PixelEyes: Decoupling Perception and Reasoning for Pinpoint Visual Evidence Seeking
Pith reviewed 2026-07-02 19:51 UTC · model grok-4.3
The pith
Decoupling reasoning from perception shortens multi-turn visual search trajectories in MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
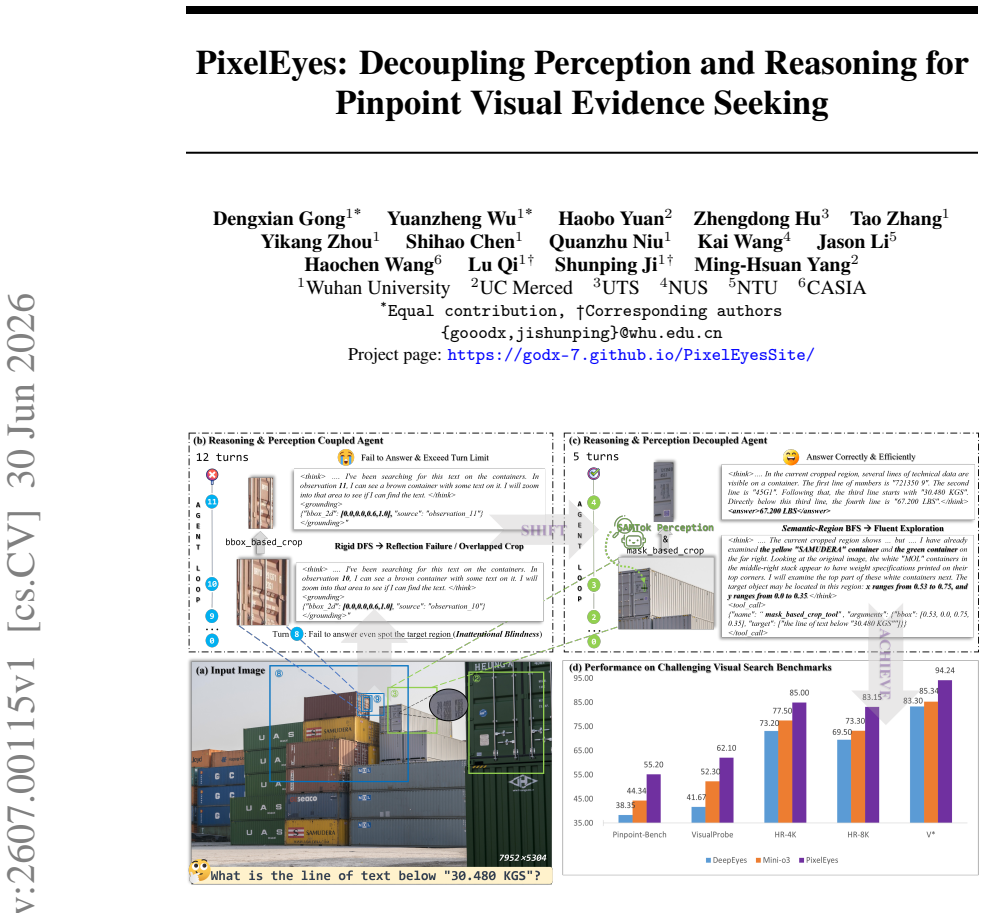
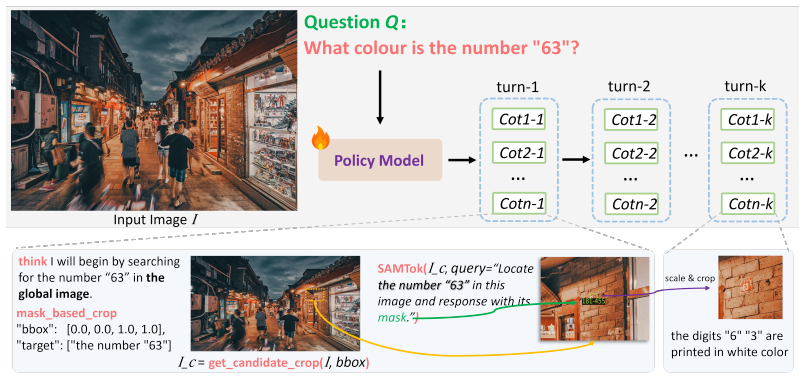
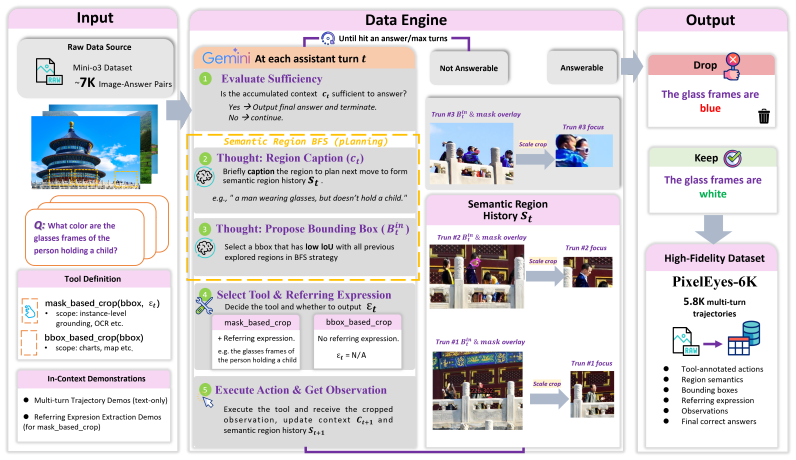
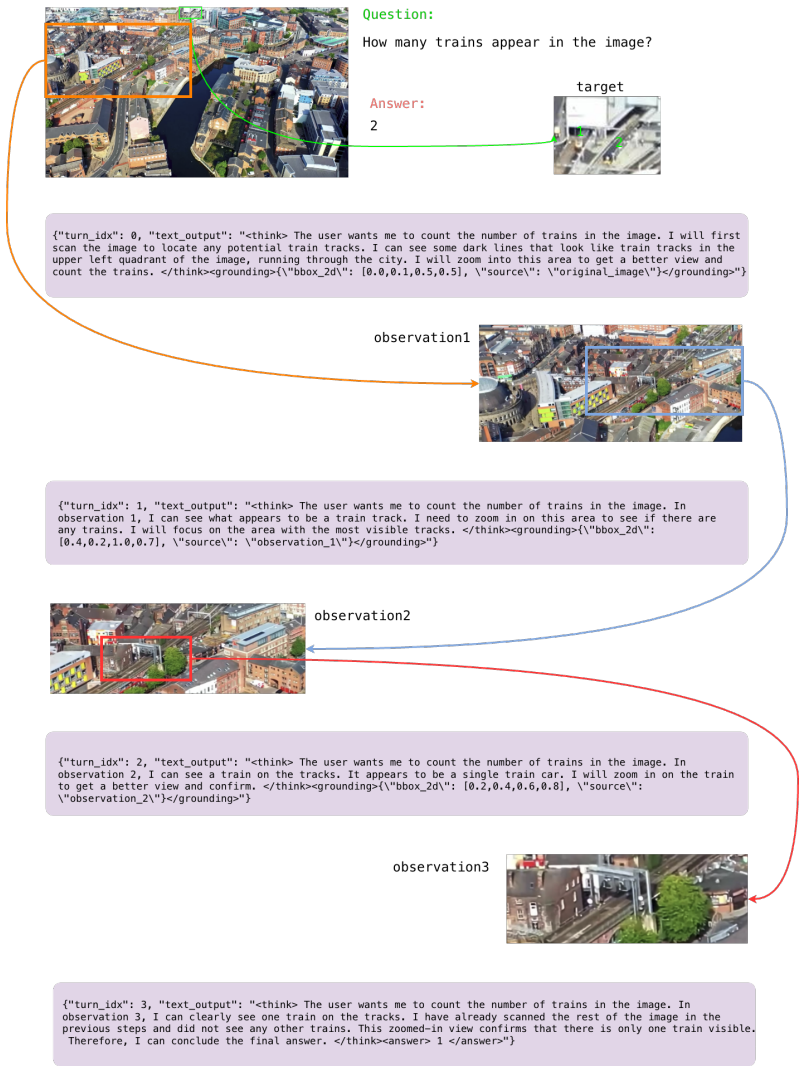
PixelEyes decouples reasoning (deciding what to look for) from perception (answering where it is) by invoking a referring segmentation model for mask-guided localization and organizing search as semantic-region breadth-first search to avoid repeated incorrect crops. These behaviors are internalized by training on the PixelEyes-6K dataset of resynthesized expert trajectories. The resulting agent is evaluated on Pinpoint-Bench, a benchmark that supplies instance-level masks and bounding boxes with no location hints so localization errors can be measured separately from reasoning errors.
What carries the argument
Explicit decoupling of reasoning (what to look for) from perception (mask-precise where) via mask-guided visual search and semantic-region breadth-first search.
If this is right
- Mask-precise localization removes the need for the reasoner to issue corrective follow-up queries after bad crops.
- Breadth-first search over semantic regions prevents the model from repeatedly zooming into the same incorrect sub-region.
- Training on resynthesized trajectories embeds the decoupled search logic directly into the model weights.
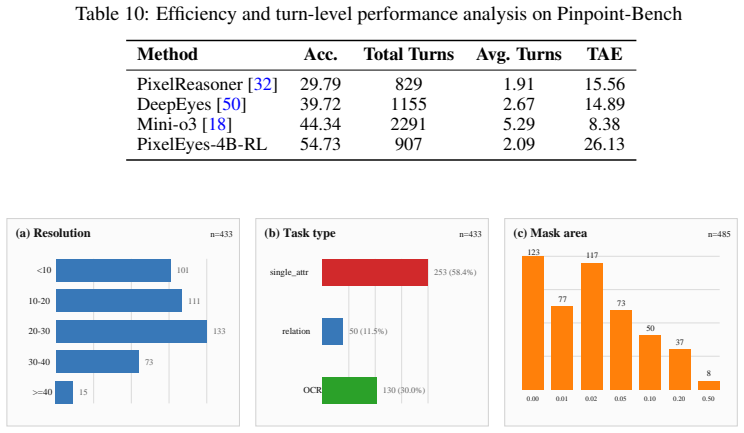
- Pinpoint-Bench isolates localization failures (such as inattentional blindness) from reasoning failures for targeted diagnosis.
- Current state-of-the-art MLLMs and agents leave substantial headroom on the benchmark, indicating the problem is widespread.
Where Pith is reading between the lines
- The same separation of decision and localization modules could be applied to other agent tasks that require repeated visual verification.
- The benchmark design suggests many reported reasoning errors in visual agents may actually stem from grounding inaccuracies that become visible only when hints are removed.
- Modular perception tools might reduce the need for ever-larger unified models in visual reasoning pipelines.
Load-bearing premise
The primary cause of long redundant trajectories is the entanglement of reasoning and perception inside one model rather than insufficient knowledge or prompt design.
What would settle it
Measure average trajectory length and success rate of PixelEyes versus an entangled MLLM baseline on the same Pinpoint-Bench questions; a clear reduction in turns while maintaining accuracy would support the claim.
Figures





read the original abstract
This paper explores multi-turn visual reasoning and observes that MLLMs repeatedly fail to localize the target, leading to long, redundant trajectories. We attribute this failure to the entanglement of reasoning and perception within a single model, the MLLM reasons and localizes simultaneously, and inaccurate localization triggers additional reasoning turns that bloat the trajectory. To solve this problem, we propose PixelEyes, a multi-turn visual reasoning agent that explicitly decouples reasoning from perception, i.e., the reasoner decides what to look for, while a specialized perception tool answers where it is. Specifically, PixelEyes introduces 1) Mask-guided Visual Search. A referring segmentation model is invoked to provide mask-precise localization, freeing the reasoner from the need to compensate for imprecise grounding. 2) Semantic-region Breadth-first Search (BFS). To eliminate redundant loops caused by repeatedly cropping incorrect sub-regions, we organize exploration as a breadth-first search over semantic regions. To internalize these capabilities, we construct the PixelEyes-6K dataset by resynthesizing expert trajectories from existing data. This explicitly embeds our mask-guided search and BFS logic into the model. We further introduce Pinpoint-Bench, a zero-hint visual search benchmark, i.e., no location cues are provided in the question, with instance-level masks and bounding boxes that separate localization failures from reasoning failures, enabling fine-grained analysis of failure modes such as inattentional blindness. Recent state-of-the-art MLLMs and visual reasoning agents leave large headroom on Pinpoint-Bench, demonstrating its quality and difficulty. Code and models are open-sourced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that entanglement of reasoning and perception inside MLLMs causes long redundant trajectories in multi-turn visual reasoning tasks. It proposes PixelEyes, an agent that decouples the two by letting a reasoner decide what to look for while a specialized referring segmentation tool provides mask-precise localization. The approach adds Mask-guided Visual Search and Semantic-region BFS over regions, resynthesizes PixelEyes-6K trajectories to embed this logic, and introduces Pinpoint-Bench (zero-hint, with instance masks/boxes) to separate localization from reasoning failures. Code, models, and data are open-sourced.
Significance. If the reported gains on trajectory length and localization accuracy hold under the new benchmark, the work supplies a concrete architectural separation that directly targets a documented failure mode, plus a reproducible benchmark and dataset that enable fine-grained diagnosis of visual search errors. The resynthesis of expert trajectories to internalize BFS and mask-guided logic, together with open-sourcing, strengthens the contribution for the visual-agent community.
minor comments (3)
- §3 (Method): the description of how the BFS queue is maintained across turns and how semantic regions are extracted from the segmentation masks should be expanded with a short pseudocode or diagram; the current prose leaves the exact termination condition and backtracking rule ambiguous.
- §4.2 (Pinpoint-Bench): the paper states that the benchmark 'separates localization failures from reasoning failures' but does not report inter-annotator agreement on the instance-level masks or the exact protocol used to decide whether a failure is localization vs. reasoning; adding these numbers would strengthen the fine-grained analysis claim.
- Table 2 / §5: the comparison against prior agents lists trajectory length but does not report the number of perception-tool calls separately from reasoning steps; this metric would directly test the decoupling hypothesis.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of PixelEyes, including recognition of the decoupling approach, the PixelEyes-6K dataset, Pinpoint-Bench benchmark, and open-sourcing of code and models. The recommendation for minor revision is noted, and we will prepare the revised manuscript accordingly.
Circularity Check
No significant circularity detected
full rationale
The paper proposes an explicit architectural decoupling of reasoning and perception via mask-guided search and BFS, constructs a dataset to embed that logic, and introduces a benchmark for evaluation. No equations, fitted parameters, or self-citation chains appear in the provided text. The central claim is implemented directly rather than derived from prior fitted quantities or self-referential definitions, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. InNeurIPS, 2022. 3
2022
-
[2]
3.7 sonnet and claude code, 2025
Claude Anthropic. 3.7 sonnet and claude code, 2025. 2
2025
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 2, 8, 10, 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024. 3 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InCVPR, 2024. 3
2024
-
[8]
Schwing, Alexander Kirillov, and Rohit Girdhar
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. Masked- attention mask transformer for universal image segmentation. InCVPR, 2022. 3
2022
-
[9]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, et al. Molmo2: Open weights and data for vision-language models with video understanding and grounding.arXiv preprint arXiv:2601.10611,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1.5-vl technical report.arXiv preprint arXiv:2505.07062, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Visual programming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. InCVPR, 2023. 3
2023
-
[13]
CogVLM2: Visual Language Models for Image and Video Understanding
Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qingsong Lv, Yan Wang, Yean Cheng, Shiyu Huang, Junhui Ji, Zhao Xue, et al. Cogvlm2: Visual language models for image and video understanding. arXiv preprint arXiv:2408.16500, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models. NeurIPS, 2024. 2
2024
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Detect anything via next point prediction.arXiv preprint arXiv:2510.12798, 2025
Qing Jiang, Junan Huo, Xingyu Chen, Yuda Xiong, Zhaoyang Zeng, Yihao Chen, Tianhe Ren, Junzhi Yu, and Lei Zhang. Detect anything via next point prediction.arXiv preprint arXiv:2510.12798, 2025. 2
-
[17]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InICCV, 2023. 3
2023
-
[18]
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Xin Lai, Junyi Li, Wei Li, Tao Liu, Tianjian Li, and Hengshuang Zhao. Mini-o3: Scaling up reasoning patterns and interaction turns for visual search.arXiv preprint arXiv:2509.07969, 2025. 2, 3, 5, 7, 8, 15, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InCVPR, 2024. 2
2024
-
[20]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 3
2023
-
[21]
Open-o3 video: Grounded video reasoning with explicit spatio-temporal evidence.ICML, 2026
Jiahao Meng, Xiangtai Li, Haochen Wang, Yue Tan, Tao Zhang, Lingdong Kong, Yunhai Tong, Anran Wang, Zhiyang Teng, Yujing Wang, and Zhuochen Wang. Open-o3 video: Grounded video reasoning with explicit spatio-temporal evidence.ICML, 2026. 3
2026
-
[22]
Introducing o3 and o4-mini, 2025
OpenAI. Introducing o3 and o4-mini, 2025. 2
2025
-
[23]
Glamm: Pixel grounding large multimodal model
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S Khan. Glamm: Pixel grounding large multimodal model. InCVPR, 2024. 3
2024
-
[24]
Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration
Haozhan Shen, Kangjia Zhao, Tiancheng Zhao, Ruochen Xu, Zilun Zhang, Mingwei Zhu, and Jianwei Yin. Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration. InEMNLP, pages 6613–6629, 2025. 2, 3
2025
-
[25]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Juntao Li, Xiaoye Qu, et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning.arXiv preprint arXiv:2505.08617, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 2, 3, 8, 14
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Chen, J...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Traceable evidence enhanced visual grounded reasoning: Evaluation and methodology.ICLR, 2026
Haochen Wang, Xiangtai Li, Zilong Huang, Anran Wang, Jiacong Wang, Tao Zhang, Jiani Zheng, Sule Bai, Zijian Kang, Jiashi Feng, et al. Traceable evidence enhanced visual grounded reasoning: Evaluation and methodology.ICLR, 2026. 2, 3, 7, 8
2026
-
[31]
X-sam: From segment anything to any segmentation.arXiv preprint arXiv:2508.04655, 2025
Hao Wang, Limeng Qiao, Zequn Jie, Zhijian Huang, Chengjian Feng, Qingfang Zheng, Lin Ma, Xi- angyuan Lan, and Xiaodan Liang. X-sam: From segment anything to any segmentation.arXiv preprint arXiv:2508.04655, 2025. 3
-
[32]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning.arXiv preprint arXiv:2505.15966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Grasp any region: Towards precise, contextual pixel understanding for multimodal llms.ICLR,
Haochen Wang, Yuhao Wang, Tao Zhang, Yikang Zhou, Yanwei Li, Jiacong Wang, Ye Tian, Jiahao Meng, Zilong Huang, Guangcan Mai, Anran Wang, Yunhai Tong, Zhuochen Wang, Xiangtai Li, and Zhaoxiang Zhang. Grasp any region: Towards precise, contextual pixel understanding for multimodal llms.ICLR,
-
[34]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Himtok: Learning hierarchical mask tokens for image segmentation with large multimodal model
Tao Wang, Changxu Cheng, Lingfeng Wang, Senda Chen, and Wuyue Zhao. Himtok: Learning hierarchical mask tokens for image segmentation with large multimodal model. InICCV, 2025. 3
2025
-
[36]
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. InAAAI, 2025. 2, 3, 7, 8
2025
-
[37]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Cong Wei, Yujie Zhong, Haoxian Tan, Yong Liu, Zheng Zhao, Jie Hu, and Yujiu Yang. Hyperseg: Towards universal visual segmentation with large language model.arXiv preprint arXiv:2411.17606, 2024. 3
-
[39]
Lai Wei, Liangbo He, Jun Lan, Lingzhong Dong, Yutong Cai, Siyuan Li, Huijia Zhu, Weiqiang Wang, Linghe Kong, Yue Wang, et al. Zooming without zooming: Region-to-image distillation for fine-grained multimodal perception.arXiv preprint arXiv:2602.11858, 2026. 3
-
[40]
Mingyuan Wu, Jingcheng Yang, Jize Jiang, Meitang Li, Kaizhuo Yan, Hanchao Yu, Minjia Zhang, Chengxiang Zhai, and Klara Nahrstedt. Vtool-r1: Vlms learn to think with images via reinforcement learning on multimodal tool use.arXiv preprint arXiv:2505.19255, 2025. 2
-
[41]
V*: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. In CVPR, 2024. 2, 3, 7, 8
2024
-
[42]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos.arXiv preprint, 2025
Haobo Yuan, Xiangtai Li, Tao Zhang, Yueyi Sun, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, and Ming-Hsuan Yang. Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos.arXiv preprint, 2025. 3, 10
2025
-
[44]
Omg-llava: Bridging image-level, object-level, pixel-level reasoning and understanding
Tao Zhang, Xiangtai Li, Hao Fei, Haobo Yuan, Shengqiong Wu, Shunping Ji, Chen Change Loy, and Shuicheng Yan. Omg-llava: Bridging image-level, object-level, pixel-level reasoning and understanding. NeurIPS, 2024. 2
2024
-
[45]
Adaptive Chain-of-Focus Reasoning via Dynamic Visual Search and Zooming for Efficient VLMs
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, et al. Adaptive chain-of-focus reasoning via dynamic visual search and zooming for efficient vlms.arXiv preprint arXiv:2505.15436, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Yifan Zhang, Liang Hu, Haofeng Sun, Peiyu Wang, Yichen Wei, Shukang Yin, Jiangbo Pei, Wei Shen, Peng Xia, Yi Peng, et al. Skywork-r1v4: Toward agentic multimodal intelligence through interleaved thinking with images and deepresearch.arXiv preprint arXiv:2512.02395, 2025. 3
-
[47]
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025. 3, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024. 2, 7, 8, 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Instruction-guided visual masking.NeurIPS, 37:126004–126031, 2024
Jinliang Zheng, Jianxiong Li, Sijie Cheng, Yinan Zheng, Jiaming Li, Jihao Liu, Yu Liu, Jingjing Liu, and Xianyuan Zhan. Instruction-guided visual masking.NeurIPS, 37:126004–126031, 2024. 3
2024
-
[50]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025. 3, 8, 15, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Focus: Internal mllm representations for efficient fine-grained visual question answering
Liangyu Zhong, Fabio Rosenthal, Joachim Sicking, Fabian Hüger, Thorsten Bagdonat, Hanno Gottschalk, and Leo Schwinn. Focus: Internal mllm representations for efficient fine-grained visual question answering. arXiv preprint arXiv:2506.21710, 2025. 2 12
-
[52]
Samtok: Representing any mask with two words.arXiv preprint arXiv:2601.16093, 2026
Yikang Zhou, Tao Zhang, Dengxian Gong, Yuanzheng Wu, Ye Tian, Haochen Wang, Haobo Yuan, Jiacong Wang, Lu Qi, Hao Fei, et al. Samtok: Representing any mask with two words.arXiv preprint arXiv:2601.16093, 2026. 2, 3, 4, 10
-
[53]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 3 13 Appendix A More Experiment Results Implementation Details.For SFT, we fine-tune the base model...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.