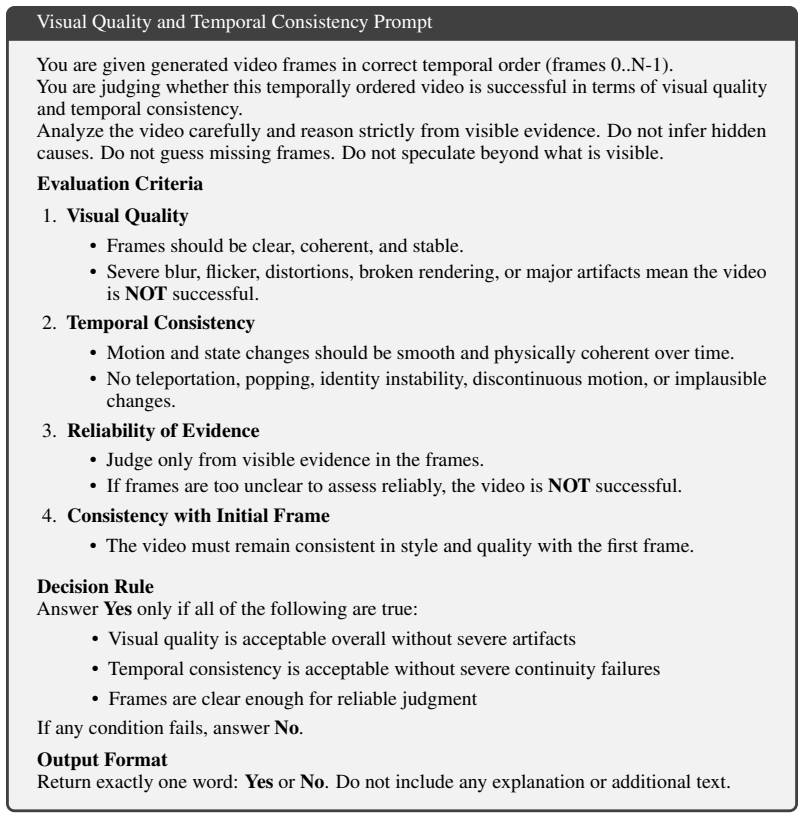
- [Abstract and §4] Abstract and §4 (Evaluation): The central claim that the Executor surpasses the Demonstrator rests exclusively on a VLM-based scoring protocol in which the same VLM supplies task generation, solution generation, RL reward, and final success judgment. No independent human-annotated validation set, physical-robot ground-truth metric, or cross-model evaluator is reported. This directly affects the abstract claim and the DreamGen transfer results; without such controls it is impossible to rule out that improvements arise from stylistic or caption-matching artifacts rather than execution capability.
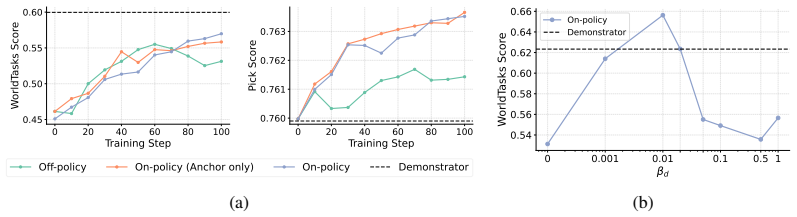
- [§3.3] §3.3 (RL from VLM Feedback): The asserted asymmetry between VLM generation and judgment is not quantified. No ablation isolates whether the VLM reward improves performance beyond the distillation baseline, nor is any analysis provided of reward noise, bias, or failure modes on the WorldTasks-Benchmark tasks.
- [Table 2 and §5.1] Table 2 and §5.1: Reported success rates for Executor vs. Demonstrator lack per-run standard deviations, confidence intervals, or statistical significance tests. The absence of these statistics makes it impossible to assess whether the claimed superiority is reliable or could be explained by variance.
minor comments (2)
- [Figure 1] Figure 1 caption and pipeline diagram: the distinction between the Demonstrator (caption-conditioned) and Executor (image+short-prompt) conditioning is visually clear but the exact conditioning tokens passed at inference time are not labeled.
- [Related Work] Related Work section: discussion of prior VLM-as-judge and self-distillation literature is present but omits several recent works on bias and calibration of VLM reward models.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, agreeing where revisions are needed to strengthen statistical reporting and ablations while defending the design choices around the VLM evaluation protocol. We outline specific changes for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] The central claim that the Executor surpasses the Demonstrator rests exclusively on a VLM-based scoring protocol in which the same VLM supplies task generation, solution generation, RL reward, and final success judgment. No independent human-annotated validation set, physical-robot ground-truth metric, or cross-model evaluator is reported.
Authors: We acknowledge the evaluation relies on a single consistent VLM protocol, which the abstract already qualifies as 'under our VLM-based evaluation protocol.' This enables scalable assessment without curated labels. We agree this cannot fully rule out VLM-specific artifacts. In revision we will expand §4 to discuss this limitation explicitly, add caveats on potential stylistic biases, and clarify DreamGen results use the same protocol but demonstrate competitive transfer. We do not have a human-annotated set available. revision: partial
-
Referee: [§3.3] The asserted asymmetry between VLM generation and judgment is not quantified. No ablation isolates whether the VLM reward improves performance beyond the distillation baseline, nor is any analysis provided of reward noise, bias, or failure modes on the WorldTasks-Benchmark tasks.
Authors: The asymmetry (judging success vs. generating detailed solutions) is foundational, but we agree it requires quantification. We will add an ablation in the revision comparing distillation-only vs. full RL Executor performance, plus analysis of reward consistency (e.g., inter-run agreement and example failure modes) on WorldTasks-Benchmark. These will be inserted in §3.3 and experiments. revision: yes
-
Referee: [Table 2 and §5.1] Reported success rates for Executor vs. Demonstrator lack per-run standard deviations, confidence intervals, or statistical significance tests.
Authors: We agree that variance measures are essential. The original runs support recomputation; we will add per-run standard deviations, 95% confidence intervals, and significance tests (e.g., paired t-tests) to Table 2 and §5.1 in the revision. revision: yes
- Independent human-annotated validation set or cross-model evaluator, as none was collected and creating one would require substantial new resources beyond the current scope.
Circularity Check
No circularity; empirical claims rest on external VLM asymmetry and benchmarks
full rationale
The paper's method generates tasks/solutions via VLM, conditions Demonstrator, distills to Executor, applies RL from VLM feedback, and evaluates via VLM protocol while claiming asymmetry between judgment and generation. No derivation step, equation, or prediction reduces by construction to its own inputs. No self-citation is load-bearing for uniqueness or ansatz. Results are presented as empirical comparisons on the authors' WorldTasks-Benchmark and external DreamGen benchmark. This is self-contained against external benchmarks with no exhibited reduction of the form Eq. X = Eq. Y or fitted parameter renamed as prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
From generation to generalization: Emergent few-shot learning in video diffusion models, 2025
Pablo Acuaviva, Aram Davtyan, Mariam Hassan, Sebastian Stapf, Ahmad Rahimi, Alexandre Alahi, and Paolo Favaro. From generation to generalization: Emergent few-shot learning in video diffusion models, 2025. URLhttps://arxiv.org/abs/2506.07280
-
[2]
Rethinking visual intelligence: Insights from video pretraining, 2025
Pablo Acuaviva, Aram Davtyan, Mariam Hassan, Sebastian Stapf, Ahmad Rahimi, Alexandre Alahi, and Paolo Favaro. Rethinking visual intelligence: Insights from video pretraining, 2025. URLhttps://arxiv.org/abs/2510.24448
-
[3]
On-policy distillation of language models: Learning from self-generated mistakes
R Agarwal, N Vieillard, Y Zhou, and P Stanczyk. On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representa- tions, 2024
2024
-
[4]
Concrete Problems in AI Safety
D Amodei, C Olah, J Steinhardt, and P Christiano. Concrete problems in ai safety.arXiv preprint arXiv:1606.06565, 2016. URLhttps://arxiv.org/abs/1606.06565
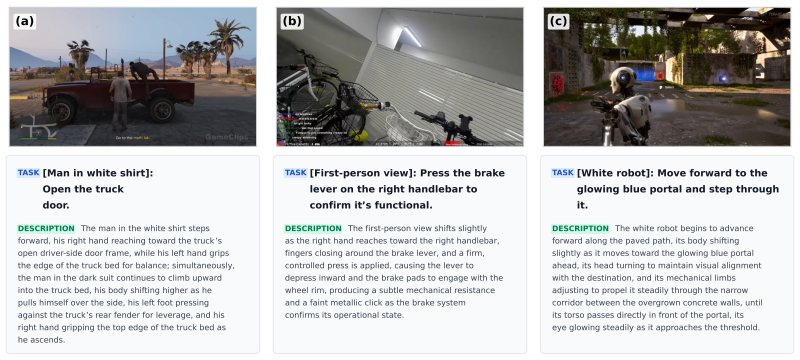
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Videophy: Evaluating physical commonsense for video generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=9D2QvO1uWj
2025
-
[6]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J Bjorck, F Castañeda, N Cherniadev, X Da, and R Ding. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. URL https: //arxiv.org/abs/2503.14734
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Training diffusion models with reinforce- ment learning
K Black, M Janner, Y Du, I Kostrikov, and S Levine. Training diffusion models with reinforce- ment learning. InInternational Conference on Learning Representations, 2024
2024
-
[8]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A Blattmann, T Dockhorn, S Kulal, and D Mendelevitch. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. URL https://arxiv.org/abs/2311.15127
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
RT-1: Robotics Transformer for Real-World Control at Scale
A Brohan, N Brown, J Carbajal, Y Chebotar, and J Dabis. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022. URL https://arxiv. org/abs/2212.06817. 13
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Genie: Generative interactive environments
J Bruce, MD Dennis, A Edwards, J Parker-Holder, and Y Shi. Genie: Generative interactive environments. InInternational Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=bJbSbJskOS
2024
-
[11]
Diffusion policy: Visuomotor policy learning via action diffusion, 2023
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion, 2023
2023
-
[12]
Deep reinforcement learning from human preferences
PF Christiano, J Leike, T Brown, M Martic, and S Legg. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, 2017
2017
-
[13]
Video language planning
Y Du, S Yang, P Florence, F Xia, A Wahid, and P Sermanet. Video language planning. In International Conference on Learning Representations, 2024
2024
-
[14]
Learning universal policies via text-guided video generation
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schu- urmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. InNeurIPS, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/ 1d5b9233ad716a43be5c0d3023cb82d0-Abstract-Conference.html
2023
-
[15]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models
Y Fan, O Watkins, Y Du, H Liu, M Ryu, and C Boutilier. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. InAdvances in Neural Information Processing Systems, 2023
2023
-
[16]
Born again neural networks
T Furlanello, Z Lipton, M Tschannen, and L Itti. Born again neural networks. InProceedings of Machine Learning Research, 2018
2018
-
[17]
Ziyu Guo, Xinyan Chen, Renrui Zhang, Ruichuan An, Yu Qi, Dongzhi Jiang, Xiangtai Li, Manyuan Zhang, Hongsheng Li, and Pheng-Ann Heng. Are video models ready as zero-shot reasoners? an empirical study with the mme-cof benchmark.ArXiv, abs/2510.26802, 2025
-
[18]
D Ha and J Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018. URL https://arxiv.org/abs/1803.10122
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Ltx-2: Efficient joint audio-visual foundation model, 2026
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Eitan Richardson, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Shahar Armon, V...
2026
-
[20]
Dream to Control: Learning Behaviors by Latent Imagination
D Hafner, T Lillicrap, J Ba, and M Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019. URL https://arxiv.org/abs/1912. 01603
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[21]
Learning latent dynamics for planning from pixels
D Hafner, T Lillicrap, I Fischer, R Villegas, D Ha, and H Lee. Learning latent dynamics for planning from pixels. InProceedings of Machine Learning Research, 2019
2019
-
[22]
Mariam Hassan, Sebastian Stapf, Ahmad Rahimi, Pedro M. B. Rezende, Yasaman Haghighi, David Brüggemann, Isinsu Katircioglu, Lin Zhang, Xiaoran Chen, Suman Saha, Marco Cannici, Elie Aljalbout, Botao Ye, Xi Wang, Aram Davtyan, Mathieu Salzmann, Davide Scaramuzza, Marc Pollefeys, Paolo Favaro, and Alexandre Alahi. Gem: A generalizable ego-vision multimodal wo...
2025
-
[23]
Pre-trained video generative models as world simulators.CoRR, abs/2502.07825, February 2025
Haoran He, Yang Zhang, Liang Lin, Zhongwen Xu, and Ling Pan. Pre-trained video generative models as world simulators.CoRR, abs/2502.07825, February 2025. URL https://doi.org/ 10.48550/arXiv.2502.07825
-
[24]
TempFlow-GRPO: When Timing Matters for GRPO in Flow Models
X He, S Fu, Y Zhao, W Li, J Yang, D Yin, and F Rao. Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324, 2025. URL https: //arxiv.org/abs/2508.04324. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Distilling the Knowledge in a Neural Network
G Hinton, O Vinyals, and J Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. URLhttps://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Denoising diffusion probabilistic models
J Ho, A Jain, and P Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, 2020
2020
-
[27]
Imagen Video: High Definition Video Generation with Diffusion Models
J Ho, W Chan, C Saharia, J Whang, R Gao, and A Gritsenko. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022. URL https: //arxiv.org/abs/2210.02303
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
W Hong, M Ding, W Zheng, X Liu, and J Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022. URL https://arxiv.org/abs/2205.15868
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Relic: Interactive video world model with long-horizon memory, 2025
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, Kalyan Sunkavalli, Feng Liu, Zhengqi Li, and Hao Tan. Relic: Interactive video world model with long-horizon memory, 2025. URL https://arxiv.org/abs/2512.04040
-
[30]
Vbench: Comprehensive benchmark suite for video generative models
Z Huang, Y He, J Yu, F Zhang, C Si, Y Jiang, and Y Zhang. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[31]
Reinforcement Learning via Self-Distillation
J Hübotter, F Lübeck, L Behric, and A Baumann. Reinforcement learning via self-distillation. arXiv preprint arXiv:2601.20802, 2026. URLhttps://arxiv.org/abs/2601.20802
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
DreamGen: Unlocking Generalization in Robot Learning through Video World Models
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, Loic Magne, Ajay Mandlekar, Avnish Narayan, You Liang Tan, Guanzhi Wang, Jing Wang, Qi Wang, Yinzhen Xu, Xiaohui Zeng, Kaiyuan Zheng, Ruijie Zheng, Ming-Yu Liu, Luke Zettlemoyer, Dieter Fox, Jan Kautz, Scott Reed, Yuke Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Distribution matching distillation meets reinforcement learning, 2026
D Jiang, D Liu, Z Wang, Q Wu, L Li, H Li, X Jin, and D Liu. Distribution matching distillation meets reinforcement learning.arXiv preprint arXiv:2511.13649, 2025. URL https://arxiv. org/abs/2511.13649
-
[34]
Miradata: A large-scale video dataset with long durations and structured captions
X Ju, Y Gao, Z Zhang, Z Yuan, X Wang, and A Zeng. Miradata: A large-scale video dataset with long durations and structured captions. InAdvances in Neural Information Processing Systems, 2024
2024
-
[35]
Pick-a-pic: An open dataset of user preferences for text-to-image generation
Y Kirstain, A Polyak, U Singer, S Matiana, and J Penna. Pick-a-pic: An open dataset of user preferences for text-to-image generation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[36]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W Kong, Q Tian, Z Zhang, R Min, Z Dai, J Zhou, and J Xiong. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. URL https://arxiv.org/abs/2412.03603
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
J Li, Y Cui, T Huang, Y Ma, C Fan, Y Cheng, and M Yang. Mixgrpo: Unlocking flow- based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025. URL https://arxiv.org/abs/2507.21802
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Flow Matching for Generative Modeling
Y Lipman, RTQ Chen, H Ben-Hamu, M Nickel, and M Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. URL https://arxiv.org/abs/2210. 02747
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Y Lipman, M Havasi, P Holderrieth, N Shaul, and M Le. Flow matching guide and code.arXiv preprint arXiv:2412.06264, 2024. URLhttps://arxiv.org/abs/2412.06264
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Flow-GRPO: Training flow matching models via online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di ZHANG, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online RL. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=oCBKGw5HNf. 15
2026
-
[41]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X Liu, C Gong, and Q Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. URL https://arxiv.org/abs/2209. 03003
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
S Luo, Y Tan, L Huang, J Li, and H Zhao. Latent consistency models: Synthesizing high- resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023. URL https://arxiv.org/abs/2310.04378
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA, :, Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, Daniel Dworakowski, Jiaojiao Fan, Michele Fenzi, Francesco Ferroni, Sanja Fidler, Dieter Fox, Songwei Ge, Yunhao Ge, Jinwei Gu, Siddharth Gururani, Ethan He, Jiahui Huang, Jacob Huffman, Pooya Jannaty, Ji...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Open x-embodiment: Robotic learn- ing datasets and rt-x models: Open x-embodiment collaboration 0
A O’Neill, A Rehman, A Maddukuri, and A Gupta. Open x-embodiment: Robotic learn- ing datasets and rt-x models: Open x-embodiment collaboration 0. InIEEE International Conference on Robotics and Automation, 2024
2024
-
[45]
Training language models to follow instructions with human feedback
L Ouyang, J Wu, X Jiang, D Almeida, and C Wainwright. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, 2022
2022
-
[46]
Vlp: Vision language planning for autonomous driving
C Pan, B Yaman, T Nesti, A Mallik, and AG Allievi. Vlp: Vision language planning for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[47]
arXiv preprint arXiv:2310.12921 (2023)
Juan Rocamonde, Victoriano Montesinos, Elvis Nava, Ethan Perez, and David Lindner. Vision-language models are zero-shot reward models for reinforcement learning.CoRR, abs/2310.12921, 2023. URLhttps://doi.org/10.48550/arXiv.2310.12921
-
[48]
A reduction of imitation learning and structured prediction to no-regret online learning
S Ross, G Gordon, and D Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of Machine Learning Research, 2011
2011
-
[49]
AA Rusu, SG Colmenarejo, C Gulcehre, and G Desjardins. Policy distillation.arXiv preprint arXiv:1511.06295, 2015. URLhttps://arxiv.org/abs/1511.06295
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[50]
Progressive Distillation for Fast Sampling of Diffusion Models
T Salimans and J Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022. URLhttps://arxiv.org/abs/2202.00512
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
Mastering atari, go, chess and shogi by planning with a learned model.Nature, 2020
J Schrittwieser, I Antonoglou, T Hubert, and K Simonyan. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 2020
2020
-
[52]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z Shao, P Wang, Q Zhu, R Xu, J Song, X Bi, and H Zhang. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Self-Distillation Enables Continual Learning
I Shenfeld, M Damani, J Hübotter, and P Agrawal. Self-distillation enables continual learning. arXiv preprint arXiv:2601.19897, 2026. URLhttps://arxiv.org/abs/2601.19897
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Mind the gap: Examining the self- improvement capabilities of large language models
Y Song, H Zhang, C Eisenach, S Kakade, and D Foster. Mind the gap: Examining the self- improvement capabilities of large language models. InInternational Conference on Learning Representations, 2025
2025
-
[55]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InICML, pages 32211–32252, 2023. 16
2023
-
[56]
Composition of Memory Experts for Diffusion World Models
S Stapf, PA Huertos, A Davtyan, and P Favaro. Composition of memory experts for diffusion world models.arXiv preprint arXiv:2605.18813, 2026. URL https://arxiv.org/abs/ 2605.18813
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Learning to summarize with human feedback
N Stiennon, L Ouyang, J Wu, D Ziegler, and R Lowe. Learning to summarize with human feedback. InAdvances in Neural Information Processing Systems, 2020
2020
-
[58]
Richard S. Sutton. First results with dyna, an integrated architecture for learning, planning and reacting. InNeural Networks for Control. MIT Press, 1991. URL https://doi.org/10. 7551/mitpress/4939.003.0012
1991
-
[59]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[60]
Technical report
URLhttps://qwen.ai/blog?id=qwen3.5. Technical report
-
[61]
HunyuanVideo 1.5 Technical Report
Tencent Hunyuan Foundation Model Team. Hunyuanvideo 1.5 technical report, 2025. URL https://arxiv.org/abs/2511.18870
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Diffusion model alignment using direct preference optimization
B Wallace, M Dang, R Rafailov, L Zhou, and A Lou. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[63]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
A very big video reasoning suite, 2026
Maijunxian Wang, Ruisi Wang, Juyi Lin, Ran Ji, Thaddäus Wiedemer, Qingying Gao, Dezhi Luo, Yaoyao Qian, Lianyu Huang, Zelong Hong, Jiahui Ge, Qianli Ma, Hang He, Yifan Zhou, Lingzi Guo, Lantao Mei, Jiachen Li, Hanwen Xing, Tianqi Zhao, Fengyuan Yu, Weihang Xiao, Yizheng Jiao, Jianheng Hou, Danyang Zhang, Pengcheng Xu, Boyang Zhong, Zehong Zhao, Gaoyun Fan...
-
[65]
Y Wang, Z Sun, J Zhang, Z Xian, E Biyik, and D Held. Rl-vlm-f: Reinforcement learning from vision language foundation model feedback.arXiv preprint arXiv:2402.03681, 2024. URL https://arxiv.org/abs/2402.03681
-
[66]
Video models are zero-shot learners and reasoners,
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners,
-
[67]
URLhttps://arxiv.org/abs/2509.20328
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
RJ Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine Learning, 1992. doi: 10.1007/BF00992696. URL https://link. springer.com/article/10.1007/bf00992696
-
[69]
S Xue, C Ge, S Zhang, Y Li, and ZM Ma. Advantage weighted matching: Aligning rl with pretraining in diffusion models.arXiv preprint arXiv:2509.25050, 2025. URL https: //arxiv.org/abs/2509.25050
-
[70]
DanceGRPO: Unleashing GRPO on Visual Generation
Z Xue, J Wu, Y Gao, F Kong, L Zhu, M Chen, and Z Liu. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025. URL https://arxiv.org/abs/ 2505.07818. 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
One-step diffusion with distribution matching distillation
T Yin, M Gharbi, R Zhang, E Shechtman, and F Durand. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[72]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[73]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
K Zheng, H Chen, H Ye, H Wang, Q Zhang, and K Jiang. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025. URL https: //arxiv.org/abs/2509.16117
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
B Zitkovich, T Yu, S Xu, P Xu, T Xiao, F Xia, and J Wu. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InProceedings of Machine Learning Research, 2023. A Technical appendices and supplementary material A.1 Further Implementation Details In Tab. 3, we report the hyperparameters used for self-distilling LTX-2 and HunyuanVide...
-
[75]
Task 1:[Man in blue shirt]: Step onto the yellow lane marking and stop exactly at the white arrow’s tip. Description 1:The man in the blue shirt begins walking forward along the center of the road, his feet deliberately stepping onto the double yellow lane marking, and continues moving straight ahead until he reaches the tip of the white directional arrow...
-
[76]
Task 2:[Person in blue shirt]: Move for- ward to the nearest building. Description 2:The person in the blue shirt begins walking forward along the center of the road, maintaining a steady pace toward the building on the left side of the street, their body oriented directly ahead as they cross the yellow double lines; after a few steps, they continue movin...
-
[77]
Task 1:[Character with horned helmet]: Use the bow to aim at the tree trunk di- rectly ahead. Description 1:The character with the horned helmet slowly turns their upper body toward the tree trunk directly ahead, simultaneously drawing the bowstring back with their right hand while keeping their left hand steady on the bow’s grip, their gaze fixed on the ...
-
[78]
Task 2:[Character with horned helmet]: Move to the largest boulder and stop be- side its left edge. Description 2:The character with the horned helmet begins walking forward along the stone path, their body oriented toward the largest boulder visible to the left, and after a few steps, they decelerate, shifting their weight slightly as they turn their hea...
-
[79]
Task 1:[Driver in racing suit]: Press the red button on the steering wheel’s right side. Description 1:The driver’s right hand, clad in a black racing glove, moves slightly forward and inward, pressing the red button located on the right side of the steering wheel, while the left hand re- mains steady on the left side of the wheel, and the vehicle continu...
-
[80]
Task 2:[First-person view]: Align the car’s front bumper with the white track curb ahead. Description 2:The driver’s hands grip the steering wheel firmly, thumbs press- ing the paddle shifters while the left hand subtly adjusts its position to maintain con- trol; simultaneously, the right hand makes a slight inward rotation of the wheel to ini- tiate a ge...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.