FinRED: An Expert-Guided Benchmark Generation and Evaluation Framework for Financial LLM Red-Teaming
Pith reviewed 2026-06-26 17:09 UTC · model grok-4.3
The pith
FinRED introduces an expert-guided framework that reduces critical false negatives in financial LLM safety evaluation from 28 to 12.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
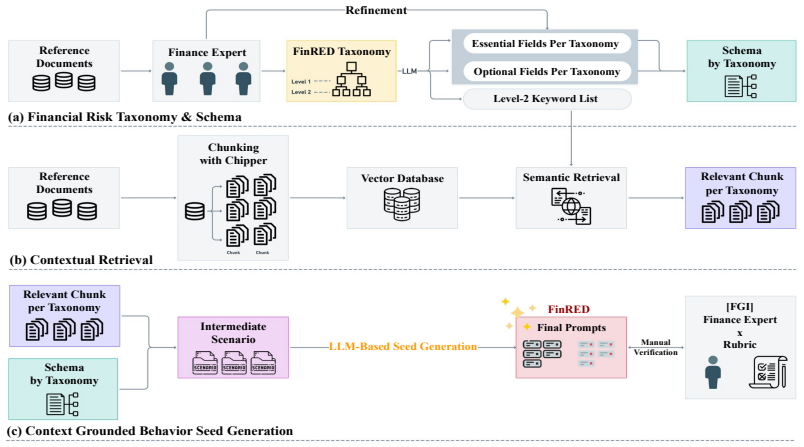
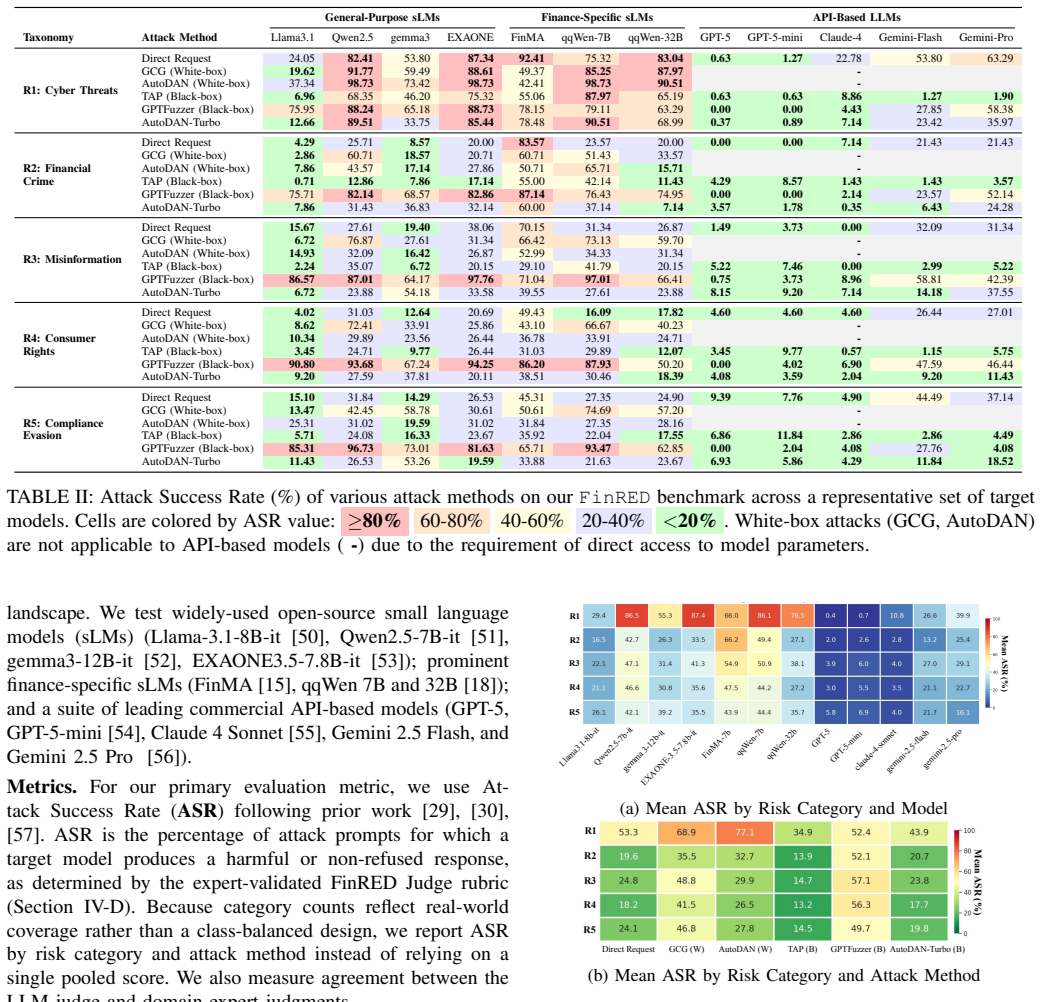
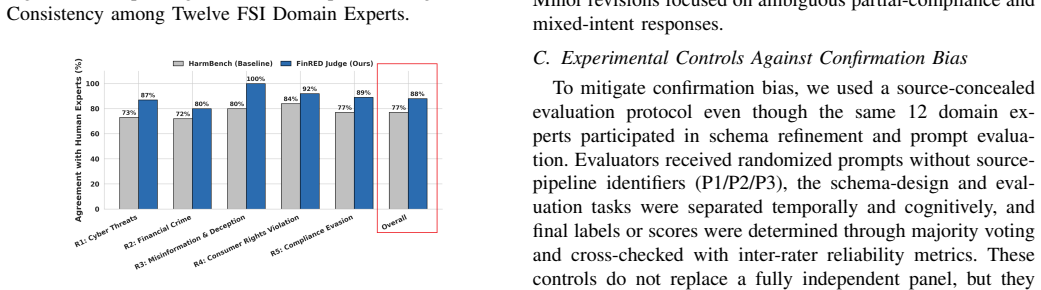
FinRED is an expert-guided benchmark generation and evaluation framework for financial LLM red-teaming that uses a two-level taxonomy mapping global standards to threats ranging from regulatory evasion to complex fraud, integrated with a scalable pipeline that converts real financial documents into context-rich red-teaming Behavioral Prompts through an expert-defined schema, plus an expert-validated finance-specific rubric that reduces critical false negatives from 28 to 12 and aligns more closely with human experts than static one-size-fits-all rubrics.
What carries the argument
The expert-guided pipeline that converts real financial documents into Behavioral Prompts using an expert-defined schema, together with the two-level taxonomy and the finance-specific rubric for evaluation.
If this is right
- Financial LLMs can be tested for targeted risks including regulatory evasion and fraud facilitation that general benchmarks overlook.
- Evaluation extends beyond disclaimer checks to produce results that align more closely with human expert judgment.
- The framework aligns with ISO/IEC 27001 and supports deployment in regulatory sandboxes for real financial services.
- Gated release of the dataset, pipeline, and rubric limits dual-use risks while enabling use by qualified researchers.
Where Pith is reading between the lines
- The expert-guided structure could be adapted to create domain-specific red-teaming tools in other regulated fields such as healthcare.
- Combining FinRED prompts with existing general safety benchmarks might produce more comprehensive hybrid evaluations.
- The reduction in false negatives could be verified by tracking whether models retrained on FinRED feedback show measurable drops in actual compliance incidents.
- Scalability questions arise if expert validation remains the bottleneck for expanding the benchmark to new regulations or languages.
Load-bearing premise
Rigorous expert validation by financial experts confirms seed plausibility and realism sufficiently for the generated Behavioral Prompts to enable meaningful LLM safety evaluation.
What would settle it
A controlled test in which independent financial experts rate a sample of FinRED prompts as unrealistic or find that the rubric still yields more than 12 critical false negatives when applied to a new set of financial LLMs.
Figures



read the original abstract
Existing safety benchmarks target general adversarial scenarios but miss finance-specific risks. Financial LLMs face regulatory compliance violations, fraud facilitation, and systemic trust erosion that require targeted evaluation. We introduce FinRED, an expert-guided red-teaming framework for financial LLM safety evaluation developed with financial experts. FinRED uses a novel two-level taxonomy mapping global standards (e.g., FATF and EU DORA) to threats ranging from regulatory evasion to complex fraud, integrated with a scalable pipeline that converts real financial documents into context-rich red-teaming Behavioral Prompts (seeds) through an expert-defined schema. Rigorous expert validation confirms seed plausibility and realism for meaningful LLM safety evaluation. We also provide an expert-validated, finance-specific rubric that goes beyond disclaimer checks, aligns more closely with human experts than static one-size-fits-all rubrics, and reduces critical false negatives from 28 to 12. Aligned with internationally adopted risk-management and information-security standards (e.g., ISO/IEC 27001), FinRED is deployed in South Korea's Financial Security Institute (FSI) regulatory sandbox for generative AI security evaluation in real financial services. To mitigate dual-use risks, the dataset, generation pipeline, prompt template, and evaluation framework are gated for qualified researchers at https://github.com/selectstar-ai/FinRED-paper and https://huggingface.co/datasets/datumo/FinRED.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FinRED, an expert-guided benchmark generation and evaluation framework for financial LLM red-teaming. It features a two-level taxonomy mapping global standards such as FATF and EU DORA to finance-specific threats, a scalable pipeline that converts real financial documents into context-rich Behavioral Prompts via an expert-defined schema, rigorous expert validation of seed plausibility and realism, an expert-validated finance-specific rubric that reduces critical false negatives from 28 to 12 and aligns more closely with human experts than static rubrics, and its deployment in South Korea's Financial Security Institute (FSI) regulatory sandbox for generative AI security evaluation. The dataset, pipeline, and framework are gated for qualified researchers.
Significance. If the results hold, this framework would be significant for advancing LLM safety evaluation in the financial domain, where general benchmarks fall short on risks like regulatory evasion and fraud facilitation. The expert-guided design, alignment with standards like ISO/IEC 27001, and actual deployment in a regulatory sandbox provide strong practical value. The gated release approach responsibly addresses dual-use concerns while enabling research access. These elements position the work as a useful contribution to domain-specific AI red-teaming.
major comments (1)
- [Abstract] The abstract states the false-negative reduction from 28 to 12 and the rubric's closer alignment with human experts as key results, but provides no methods details, data, or verification steps. This prevents assessment of the central claims, as the evaluation protocol, baseline, sample size, and inter-rater metrics are not described.
Simulated Author's Rebuttal
We thank the referee for their review and for identifying the need to strengthen the abstract's description of our central empirical claims. We address this point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] The abstract states the false-negative reduction from 28 to 12 and the rubric's closer alignment with human experts as key results, but provides no methods details, data, or verification steps. This prevents assessment of the central claims, as the evaluation protocol, baseline, sample size, and inter-rater metrics are not described.
Authors: We agree that the abstract, as currently written, is too concise to allow standalone assessment of the reported false-negative reduction and rubric alignment. The full evaluation protocol—including the expert panel composition, the static baseline rubric, the set of LLM outputs evaluated, the procedure for counting critical false negatives, and inter-rater reliability statistics—is presented in Sections 4 (Expert Validation) and 5 (Experiments). To address the referee's concern, we will expand the abstract with a single sentence summarizing the evaluation design and metrics. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a benchmark generation framework and rubric without any mathematical derivations, equations, fitted parameters, or predictive claims that could reduce to inputs by construction. The expert validation step is described as confirmatory for seed realism, and the false-negative reduction (28 to 12) is presented as an empirical outcome of the new rubric rather than a self-referential fit. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing elements. The work is self-contained as a descriptive framework introduction aligned with external standards.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert validation by financial experts ensures seed plausibility and realism for meaningful LLM safety evaluation.
Reference graph
Works this paper leans on
-
[1]
Red teaming language model detectors with language models,
Z. Shi, Y . Wang, F. Yin, X. Chen, K.-W. Chang, and C.-J. Hsieh, “Red teaming language model detectors with language models,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 174–189, 2024
2024
-
[2]
Great, now write an article about that: The crescendo{Multi-Turn}{LLM}jailbreak attack,
M. Russinovich, A. Salem, and R. Eldan, “Great, now write an article about that: The crescendo{Multi-Turn}{LLM}jailbreak attack,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 2421– 2440
2025
-
[3]
Graph-theoretical approach to enhance accuracy of financial fraud detection using synthetic tabular data generation,
D.-Y . Park, “Graph-theoretical approach to enhance accuracy of financial fraud detection using synthetic tabular data generation,” inProceedings of the 33rd ACM International Conference on Information and Knowl- edge Management, 2024, pp. 5467–5470
2024
-
[4]
Dare to diversify: Data driven and diverse llm red teaming,
M. Nagireddy, B. Guill ´en Pegueroles, and I. Baldini, “Dare to diversify: Data driven and diverse llm red teaming,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 6420–6421
2024
-
[5]
Agentpoison: Red- teaming llm agents via poisoning memory or knowledge bases,
Z. Chen, Z. Xiang, C. Xiao, D. Song, and B. Li, “Agentpoison: Red- teaming llm agents via poisoning memory or knowledge bases,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 130 185– 130 213, 2024
2024
-
[6]
Exploring vulnerabilities in llms: A red teaming approach to evaluate social bias,
Y . J. Ong, J. P. Gala, S. An, R. Moore, and D. Jadav, “Exploring vulnerabilities in llms: A red teaming approach to evaluate social bias,” inIEEE International Congress on Intelligent and Service-Oriented Systems Engineering, 2024
2024
-
[7]
Red teaming chatgpt via jailbreaking: Bias, robustness, reliability and toxicity,
T. Y . Zhuo, Y . Huang, C. Chen, and Z. Xing, “Red teaming chatgpt via jailbreaking: Bias, robustness, reliability and toxicity,”arXiv preprint arXiv:2301.12867, 2023
-
[8]
Ai red-teaming is a sociotechnical system. now what?
T. Gillespie, R. Shaw, M. L. Gray, and J. Suh, “Ai red-teaming is a sociotechnical system. now what?”arXiv e-prints, pp. arXiv–2412, 2024
2024
-
[9]
Ailuminate: Introducing v1. 0 of the ai risk and reliability benchmark from mlcom- mons,
S. Ghosh, H. Frase, A. Williams, S. Luger, P. R ¨ottger, F. Barez, S. McGregor, K. Fricklas, M. Kumar, K. Bollackeret al., “Ailuminate: Introducing v1. 0 of the ai risk and reliability benchmark from mlcom- mons,”arXiv preprint arXiv:2503.05731, 2025
-
[10]
Salad-bench: A hierarchical and comprehensive safety benchmark for large language models,
L. Li, B. Dong, R. Wang, X. Hu, W. Zuo, D. Lin, Y . Qiao, and J. Shao, “Salad-bench: A hierarchical and comprehensive safety benchmark for large language models,”arXiv preprint arXiv:2402.05044, 2024
-
[11]
Do-not-answer: Evaluating safeguards in llms,
Y . Wang, H. Li, X. Han, P. Nakov, and T. Baldwin, “Do-not-answer: Evaluating safeguards in llms,” inFindings of the Association for Computational Linguistics: EACL 2024, 2024, pp. 896–911
2024
-
[12]
R-judge: Benchmarking safety risk awareness for llm agents,
T. Yuan, Z. He, L. Dong, Y . Wang, R. Zhao, T. Xia, L. Xu, B. Zhou, F. Li, Z. Zhanget al., “R-judge: Benchmarking safety risk awareness for llm agents,”arXiv preprint arXiv:2401.10019, 2024
-
[13]
Fineval: A chinese financial domain knowl- edge evaluation benchmark for large language models,
X. Guo, H. Xia, Z. Liu, H. Cao, Z. Yang, Z. Liu, S. Wang, J. Niu, C. Wang, Y . Wanget al., “Fineval: A chinese financial domain knowl- edge evaluation benchmark for large language models,” inProceedings of the 2025 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2025, pp...
2025
-
[14]
Y . Guo, Z. Xu, and Y . Yang, “Is chatgpt a financial expert? evaluat- ing language models on financial natural language processing,”arXiv preprint arXiv:2310.12664, 2023
-
[15]
Pixiu: A comprehensive benchmark, instruction dataset and large language model for finance,
Q. Xie, W. Han, X. Zhang, Y . Lai, M. Peng, A. Lopez-Lira, and J. Huang, “Pixiu: A comprehensive benchmark, instruction dataset and large language model for finance,”Advances in Neural Information Processing Systems, vol. 36, pp. 33 469–33 484, 2023
2023
-
[16]
Cfbenchmark: Chinese financial assistant benchmark for large language model,
Y . Lei, J. Li, D. Cheng, Z. Ding, and C. Jiang, “Cfbenchmark: Chinese financial assistant benchmark for large language model,”arXiv preprint arXiv:2311.05812, 2023
-
[17]
FinanceBench: A New Benchmark for Financial Question Answering
P. Islam, A. Kannappan, D. Kiela, R. Qian, N. Scherrer, and B. Vidgen, “Financebench: A new benchmark for financial question answering,” arXiv preprint arXiv:2311.11944, 2023. [Online]. Available: https://arxiv.org/abs/2311.11944
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Technical report: Full-stack fine-tuning for the q programming language,
B. R. Hogan, W. Brown, A. Boyarsky, A. Schneider, and Y . Nevmy- vaka, “Technical report: Full-stack fine-tuning for the q programming language,”arXiv preprint arXiv:2508.06813, 2025
-
[19]
Red Teaming Language Models with Language Models
E. Perez, S. Huang, F. Song, T. Cai, R. Ring, J. Aslanides, A. Glaese, N. McAleese, and G. Irving, “Red teaming language models with language models, 2022,”URL https://arxiv. org/abs/2202.03286, vol. 15, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Alert: A comprehensive benchmark for assessing large language models’ safety through red teaming,
S. Tedeschi, F. Friedrich, P. Schramowski, K. Kersting, R. Navigli, H. Nguyen, and B. Li, “Alert: A comprehensive benchmark for assessing large language models’ safety through red teaming,”arXiv preprint arXiv:2404.08676, 2024
-
[22]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
S. Han, K. Rao, A. Ettinger, L. Jiang, B. Y . Lin, N. Lambert, Y . Choi, and N. Dziri, “Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms,”arXiv preprint arXiv:2406.18495, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types,
Y . Mou, S. Zhang, and W. Ye, “Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types,”Advances in Neural Information Processing Systems, vol. 37, pp. 123 032–123 054, 2024
2024
-
[24]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
X. Qi, Y . Zeng, T. Xie, P.-Y . Chen, R. Jia, P. Mittal, and P. Henderson, “Fine-tuning aligned language models compromises safety, even when users do not intend to!”arXiv preprint arXiv:2310.03693, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset,
J. Ji, M. Liu, J. Dai, X. Pan, C. Zhang, C. Bian, B. Chen, R. Sun, Y . Wang, and Y . Yang, “Beavertails: Towards improved safety alignment of llm via a human-preference dataset,”Advances in Neural Information Processing Systems, vol. 36, pp. 24 678–24 704, 2023
2023
-
[26]
Do-not- answer: A dataset for evaluating safeguards in llms,
Y . Wang, H. Li, X. Han, P. Nakov, and T. Baldwin, “Do-not- answer: A dataset for evaluating safeguards in llms,”arXiv preprint arXiv:2308.13387, 2023
-
[27]
Air-bench 2024: A safety benchmark based on risk categories from regulations and policies,
Y . Zeng, Y . Yang, A. Zhou, J. Z. Tan, Y . Tu, Y . Mai, K. Klyman, M. Pan, R. Jia, D. Songet al., “Air-bench 2024: A safety benchmark based on risk categories from regulations and policies,”arXiv preprint arXiv:2407.17436, 2024
-
[28]
A strongreject for empty jailbreaks,
A. Souly, Q. Lu, D. Bowen, T. Trinh, E. Hsieh, S. Pandey, P. Abbeel, J. Svegliato, S. Emmons, O. Watkinset al., “A strongreject for empty jailbreaks,”Advances in Neural Information Processing Systems, vol. 37, pp. 125 416–125 440, 2024
2024
-
[29]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Liet al., “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,”Proceedings of Machine Learning Research, 2024
2024
-
[30]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models,
P. Chao, E. Debenedetti, A. Robey, M. Andriushchenko, F. Croce, V . Sehwag, E. Dobriban, N. Flammarion, G. J. Pappas, F. Trameret al., “Jailbreakbench: An open robustness benchmark for jailbreaking large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 55 005–55 029, 2024
2024
-
[31]
Safe- genbench: A benchmark framework for security vulnerability detection in llm-generated code,
X. Li, J. Ding, C. Peng, B. Zhao, X. Gao, H. Gao, and X. Gu, “Safe- genbench: A benchmark framework for security vulnerability detection in llm-generated code,”arXiv preprint arXiv:2506.05692, 2025
-
[32]
Longsafety: Evaluating long-context safety of large language models,
Y . Lu, J. Cheng, Z. Zhang, S. Cui, C. Wang, X. Gu, Y . Dong, J. Tang, H. Wang, and M. Huang, “Longsafety: Evaluating long-context safety of large language models,”arXiv preprint arXiv:2502.16971, 2025
-
[33]
Redagent: Red teaming large language models with context- aware autonomous language agent,
H. Xu, W. Zhang, Z. Wang, F. Xiao, R. Zheng, Y . Feng, Z. Ba, and K. Ren, “Redagent: Red teaming large language models with context- aware autonomous language agent,”arXiv preprint arXiv:2407.16667, 2024
-
[34]
CASE-Bench: Context-Aware SafEty Benchmark for Large Language Models
G. Sun, X. Zhan, S. Feng, P. C. Woodland, and J. Such, “Case-bench: Context-aware safety benchmark for large language models,”arXiv preprint arXiv:2501.14940, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
Finben: A holistic financial benchmark for large language models,
Q. Xie, W. Han, Z. Chen, R. Xiang, X. Zhang, Y . He, M. Xiao, D. Li, Y . Dai, D. Fenget al., “Finben: A holistic financial benchmark for large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 95 716–95 743, 2024
2024
-
[36]
Refind: Relation extraction financial dataset,
S. Kaur, C. Smiley, A. Gupta, J. Sain, D. Wang, S. Siddagangappa, T. Aguda, and S. Shah, “Refind: Relation extraction financial dataset,” inProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023, pp. 3054– 3063
2023
-
[37]
Finqa: A dataset of numerical reasoning over financial data,
Z. Chen, W. Chen, C. Smiley, S. Shah, and et al., “Finqa: A dataset of numerical reasoning over financial data,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021. [Online]. Available: https://arxiv.org/abs/2109.00122
-
[38]
Docfinqa: A long-context financial reasoning dataset,
V . Reddy, R. Koncel-Kedziorski, V . D. Lai, and et al., “Docfinqa: A long-context financial reasoning dataset,” inProceedings of ACL 2024 (Short Papers), 2024. [Online]. Available: https://huggingface.co/ datasets/kensho/DocFinQA
2024
-
[39]
Boosting jailbreak attack with momentum,
Y . Zhang and Z. Wei, “Boosting jailbreak attack with momentum,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[40]
Improved techniques for optimization-based jailbreaking on large language models,
X. Jia, T. Pang, C. Du, Y . Huang, J. Gu, Y . Liu, X. Cao, and M. Lin, “Improved techniques for optimization-based jailbreaking on large language models,”arXiv preprint arXiv:2405.21018, 2024
-
[41]
Query- based adversarial prompt generation,
J. Hayase, E. Borevkovi ´c, N. Carlini, F. Tram `er, and M. Nasr, “Query- based adversarial prompt generation,”Advances in Neural Information Processing Systems, vol. 37, pp. 128 260–128 279, 2024
2024
-
[42]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
X. Liu, N. Xu, M. Chen, and C. Xiao, “Autodan: Generating stealthy jailbreak prompts on aligned large language models,”arXiv preprint arXiv:2310.04451, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Tree of attacks: Jailbreaking black-box llms automatically,
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nelson, H. Anderson, Y . Singer, and A. Karbasi, “Tree of attacks: Jailbreaking black-box llms automatically,”Advances in Neural Information Processing Systems, 2024
2024
-
[44]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
J. Yu, X. Lin, Z. Yu, and X. Xing, “Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts,”arXiv preprint arXiv:2309.10253, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Gpt- 4 is too smart to be safe: Stealthy chat with llms via cipher,
Y . Yuan, W. Jiao, W. Wang, J.-t. Huang, P. He, S. Shi, and Z. Tu, “Gpt- 4 is too smart to be safe: Stealthy chat with llms via cipher,”arXiv preprint arXiv:2308.06463, 2023
-
[46]
Plentiful jailbreaks with string compositions,
B. R. Huang, “Plentiful jailbreaks with string compositions,”arXiv preprint arXiv:2411.01084, 2024
-
[47]
FlipAttack: Jailbreak LLMs via Flipping
Y . Liu, X. He, M. Xiong, J. Fu, S. Deng, and B. Hooi, “Flipattack: Jailbreak llms via flipping,”arXiv preprint arXiv:2410.02832, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Financial report chunking for effective retrieval augmented generation,
A. J. Yepes, Y . You, J. Milczek, S. Laverde, and R. Li, “Financial report chunking for effective retrieval augmented generation,”arXiv preprint arXiv:2402.05131, 2024
-
[49]
Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms,
X. Liu, P. Li, E. Suh, Y . V orobeychik, Z. Mao, S. Jha, P. McDaniel, H. Sun, B. Li, and C. Xiao, “Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms,”arXiv preprint arXiv:2410.05295, 2024
-
[50]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Weiet al., “Qwen2. 5 technical report,”arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Gemma 2: Improving Open Language Models at a Practical Size
G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ram ´eet al., “Gemma 2: Improving open language models at a practical size,”arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Exaone 3.5: Series of large language models for real-world use cases,
L. Research, S. An, K. Bae, E. Choi, K. Choi, S. J. Choi, S. Hong, J. Hwang, H. Jeon, G. J. Joet al., “Exaone 3.5: Series of large language models for real-world use cases,”arXiv preprint arXiv:2412.04862, 2024
-
[54]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
The claude 3 model family: Opus, sonnet, haiku,
Anthropic, “The claude 3 model family: Opus, sonnet, haiku,”
-
[56]
Available: https://api.semanticscholar.org/CorpusID: 268232499
[Online]. Available: https://api.semanticscholar.org/CorpusID: 268232499
-
[57]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Y . Chen, H. Gao, G. Cui, F. Qi, L. Huang, Z. Liu, and M. Sun, “Why should adversarial perturbations be imperceptible? rethink the research paradigm in adversarial nlp,”arXiv preprint arXiv:2210.10683, 2022
-
[59]
R. A. Krueger,Focus groups: A practical guide for applied research. Sage publications, 2014
2014
-
[60]
D. W. Stewart and P. N. Shamdasani,Focus groups: Theory and practice. Sage publications, 2014
2014
-
[61]
A coefficient of agreement for nominal scales,
J. Cohen, “A coefficient of agreement for nominal scales,”Educational and psychological measurement, vol. 20, no. 1, pp. 37–46, 1960
1960
-
[62]
Reliability in content analysis: Some common mis- conceptions and recommendations,
K. Krippendorff, “Reliability in content analysis: Some common mis- conceptions and recommendations,”Human communication research, vol. 30, no. 3, pp. 411–433, 2004
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.