DriveVer: Lightweight Trajectory Evaluator as Test-Time Verifier for Autonomous Driving
Pith reviewed 2026-07-02 14:57 UTC · model grok-4.3
The pith
DriveVer adds a compact test-time verifier that scores and refines driving trajectories to lift base planner performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
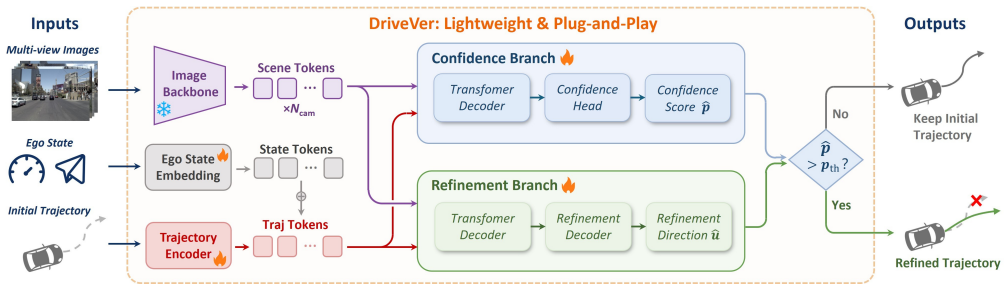
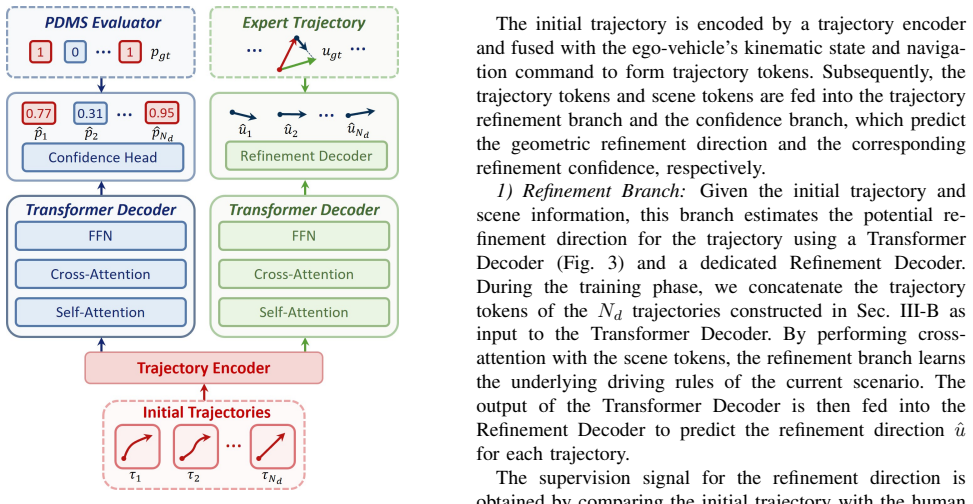
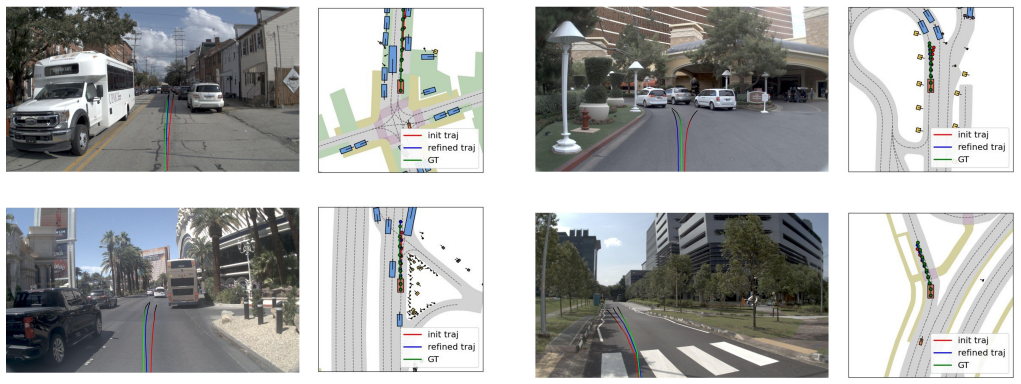
DriveVer is a lightweight dual-head verifier trained on a NAVSIM-derived trajectory dataset built by condition-driven clustering and balanced sampling of ego states and commands. At inference it fuses candidate trajectories with multi-view images and kinematic features to predict a safety confidence score together with an absolute geometric refinement vector, thereby validating and correcting trajectories generated by base planners.
What carries the argument
Dual-head architecture that fuses candidate trajectories with multi-view visual representations and ego-vehicle kinematic features to output a safety confidence score and a geometric refinement vector.
If this is right
- Base planning models receive measurable performance gains when paired with DriveVer at inference time.
- The verifier adds only minimal computational overhead while preserving real-time operation.
- Improvement comes from test-time scaling rather than further training-time scaling of the planner.
- A specially sampled NAVSIM trajectory dataset suffices to train an effective verifier.
Where Pith is reading between the lines
- The same verifier pattern could be tested on other sequential control tasks that generate candidate trajectories.
- Accurate refinement vectors might let planners generate fewer candidates in the first place.
- Performance on edge cases would depend on how completely the clustered dataset covers rare command combinations.
Load-bearing premise
The trajectory dataset constructed from NAVSIM via condition-driven clustering and balanced sampling according to ego-vehicle states and navigation commands is representative enough for the verifier to generalize.
What would settle it
If DriveVer is attached to base planners on a different driving benchmark and produces no measurable gains in collision rate or route completion, the performance-improvement claim would be falsified.
Figures

read the original abstract
End-to-end autonomous driving models often encounter performance bottlenecks, as training-time scaling leads to high computational costs and diminishing marginal returns. Existing planners typically adopt a one-shot generation paradigm, lacking secondary validation and active correction mechanisms to detect and revise suboptimal or unsafe trajectories during inference. To address this issue, we propose DriveVer, a lightweight, plug-and-play Test-Time Verifier that leverages the test-time scaling paradigm to enable autonomous driving systems to validate and refine trajectories without costly and heavy training. We construct a dedicated trajectory dataset based on the NAVSIM benchmark through condition-driven clustering and balanced sampling according to ego-vehicle states and navigation commands. Employing a dual-head architecture, DriveVer efficiently fuses candidate trajectories with multi-view visual representations and ego-vehicle kinematic features to simultaneously predict a safety confidence score and an absolute geometric refinement vector. Extensive experiments on the NAVSIM benchmark show that DriveVer significantly improves the performance of base planning models. Notably, as an extremely compact model with only 34M parameters, DriveVer introduces minimal computational overhead, achieving competitive results while maintaining real-time inference efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DriveVer, a 34M-parameter dual-head model that serves as a plug-and-play test-time verifier for trajectories generated by end-to-end autonomous driving planners. It is trained on a dataset constructed from the NAVSIM benchmark via condition-driven clustering and balanced sampling on ego states and navigation commands; the model fuses candidate trajectories with multi-view images and kinematic features to output a safety confidence score and an absolute geometric refinement vector. The central claim is that this lightweight verifier yields significant performance gains on NAVSIM while adding negligible compute and preserving real-time inference.
Significance. If the claimed improvements and generalization hold, the work would demonstrate a practical test-time scaling mechanism that augments existing planners without retraining, using an unusually compact architecture. The emphasis on a dedicated trajectory dataset and dual-head prediction is a concrete contribution to verification-based planning.
major comments (2)
- [Dataset construction] Dataset construction section: the condition-driven clustering plus balanced sampling on ego-vehicle states and navigation commands is presented as sufficient to train a verifier that generalizes, yet no analysis is supplied showing coverage of long-tail regimes (rare multi-agent interactions, sensor degradation, or out-of-cluster command sequences) that still appear in the NAVSIM test split. This directly affects whether the reported safety-score and refinement predictions remain reliable where verification is most needed.
- [Results / Experiments] Results section: the abstract states that 'extensive experiments on the NAVSIM benchmark show that DriveVer significantly improves the performance of base planning models,' but the manuscript supplies no quantitative metrics, error bars, ablation tables, or comparison against alternative verifiers or sampling strategies. Without these numbers the central performance claim cannot be evaluated.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least the headline NAVSIM metric deltas and parameter count so readers can immediately assess the claimed efficiency-accuracy trade-off.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed review of our manuscript. The two major comments identify areas where additional analysis and reporting would strengthen the presentation of our work. We address each point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: the condition-driven clustering plus balanced sampling on ego-vehicle states and navigation commands is presented as sufficient to train a verifier that generalizes, yet no analysis is supplied showing coverage of long-tail regimes (rare multi-agent interactions, sensor degradation, or out-of-cluster command sequences) that still appear in the NAVSIM test split. This directly affects whether the reported safety-score and refinement predictions remain reliable where verification is most needed.
Authors: We agree that an explicit analysis of long-tail coverage would strengthen the manuscript. While the condition-driven clustering and balanced sampling were intended to promote diversity across ego states and navigation commands, we did not provide quantitative verification of coverage for rare multi-agent interactions or out-of-cluster sequences relative to the NAVSIM test split. In the revised manuscript we will add a dedicated analysis (in the dataset section or an appendix) that reports statistics on the distribution of these regimes in the constructed training set versus the test split, along with any identified limitations. revision: yes
-
Referee: [Results / Experiments] Results section: the abstract states that 'extensive experiments on the NAVSIM benchmark show that DriveVer significantly improves the performance of base planning models,' but the manuscript supplies no quantitative metrics, error bars, ablation tables, or comparison against alternative verifiers or sampling strategies. Without these numbers the central performance claim cannot be evaluated.
Authors: We acknowledge that the experimental results were not presented with the level of detail required for full evaluation. Although the manuscript claims improvements on NAVSIM, the current version lacks the supporting quantitative tables, error bars, ablations, and baseline comparisons. In the revision we will expand the Results section to include comprehensive performance metrics (e.g., safety, progress, and comfort scores), standard deviations across runs, ablation studies on the dual-head architecture and sampling strategy, and direct comparisons against alternative verification approaches. revision: yes
Circularity Check
No circularity: model trained on constructed dataset and evaluated externally
full rationale
The paper constructs a trajectory dataset from NAVSIM via clustering and sampling, trains a dual-head verifier to output safety scores and refinements, then reports benchmark improvements. No equations, predictions, or claims reduce by construction to fitted inputs or self-citations; the evaluation is on a held-out benchmark split independent of the training construction. This is the standard non-circular training/evaluation setup.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Condition-driven clustering and balanced sampling of NAVSIM trajectories produces a training distribution that supports learning a generalizable safety and refinement predictor.
Reference graph
Works this paper leans on
-
[1]
A survey on vision-language-action models for autonomous driving,
S. Jiang, Z. Huang, K. Qian, Z. Luo, T. Zhu, Y . Zhong, Y . Tang, M. Kong, Y . Wang, S. Jiaoet al., “A survey on vision-language-action models for autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 4524–4536
2025
-
[2]
Vision-language-action models for autonomous driving: Past, present, and future,
T. Hu, X. Liu, S. Wang, Y . Zhu, A. Liang, L. Kong, G. Zhao, Z. Gong, J. Cen, Z. Huanget al., “Vision-language-action models for autonomous driving: Past, present, and future,”arXiv preprint arXiv:2512.16760, 2025
-
[3]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[4]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8340–8350
2023
-
[5]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wanget al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
2023
-
[6]
Adathinkdrive: Adaptive thinking via reinforcement learning for autonomous driving,
Y . Luo, F. Li, S. Xu, Z. Lai, L. Yang, Q. Chen, Z. Luo, Z. Xie, S. Jiang, J. Liuet al., “Adathinkdrive: Adaptive thinking via reinforcement learning for autonomous driving,”arXiv preprint arXiv:2509.13769, 2025
-
[7]
Minddriver: Introducing progres- sive multimodal reasoning for autonomous driving,
L. Zhang, Y . Yuan, C. Wu, X. Chang, X. Cai, S. Zeng, L. Shi, S. Wang, H. Zhang, and M. Xu, “Minddriver: Introducing progres- sive multimodal reasoning for autonomous driving,”arXiv preprint arXiv:2602.21952, 2026
-
[8]
Xiaomi OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
J. Lu, J. Guan, Z. Huang, J. Li, G. Li, L. Kong, Y . Li, H. Wang, S. Xu, Y . Luo, F. Li, C. Dang, J. Wang, T. Xu, J. Wu, J. Wu, X. Hao, W. Zhang, T. Jiang, L. Zhang, L. Zhou, Y . Tang, J. Wang, Y . Gao, X. Bu, H. Tian, Y . Qiu, F. Jia, L. Liu, Y . Ge, H. Li, Y . Shen, J. Cui, H. Xie, B. Wang, H. Sun, J. Zhao, J. Huang, P. Liu, Z. Zhu, Y . Jiang, Z. Guo, C...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Vilta: A vlm-in-the- loop adversary for enhancing driving policy robustness,
Q. Chen, F. Li, S. Xu, Z. Lai, Z. Xie, Y . Luo, S. Jiang, H. Li, L. Chen, B. Wang, Y . Zhang, and Z.-X. Yang, “Vilta: A vlm-in-the- loop adversary for enhancing driving policy robustness,”arXiv preprint arXiv:2601.12672, 2026
-
[10]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Q. Zhang, F. Lyu, Z. Sun, L. Wang, W. Zhang, W. Hua, H. Wu, Z. Guo, Y . Wang, N. Muennighoffet al., “A survey on test-time scaling in large language models: What, how, where, and how well?”arXiv preprint arXiv:2503.24235, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
S. Chen, B. Jiang, H. Gao, B. Liao, Q. Xu, Q. Zhang, C. Huang, W. Liu, and X. Wang, “Vadv2: End-to-end vectorized autonomous driving via probabilistic planning,”arXiv preprint arXiv:2402.13243, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y . Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wuet al., “Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation,”arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhanget al., “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 037–12 047
2025
-
[14]
Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
B. Jiang, S. Chen, B. Liao, X. Zhang, W. Yin, Q. Zhang, C. Huang, W. Liu, and X. Wang, “Senna: Bridging large vision- language models and end-to-end autonomous driving,”arXiv preprint arXiv:2410.22313, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
B. Jiang, S. Chen, Q. Zhang, W. Liu, and X. Wang, “Alphadrive: Un- leashing the power of vlms in autonomous driving via reinforcement learning and reasoning,”arXiv preprint arXiv:2503.07608, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Mtrdrive: Memory-tool synergistic reason- ing for robust autonomous driving in corner cases,
Z. Luo, K. Qian, J. Wang, Y . Luo, J. Miao, Z. Fu, Y . Wang, S. Jiang, Z. Huang, Y . Huet al., “Mtrdrive: Memory-tool synergistic reason- ing for robust autonomous driving in corner cases,”arXiv preprint arXiv:2509.20843, 2025
-
[17]
EMMA: End-to-End Multimodal Model for Autonomous Driving
J.-J. Hwang, R. Xu, H. Lin, W.-C. Hung, J. Ji, K. Choi, D. Huang, T. He, P. Covington, B. Sappet al., “Emma: End-to-end multimodal model for autonomous driving,”arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Openemma: Open-source multimodal model for end-to-end autonomous driving,
S. Xing, C. Qian, Y . Wang, H. Hua, K. Tian, Y . Zhou, and Z. Tu, “Openemma: Open-source multimodal model for end-to-end autonomous driving,” inProceedings of the Winter Conference on Applications of Computer Vision, 2025, pp. 1001–1009
2025
-
[19]
Z. Zhou, T. Cai, S. Z. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma, “Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning,”arXiv preprint arXiv:2506.13757, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wanget al., “Recogdrive: A reinforced cog- nitive framework for end-to-end autonomous driving,”arXiv preprint arXiv:2506.08052, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Unleashing vla potentials in autonomous driving via explicit learning from failures,
Y . Luo, Q. Chen, F. Li, S. Xu, J. Liu, Z. Song, Z.-x. Yang, and F. Wen, “Unleashing vla potentials in autonomous driving via explicit learning from failures,”arXiv preprint arXiv:2603.01063, 2026
-
[22]
Last-vla: Thinking in latent spatio-temporal space for vision-language-action in autonomous driving,
Y . Luo, F. Li, S. Xu, Y . Ji, Z. Zhang, B. Wang, Y . Shen, J. Cui, L. Chen, G. Chenet al., “Last-vla: Thinking in latent spatio-temporal space for vision-language-action in autonomous driving,”arXiv preprint arXiv:2603.01928, 2026
-
[23]
Reasonplan: Unified scene prediction and decision reasoning for closed-loop autonomous driving,
X. Liu, Z. Zhong, Y . Guo, Y .-F. Liu, Z. Su, Q. Zhang, J. Wang, Y . Gao, Y . Zheng, Q. Linet al., “Reasonplan: Unified scene prediction and decision reasoning for closed-loop autonomous driving,”arXiv preprint arXiv:2505.20024, 2025
-
[24]
Sce2drivex: A generalized mllm framework for scene-to-drive learn- ing,
R. Zhao, Q. Yuan, J. Li, H. Hu, Y . Li, C. Zheng, and F. Gao, “Sce2drivex: A generalized mllm framework for scene-to-drive learn- ing,”arXiv preprint arXiv:2502.14917, 2025
-
[25]
End-to-end driving with online trajectory evaluation via bev world model,
Y . Li, Y . Wang, Y . Liu, J. He, L. Fan, and Z. Zhang, “End-to-end driving with online trajectory evaluation via bev world model,”arXiv preprint arXiv:2504.01941, 2025
-
[26]
Q. Chen, F. Li, Y . Luo, Z. Zhang, H. Sun, F. Li, B. Wang, G. Chen, Y . Ji, J. Deng, H. Xie, H. Ye, L. Chen, and Y . Zhang, “Drivereward: A comprehensive dataset and generative vision-language reward model for autonomous driving,”arXiv preprint arXiv:2606.08525, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavoneet al., “Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 28 706– 28 719, 2024
2024
-
[28]
E. Kirby, A. Boulch, Y . Xu, Y . Yin, G. Puy, ´E. Zablocki, A. Bursuc, S. Gidaris, R. Marlet, F. Bartoccioniet al., “Driving on registers,” arXiv preprint arXiv:2601.05083, 2026
-
[29]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolff, A. Lang, L. Fletcher, O. Beijbom, and S. Omari, “nuplan: A closed-loop ml- based planning benchmark for autonomous vehicles,”arXiv preprint arXiv:2106.11810, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Openscene: The largest up-to-date 3d occupancy prediction benchmark in autonomous driving,
O. Contributors, “Openscene: The largest up-to-date 3d occupancy prediction benchmark in autonomous driving,” inProceedings of the Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023, pp. 18–22
2023
-
[31]
Para- drive: Parallelized architecture for real-time autonomous driving,
X. Weng, B. Ivanovic, Y . Wang, Y . Wang, and M. Pavone, “Para- drive: Parallelized architecture for real-time autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 449–15 458
2024
-
[32]
Hydra-next: Robust closed-loop driving with open-loop training,
Z. Li, S. Wang, S. Lan, Z. Yu, Z. Wu, and J. M. Alvarez, “Hydra-next: Robust closed-loop driving with open-loop training,”arXiv preprint arXiv:2503.12030, 2025
-
[33]
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Y . Li, S. Shang, W. Liu, B. Zhan, H. Wang, Y . Wang, Y . Chen, X. Wang, Y . An, C. Tanget al., “Drivevla-w0: World models amplify data scaling law in autonomous driving,”arXiv preprint arXiv:2510.12796, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Goalflow: Goal-driven flow matching for multimodal trajec- tories generation in end-to-end autonomous driving,
Z. Xing, X. Zhang, Y . Hu, B. Jiang, T. He, Q. Zhang, X. Long, and W. Yin, “Goalflow: Goal-driven flow matching for multimodal trajec- tories generation in end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1602–1611
2025
-
[35]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2022
2022
-
[36]
Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario,
T. Qian, J. Chen, L. Zhuo, Y . Jiao, and Y .-G. Jiang, “Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 5, 2024, pp. 4542–4550
2024
-
[37]
Pseudo-simulation for autonomous driving,
W. Cao, M. Hallgarten, T. Li, D. Dauner, X. Gu, C. Wang, Y . Miron, M. Aiello, H. Li, I. Gilitschenskiet al., “Pseudo-simulation for autonomous driving,”arXiv preprint arXiv:2506.04218, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.