Orca: The World is in Your Mind
Pith reviewed 2026-06-30 06:18 UTC · model grok-4.3
The pith
Orca learns a unified world latent space via next-state prediction from multimodal signals, enabling stronger readouts on text, image and action tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
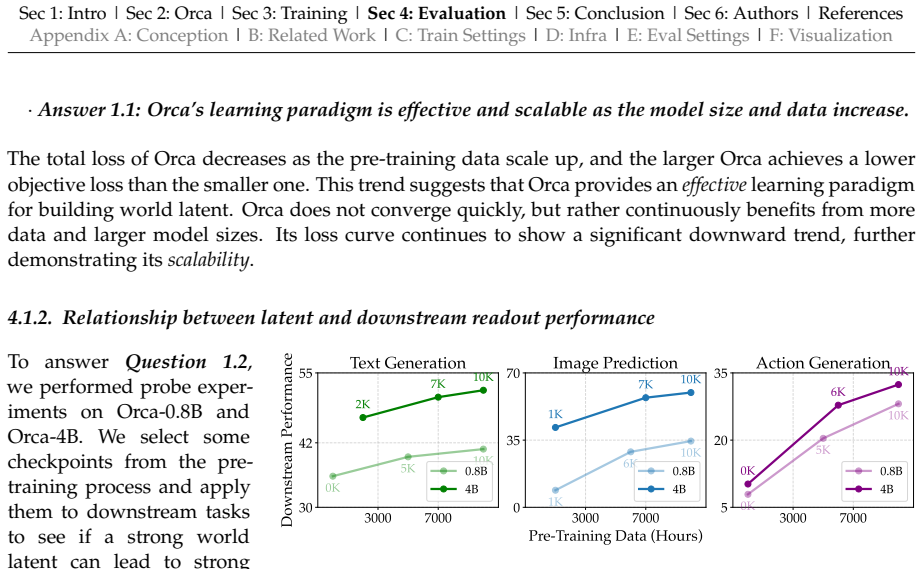
Orca learns a unified world latent space from multimodal world signals by centering on Next-State-Prediction modeling. Unconscious learning captures dense natural state transitions from continuous videos, while conscious learning models sparse meaningful state transitions using language-described events and VQA supervision. The resulting latent, exposed through lightweight modality-specific decoders with a frozen backbone, supports stronger readouts on text generation, image prediction, and embodied action generation than similar-sized specialized baselines.
What carries the argument
Next-State-Prediction modeling that unifies state-transition learning across video and language into a single latent space.
If this is right
- A stronger pre-trained world latent directly improves downstream performance on text generation, image prediction, and embodied action generation.
- Freezing the backbone after large-scale pre-training and training only lightweight decoders is sufficient to expose the latent's utility across modalities.
- The combination of unconscious video-based and conscious language-based pre-training produces a latent that scales to multiple readout tasks.
- Outperformance over similar-sized specialized baselines holds when the same frozen backbone serves all three domains.
Where Pith is reading between the lines
- If the latent encodes general state transitions, adding a new decoder could enable readouts for modalities such as audio without retraining the core model.
- Direct comparison of internal representations between Orca and task-specific models could isolate which world-state features arise only from the unified objective.
- Extending the pre-training inventory to additional sensor streams would test whether the next-state objective remains effective beyond video and text.
Load-bearing premise
That performance gains on the readout tasks are driven by the quality of the latent space itself rather than by decoder architecture choices or overlap between the pre-training inventory and the evaluation data.
What would settle it
Train identical lightweight decoders on a randomly initialized backbone or on a backbone pre-trained without the next-state-prediction objective and check whether the performance advantage over Orca disappears on the three readout tasks.
Figures





read the original abstract
We introduce Orca, an initial instantiation of a general world foundation model. Orca learns a unified world latent space from multimodal world signals and exposes it through multimodal readout interfaces. Rather than optimizing isolated next-token, next-frame, or next-action prediction, we are centered on Next-State-Prediction modeling, offering a unified state-transition modeling route toward understanding, predicting, and acting upon the world. Orca learns through two complementary paradigms: unconscious learning captures dense natural state transitions from continuous videos, and conscious learning models sparse meaningful state transitions by language-described events and VQA supervision. For pre-training, we construct a large-scale world-learning inventory data, including 125K hours of video data and 160M event annotations. After pre-training, Orca learns a unified world latent space. To examine whether the learned latent supports downstream, we evaluate it by three representative downstream readouts: text generation, image prediction, and embodied action generation. Orca's backbone is frozen, and only the lightweight modality-specific decoders are trainable. Experiments show the scalability of the proposed paradigm and verify that stronger world latent enables stronger downstream readouts. Orca outperforms similar-sized specialized baselines. These results show that Orca, as a general world foundation model, presents a promising approach to understanding, predicting, and acting upon the world. Finally, we discuss the current limitations, aiming to provide useful insights and inspiration for the community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
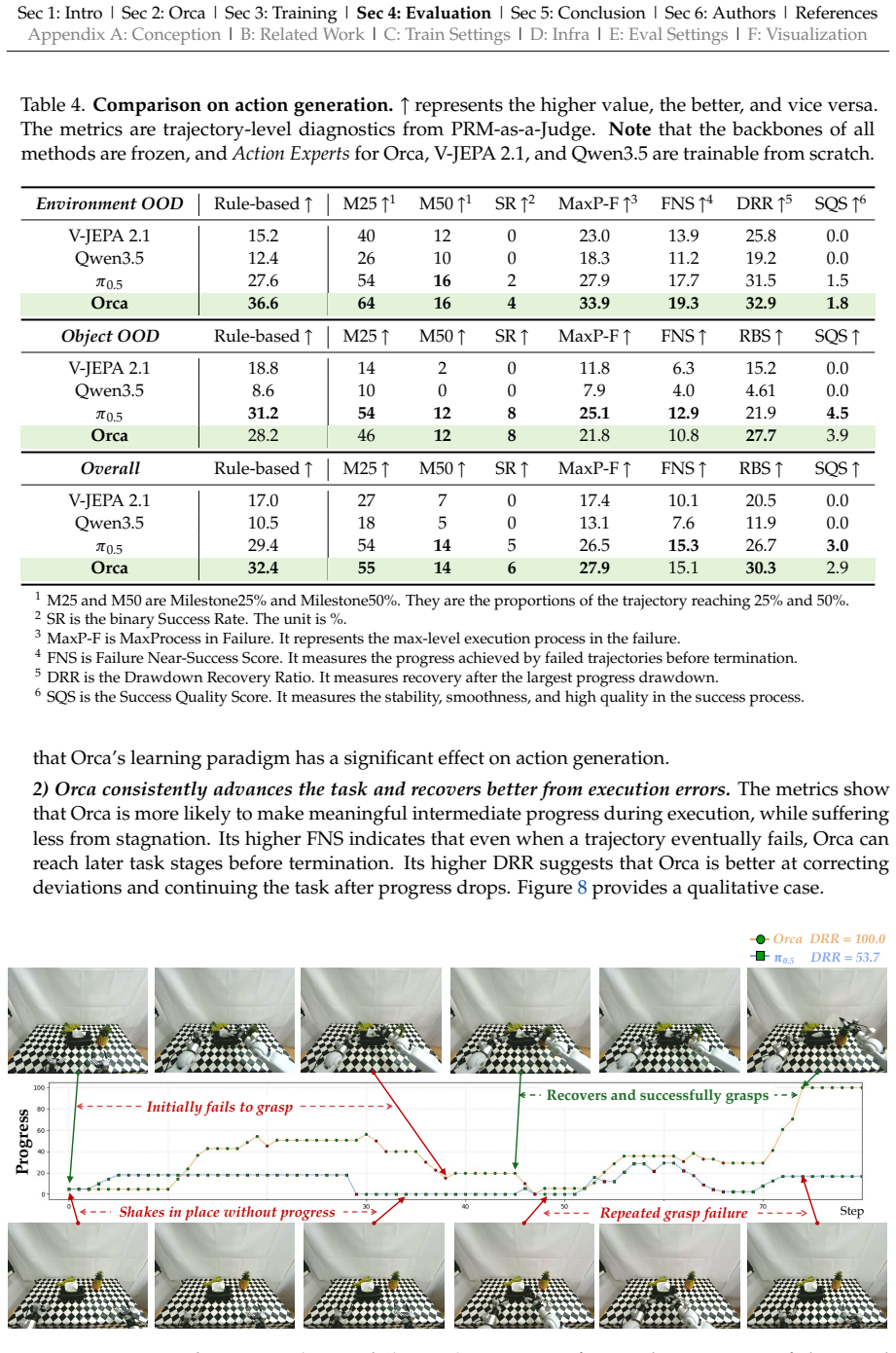
Summary. The paper introduces Orca as an initial general world foundation model that learns a unified world latent space from multimodal signals (video, language, VQA) via Next-State-Prediction rather than modality-specific next-token/frame/action prediction. Pre-training uses a 125K-hour video inventory with 160M event annotations through unconscious (dense video transitions) and conscious (sparse language-described events) paradigms. After pre-training the backbone is frozen and only lightweight modality-specific decoders are trained for three downstream readouts: text generation, image prediction, and embodied action generation. The manuscript claims this protocol demonstrates scalability, that stronger world latents yield stronger readouts, and that Orca outperforms similar-sized specialized baselines.
Significance. If the attribution to the unified latent holds and the outperformance is reproducible with proper controls, the work would be significant for the field of generalist multimodal models by offering a unified state-transition modeling route that could reduce the need for separate specialized models. The scale of the pre-training inventory (125K hours + 160M annotations) and the explicit separation of unconscious/conscious learning are notable strengths, as is the attempt to evaluate a single frozen backbone across text, vision, and action readouts.
major comments (2)
- [abstract / evaluation protocol] The central claim that 'stronger world latent enables stronger downstream readouts' (abstract) rests on the evaluation protocol of freezing the backbone after pre-training on the 125K-hour inventory and training only lightweight decoders. No ablation is described that holds decoder capacity and data fixed while varying only the latent (e.g., random-init backbone or controlled data overlap), leaving open that gains could arise from data volume/diversity or decoder design rather than latent geometry. This is load-bearing for the attribution to the unified Next-State-Prediction latent.
- [abstract] The abstract asserts that 'experiments show the scalability of the proposed paradigm and verify that stronger world latent enables stronger downstream readouts' and that 'Orca outperforms similar-sized specialized baselines,' yet provides no quantitative results, baseline details, error bars, data-split information, or statistical tests. Without these, the soundness of the outperformance claim cannot be assessed from the manuscript text.
minor comments (2)
- [abstract] The abstract refers to 'three representative downstream readouts' but does not specify the exact tasks, metrics, or datasets used for text generation, image prediction, and embodied action generation.
- [abstract] Notation for the 'unified world latent space' and 'Next-State-Prediction' is introduced without an accompanying equation or diagram in the abstract; a formal definition would aid clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and indicate planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [abstract / evaluation protocol] The central claim that 'stronger world latent enables stronger downstream readouts' (abstract) rests on the evaluation protocol of freezing the backbone after pre-training on the 125K-hour inventory and training only lightweight decoders. No ablation is described that holds decoder capacity and data fixed while varying only the latent (e.g., random-init backbone or controlled data overlap), leaving open that gains could arise from data volume/diversity or decoder design rather than latent geometry. This is load-bearing for the attribution to the unified Next-State-Prediction latent.
Authors: We agree that the attribution to the unified latent would be strengthened by an ablation that isolates latent quality while holding decoder capacity and training data fixed. In the revised manuscript we will add a controlled comparison of the pre-trained backbone against a randomly-initialized backbone (identical decoder training protocol and data) and will report results on a data-overlap-controlled subset. These additions directly address the load-bearing concern. revision: yes
-
Referee: [abstract] The abstract asserts that 'experiments show the scalability of the proposed paradigm and verify that stronger world latent enables stronger downstream readouts' and that 'Orca outperforms similar-sized specialized baselines,' yet provides no quantitative results, baseline details, error bars, data-split information, or statistical tests. Without these, the soundness of the outperformance claim cannot be assessed from the manuscript text.
Authors: The abstract is intentionally concise; the full quantitative results, baseline specifications, data splits, error bars, and statistical details appear in Sections 4–5 and the associated tables/figures. To improve standalone readability we will expand the abstract with one or two key performance deltas and will ensure the abstract explicitly references the main-text tables containing the complete experimental protocol. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical pre-training and evaluation protocol for a multimodal world model without presenting any mathematical derivations, equations, or fitting procedures. Claims rest on experimental comparisons after freezing the backbone and training lightweight decoders, which is a standard non-circular evaluation approach for foundation models. No self-citations, ansatzes, or renamings are invoked as load-bearing steps in the provided text, and the central assertion that stronger latents yield stronger readouts is supported (or not) by the reported results rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Next-State-Prediction provides a unified route to understanding, predicting, and acting upon the world
invented entities (1)
-
unified world latent space
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems
24 AgiBot-World-Contributors, Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. InIROS, 2025. 31 Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Y...
2025
-
[2]
General Covariant Action Modeling: Constructing Generalized Manifolds via Spatio-Temporal Decoupling
9, 24, 31 Google Deepmind. Gemini 3.1 pro best for complex tasks and bringing creative concepts to life, February 2026a. URLhttps://deepmind.google/models/gemini/pro/. 10, 23, 32 Google Deepmind. Gemma 4: Byte for byte, the most capable open models, April 2026b. URLhttps: //blog.google/innovation-and-ai/technology/developers-tools/gemma-4/. 9, 10, 24, 31,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
24 Shangchen Miao, Ningya Feng, Jialong Wu, Ye Lin, Xu He, Dong Li, and Mingsheng Long
URLhttps://ai.meta.com/blog/llama-4-multimodal-intelligence/. 24 Shangchen Miao, Ningya Feng, Jialong Wu, Ye Lin, Xu He, Dong Li, and Mingsheng Long. Jepa-vla: Video predictive embedding is needed for vla models.ArXiv, 2026. 25 MiniMax Team. Minimax m2.7: Early echoes of self-evolution, March 2026. URLhttps://www.mini max.io/news/minimax-m27-en. 23 Mistra...
2026
-
[4]
Reason-rft: Reinforcement fine-tuning for visual reasoning of vision language models
25 Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Xiansheng Chen, Pengwei Wang, Zhongyuan Wang, and Shang- hang Zhang. Reason-rft: Reinforcement fine-tuning for visual reasoning of vision language models. InNeurIPS, 2025. 24 Yuxuan Tian, Yuheng Ji, Xiaolong Zheng, Ziheng Qin, Yipu Wang, Xinyi Zheng, Yuyang Liu, Shuanghao Bai, Zhe Li, Liang Wang, et al. Spatial int...
2025
-
[5]
Llama 2: Open foundation and fine-tuned chat models.ArXiv, 2023
24 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.ArXiv, 2023. 23 Wan Team, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wa...
2023
-
[6]
23 21 Sec 1: Intro | Sec 2: Orca | Sec 3: Training | Sec 4: Evaluation | Sec 5: Conclusion | Sec 6: Authors | References Appendix A: Conception| B: Related Work | C: Train Settings | D: Infra | E: Eval Settings | F: Visualization Appendix A. Orca Conception Passive Task Driven Active World Learner This is a fridge Next Frame Prediction Visual Dynamics Pre...
2023
-
[7]
next token prediction
strengthen agentic language modeling. The former emphasizes tool-oriented intelligence, and the latter focuses on long-horizon agentic engineering. MiniMax-M2.7 (MiniMax Team, 2026) investigates self-evolving for real-world productivity. Phi-4-reasoning (Abdin et al., 2025) shows the effectiveness of high-quality reasoning supervision in dense models. The...
2026
-
[8]
The loss is: Lobs =E h ℓlat ˆ𝑣𝑙 𝑡+1,𝑣 𝑙 𝑡+1 i
Observation-only state transition.𝑣 𝑙 𝑡+1 is the latent of the next frame. The loss is: Lobs =E h ℓlat ˆ𝑣𝑙 𝑡+1,𝑣 𝑙 𝑡+1 i . (C-2)
-
[9]
Event-conditioned state transition.The language specifies whether the current state should be mapped toward an adjacent (earlier or later) event state. Accordingly, Orca predicts the visual latent in the previous event selected by theprevious-event conditionand the visual latent in the next event selected by thenext-event condition. The event-conditioned ...
-
[10]
This term is denoted asL vqa
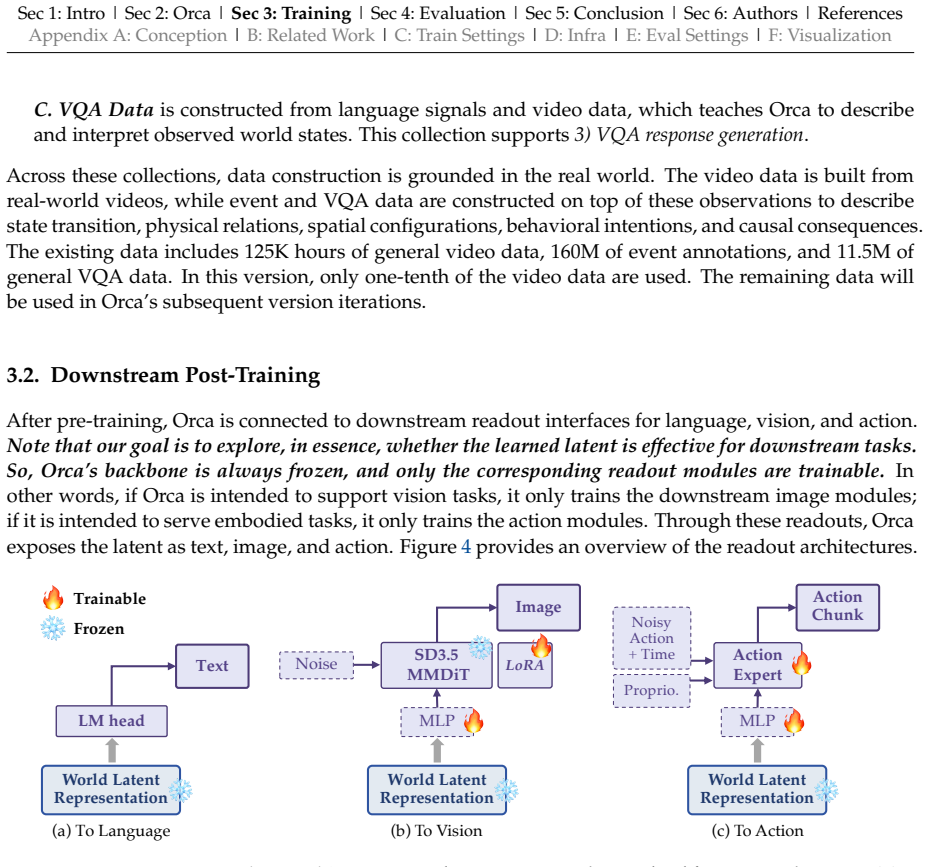
VQA response generation.Orca uses the language modeling head to predict the target answer with the standard next-token prediction loss. This term is denoted asL vqa. The final Orca’s pre-training objective is:Lpre =0.1L obs +0.5L evt +0.4L vqa. At the data-sampling level, Orca mixes state transition samples and VQA samples with an approximate ratio of 5 :...
-
[11]
The last-layer hidden state of𝑞 1 is passed to thevisual transition head(two-layer MLP), and the ground truth latent𝑣 𝑙 𝑡+1 is obtained by the frozen vision encoder of VLM backbone
Observation-only state transition.Given the current observation𝑣 𝑡 and<Query 1>𝑞 1, Orca pre- dicts the latent ˆ𝑣𝑙 𝑡+1 of a temporally next frame. The last-layer hidden state of𝑞 1 is passed to thevisual transition head(two-layer MLP), and the ground truth latent𝑣 𝑙 𝑡+1 is obtained by the frozen vision encoder of VLM backbone
-
[12]
The previous-eventL prev and next-event directionsL next, which are calculatedL evt in Equation C-3
Event-conditioned State Transition.Given𝑣 𝑡,𝑞 1, an instruction𝑒 𝑡+Δ, and the<Query 2>𝑞 2, Orca predicts the latent ˆ𝑣𝑙 𝑡+Δ of random frame in the instruction-specified target event.𝑒 𝑡+Δ specifies the transition direction and target event, while𝑞 2 reads out the corresponding instruction-conditioned predictive state. The previous-eventL prev and next-eve...
2024
-
[13]
Latent𝑞 1: predictive query states from Orca, providing latent for future state evolution
-
[14]
Noisy action with time embedding: Actions with Gaussian noise, and time embedding added
-
[15]
score": 3,
Proprioception: robot proprioceptive state, including joint and end-effector related information. Settings.TheAction Expertis trained with the flow-matching loss to obtain the action chunks. The ground-truth action chunk is perturbed with Gaussian noise, and theAction Expertpredicts the corre- sponding velocity. The architecture and training settings of t...
2026
-
[16]
The robot arm moves toward the book. 10
-
[17]
The gripper contacts the book. 10
-
[18]
The book is pushed to the edge, with more than 2 cm beyond the edge, without falling. 20
-
[19]
The book is successfully grasped. 30
-
[20]
The book is moved toward the bookshelf while being grasped. 20
-
[21]
10 Stacked Bowls
The book is successfully placed on the bookshelf. 10 Stacked Bowls
-
[22]
The hand moves toward Bowl 1. 10
-
[23]
Bowl 1 is grasped. 20
-
[24]
Bowl 1 is placed stably. 10
-
[25]
The hand moves toward Bowl 2. 10
-
[26]
Bowl 2 is grasped. 10
-
[27]
Bowl 2 is stably stacked into Bowl 1. 10
-
[28]
The hand moves toward Bowl 3. 10
-
[29]
Bowl 3 is grasped. 10
-
[30]
10 Pull Out Tissue
Bowl 3 is stably stacked into Bowl 2. 10 Pull Out Tissue
-
[31]
Arm A moves toward the tissue box. 10
-
[32]
Arm A holds the tissue box. 20
-
[33]
Arm B moves toward the tissue. 20
-
[34]
Arm B successfully grasps the yellow tissue. 40
-
[35]
10 ⊲The two arms are scored separately.- Stamp
The tissue is placed on the table. 10 ⊲The two arms are scored separately.- Stamp
-
[36]
The robot arm moves toward the stamp. 10
-
[37]
The stamp is successfully grasped and lifted. 30
-
[38]
The stamp is moved above the document. 10
-
[39]
The document is stamped by pressing the stamp. 20
-
[40]
The stamp is moved above the ink pad. 10
-
[41]
20 ⊲If the stamp topples, scoring stops.- Scoop Sugar
The stamp is placed stably without toppling. 20 ⊲If the stamp topples, scoring stops.- Scoop Sugar
-
[42]
The hand moves toward the spoon. 10
-
[43]
The spoon is successfully grasped. 20
-
[44]
Sugar is scooped with the spoon. 20
-
[45]
The spoon is moved to the mug; the spoon must be held, but sugar is not strictly required. 10
-
[46]
The sugar is poured into the mug; the spoon must be held, but sugar is not required. 20
-
[47]
Press the button to start copying
The spoon is placed back on the right side of the table. 20 Table E3.Detailed rule-based results under real-robot OOD settings. Settings Model Rule-based Score Book Bowls Tissue Stamp Sugar Average Environment OOD 𝜋0.5 27 44 32 9 26 27.6 V-JEPA 2.1 24 15 28 6 3 15.2 Qwen3.5-0.8B 1 28 0 0 10 7.8 Qwen3.5-4B 19 27 0 6 10 12.4 Orca-0.8B 23 44 28 27 15 27.4 Or...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.