RoboAtlas: Contextual Active SLAM
Pith reviewed 2026-06-25 19:10 UTC · model grok-4.3
The pith
RoboAtlas uses a contextual bandit to balance exploration and semantic reasoning in active SLAM, reaching 90.6 percent success on unseen benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
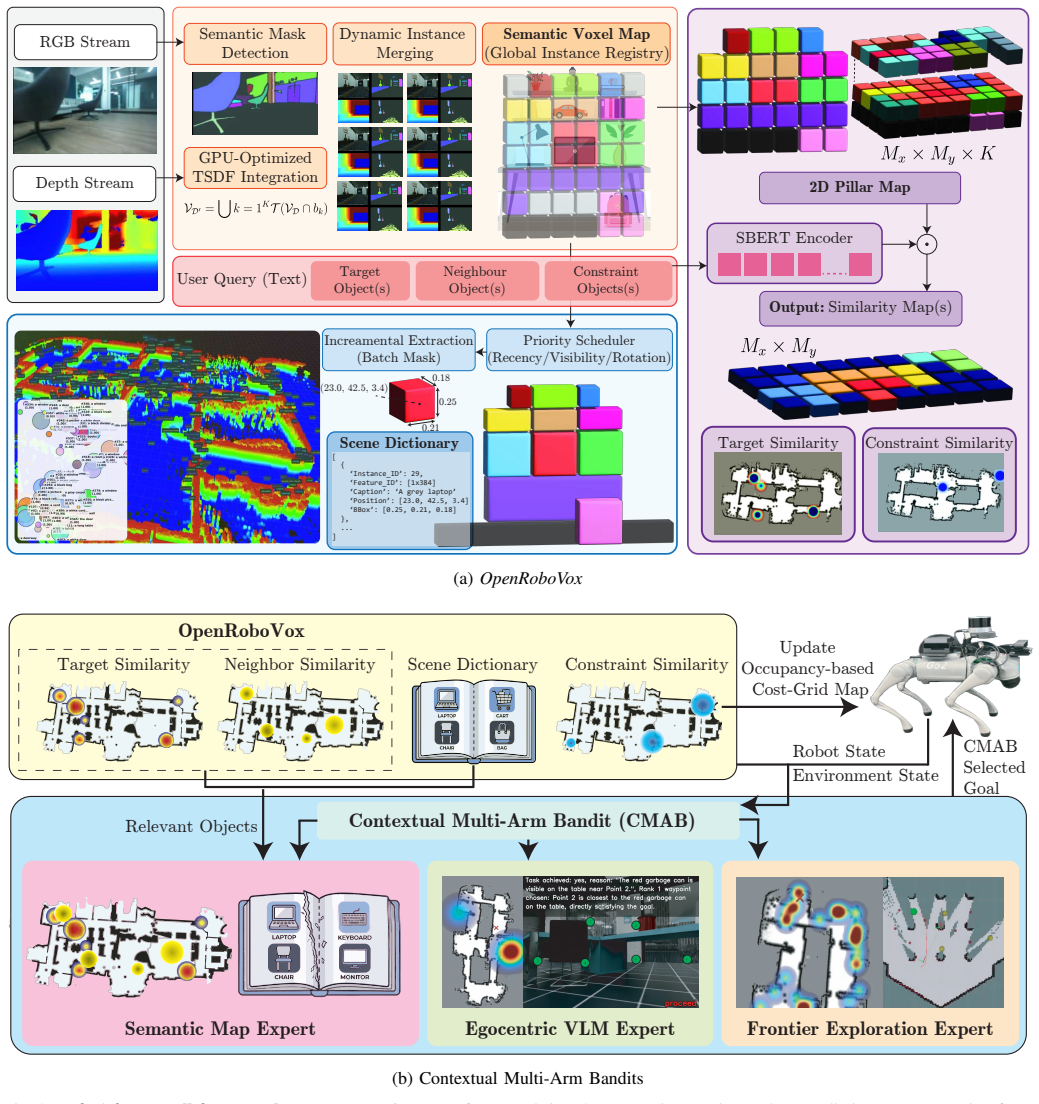
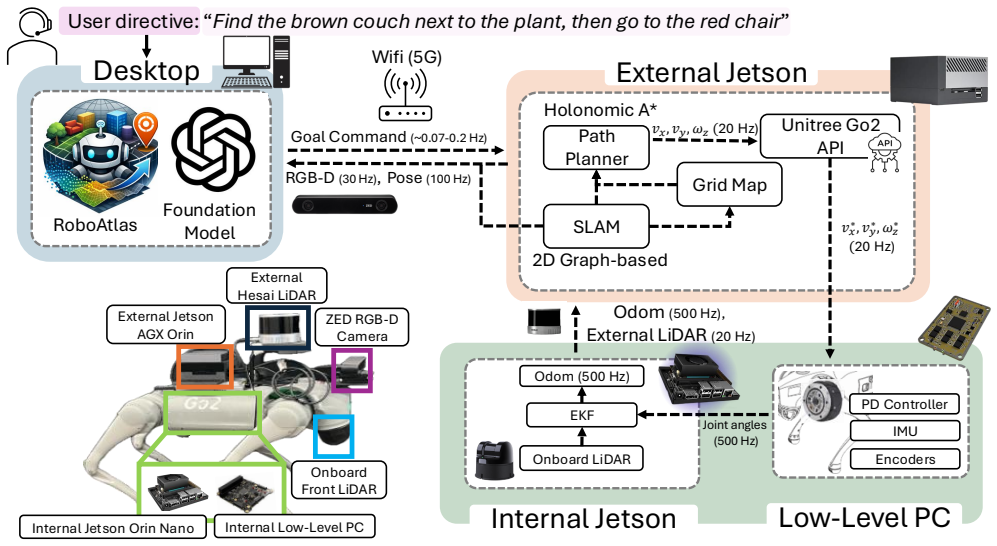
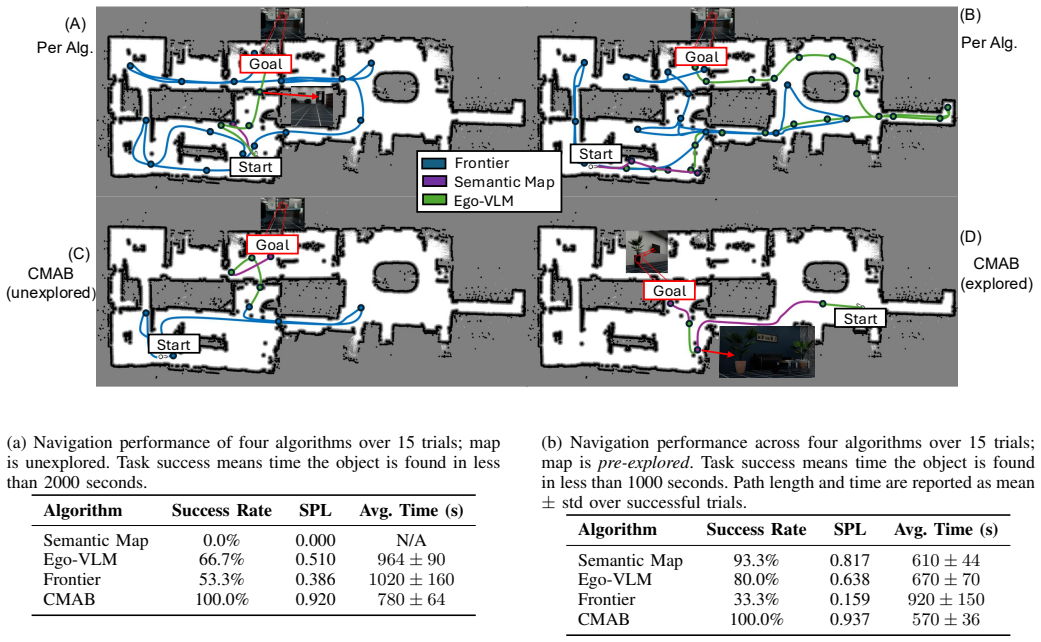
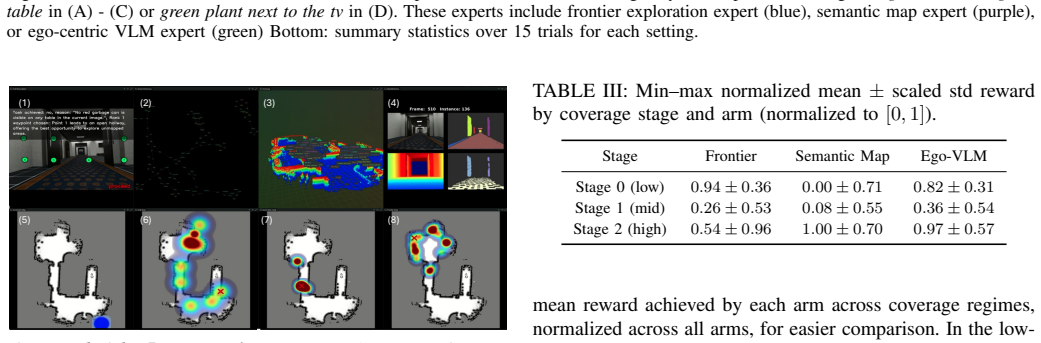
RoboAtlas integrates frontier exploration, global semantic-map reasoning, and egocentric vision-language model reasoning through a contextual multi-armed bandit that transitions from exploration to semantically guided navigation as scene understanding improves. It achieves a 100 percent task success rate in real-world environments exceeding 1800 square meters with around 30,000 mapped instances and state-of-the-art performance on a benchmark with 90.6 percent success rate using a large model, improving over the strongest prior baseline by 17.8 percentage points. Using a much smaller model, it still achieves 88.8 percent success rate.
What carries the argument
The contextual multi-armed bandit that adaptively balances geometric exploration and semantic reasoning using scalable 3D semantic mapping.
If this is right
- The system achieves full task success in real robot deployments across very large indoor spaces.
- Performance on standard tests exceeds previous methods by nearly 18 percentage points in success rate.
- Smaller vision-language models can surpass larger ones when supported by detailed semantic maps.
- Grounding vision-language models in large-scale 3D maps supports more robust active SLAM.
Where Pith is reading between the lines
- Improving mapping accuracy could allow even lighter models to handle complex navigation tasks.
- The method might apply to other tasks where robots need to reason about objects in unseen spaces.
- Errors in object labeling could cause the system to choose poor exploration paths.
Load-bearing premise
The 3D semantic mapping must produce labels accurate and complete enough to support reliable reasoning for navigation choices.
What would settle it
A controlled test where semantic labels are randomly perturbed or removed, checking whether the reported success rates drop significantly below the baselines.
Figures






read the original abstract
We present RoboAtlas, a contextual Active SLAM framework that adaptively balances geometric exploration and semantic reasoning using a scalable 3D semantic mapping system, OpenRoboVox. RoboAtlas integrates frontier exploration, global semantic-map reasoning, and egocentric VLM-based reasoning through a contextual multi-armed bandit that transitions from exploration to semantically guided navigation as scene understanding improves. We evaluate the system in simulation and on a Unitree Go2 robot in large-scale real-world environments exceeding 1800 m2 with approx. 30k mapped semantic instances, achieving a 100% task success rate. On the GOAT-Bench "Val Unseen" benchmark, RoboAtlas achieves state-of-the-art performance with highest reported success rate (SR) of 90.6%, using GPT-4o, improving over the strongest prior baseline by 17.8 percentage points in SR. Using the much smaller Qwen2.5-VL-7B model, it still achieves 88.8% SR, outperforming all baselines using GPT-4o in SR, and revealing the importance of the information gained by our semantic mapping framework over simply replacing the underlying foundation model. The results demonstrate that grounding foundation models with large-scale 3D semantic maps enables robust and efficient contextual Active SLAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents RoboAtlas, a contextual Active SLAM framework that integrates frontier exploration, global semantic-map reasoning via the OpenRoboVox 3D mapping system, and egocentric VLM reasoning through a contextual multi-armed bandit policy. The policy adaptively shifts from geometric exploration to semantically guided navigation as scene understanding improves. On the GOAT-Bench 'Val Unseen' benchmark the system reports state-of-the-art success rates of 90.6% (GPT-4o) and 88.8% (Qwen2.5-VL-7B), together with 100% task success in real-world trials on >1800 m² environments containing ~30k mapped semantic instances.
Significance. If the reported performance gains prove robust, the work provides concrete evidence that grounding VLMs with large-scale 3D semantic maps can yield substantial improvements in active SLAM, allowing smaller models to surpass larger ones and highlighting the value of scalable semantic mapping over raw model scale.
major comments (3)
- [Results / Experiments] Results section: the headline success rates (90.6% and 88.8% SR) are reported without error bars, number of evaluation episodes, or any statistical significance tests, so the claimed 17.8 pp improvement cannot be assessed for reliability.
- [Methods / Experiments] Methods / Experiments: no ablation studies isolate the contribution of OpenRoboVox mapping, the contextual bandit, or the VLM component, leaving the attribution of performance gains to the proposed framework unverified.
- [Methods] Implementation details: the tuning procedure, hyper-parameters, and exploration-to-exploitation schedule of the contextual multi-armed bandit are not described, which is load-bearing for reproducing the reported benchmark numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Results / Experiments] Results section: the headline success rates (90.6% and 88.8% SR) are reported without error bars, number of evaluation episodes, or any statistical significance tests, so the claimed 17.8 pp improvement cannot be assessed for reliability.
Authors: We agree that error bars, the exact number of evaluation episodes, and statistical significance tests are necessary to assess reliability. In the revised manuscript we will report the number of GOAT-Bench Val Unseen episodes, include standard-error bars on all success-rate figures, and add appropriate statistical tests comparing RoboAtlas against the strongest baseline. revision: yes
-
Referee: [Methods / Experiments] Methods / Experiments: no ablation studies isolate the contribution of OpenRoboVox mapping, the contextual bandit, or the VLM component, leaving the attribution of performance gains to the proposed framework unverified.
Authors: We acknowledge that ablation studies are required to attribute gains to individual components. The revised version will include a dedicated ablation section with controlled variants that disable OpenRoboVox, replace the contextual bandit with a fixed policy, and swap the VLM while keeping the mapping framework fixed. revision: yes
-
Referee: [Methods] Implementation details: the tuning procedure, hyper-parameters, and exploration-to-exploitation schedule of the contextual multi-armed bandit are not described, which is load-bearing for reproducing the reported benchmark numbers.
Authors: We agree that these details are essential for reproducibility. The revised manuscript will add a subsection detailing the bandit formulation, all hyper-parameters, the tuning procedure (including any cross-validation on a held-out set), and the precise schedule governing the shift from exploration to exploitation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical robotic framework evaluated via benchmark success rates (e.g., 90.6% SR on GOAT-Bench Val Unseen) and real-world trials. No equations, derivations, or parameter-fitting steps are presented that would reduce reported outcomes to inputs by construction. The central claims rest on measured performance of the integrated system (OpenRoboVox mapping + contextual bandit), which is externally falsifiable on the stated benchmarks and does not rely on self-citation chains or self-definitional premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on active simultaneous localization and mapping: State of the art and new frontiers,
J. A. Placed, J. Strader, H. Carrillo, N. Atanasov, V . Indelman, L. Car- lone, and J. A. Castellanos, “A survey on active simultaneous localization and mapping: State of the art and new frontiers,”IEEE Transactions on Robotics, vol. 39, no. 3, pp. 1686–1705, 2023
2023
-
[2]
Saber: Data-driven motion planner for autonomously navigating heterogeneous robots,
A. Schperberg, S. Tsuei, S. Soatto, and D. Hong, “Saber: Data-driven motion planner for autonomously navigating heterogeneous robots,” IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 8086–8093, 2021
2021
-
[3]
Algorithms for routing of unmanned aerial vehicles with mobile recharging stations,
K. Yu, A. K. Budhiraja, and P. Tokekar, “Algorithms for routing of unmanned aerial vehicles with mobile recharging stations,” in2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 5720–5725, 2018
2018
-
[4]
Frontier-based exploration for multi-robot rendezvous in communication-restricted un- known environments,
M. Tellaroli, M. Luperto, M. Antonazzi, and N. Basilico, “Frontier-based exploration for multi-robot rendezvous in communication-restricted un- known environments,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5807–5812, 2024
2024
-
[5]
How to not train your dragon: Training-free embodied object goal navigation with semantic frontiers,
J. Chen, G. Li, S. Kumar, B. Ghanem, and F. Yu, “How to not train your dragon: Training-free embodied object goal navigation with semantic frontiers,” 2023
2023
-
[6]
Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation,
S. Y . Gadre, M. Wortsman, G. Ilharco, L. Schmidt, and S. Song, “Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation,”CVPR, 2023
2023
-
[7]
Vlfm: Vision- language frontier maps for zero-shot semantic navigation,
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher, “Vlfm: Vision- language frontier maps for zero-shot semantic navigation,” in2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 42– 48, 2024
2024
-
[8]
Energy- constrained multi-robot exploration for autonomous map building,
S. H. Karumanchi, B. Rokaha, A. Schperberg, and A. P. Vinod, “Energy- constrained multi-robot exploration for autonomous map building,” in 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 9154–9161, 2025
2025
-
[9]
A practical, decision-theoretic approach to multi-robot mapping and exploration,
J. Ko, B. Stewart, D. Fox, K. Konolige, and B. Limketkai, “A practical, decision-theoretic approach to multi-robot mapping and exploration,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 3232–3238, 2003
2003
-
[10]
Coordinated multi-robot exploration using a segmentation of the environment,
K. M. Wurm, C. Stachniss, and W. Burgard, “Coordinated multi-robot exploration using a segmentation of the environment,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 1160–1165, 2008
2008
-
[11]
Multi-robot coordination for energy-efficient exploration,
A. Benkrid, A. Benallegue, and N. Achour, “Multi-robot coordination for energy-efficient exploration,”Journal of Control, Automation and Electrical Systems, vol. 30, no. 6, pp. 911–920, 2019
2019
-
[12]
Coordinated multi-robot exploration,
W. Burgard, M. Moors, C. Stachniss, and F. E. Schneider, “Coordinated multi-robot exploration,”IEEE Transactions on Robotics, vol. 21, no. 3, pp. 376–386, 2005
2005
-
[13]
Decentralized coordination for multirobot exploration,
B. Yamauchi, “Decentralized coordination for multirobot exploration,” Robotics and Autonomous Systems, vol. 29, no. 2-3, pp. 111–118, 1999
1999
-
[14]
Namo-llm: Efficient navigation among movable obstacles with large language model guidance,
Y . Zhang and Y . Kantaros, “Namo-llm: Efficient navigation among movable obstacles with large language model guidance,”IEEE Robotics and Automation Letters, vol. 10, no. 12, pp. 13026–13033, 2025
2025
-
[15]
Can an embodied agent find your “cat-shaped mug
V . S. Dorbala, J. F. Mullen, and D. Manocha, “Can an embodied agent find your “cat-shaped mug”? llm-based zero-shot object navigation,” IEEE Robotics and Automation Letters, vol. 9, p. 4083–4090, May 2024
2024
-
[16]
Esc: Exploration with soft commonsense constraints for zero- shot object navigation,
K. Zhou, K. Zheng, C. Pryor, Y . Shen, H. Jin, L. Getoor, and X. E. Wang, “Esc: Exploration with soft commonsense constraints for zero- shot object navigation,” 2023
2023
-
[17]
Visual language maps for robot navigation,
C. Huang, O. Mees, A. Zeng, and W. Burgard, “Visual language maps for robot navigation,” 2023
2023
-
[18]
Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,
D. Shah, B. Osinski, B. Ichter, and S. Levine, “Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,” 2022
2022
-
[19]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch, “Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,” 2022
2022
-
[20]
Inner monologue: Embodied reasoning through planning with language models,
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, P. Sermanet, N. Brown, T. Jack- son, L. Luu, S. Levine, K. Hausman, and B. Ichter, “Inner monologue: Embodied reasoning through planning with language models,” 2022
2022
-
[21]
Stairway to success: An online floor-aware zero-shot object- goal navigation framework via llm-driven coarse-to-fine exploration,
Z. Gong, R. Li, T. Hu, R. Qiu, L. Kong, L. Zhang, G. Zhao, Y . Ding, and J. Liang, “Stairway to success: An online floor-aware zero-shot object- goal navigation framework via llm-driven coarse-to-fine exploration,” IEEE Robotics and Automation Letters, vol. 11, no. 3, pp. 2943–2950, 2026
2026
-
[22]
Dynavlm: Zero-shot vision-language naviga- tion system with dynamic viewpoints and self-refining graph memory,
Z. Ji, H. Lin, and Y . Gao, “Dynavlm: Zero-shot vision-language naviga- tion system with dynamic viewpoints and self-refining graph memory,” 2025
2025
-
[23]
Handle object navigation as weighted traveling repairman problem,
R. Liu, X. Xu, S. Yuan, and L. Xie, “Handle object navigation as weighted traveling repairman problem,” 2025
2025
-
[24]
Orionnav: Online plan- ning for robot autonomy with context-aware llm and open-vocabulary semantic scene graphs,
V . N. Devarakonda, R. G. Goswami, A. U. Kaypak, N. Patel, R. Khor- rambakht, P. Krishnamurthy, and F. Khorrami, “Orionnav: Online plan- ning for robot autonomy with context-aware llm and open-vocabulary semantic scene graphs,” 2024
2024
-
[25]
3p-llm: Probabilistic path planning using large language model for autonomous robot navigation,
E. Latif, “3p-llm: Probabilistic path planning using large language model for autonomous robot navigation,” 2024
2024
-
[26]
Msgnav: Unleashing the power of multi-modal 3d scene graph for zero-shot embodied navigation,
X. Huang, S. Zhao, Y . Wang, X. Lu, W. Zhang, R. Qu, W. Li, Y . Wang, and C. Wen, “Msgnav: Unleashing the power of multi-modal 3d scene graph for zero-shot embodied navigation,”arXiv preprint arXiv:2511.10376, 2025
-
[27]
Semanticfu- sion: Dense 3d semantic mapping with convolutional neural networks,
J. McCormac, A. Handa, A. Davison, and S. Leutenegger, “Semanticfu- sion: Dense 3d semantic mapping with convolutional neural networks,” 2016
2016
-
[28]
Maskfusion: Real-time recogni- tion, tracking and reconstruction of multiple moving objects,
M. R ¨unz, M. Buffier, and L. Agapito, “Maskfusion: Real-time recogni- tion, tracking and reconstruction of multiple moving objects,” 2018
2018
-
[29]
Fusion++: V olumetric object-level slam,
J. McCormac, R. Clark, M. Bloesch, A. J. Davison, and S. Leutenegger, “Fusion++: V olumetric object-level slam,” 2018
2018
-
[30]
Panopticfusion: Online volumetric semantic mapping at the level of stuff and things,
G. Narita, T. Seno, T. Ishikawa, and Y . Kaji, “Panopticfusion: Online volumetric semantic mapping at the level of stuff and things,” 2019
2019
-
[31]
Pocd: Probabilistic object-level change detection and volu- metric mapping in semi-static scenes,
J. Qian, V . Chatrath, J. Yang, J. Servos, A. P. Schoellig, and S. L. Waslander, “Pocd: Probabilistic object-level change detection and volu- metric mapping in semi-static scenes,” 2022
2022
-
[32]
Pov-slam: Probabilistic object-aware variational slam in semi-static environments,
J. Qian, V . Chatrath, J. Servos, A. Mavrinac, W. Burgard, S. L. Waslander, and A. P. Schoellig, “Pov-slam: Probabilistic object-aware variational slam in semi-static environments,” 2023
2023
-
[33]
Concept- graphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa,et al., “Concept- graphs: Open-vocabulary 3d scene graphs for perception and planning,” in2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 5021–5028, IEEE, 2024
2024
-
[34]
Openvox: Real-time instance-level open-vocabulary probabilistic voxel representation,
Y . Deng, B. Yao, Y . Tang, Y . Yang, and Y . Yue, “Openvox: Real-time instance-level open-vocabulary probabilistic voxel representation,” 2025
2025
-
[35]
One map to find them all: Real-time open-vocabulary mapping for zero-shot multi-object navigation,
F. L. Busch, T. Homberger, J. Ortega-Peimbert, Q. Yang, and O. Ander- sson, “One map to find them all: Real-time open-vocabulary mapping for zero-shot multi-object navigation,”arXiv preprint arXiv:2409.11764, 2024
-
[36]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang, “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,”arXiv preprint arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Yolo- world: Real-time open-vocabulary object detection,
T. Cheng, L. Song, Y . Ge, W. Liu, X. Wang, and Y . Shan, “Yolo- world: Real-time open-vocabulary object detection,”arXiv preprint arXiv:2401.17270, 2024
-
[38]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,”arXiv preprint arXiv:2103.00020, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,”arXiv preprint arXiv:2301.12597, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll´ar, and R. Girshick, “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[41]
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
C. Zhang, D. Han, Y . Qiao, J. U. Kim, S.-H. Bae, S. Lee, and C. S. Hong, “Faster segment anything: Towards lightweight sam for mobile applications,”arXiv preprint arXiv:2306.14289, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Convolutions die hard: Open-vocabulary segmentation with single frozen convolutional clip,
Q. Yu, J. He, X. Deng, X. Shen, and L.-C. Chen, “Convolutions die hard: Open-vocabulary segmentation with single frozen convolutional clip,” inNeurIPS, 2023
2023
-
[43]
Embodied question answering,
A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Batra, “Embodied question answering,” 2017
2017
-
[44]
Behavior- 1k: A human-centered, embodied ai benchmark with 1,000 everyday activities and realistic simulation,
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, W. Ai, B. Martinez, H. Yin, M. Lingelbach, M. Hwang, A. Hiranaka, S. Garlanka, A. Aydin, S. Lee, J. Sun, M. Anvari, M. Sharma, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, Y . Li, S. Savarese, H. Gweon, ...
2024
-
[45]
Explore until confident: Efficient exploration for embodied question answering,
A. Z. Ren, J. Clark, A. Dixit, M. Itkina, A. Majumdar, and D. Sadigh, “Explore until confident: Efficient exploration for embodied question answering,” 2024
2024
-
[46]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks,
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “Alfred: A benchmark for interpreting grounded instructions for everyday tasks,” 2020
2020
-
[47]
Habitat 2.0: Training home assistants to rearrange their habitat,
A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y . Zhao, J. Turner, N. Maestre, M. Mukadam, D. Chaplot, O. Maksymets, A. Gokaslan, V . V ondrus, S. Dharur, F. Meier, W. Galuba, A. Chang, Z. Kira, V . Koltun, J. Malik, M. Savva, and D. Batra, “Habitat 2.0: Training home assistants to rearrange their habitat,” 2022
2022
-
[48]
Move to understand a 3d scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation,
Z. Zhu, X. Wang, Y . Li, Z. Zhang, X. Ma, Y . Chen, B. Jia, W. Liang, Q. Yu, Z. Deng, S. Huang, and Q. Li, “Move to understand a 3d scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation,”International Conference on Computer Vision (ICCV), 2025
2025
-
[49]
3d- mem: 3d scene memory for embodied exploration and reasoning,
Y . Yang, H. Yang, J. Zhou, P. Chen, H. Zhang, Y . Du, and C. Gan, “3d- mem: 3d scene memory for embodied exploration and reasoning,” in Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pp. 17294–17303, June 2025
2025
-
[50]
G. Zhang, M. Ding, J. Wu, R. Liao, and V . Tresp, “Reexplore: Improv- ing mllms for embodied exploration with contextualized retrospective experience replay,”arXiv preprint arXiv:2511.19033, 2025
-
[51]
Explore with long-term memory: A benchmark and multimodal llm- based reinforcement learning framework for embodied exploration,
S. Wang, B. Liu, Z. Gao, L. Ma, X. Wang, Y . Xie, and X. Tan, “Explore with long-term memory: A benchmark and multimodal llm- based reinforcement learning framework for embodied exploration,” in Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[52]
Himm: Human-inspired long-term memory modeling for embodied exploration and question answering,
J. Li, B. Wang, J. Xia, M. Li, and S. Hu, “Himm: Human-inspired long-term memory modeling for embodied exploration and question answering,” 2026
2026
-
[53]
OctoMap: An efficient probabilistic 3D mapping framework based on octrees,
A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Burgard, “OctoMap: An efficient probabilistic 3D mapping framework based on octrees,”Autonomous Robots, 2013. Software available at https: //octomap.github.io
2013
-
[54]
Slam toolbox: Slam for the dynamic world,
S. Macenski and I. Jambrecic, “Slam toolbox: Slam for the dynamic world,”Journal of Open Source Software, vol. 6, no. 61, p. 2783, 2021
2021
-
[55]
A contextual-bandit approach to personalized news article recommendation,
L. Li, W. Chu, J. Langford, and R. E. Schapire, “A contextual-bandit approach to personalized news article recommendation,” inProceedings of the 19th international conference on World wide web, WWW ’10, p. 661–670, ACM, Apr. 2010
2010
-
[56]
Tokenize anything via prompting,
T. Pan, L. Tang, X. Wang, and S. Shan, “Tokenize anything via prompting,” inEuropean Conference on Computer Vision, pp. 330–348, Springer, 2024
2024
-
[57]
Isaac Sim
NVIDIA, “Isaac Sim.”
-
[58]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik,et al., “Habitat: A platform for embodied ai research,”arXiv preprint arXiv:1904.01201, 2019
-
[59]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang, M. Savva, Y . Zhao, and D. Batra, “Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai,”arXiv preprint arXiv:2109.08238, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[60]
From the desks of ROS maintainers: A survey of modern and capable mobile robotics algorithms in the robot operating system 2,
S. Macenski, T. Moore, D. Lu, A. Merzlyakov, and M. Ferguson, “From the desks of ROS maintainers: A survey of modern and capable mobile robotics algorithms in the robot operating system 2,”Robotics and Autonomous Systems, vol. 168, p. 104493, 2023
2023
-
[61]
Open-source, cost-aware kinematically feasible planning for mobile and surface robotics,
S. Macenski, M. Booker, and J. Wallace, “Open-source, cost-aware kinematically feasible planning for mobile and surface robotics,”Arxiv, 2024
2024
-
[62]
Goat- bench: A benchmark for multi-modal lifelong navigation,
M. Khanna*, R. Ramrakhya*, G. Chhablani, S. Yenamandra, T. Gervet, M. Chang, Z. Kira, D. S. Chaplot, D. Batra, and R. Mottaghi, “Goat- bench: A benchmark for multi-modal lifelong navigation,” inCVPR, 2024
2024
-
[63]
Explore until confident: Efficient exploration for embodied question answering,
A. Z. Ren, J. Clark, A. Dixit, M. Itkina, A. Majumdar, and D. Sadigh, “Explore until confident: Efficient exploration for embodied question answering,”arXiv preprint arXiv:2403.15941, 2024. APPENDIXA ADAPTINGCMABFORGOAT-BENCH The reward formulation in Sec. IV-A is designed for a single open-ended directive, where exploration progress and semantic similari...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.