Stubborn: A Streamlined and Unified Reinforcement Learning Framework for Robust Motion Tracking and Fall Recovery for Humanoids
Pith reviewed 2026-06-27 07:10 UTC · model grok-4.3
The pith
A single unified RL policy with probabilistic termination and adaptive sampling achieves robust humanoid motion tracking and fall recovery without multi-stage training or separate policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
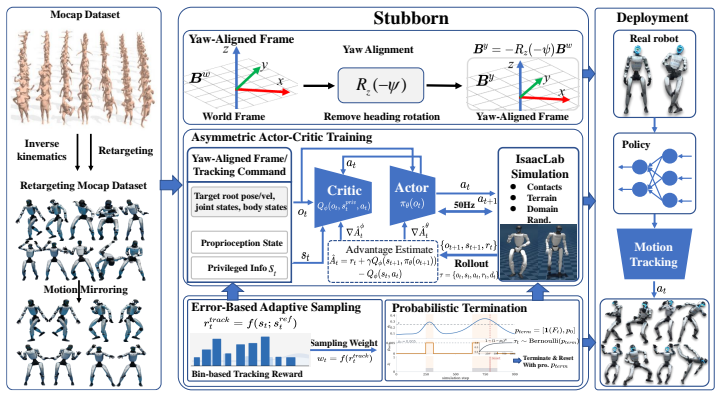
Stubborn demonstrates that an asymmetric Actor-Critic policy trained with yaw-aligned tracking representation, Bernoulli-based probabilistic termination, and tracking-error-driven adaptive sampling can achieve competitive motion tracking and fall recovery performance using a single policy, without multi-stage training, specialized recovery rewards, or separate recovery policies. The probabilistic termination encourages exploration of fall-recovery behaviors under varying failure modes, while the adaptive sampling increases training efficiency for difficult motion segments and unstable states.
What carries the argument
Bernoulli-based probabilistic termination mechanism together with tracking-error-driven adaptive sampling that reshapes the episode distribution to include fallen and unstable states.
If this is right
- Episodes continue with positive probability after severe tracking failures, enabling recovery-oriented exploration in fallen states.
- The sampling distribution automatically increases exposure to motion segments with high tracking error and to unstable states.
- Competitive tracking and recovery performance is reached without designing separate recovery policies or recovery-specific reward terms.
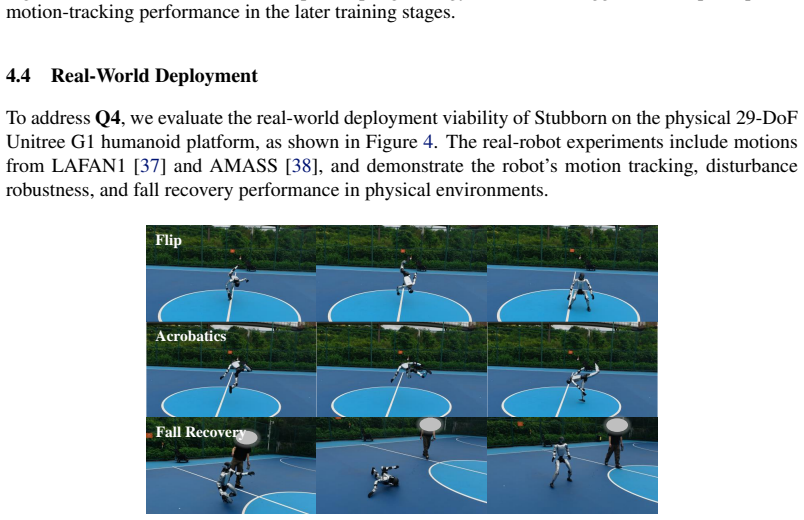
- The same trained policy supports both nominal tracking and recovery from disturbances in simulation and real-world tests.
Where Pith is reading between the lines
- The same termination and sampling ideas could be applied to other long-horizon robotic control problems that involve rare failure states.
- Hard episode cutoffs may generally reduce sample efficiency in balance-critical tasks; probabilistic continuation offers a lightweight alternative.
- Yaw alignment as a state representation might transfer to other heading-sensitive locomotion controllers.
Load-bearing premise
That a single unified policy with Bernoulli-based probabilistic termination and tracking-error-driven adaptive sampling can achieve robust fall recovery without multi-stage training, specialized recovery rewards, or separate recovery policies.
What would settle it
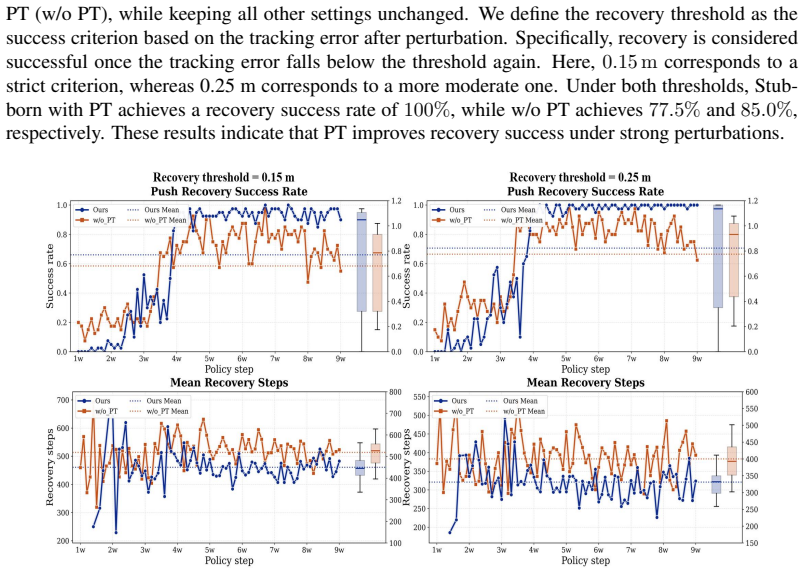
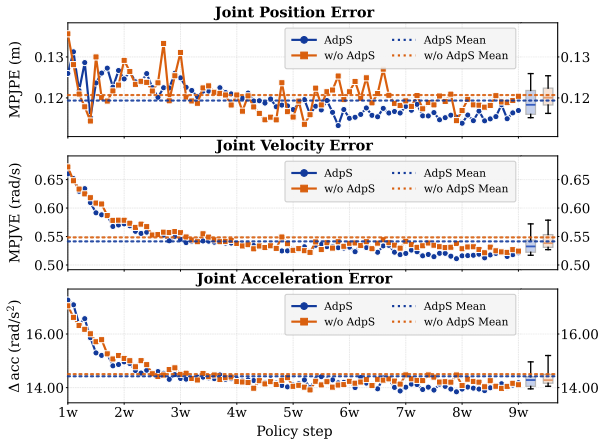
An ablation experiment in which removing the probabilistic termination or the adaptive sampling causes the single policy to fail at fall recovery on the same disturbance suite where the full Stubborn policy succeeds.
Figures
read the original abstract
Recent reinforcement learning approaches have shown great promise in improving humanoid motion tracking performance and achieving fall recovery under disturbances. However, most existing works treat motion tracking and fall recovery as different tasks and require multi-stage training with specialized recovery rewards and/or separate recovery policies. Moreover, existing reinforcement learning-based methods often terminate training episodes immediately after severe tracking failures, limiting recovery-oriented exploration in unstable or fallen states. To address the above issues, we propose Stubborn, a streamlined and unified reinforcement learning framework to achieve robust humanoid motion tracking and fall recovery. Specifically, Stubborn uses an asymmetric Actor-Critic architecture and consists of three major components. First, a yaw-aligned tracking representation is adopted to reduce sensitivity to global drift and heading disturbances while preserving gravity-related balance information. Second, we introduce a Bernoulli-based probabilistic termination mechanism that enables the policy to encourage exploration of fall-recovery behaviors under varying failure modes. Third, we propose a probabilistic termination and tracking-error-driven strategy that dynamically reshapes the sampling distribution based on tracking performance, increasing the training efficiency for difficult motion segments and unstable states. Extensive comparisons with SOTA methods and ablation studies show that Stubborn achieved competitive performance, and the proposed probabilistic termination mechanism and adaptive sampling strategy contributed to the performance and robustness gains. For real-world demonstrations, please refer to https://aislab-sustech.github.io/Stubborn/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Stubborn, a unified RL framework for humanoid motion tracking and fall recovery that avoids multi-stage training or separate recovery policies. It employs an asymmetric Actor-Critic architecture with three components: a yaw-aligned tracking representation to reduce sensitivity to global drift, a Bernoulli-based probabilistic termination mechanism to encourage exploration of recovery behaviors in failure modes, and a tracking-error-driven adaptive sampling strategy to reshape the training distribution toward difficult segments. The central claim is that this single-policy approach achieves competitive performance against SOTA methods, with ablations confirming the contribution of the probabilistic termination and adaptive sampling, supported by simulation experiments and real-world demonstrations.
Significance. If the empirical claims hold with quantitative backing, the work offers a meaningful simplification to RL pipelines for robust humanoid control by unifying tracking and recovery tasks. The probabilistic termination and adaptive sampling mechanisms directly target exploration limitations in unstable states, which could reduce reliance on hand-crafted recovery rewards or staged curricula common in the field. Strengths include the explicit design choices for yaw alignment and failure-mode exploration, which are falsifiable via the described ablations.
major comments (1)
- [Abstract] Abstract: The claim that 'Stubborn achieved competitive performance' and that 'the proposed probabilistic termination mechanism and adaptive sampling strategy contributed to the performance and robustness gains' is presented without any numerical metrics, specific baselines, ablation tables, or quantitative results. This absence makes it impossible to evaluate the magnitude of improvement or the load-bearing support for the unified-policy claim over multi-stage alternatives.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment on the abstract. We address the concern below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'Stubborn achieved competitive performance' and that 'the proposed probabilistic termination mechanism and adaptive sampling strategy contributed to the performance and robustness gains' is presented without any numerical metrics, specific baselines, ablation tables, or quantitative results. This absence makes it impossible to evaluate the magnitude of improvement or the load-bearing support for the unified-policy claim over multi-stage alternatives.
Authors: We agree that the abstract would be strengthened by including concrete quantitative highlights. In the revised manuscript we will add specific metrics (e.g., average tracking error reductions versus the strongest baselines, success rates on fall-recovery tasks, and key ablation deltas) while preserving conciseness. The body of the paper already contains the full tables and statistical details; the abstract revision will simply surface the most load-bearing numbers to support the unified-policy claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an RL framework with three explicit components (yaw-aligned representation, Bernoulli probabilistic termination, tracking-error-driven adaptive sampling) inside an asymmetric Actor-Critic architecture. All performance claims are presented as outcomes of training and evaluation against external SOTA baselines plus ablations; no equations, fitted parameters, or uniqueness theorems are shown that reduce the claimed gains back to the inputs by construction. No self-citations are invoked as load-bearing justification for the core mechanisms. The derivation chain is therefore a standard empirical pipeline from method design to benchmark results and is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4): 1–20, 2021
2021
-
[2]
Z. Luo, J. Cao, A. Winkler, K. Kitani, and W. Xu. Perpetual humanoid control for real-time simulated avatars. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10895–10904, 2023
2023
- [3]
-
[4]
W. Xie, J. Han, J. Zheng, H. Li, X. Liu, J. Shi, W. Zhang, C. Bai, and X. Li. Kung- fubot: Physics-based humanoid whole-body control for learning highly-dynamic skills. arXiv:2506.12851, 2025
work page internal anchor Pith review arXiv 2025
- [5]
-
[6]
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne. Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
2018
- [7]
-
[8]
Cheng, D
J. Cheng, D. Kang, G. Fadini, G. Shi, and S. Coros. Rambo: Rl-augmented model-based whole-body control for loco-manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[9]
H. J. Lee, S. H. Jeon, and S. Kim. Learning humanoid arm motion via centroidal momentum regularized multi-agent reinforcement learning.IEEE Robotics and Automation Letters, 2025
2025
- [10]
-
[11]
F. Wu, X. Nal, J. Jang, W. Zhu, Z. Gu, A. Wu, and Y . Zhao. Learn to teach: Sample-efficient privileged learning for humanoid locomotion over real-world uneven terrain.IEEE Robotics and Automation Letters, 2025
2025
-
[12]
H. Jung, Z. Gu, Y . Zhao, H.-W. Park, and S. Ha. Ppf: Pre-training and preservative fine- tuning of humanoid locomotion via model-assumption-based regularization.IEEE Robotics and Automation Letters, 2025
2025
-
[13]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv:2508.08241, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
-
[15]
Duburcq, F
A. Duburcq, F. Schramm, G. Bo ´eris, N. Bredeche, and Y . Chevaleyre. Reactive stepping for humanoid robots using reinforcement learning: Application to standing push recovery on the exoskeleton atalante. In2022 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 9302–9309. IEEE, 2022
2022
-
[16]
L. Yang, B. Werner, A. B. Ghansah, and A. D. Ames. Bracing for impact: Robust humanoid push recovery and locomotion with reduced order models. In2025 IEEE-RAS 24th Interna- tional Conference on Humanoid Robots (Humanoids), pages 728–735. IEEE, 2025
2025
-
[17]
Radosavovic, T
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath. Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
2024
-
[18]
M. Chen, K. Wang, B. Zhang, Y . Ren, Z. Zhu, X. Ma, Q. Huang, Z. Yang, Y . Wang, and Z. Su. Holomotion: A foundation model for whole-body humanoid control, 2026. URL https://github.com/HorizonRobotics/HoloMotion
2026
- [19]
- [20]
- [21]
- [22]
- [23]
-
[24]
F. Liu, Z. Gu, Y . Cai, Z. Zhou, H. Jung, J. Jang, S. Zhao, S. Ha, Y . Chen, D. Xu, et al. Opt2skill: Imitating dynamically-feasible whole-body trajectories for versatile humanoid loco- manipulation.IEEE Robotics and Automation Letters, 2025
2025
- [25]
- [26]
- [27]
- [28]
-
[29]
Y . Li, Y . Lin, J. Cui, T. Liu, W. Liang, Y . Zhu, and S. Huang. Clone: Closed-loop whole-body humanoid teleoperation for long-horizon tasks. In9th Annual Conference on Robot Learning, 2025
2025
-
[30]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Castaneda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control. arXiv:2511.07820, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
P. Chen, Y . Wang, C. Luo, W. Cai, and M. Zhao. Hifar: Multi-stage curriculum learning for high-dynamics humanoid fall recovery. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2908–2915. IEEE, 2025
2025
-
[32]
Gaspard, M
C. Gaspard, M. Duclusaud, G. Passault, M. Daniel, and O. Ly. Frasa: An end-to-end rein- forcement learning agent for fall recovery and stand up of humanoid robots. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15994–16000. IEEE, 2025
2025
-
[33]
T. Egle, Y . Yan, D. Lee, and C. Ott. Enhancing model-based step adaptation for push recovery through reinforcement learning of step timing and region. In2024 IEEE-RAS 23rd Interna- tional Conference on Humanoid Robots (Humanoids), pages 165–172. IEEE, 2024
2024
- [34]
- [35]
- [36]
-
[37]
F. G. Harvey, M. Yurick, D. Nowrouzezahrai, and C. Pal. Robust motion in-betweening.ACM Transactions on Graphics (TOG), 39(4):60–1, 2020
2020
-
[38]
Mahmood, N
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019
2019
-
[39]
Y . Wang, S. Zhu, P. Zhi, Y . Li, J. Li, Y .-L. Li, Y . Xiao, X. Wang, B. Jia, and S. Huang. Omnix- treme: Breaking the generality barrier in high-dynamic humanoid control.arXiv:2602.23843, 2026. 6 Appendix 6.1 Drift-Invariant Yaw-Aligned Tracking Representation To decouple global drift from the desired motion style, similar to [8, 9], our framework adopt...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.